Compare commits
547 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6ae86597e8 | ||
|
|
c578ff25bd | ||
|
|
2934a3e3be | ||
|
|
ceaa69da75 | ||
|
|
fa8e731576 | ||
|
|
685c0a106a | ||
|
|
7f539090dd | ||
|
|
2089273f95 | ||
|
|
838bb4c7ad | ||
|
|
637acd1a12 | ||
|
|
03fa9a847f | ||
|
|
d488c88e78 | ||
|
|
baae842210 | ||
|
|
ec1fb838b6 | ||
|
|
13281179df | ||
|
|
276a42c9a1 | ||
|
|
7a70a730ba | ||
|
|
d0fe59631c | ||
|
|
106892e933 | ||
|
|
19543a41b3 | ||
|
|
b172b760ab | ||
|
|
4b5d49cb41 | ||
|
|
3fd35b6058 | ||
|
|
5f86c4ab99 | ||
|
|
c94a7f6629 | ||
|
|
7d6beb4141 | ||
|
|
e2117e690a | ||
|
|
fb791290e2 | ||
|
|
5dd1488b5d | ||
|
|
529cd64d82 | ||
|
|
d2bd3e8da8 | ||
|
|
e42ce7dd86 | ||
|
|
40709462ee | ||
|
|
2ad6c01a4d | ||
|
|
70c12e788e | ||
|
|
1713791c90 | ||
|
|
9aa23fd412 | ||
|
|
e4ba09cd93 | ||
|
|
171fdf1fbc | ||
|
|
01f4e0b961 | ||
|
|
be2d5a91c7 | ||
|
|
a1d89d9478 | ||
|
|
98d1dc3b65 | ||
|
|
b80eb3acc0 | ||
|
|
05ccc1995b | ||
|
|
0de244889e | ||
|
|
e6c5c3a493 | ||
|
|
164aa2ccd2 | ||
|
|
f1599e26b3 | ||
|
|
ed64a4d32d | ||
|
|
2ee4b431d4 | ||
|
|
cd8a73ed19 | ||
|
|
e6c985ce4e | ||
|
|
a20446aeb9 | ||
|
|
7b23d76559 | ||
|
|
8315cf5818 | ||
|
|
ed16265bde | ||
|
|
dff205faf6 | ||
|
|
9aae8aee0c | ||
|
|
7c818ced2b | ||
|
|
218e887558 | ||
|
|
a68860b35a | ||
|
|
82d4d43383 | ||
|
|
94618e8feb | ||
|
|
55de7d4494 | ||
|
|
7ed639f741 | ||
|
|
41f2870c29 | ||
|
|
ba198490fa | ||
|
|
0f9ab082ab | ||
|
|
97b58965f2 | ||
|
|
f2566c68e3 | ||
|
|
a456bf5449 | ||
|
|
a09998f910 | ||
|
|
be662b913c | ||
|
|
e7ddc8448d | ||
|
|
29374f8d8a | ||
|
|
359b971103 | ||
|
|
fbdb1ae208 | ||
|
|
22c13c1eff | ||
|
|
5fc63aeaf1 | ||
|
|
d4f32673ab | ||
|
|
480dffb51b | ||
|
|
966df00124 | ||
|
|
3e2b4bc727 | ||
|
|
5929a8d42b | ||
|
|
f8ab40eb39 | ||
|
|
55e9233b93 | ||
|
|
b7277b51fd | ||
|
|
1fa9111b2b | ||
|
|
90a9e496d9 | ||
|
|
2a7dce1eb0 | ||
|
|
0c0841cc03 | ||
|
|
4c9fe016bf | ||
|
|
acc90f140c | ||
|
|
68a7bc3930 | ||
|
|
12ea64be0e | ||
|
|
7f30a673f7 | ||
|
|
897e100c32 | ||
|
|
0d4ad5cb31 | ||
|
|
b124bd0d0e | ||
|
|
6bc2f84602 | ||
|
|
d787a28c40 | ||
|
|
6b078a5731 | ||
|
|
17dddbfe21 | ||
|
|
3ff3c9e144 | ||
|
|
f5a37d82cc | ||
|
|
d3d428dc9d | ||
|
|
8dc8c5b5dc | ||
|
|
e6b06f914b | ||
|
|
4dc502a8b6 | ||
|
|
b1d1a13d5f | ||
|
|
75cc4cac5a | ||
|
|
1b7e4fbbdc | ||
|
|
9789e2f6c1 | ||
|
|
b8fb0bee24 | ||
|
|
419f77e245 | ||
|
|
59b1c3473b | ||
|
|
6db58ca375 | ||
|
|
4832b342b0 | ||
|
|
6cec542402 | ||
|
|
9644791783 | ||
|
|
5031c307d1 | ||
|
|
aa49539e3e | ||
|
|
7b4118493b | ||
|
|
d1cc9ba4ce | ||
|
|
e0e92139d7 | ||
|
|
62039392bb | ||
|
|
b72c69892e | ||
|
|
e6205e9aad | ||
|
|
b8a6fb1720 | ||
|
|
7c06d82f27 | ||
|
|
d92cb0f500 | ||
|
|
7fa72f2fe9 | ||
|
|
21d480a3b5 | ||
|
|
771c045844 | ||
|
|
e6ce484c15 | ||
|
|
102a92f62d | ||
|
|
6c7ac70701 | ||
|
|
9d8372289f | ||
|
|
766f6a1ba2 | ||
|
|
193ff24f4c | ||
|
|
c675017374 | ||
|
|
86cb852507 | ||
|
|
73494e0d7d | ||
|
|
ec61aa1b6f | ||
|
|
6df0e78b22 | ||
|
|
63c604359b | ||
|
|
08212588a0 | ||
|
|
c8518ce827 | ||
|
|
94434e3fc0 | ||
|
|
9f3af95198 | ||
|
|
acb3af8ab8 | ||
|
|
9c50889371 | ||
|
|
8c03c90708 | ||
|
|
91cc21e729 | ||
|
|
dd29199c9b | ||
|
|
9156629d72 | ||
|
|
002aa61dd9 | ||
|
|
401747a7a3 | ||
|
|
990390218c | ||
|
|
69a4d6ac83 | ||
|
|
3a67492680 | ||
|
|
d58b9edf78 | ||
|
|
5144dd09f1 | ||
|
|
6a5f3720a2 | ||
|
|
d814d3537c | ||
|
|
85380ade6a | ||
|
|
86f53deade | ||
|
|
c3357dc0e2 | ||
|
|
97e14dd294 | ||
|
|
e45c48b998 | ||
|
|
0b53eae4ad | ||
|
|
92aa3123ec | ||
|
|
e9e789da20 | ||
|
|
c6bdac8835 | ||
|
|
90df679a77 | ||
|
|
b25a422fd6 | ||
|
|
47e70bd086 | ||
|
|
f963194124 | ||
|
|
bdfc77d349 | ||
|
|
7abe90f2ac | ||
|
|
4a52779d09 | ||
|
|
a01e865042 | ||
|
|
446c50da80 | ||
|
|
750a93a1aa | ||
|
|
ba12d65792 | ||
|
|
bd40404f58 | ||
|
|
4d8d9ecfc2 | ||
|
|
f2efa022b4 | ||
|
|
fc28f34ec6 | ||
|
|
b740cc467d | ||
|
|
6ab8114eee | ||
|
|
cd3f90917f | ||
|
|
2219547a8b | ||
|
|
017426501c | ||
|
|
ca19754a30 | ||
|
|
4623f2f12a | ||
|
|
c14813c0b2 | ||
|
|
9d8308ace0 | ||
|
|
4976e81ea4 | ||
|
|
f59de87a31 | ||
|
|
53dbebb503 | ||
|
|
52df91eb60 | ||
|
|
a9a758d715 | ||
|
|
0226fa7a25 | ||
|
|
a4f47da35c | ||
|
|
29364000e2 | ||
|
|
ceecca44a4 | ||
|
|
50f62e66b0 | ||
|
|
ab39dfd254 | ||
|
|
708fad18b6 | ||
|
|
526ba34d87 | ||
|
|
5d4882dee9 | ||
|
|
48c4361d37 | ||
|
|
c1d070186e | ||
|
|
1a39fd9172 | ||
|
|
0c1ab4158e | ||
|
|
5221566335 | ||
|
|
2291c2d9ba | ||
|
|
0de14c4c8b | ||
|
|
51de0159fb | ||
|
|
37a756aeb3 | ||
|
|
353b6ed761 | ||
|
|
90815b1ac5 | ||
|
|
8a50786e61 | ||
|
|
3b77df0556 | ||
|
|
1fa11062de | ||
|
|
6883de0f1c | ||
|
|
bdde0fe094 | ||
|
|
ab22b8103e | ||
|
|
641d5cd67b | ||
|
|
9fe941e457 | ||
|
|
78060c9985 | ||
|
|
5bd6af3400 | ||
|
|
4ecd78d6a8 | ||
|
|
7e9f54ed2c | ||
|
|
7dd29c707f | ||
|
|
a1489fb1f9 | ||
|
|
5f0f5398e8 | ||
|
|
e3b2396f32 | ||
|
|
6fd70ed26a | ||
|
|
a93e6ff01a | ||
|
|
6db8c38c58 | ||
|
|
d3d3ff7970 | ||
|
|
c5b2b30f79 | ||
|
|
ac2144d65b | ||
|
|
c620b4f919 | ||
|
|
292a3a43ba | ||
|
|
5fc4693b9c | ||
|
|
6dfbaf1b88 | ||
|
|
14c6e56287 | ||
|
|
7e48514f67 | ||
|
|
d8e70c4d7f | ||
|
|
fb52989d62 | ||
|
|
5b72ebaad5 | ||
|
|
98863ab901 | ||
|
|
b5cb5eb969 | ||
|
|
7f4f96f77b | ||
|
|
3b3f75f03e | ||
|
|
a5db4d4e47 | ||
|
|
d3b0f25cfe | ||
|
|
a9c6a68c5f | ||
|
|
c27f172452 | ||
|
|
2eeb5822c1 | ||
|
|
743046d48f | ||
|
|
d3a5205bde | ||
|
|
ae6dd8929a | ||
|
|
dcf96896ef | ||
|
|
67792100bb | ||
|
|
48c1263417 | ||
|
|
12d37381fe | ||
|
|
dcec3f5f84 | ||
|
|
32e2a7830a | ||
|
|
6992249e53 | ||
|
|
107214ac53 | ||
|
|
8a58772911 | ||
|
|
e21736b470 | ||
|
|
e8679f8984 | ||
|
|
970fe02027 | ||
|
|
12216853c5 | ||
|
|
33ec92258d | ||
|
|
a578edf137 | ||
|
|
f8949ebead | ||
|
|
141c91301f | ||
|
|
8d95e67b5a | ||
|
|
0633e7f25f | ||
|
|
266da0a9d8 | ||
|
|
121c40f273 | ||
|
|
a876efb95f | ||
|
|
95a8cc9498 | ||
|
|
f02731055e | ||
|
|
1df83addfc | ||
|
|
9db43ac5e6 | ||
|
|
0f470cf96f | ||
|
|
da3fcb7b86 | ||
|
|
73dd4703b9 | ||
|
|
0c679a0151 | ||
|
|
1d6ea2dbe6 | ||
|
|
933df57654 | ||
|
|
a7c87642b4 | ||
|
|
cbe761fc33 | ||
|
|
f8aef78d25 | ||
|
|
14dbdb2d83 | ||
|
|
abda226d63 | ||
|
|
a2dc6f0a49 | ||
|
|
7a94c26333 | ||
|
|
9b1ffb384b | ||
|
|
9566bfe122 | ||
|
|
89ff103bda | ||
|
|
6c788db53a | ||
|
|
344b5fa419 | ||
|
|
c6d161b837 | ||
|
|
2065ba0c60 | ||
|
|
a481fd1a3e | ||
|
|
c50bcdbdb9 | ||
|
|
36a2a7632c | ||
|
|
e77b7014e6 | ||
|
|
d57fd0f827 | ||
|
|
6a83d2a62a | ||
|
|
2d29726c18 | ||
|
|
b241b0f954 | ||
|
|
171dd1dc02 | ||
|
|
af62d969d7 | ||
|
|
c4fd9a66c6 | ||
|
|
d191997a39 | ||
|
|
853ac4c104 | ||
|
|
ed053acad6 | ||
|
|
f147634e51 | ||
|
|
e3b2a68341 | ||
|
|
84c450aef9 | ||
|
|
f52a0eb43a | ||
|
|
6ed7559518 | ||
|
|
d977dbe9a7 | ||
|
|
17fc761c61 | ||
|
|
af878f2ed3 | ||
|
|
bb2164c324 | ||
|
|
0496becc50 | ||
|
|
618f8aa7d2 | ||
|
|
c57f711c48 | ||
|
|
4edd11f2f7 | ||
|
|
a2cf058951 | ||
|
|
d52eb10ddd | ||
|
|
4b6dae71fc | ||
|
|
ddad30c22e | ||
|
|
77067c545c | ||
|
|
465d283cad | ||
|
|
05071144fb | ||
|
|
a4e7904953 | ||
|
|
986a8c7554 | ||
|
|
9272843b77 | ||
|
|
542d4bc703 | ||
|
|
e3640fdac9 | ||
|
|
f64ab4b190 | ||
|
|
bd571e1577 | ||
|
|
e4a5cbd893 | ||
|
|
7a9fd7fd1e | ||
|
|
d9b60108db | ||
|
|
8455c8b4ed | ||
|
|
5c2e7099fc | ||
|
|
1fd1d55895 | ||
|
|
5ce4137e75 | ||
|
|
d49179541e | ||
|
|
676f258981 | ||
|
|
fa44749240 | ||
|
|
6c856f9da2 | ||
|
|
e8773cea7f | ||
|
|
4d36ffcb08 | ||
|
|
c653e492c4 | ||
|
|
f08de1f404 | ||
|
|
1218691b61 | ||
|
|
61fc27ff79 | ||
|
|
123ee24f7e | ||
|
|
52c9045a28 | ||
|
|
f00f1e8933 | ||
|
|
8da4433e57 | ||
|
|
7babb87934 | ||
|
|
f67b171385 | ||
|
|
1780d1355d | ||
|
|
5a3390e4f3 | ||
|
|
337d96b41d | ||
|
|
38a1dfea98 | ||
|
|
fbef73aeec | ||
|
|
d6214c2b7c | ||
|
|
d58c86f6fc | ||
|
|
ea34c20198 | ||
|
|
934ca94e62 | ||
|
|
1775327c2e | ||
|
|
707fcad8b4 | ||
|
|
f143c5afc6 | ||
|
|
99f94b2611 | ||
|
|
e39c1f9116 | ||
|
|
235e0b9b8f | ||
|
|
d5a9bed8a4 | ||
|
|
d7dc8a7612 | ||
|
|
08cd3ca40c | ||
|
|
a13562dcea | ||
|
|
d7a0c0d1d0 | ||
|
|
c0729b2d29 | ||
|
|
a80f474290 | ||
|
|
699207dd54 | ||
|
|
e7708010c9 | ||
|
|
f66091e08f | ||
|
|
03bb932f8f | ||
|
|
fbf8b349e0 | ||
|
|
e9278fce6a | ||
|
|
9a7db956d5 | ||
|
|
13196dd667 | ||
|
|
52b80e24d2 | ||
|
|
7dff87e65d | ||
|
|
31ee64d1b2 | ||
|
|
8e865b6918 | ||
|
|
66f91e5832 | ||
|
|
cd2d368f9c | ||
|
|
7736c1c9bd | ||
|
|
6728c0b7b5 | ||
|
|
344f92e0e7 | ||
|
|
fdabfef6a7 | ||
|
|
6c5718f134 | ||
|
|
edfde51434 | ||
|
|
3fc1347bba | ||
|
|
e643eea365 | ||
|
|
1af481f5f9 | ||
|
|
317d1c4c41 | ||
|
|
a703860512 | ||
|
|
1cd1c8ea0d | ||
|
|
53ef3bbf4f | ||
|
|
ab7b8aad7c | ||
|
|
c49213282b | ||
|
|
3c87fc5b31 | ||
|
|
9684508e1d | ||
|
|
bb0edae200 | ||
|
|
acb68a4a1e | ||
|
|
46dd6f3243 | ||
|
|
ecab072890 | ||
|
|
148534d3c2 | ||
|
|
1278f16973 | ||
|
|
7d9b3c6c5c | ||
|
|
83dcb5165c | ||
|
|
30862bb82f | ||
|
|
6c0bda8feb | ||
|
|
e14dece206 | ||
|
|
680593d636 | ||
|
|
144440214f | ||
|
|
6667b58a3f | ||
|
|
b55d9533be | ||
|
|
3484fc60e6 | ||
|
|
eac0265522 | ||
|
|
ac74431633 | ||
|
|
4c098200be | ||
|
|
2cf18972f3 | ||
|
|
d522d2a6a9 | ||
|
|
7079ce096f | ||
|
|
5e8c5067b1 | ||
|
|
570ff4e8b6 | ||
|
|
e2f1362a1f | ||
|
|
3519e38211 | ||
|
|
08734250f7 | ||
|
|
e8407f6449 | ||
|
|
04f3400f83 | ||
|
|
89c8b3e7fc | ||
|
|
66294100ec | ||
|
|
8ed8a23c8b | ||
|
|
449b0b03b5 | ||
|
|
d93754bf1d | ||
|
|
a007a61ecc | ||
|
|
e481377317 | ||
|
|
4c5831c7b4 | ||
|
|
fc54b5237f | ||
|
|
f8f42678d1 | ||
|
|
38b1f4128c | ||
|
|
04fb4f88ad | ||
|
|
4675f5df08 | ||
|
|
34ee358d40 | ||
|
|
c4cfd1a3e2 | ||
|
|
5ac4748537 | ||
|
|
2e5ec1d2dc | ||
|
|
bac4c069d7 | ||
|
|
9d4a21a10b | ||
|
|
dbeb41195d | ||
|
|
71f4998458 | ||
|
|
40af5b7574 | ||
|
|
e7a1020f82 | ||
|
|
018e49ed95 | ||
|
|
582cfe9f7c | ||
|
|
db07f740b3 | ||
|
|
bacbd351d7 | ||
|
|
7e2c61c661 | ||
|
|
3df30fd4de | ||
|
|
92789ffdc9 | ||
|
|
09b746cdec | ||
|
|
8ace7b59e3 | ||
|
|
1fc0248d8f | ||
|
|
57bde33bfe | ||
|
|
1b1e558a3b | ||
|
|
c5c7e686d0 | ||
|
|
bd28f880f6 | ||
|
|
fe2ab69773 | ||
|
|
75f9d383cb | ||
|
|
5fefba4583 | ||
|
|
780d126437 | ||
|
|
4057dd9f5b | ||
|
|
b5f8df4bb6 | ||
|
|
5ace10d39f | ||
|
|
07ecdedf0d | ||
|
|
c2ca365312 | ||
|
|
8b9ca08903 | ||
|
|
16e6b588f6 | ||
|
|
3a1d5d8904 | ||
|
|
84d1293fd0 | ||
|
|
a12be7fa77 | ||
|
|
6eee4f678f | ||
|
|
0e53c95c06 | ||
|
|
3ba97ad0dc | ||
|
|
99ff8bc1f5 | ||
|
|
63aa6ee9a5 | ||
|
|
925a42e2c4 | ||
|
|
8dc91cfed4 | ||
|
|
9c6bdeea9d | ||
|
|
f5857aaa0c | ||
|
|
9bc8ac10fa | ||
|
|
3df3879954 | ||
|
|
be1f8e7075 | ||
|
|
d602041ad0 | ||
|
|
23882bcb8e | ||
|
|
311178189f | ||
|
|
5a57526aab | ||
|
|
450dd34f4d | ||
|
|
89ed31a888 | ||
|
|
9fe031efe3 | ||
|
|
baa57266b4 | ||
|
|
3e4818d0ee | ||
|
|
b36747c728 | ||
|
|
fdbe993913 | ||
|
|
f4222e0923 | ||
|
|
f0caea9026 | ||
|
|
9c3c8ff2c4 | ||
|
|
aaefdab0aa | ||
|
|
f18a311bc2 | ||
|
|
ad9705f9c4 | ||
|
|
fb0b626813 | ||
|
|
b48fbf10e1 | ||
|
|
4aa2eab8b6 | ||
|
|
3960a19bcb | ||
|
|
b3cec4781b | ||
|
|
8f0b0bf0d0 | ||
|
|
847672d7f1 | ||
|
|
c7f2962654 |
3
.codecov.yml
Normal file
3
.codecov.yml
Normal file
@@ -0,0 +1,3 @@
|
||||
comment:
|
||||
layout: "condensed_header, condensed_files, condensed_footer"
|
||||
hide_project_coverage: TRUE
|
||||
5
.coveragerc
Normal file
5
.coveragerc
Normal file
@@ -0,0 +1,5 @@
|
||||
[run]
|
||||
omit =
|
||||
*/site-packages/*
|
||||
*/dist-packages/*
|
||||
your_package_name/tests/*
|
||||
20
.dockerignore
Normal file
20
.dockerignore
Normal file
@@ -0,0 +1,20 @@
|
||||
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
|
||||
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
|
||||
# github acions
|
||||
.github/
|
||||
.*ignore
|
||||
.git/
|
||||
# User-specific stuff
|
||||
.idea/
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv*/
|
||||
ENV/
|
||||
.conda/
|
||||
README*.md
|
||||
dashboard/
|
||||
data/
|
||||
82
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
Normal file
82
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
Normal file
@@ -0,0 +1,82 @@
|
||||
name: '🐛 报告 Bug'
|
||||
title: '[Bug]'
|
||||
description: 提交报告帮助我们改进。
|
||||
labels: [ 'bug' ]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
感谢您抽出时间报告问题!请准确解释您的问题。如果可能,请提供一个可复现的片段(这有助于更快地解决问题)。
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 发生了什么
|
||||
description: 描述你遇到的异常
|
||||
placeholder: >
|
||||
一个清晰且具体的描述这个异常是什么。
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 如何复现?
|
||||
description: >
|
||||
复现该问题的步骤
|
||||
placeholder: >
|
||||
如: 1. 打开 '...'
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: AstrBot 版本与部署方式
|
||||
description: >
|
||||
请提供您的 AstrBot 版本和部署方式。
|
||||
placeholder: >
|
||||
如: 3.1.8 Docker, 3.1.7 Windows启动器
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: dropdown
|
||||
attributes:
|
||||
label: 操作系统
|
||||
description: |
|
||||
你在哪个操作系统上遇到了这个问题?
|
||||
multiple: false
|
||||
options:
|
||||
- 'Windows'
|
||||
- 'macOS'
|
||||
- 'Linux'
|
||||
- 'Other'
|
||||
- 'Not sure'
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 额外信息
|
||||
description: >
|
||||
任何额外信息,如报错日志、截图等。
|
||||
placeholder: >
|
||||
请提供完整的报错日志或截图。
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: 你愿意提交 PR 吗?
|
||||
description: >
|
||||
这绝对不是必需的,但我们很乐意在贡献过程中为您提供指导特别是如果你已经很好地理解了如何实现修复。
|
||||
options:
|
||||
- label: 是的,我愿意提交 PR!
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Code of Conduct
|
||||
options:
|
||||
- label: >
|
||||
我已阅读并同意遵守该项目的 [行为准则](https://docs.github.com/zh/site-policy/github-terms/github-community-code-of-conduct)。
|
||||
required: true
|
||||
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: "感谢您填写我们的表单!"
|
||||
42
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
Normal file
42
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
Normal file
@@ -0,0 +1,42 @@
|
||||
|
||||
name: '🎉 功能建议'
|
||||
title: "[Feature]"
|
||||
description: 提交建议帮助我们改进。
|
||||
labels: [ "enhancement" ]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
感谢您抽出时间提出新功能建议,请准确解释您的想法。
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 描述
|
||||
description: 简短描述您的功能建议。
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 使用场景
|
||||
description: 你想要发生什么?
|
||||
placeholder: >
|
||||
一个清晰且具体的描述这个功能的使用场景。
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: 你愿意提交PR吗?
|
||||
description: >
|
||||
这不是必须的,但我们欢迎您的贡献。
|
||||
options:
|
||||
- label: 是的, 我愿意提交PR!
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Code of Conduct
|
||||
options:
|
||||
- label: >
|
||||
我已阅读并同意遵守该项目的 [行为准则](https://docs.github.com/zh/site-policy/github-terms/github-community-code-of-conduct)。
|
||||
required: true
|
||||
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: "感谢您填写我们的表单!"
|
||||
10
.github/PULL_REQUEST_TEMPLATE.md
vendored
Normal file
10
.github/PULL_REQUEST_TEMPLATE.md
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
<!-- 如果有的话,指定这个 PR 要解决的 ISSUE -->
|
||||
修复了 #XYZ
|
||||
|
||||
### Motivation
|
||||
|
||||
<!--解释为什么要改动-->
|
||||
|
||||
### Modifications
|
||||
|
||||
<!--简单解释你的改动-->
|
||||
35
.github/workflows/auto_release.yml
vendored
Normal file
35
.github/workflows/auto_release.yml
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
on:
|
||||
push:
|
||||
tags:
|
||||
- 'v*'
|
||||
workflow_dispatch:
|
||||
|
||||
name: Auto Release
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
contents: write
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Dashboard Build
|
||||
run: |
|
||||
cd dashboard
|
||||
npm install
|
||||
npm run build
|
||||
echo "COMMIT_SHA=$(git rev-parse HEAD)" >> $GITHUB_ENV
|
||||
echo ${{ github.ref_name }} > dist/assets/version
|
||||
zip -r dist.zip dist
|
||||
|
||||
- name: Fetch Changelog
|
||||
run: |
|
||||
echo "changelog=changelogs/${{github.ref_name}}.md" >> "$GITHUB_ENV"
|
||||
|
||||
- name: Create Release
|
||||
uses: ncipollo/release-action@v1
|
||||
with:
|
||||
bodyFile: ${{ env.changelog }}
|
||||
artifacts: "dashboard/dist.zip"
|
||||
93
.github/workflows/codeql.yml
vendored
Normal file
93
.github/workflows/codeql.yml
vendored
Normal file
@@ -0,0 +1,93 @@
|
||||
# For most projects, this workflow file will not need changing; you simply need
|
||||
# to commit it to your repository.
|
||||
#
|
||||
# You may wish to alter this file to override the set of languages analyzed,
|
||||
# or to provide custom queries or build logic.
|
||||
#
|
||||
# ******** NOTE ********
|
||||
# We have attempted to detect the languages in your repository. Please check
|
||||
# the `language` matrix defined below to confirm you have the correct set of
|
||||
# supported CodeQL languages.
|
||||
#
|
||||
name: "CodeQL"
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ "master" ]
|
||||
pull_request:
|
||||
branches: [ "master" ]
|
||||
schedule:
|
||||
- cron: '21 15 * * 5'
|
||||
|
||||
jobs:
|
||||
analyze:
|
||||
name: Analyze (${{ matrix.language }})
|
||||
# Runner size impacts CodeQL analysis time. To learn more, please see:
|
||||
# - https://gh.io/recommended-hardware-resources-for-running-codeql
|
||||
# - https://gh.io/supported-runners-and-hardware-resources
|
||||
# - https://gh.io/using-larger-runners (GitHub.com only)
|
||||
# Consider using larger runners or machines with greater resources for possible analysis time improvements.
|
||||
runs-on: ${{ (matrix.language == 'swift' && 'macos-latest') || 'ubuntu-latest' }}
|
||||
timeout-minutes: ${{ (matrix.language == 'swift' && 120) || 360 }}
|
||||
permissions:
|
||||
# required for all workflows
|
||||
security-events: write
|
||||
|
||||
# required to fetch internal or private CodeQL packs
|
||||
packages: read
|
||||
|
||||
# only required for workflows in private repositories
|
||||
actions: read
|
||||
contents: read
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
include:
|
||||
- language: python
|
||||
build-mode: none
|
||||
# CodeQL supports the following values keywords for 'language': 'c-cpp', 'csharp', 'go', 'java-kotlin', 'javascript-typescript', 'python', 'ruby', 'swift'
|
||||
# Use `c-cpp` to analyze code written in C, C++ or both
|
||||
# Use 'java-kotlin' to analyze code written in Java, Kotlin or both
|
||||
# Use 'javascript-typescript' to analyze code written in JavaScript, TypeScript or both
|
||||
# To learn more about changing the languages that are analyzed or customizing the build mode for your analysis,
|
||||
# see https://docs.github.com/en/code-security/code-scanning/creating-an-advanced-setup-for-code-scanning/customizing-your-advanced-setup-for-code-scanning.
|
||||
# If you are analyzing a compiled language, you can modify the 'build-mode' for that language to customize how
|
||||
# your codebase is analyzed, see https://docs.github.com/en/code-security/code-scanning/creating-an-advanced-setup-for-code-scanning/codeql-code-scanning-for-compiled-languages
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
|
||||
# Initializes the CodeQL tools for scanning.
|
||||
- name: Initialize CodeQL
|
||||
uses: github/codeql-action/init@v3
|
||||
with:
|
||||
languages: ${{ matrix.language }}
|
||||
build-mode: ${{ matrix.build-mode }}
|
||||
# If you wish to specify custom queries, you can do so here or in a config file.
|
||||
# By default, queries listed here will override any specified in a config file.
|
||||
# Prefix the list here with "+" to use these queries and those in the config file.
|
||||
|
||||
# For more details on CodeQL's query packs, refer to: https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/configuring-code-scanning#using-queries-in-ql-packs
|
||||
# queries: security-extended,security-and-quality
|
||||
|
||||
# If the analyze step fails for one of the languages you are analyzing with
|
||||
# "We were unable to automatically build your code", modify the matrix above
|
||||
# to set the build mode to "manual" for that language. Then modify this step
|
||||
# to build your code.
|
||||
# ℹ️ Command-line programs to run using the OS shell.
|
||||
# 📚 See https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#jobsjob_idstepsrun
|
||||
- if: matrix.build-mode == 'manual'
|
||||
shell: bash
|
||||
run: |
|
||||
echo 'If you are using a "manual" build mode for one or more of the' \
|
||||
'languages you are analyzing, replace this with the commands to build' \
|
||||
'your code, for example:'
|
||||
echo ' make bootstrap'
|
||||
echo ' make release'
|
||||
exit 1
|
||||
|
||||
- name: Perform CodeQL Analysis
|
||||
uses: github/codeql-action/analyze@v3
|
||||
with:
|
||||
category: "/language:${{matrix.language}}"
|
||||
45
.github/workflows/coverage_test.yml
vendored
Normal file
45
.github/workflows/coverage_test.yml
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
name: Run tests and upload coverage
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- master
|
||||
paths-ignore:
|
||||
- 'README.md'
|
||||
- 'changelogs/**'
|
||||
- 'dashboard/**'
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
test:
|
||||
name: Run tests and collect coverage
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install -r requirements.txt
|
||||
pip install pytest pytest-cov pytest-asyncio
|
||||
|
||||
- name: Run tests
|
||||
run: |
|
||||
mkdir data
|
||||
mkdir data/plugins
|
||||
mkdir data/config
|
||||
mkdir data/temp
|
||||
export TESTING=true
|
||||
export ZHIPU_API_KEY=${{ secrets.OPENAI_API_KEY }}
|
||||
PYTHONPATH=./ pytest --cov=. tests/ -v -o log_cli=true -o log_level=DEBUG
|
||||
|
||||
- name: Upload results to Codecov
|
||||
uses: codecov/codecov-action@v4
|
||||
with:
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
43
.github/workflows/docker-image.yml
vendored
Normal file
43
.github/workflows/docker-image.yml
vendored
Normal file
@@ -0,0 +1,43 @@
|
||||
name: Docker Image CI/CD
|
||||
|
||||
on:
|
||||
push:
|
||||
tags:
|
||||
- 'v*'
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
publish-docker:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: 拉取源码
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 1
|
||||
|
||||
- name: 设置 QEMU
|
||||
uses: docker/setup-qemu-action@v3
|
||||
|
||||
- name: 设置 Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
|
||||
- name: 登录到 DockerHub
|
||||
uses: docker/login-action@v3
|
||||
with:
|
||||
username: ${{ secrets.DOCKER_HUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKER_HUB_PASSWORD }}
|
||||
|
||||
- name: 构建和推送 Docker hub
|
||||
uses: docker/build-push-action@v6
|
||||
with:
|
||||
context: .
|
||||
platforms: linux/amd64,linux/arm64
|
||||
push: true
|
||||
tags: |
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/astrbot:latest
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/astrbot:${{ github.ref_name }}
|
||||
|
||||
- name: Post build notifications
|
||||
run: echo "Docker image has been built and pushed successfully"
|
||||
|
||||
27
.github/workflows/stale.yml
vendored
Normal file
27
.github/workflows/stale.yml
vendored
Normal file
@@ -0,0 +1,27 @@
|
||||
# This workflow warns and then closes issues and PRs that have had no activity for a specified amount of time.
|
||||
#
|
||||
# You can adjust the behavior by modifying this file.
|
||||
# For more information, see:
|
||||
# https://github.com/actions/stale
|
||||
name: Mark stale issues and pull requests
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: '21 23 * * *'
|
||||
|
||||
jobs:
|
||||
stale:
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
issues: write
|
||||
pull-requests: write
|
||||
|
||||
steps:
|
||||
- uses: actions/stale@v5
|
||||
with:
|
||||
repo-token: ${{ secrets.GITHUB_TOKEN }}
|
||||
stale-issue-message: 'Stale issue message'
|
||||
stale-pr-message: 'Stale pull request message'
|
||||
stale-issue-label: 'no-issue-activity'
|
||||
stale-pr-label: 'no-pr-activity'
|
||||
21
.gitignore
vendored
21
.gitignore
vendored
@@ -1,3 +1,24 @@
|
||||
__pycache__
|
||||
botpy.log
|
||||
.vscode
|
||||
data_v2.db
|
||||
data_v3.db
|
||||
configs/session
|
||||
configs/config.yaml
|
||||
**/.DS_Store
|
||||
temp
|
||||
cmd_config.json
|
||||
data
|
||||
cookies.json
|
||||
logs/
|
||||
addons/plugins
|
||||
.coverage
|
||||
|
||||
|
||||
tests/astrbot_plugin_openai
|
||||
chroma
|
||||
node_modules/
|
||||
.DS_Store
|
||||
package-lock.json
|
||||
package.json
|
||||
venv/*
|
||||
20
Dockerfile
Normal file
20
Dockerfile
Normal file
@@ -0,0 +1,20 @@
|
||||
FROM python:3.10-slim
|
||||
WORKDIR /AstrBot
|
||||
|
||||
COPY . /AstrBot/
|
||||
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
gcc \
|
||||
build-essential \
|
||||
python3-dev \
|
||||
libffi-dev \
|
||||
libssl-dev \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN python -m pip install -r requirements.txt
|
||||
|
||||
EXPOSE 6185
|
||||
EXPOSE 6186
|
||||
|
||||
CMD [ "python", "main.py" ]
|
||||
456
README.md
456
README.md
@@ -1,342 +1,146 @@
|
||||
<p align="center">
|
||||
|
||||

|
||||
|
||||
|
||||
</p>
|
||||
|
||||
<div align="center">
|
||||
|
||||
<img src="https://socialify.git.ci/Soulter/QQChannelChatGPT/image?description=1&forks=1&issues=1&language=1&name=1&owner=1&pattern=Circuit%20Board&stargazers=1&theme=Light" alt="QQChannelChatGPT" width="600" height="300" />
|
||||
_✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨_
|
||||
|
||||
<!-- [](https://www.python.org/)
|
||||
[](https://github.com/Soulter/QQChannelChatGPT/blob/master/LICENSE)
|
||||
 -->
|
||||
|
||||
基于go-cqhttp和官方QQ频道SDK的QQ机器人项目。支持ChatGPT、Claude、HuggingChat、Bard大模型。一次部署,同时使用。
|
||||
[](https://github.com/Soulter/AstrBot/releases/latest)
|
||||
<img src="https://img.shields.io/badge/python-3.10+-blue.svg" alt="python">
|
||||
<a href="https://hub.docker.com/r/soulter/astrbot"><img alt="Docker pull" src="https://img.shields.io/docker/pulls/soulter/astrbot.svg"/></a>
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/QQ群-322154837-purple">
|
||||
[](https://wakatime.com/badge/user/915e5316-99c6-4563-a483-ef186cf000c9/project/018e705a-a1a7-409a-a849-3013485e6c8e)
|
||||
[](https://codecov.io/gh/Soulter/AstrBot)
|
||||
[<img src="https://api.gitsponsors.com/api/badge/img?id=575865240" height="20">](https://api.gitsponsors.com/api/badge/link?p=XEpbdGxlitw/RbcwiTX93UMzNK/jgDYC8NiSzamIPMoKvG2lBFmyXhSS/b0hFoWlBBMX2L5X5CxTDsUdyvcIEHTOfnkXz47UNOZvMwyt5CzbYpq0SEzsSV1OJF1cCo90qC/ZyYKYOWedal3MhZ3ikw==)
|
||||
</a>
|
||||
|
||||
部署文档:https://github.com/Soulter/QQChannelChatGPT/wiki
|
||||
|
||||
欢迎加群讨论 | **QQ群号:322154837** | **频道号: x42d56aki2** |
|
||||
<a href="https://astrbot.app/">查看文档</a> |
|
||||
<a href="https://github.com/Soulter/AstrBot/issues">问题提交</a>
|
||||
</div>
|
||||
|
||||
<!-- <img src="https://user-images.githubusercontent.com/37870767/230417115-9dd3c9d5-6b6b-4928-8fe3-82f559208aab.JPG" width="300"></img> -->
|
||||
AstrBot 是一个松耦合、异步、支持多消息平台部署、具有易用的插件系统和完善的大语言模型(LLM)接入功能的聊天机器人及开发框架。
|
||||
|
||||
## ✨ 主要功能
|
||||
|
||||
1. **大语言模型对话**。支持各种大语言模型,包括 OpenAI API、Google Gemini、Llama、Deepseek、ChatGLM 等,支持接入本地部署的大模型,通过 Ollama、LLMTuner。具有多轮对话、人格情境、多模态能力,支持图片理解、语音转文字(Whisper)。
|
||||
2. **多消息平台接入**。支持接入 QQ(OneBot)、QQ 频道、微信(Gewechat、VChat)、Telegram。后续将支持钉钉、飞书、Discord、WhatsApp、小爱音响。支持速率限制、白名单、关键词过滤、百度内容审核。
|
||||
3. **Agent**。原生支持部分 Agent 能力,如代码执行器、自然语言待办、网页搜索。对接 [Dify 平台](https://astrbot.app/others/dify.html),便捷接入 Dify 智能助手、知识库和 Dify 工作流。
|
||||
4. **插件扩展**。深度优化的插件机制,支持[开发插件](https://astrbot.app/dev/plugin.html)扩展功能,极简开发。已支持安装多个插件。
|
||||
5. **可视化管理面板**。支持可视化修改配置、插件管理、日志查看等功能,降低配置难度。集成 WebChat,可在面板上与大模型对话。
|
||||
6. **高稳定性、高模块化**。基于事件总线和流水线的架构设计,高度模块化,低耦合。
|
||||
|
||||
> [!TIP]
|
||||
> 管理面板在线体验 Demo: [https://demo.astrbot.app/](https://demo.astrbot.app/)
|
||||
>
|
||||
> 用户名: `astrbot`, 密码: `astrbot`。此 Demo 未配置 LLM,因此无法在聊天页使用大模型。
|
||||
|
||||
## ✨ 使用方式
|
||||
|
||||
#### Docker 部署
|
||||
|
||||
请参阅官方文档 [使用 Docker 部署 AstrBot](https://astrbot.app/deploy/astrbot/docker.html#%E4%BD%BF%E7%94%A8-docker-%E9%83%A8%E7%BD%B2-astrbot) 。
|
||||
|
||||
#### Windows 一键安装器部署
|
||||
|
||||
需要电脑上安装有 Python(>3.10)。请参阅官方文档 [使用 Windows 一键安装器部署 AstrBot](https://astrbot.app/deploy/astrbot/windows.html) 。
|
||||
|
||||
#### Replit 部署
|
||||
|
||||
[](https://repl.it/github/Soulter/AstrBot)
|
||||
|
||||
#### CasaOS 部署
|
||||
|
||||
社区贡献的部署方式。
|
||||
|
||||
请参阅官方文档 [通过源码部署 AstrBot](https://astrbot.app/deploy/astrbot/casaos.html) 。
|
||||
|
||||
#### 手动部署
|
||||
|
||||
请参阅官方文档 [通过源码部署 AstrBot](https://astrbot.app/deploy/astrbot/cli.html) 。
|
||||
|
||||
|
||||
## ⚡ 消息平台支持情况
|
||||
|
||||
|
||||
| 平台 | 支持性 | 详情 | 消息类型 |
|
||||
| -------- | ------- | ------- | ------ |
|
||||
| QQ | ✔ | 私聊、群聊 | 文字、图片、语音 |
|
||||
| QQ 官方API | ✔ | 私聊、群聊,QQ 频道私聊、群聊 | 文字、图片 |
|
||||
| 微信 | ✔ | [Gewechat](https://github.com/Devo919/Gewechat)。微信个人号私聊、群聊 | 文字、图片、语音 |
|
||||
| [Telegram](https://github.com/Soulter/astrbot_plugin_telegram) | ✔ | 私聊、群聊 | 文字、图片 |
|
||||
| 微信对话开放平台 | 🚧 | 计划内 | - |
|
||||
| 飞书 | 🚧 | 计划内 | - |
|
||||
| Discord | 🚧 | 计划内 | - |
|
||||
| WhatsApp | 🚧 | 计划内 | - |
|
||||
| 小爱音响 | 🚧 | 计划内 | - |
|
||||
|
||||
## ❤️ 贡献
|
||||
|
||||
欢迎任何 Issues/Pull Requests!只需要将你的更改提交到此项目 :)
|
||||
|
||||
对于新功能的添加,请先通过 Issue 讨论。
|
||||
|
||||
## 🌟 支持
|
||||
|
||||
- Star 这个项目!
|
||||
- 在[爱发电](https://afdian.com/a/soulter)支持我!
|
||||
- 在[微信](https://drive.soulter.top/f/pYfA/d903f4fa49a496fda3f16d2be9e023b5.png)支持我~
|
||||
|
||||
## ✨ Demo
|
||||
|
||||
> [!NOTE]
|
||||
> 代码执行器的文件输入/输出目前仅测试了 Napcat(QQ), Lagrange(QQ)
|
||||
|
||||
<div align='center'>
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/4ee688d9-467d-45c8-99d6-368f9a8a92d8" width="600">
|
||||
|
||||
_✨基于 Docker 的沙箱化代码执行器(Beta 测试中)✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/0378f407-6079-4f64-ae4c-e97ab20611d2" height=500>
|
||||
|
||||
_✨ 多模态、网页搜索、长文本转图片(可配置) ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/8ec12797-e70f-460a-959e-48eca39ca2bb" height=100>
|
||||
|
||||
_✨ 自然语言待办事项 ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/e137a9e1-340a-4bf2-bb2b-771132780735" height=150>
|
||||
<img src="https://github.com/user-attachments/assets/480f5e82-cf6a-4955-a869-0d73137aa6e1" height=150>
|
||||
|
||||
_✨ 插件系统——部分插件展示 ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/592a8630-14c7-4e06-b496-9c0386e4f36c" width=600>
|
||||
|
||||
_✨ 管理面板 ✨_
|
||||
|
||||
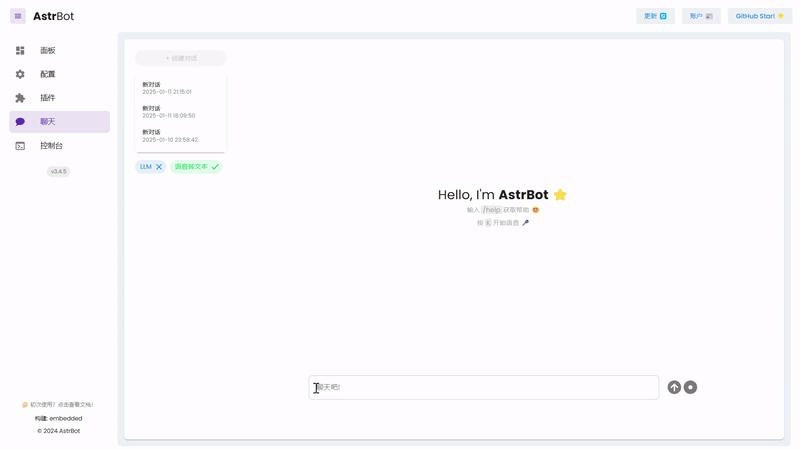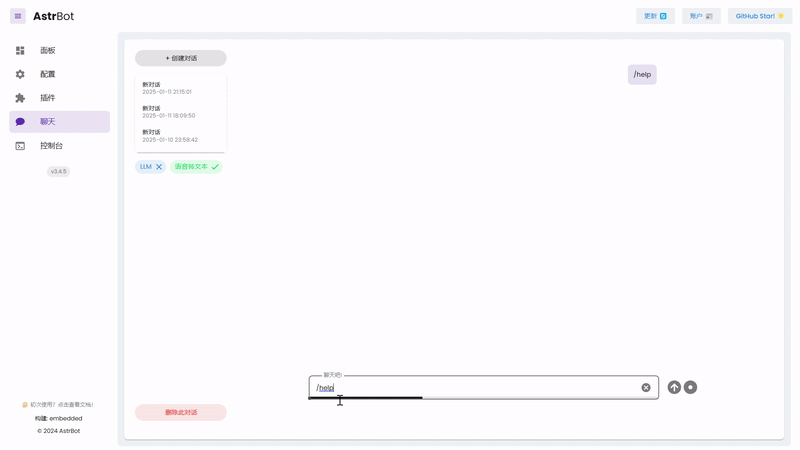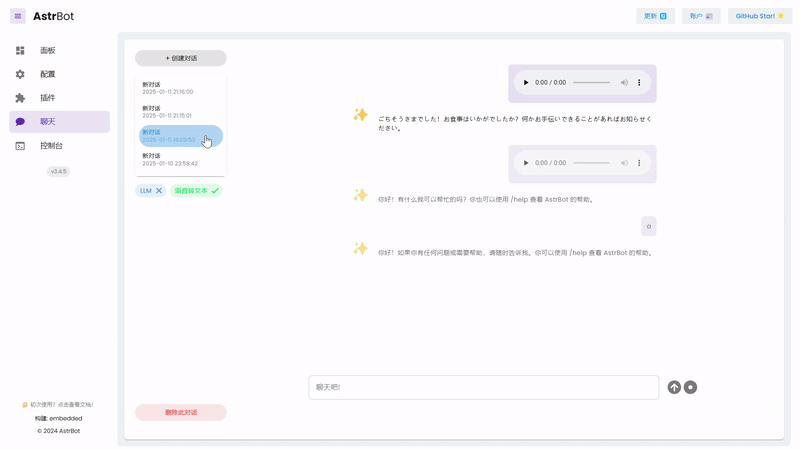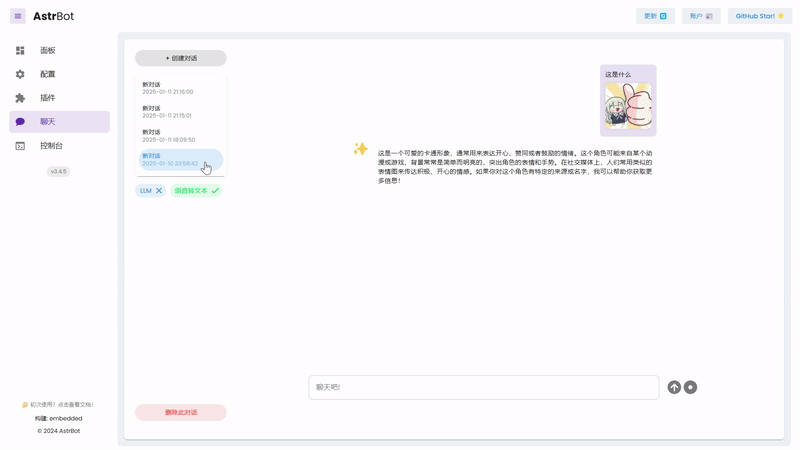
|
||||
|
||||
_✨ 内置 Web Chat,在线与机器人交互 ✨_
|
||||
|
||||
</div>
|
||||
|
||||
## 🤔您可能想了解的
|
||||
- **如何部署?** [帮助文档](https://github.com/Soulter/QQChannelChatGPT/wiki) (部署不成功欢迎进群捞人解决<3)
|
||||
- **go-cqhttp启动不成功、报登录失败?** [在这里搜索解决方法](https://github.com/Mrs4s/go-cqhttp/issues)
|
||||
- **程序闪退/机器人启动不成功?** [提交issue或加群反馈](https://github.com/Soulter/QQChannelChatGPT/issues)
|
||||
- **如何开启ChatGPT、Bard、Claude等语言模型?** [查看帮助](https://github.com/Soulter/QQChannelChatGPT/wiki/%E8%A1%A5%E5%85%85%EF%BC%9A%E5%A6%82%E4%BD%95%E5%BC%80%E5%90%AFChatGPT%E3%80%81Bard%E3%80%81Claude%E7%AD%89%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%EF%BC%9F)
|
||||
## ⭐ Star History
|
||||
|
||||
## 🧩功能:
|
||||
> [!TIP]
|
||||
> 如果本项目对您的生活 / 工作产生了帮助,或者您关注本项目的未来发展,请给项目 Star,这是我维护这个开源项目的动力 <3
|
||||
|
||||
🌍支持的AI语言模型一览:
|
||||
[](https://star-history.com/#soulter/astrbot&Date)
|
||||
|
||||
**文字模型**
|
||||
|
||||
- OpenAI GPT-3模型(原生支持)
|
||||
- OpenAI GPT-3.5模型(原生支持)
|
||||
- OpenAI GPT-4模型(原生支持)
|
||||
- ChatGPT网页版 GPT-3.5模型(免费,原生支持)
|
||||
- ChatGPT网页版 GPT-4模型(需订阅Plus账户,原生支持)
|
||||
- Bing(免费,原生支持)
|
||||
- Claude模型(免费,由[LLMs插件](https://github.com/Soulter/llms)支持)
|
||||
- HuggingChat模型(免费,由[LLMs插件](https://github.com/Soulter/llms)支持)
|
||||
- Google Bard(免费,由[LLMs插件](https://github.com/Soulter/llms)支持)
|
||||
<!-- ## ✨ ATRI [Beta 测试]
|
||||
|
||||
**图片生成**
|
||||
该功能作为插件载入。插件仓库地址:[astrbot_plugin_atri](https://github.com/Soulter/astrbot_plugin_atri)
|
||||
|
||||
- NovelAI/Naifu (免费,由[AIDraw插件](https://github.com/Soulter/aidraw)支持)
|
||||
1. 基于《ATRI ~ My Dear Moments》主角 ATRI 角色台词作为微调数据集的 `Qwen1.5-7B-Chat Lora` 微调模型。
|
||||
2. 长期记忆
|
||||
3. 表情包理解与回复
|
||||
4. TTS
|
||||
-->
|
||||
|
||||
_アトリは、高性能ですから!_
|
||||
|
||||
🌍机器人支持的能力一览:
|
||||
- 同时部署机器人到QQ和QQ频道
|
||||
- 大模型对话
|
||||
- 大模型网页搜索能力 **(目前仅支持OpenAI系的模型,最新版本下使用web on指令打开)**
|
||||
- 插件安装(在QQ或QQ频道聊天框内输入`plugin`了解详情)
|
||||
- 回复文字图片渲染(以图片markdown格式回复,**大幅度降低被风控概率**,需手动在`cmd_config.json`内开启qq_pic_mode)
|
||||
- 人格设置
|
||||
- 关键词回复
|
||||
- 热更新(更新本项目时**仅需**在QQ或QQ频道聊天框内输入`update latest r`)
|
||||
- Windows一键部署(https://github.com/Soulter/QQChatGPTLauncher/releases/latest)
|
||||
|
||||
<!--
|
||||
### 基本功能
|
||||
<details>
|
||||
<summary>✅ 回复符合上下文</summary>
|
||||
|
||||
- 程序向API发送近多次对话内容,模型根据上下文生成回复
|
||||
|
||||
- 你可在`configs/config.yaml`中修改`total_token_limit`来近似控制缓存大小。
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>✅ 超额自动切换</summary>
|
||||
|
||||
- 超额时,程序自动切换openai的key,方便快捷
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
|
||||
<summary>✅ 支持统计频道、消息数量等信息</summary>
|
||||
|
||||
- 实现了简单的统计功能
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>✅ 多并发处理,回复速度快</summary>
|
||||
|
||||
- 使用了协程,理论最高可以支持每个子频道每秒回复5条信息
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>✅ 持久化转储历史记录,重启不丢失</summary>
|
||||
|
||||
- 使用内置的sqlite数据库存储历史记录到本地
|
||||
|
||||
- 方式为定时转储,可在`config.yaml`下修改`dump_history_interval`来修改间隔时间,单位为分钟。
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>✅ 支持多种指令控制</summary>
|
||||
|
||||
- 详见下方`指令功能`
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>✅ 官方API,稳定</summary>
|
||||
|
||||
- 不使用ChatGPT逆向接口,而使用官方API接口,稳定方便。
|
||||
|
||||
- QQ频道机器人框架为QQ官方开源的框架,稳定。
|
||||
|
||||
</details> -->
|
||||
|
||||
<!-- > 关于token:token就相当于是AI中的单词数(但是不等于单词数),`text-davinci-003`模型中最大可以支持`4097`个token。在发送信息时,这个机器人会将用户的历史聊天记录打包发送给ChatGPT,因此,`token`也会相应的累加,为了保证聊天的上下文的逻辑性,就有了缓存token。 -->
|
||||
|
||||
### 🛠️ 插件支持
|
||||
|
||||
本项目支持接入插件。
|
||||
|
||||
> 使用`plugin i 插件GitHub链接`即可安装。
|
||||
|
||||
插件开发教程:https://github.com/Soulter/QQChannelChatGPT/wiki/%E5%9B%9B%E3%80%81%E5%BC%80%E5%8F%91%E6%8F%92%E4%BB%B6
|
||||
|
||||
部分插件:
|
||||
|
||||
- `LLMS`: https://github.com/Soulter/llms | Claude, HuggingChat 大语言模型接入。
|
||||
|
||||
- `GoodPlugins`: https://github.com/Soulter/goodplugins | 随机动漫图片、搜番、喜报生成器等等
|
||||
|
||||
- `sysstat`: https://github.com/Soulter/sysstatqcbot | 查看系统状态
|
||||
|
||||
- `BiliMonitor`: https://github.com/Soulter/BiliMonitor | 订阅B站动态
|
||||
|
||||
- `liferestart`: https://github.com/Soulter/liferestart | 人生重开模拟器
|
||||
|
||||
<!--
|
||||
### 指令
|
||||
|
||||
#### OpenAI官方API
|
||||
在频道内需要先`@`机器人之后再输入指令;在QQ中暂时需要在消息前加上`ai `,不需要@
|
||||
- `/reset`重置prompt
|
||||
- `/his`查看历史记录(每个用户都有独立的会话)
|
||||
- `/his [页码数]`查看不同页码的历史记录。例如`/his 2`查看第2页
|
||||
- `/token`查看当前缓存的总token数
|
||||
- `/count` 查看统计
|
||||
- `/status` 查看chatGPT的配置
|
||||
- `/help` 查看帮助
|
||||
- `/key` 动态添加key
|
||||
- `/set` 人格设置面板
|
||||
- `/keyword nihao 你好` 设置关键词回复。nihao->你好
|
||||
- `/bing` 切换为bing
|
||||
- `/revgpt` 切换为ChatGPT逆向库
|
||||
- `/画` 画画
|
||||
|
||||
#### Bing语言模型
|
||||
- `/reset`重置prompt
|
||||
- `/gpt` 切换为OpenAI官方API
|
||||
- `/revgpt` 切换为ChatGPT逆向库
|
||||
|
||||
#### 逆向ChatGPT库语言模型
|
||||
- `/gpt` 切换为OpenAI官方API
|
||||
- `/bing` 切换为bing
|
||||
|
||||
* 切换模型指令支持临时回复。如`/bing 你好`将会临时使用一次bing模型 -->
|
||||
|
||||
## 📰使用方法:
|
||||
|
||||
使用文档:https://github.com/Soulter/QQChannelChatGPT/wiki
|
||||
|
||||
**Windows用户可以使用启动器一键安装,请前往Release下载最新版本(Beta)**
|
||||
<!--
|
||||
### 安装第三方库
|
||||
|
||||
```shell
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
> ⚠Python版本应>=3.9
|
||||
|
||||
### 配置
|
||||
|
||||
**详细部署教程链接:**https://github.com/Soulter/QQChannelChatGPT/wiki
|
||||
|
||||
### 启动
|
||||
- 启动main.py -->
|
||||
|
||||
## 🙇感谢
|
||||
本项目使用了一下项目:
|
||||
|
||||
[ChatGPT by acheong08](https://github.com/acheong08/ChatGPT)
|
||||
|
||||
[EdgeGPT by acheong08](https://github.com/acheong08/EdgeGPT)
|
||||
|
||||
[go-cqhttp by Mrs4s](https://github.com/Mrs4s/go-cqhttp)
|
||||
|
||||
[nakuru-project by Lxns-Network](https://github.com/Lxns-Network/nakuru-project)
|
||||
|
||||
<!-- ## 👀部分演示截图
|
||||
|
||||
帮助中心(`help`指令)
|
||||

|
||||
|
||||
-->
|
||||
## ⚙配置文件说明:
|
||||
```yaml
|
||||
# 如果你不知道怎么部署,请查看https://github.com/Soulter/QQChannelChatGPT/wiki
|
||||
# 不一定需要key了,如果你没有key但有openAI账号或者必应账号,可以考虑使用下面的逆向库
|
||||
|
||||
|
||||
###############平台设置#################
|
||||
|
||||
# QQ频道机器人
|
||||
# QQ开放平台的appid和令牌
|
||||
# q.qq.com
|
||||
# enable为true则启用,false则不启用
|
||||
qqbot:
|
||||
enable: true
|
||||
appid:
|
||||
token:
|
||||
|
||||
# QQ机器人
|
||||
# enable为true则启用,false则不启用
|
||||
# 需要安装GO-CQHTTP配合使用。
|
||||
# 文档:https://docs.go-cqhttp.org/
|
||||
# 请将go-cqhttp的配置文件的sever部分粘贴为以下内容,否则无法使用
|
||||
# 请先启动go-cqhttp再启动本程序
|
||||
#
|
||||
# servers:
|
||||
# - http:
|
||||
# host: 127.0.0.1
|
||||
# version: 0
|
||||
# port: 5700
|
||||
# timeout: 5
|
||||
# - ws:
|
||||
# address: 127.0.0.1:6700
|
||||
# middlewares:
|
||||
# <<: *default
|
||||
gocqbot:
|
||||
enable: false
|
||||
|
||||
# 设置是否一个人一个会话
|
||||
uniqueSessionMode: false
|
||||
# QChannelBot 的版本,请勿修改此字段,否则可能产生一些bug
|
||||
version: 3.0
|
||||
# [Beta] 转储历史记录时间间隔(分钟)
|
||||
dump_history_interval: 10
|
||||
# 一个用户只能在time秒内发送count条消息
|
||||
limit:
|
||||
time: 60
|
||||
count: 5
|
||||
# 公告
|
||||
notice: "此机器人由Github项目QQChannelChatGPT驱动。"
|
||||
# 是否打开私信功能
|
||||
# 设置为true则频道成员可以私聊机器人。
|
||||
# 设置为false则频道成员不能私聊机器人。
|
||||
direct_message_mode: true
|
||||
|
||||
# 系统代理
|
||||
# http_proxy: http://localhost:7890
|
||||
# https_proxy: http://localhost:7890
|
||||
|
||||
# 自定义回复前缀,如[Rev]或其他,务必加引号以防止不必要的bug。
|
||||
reply_prefix:
|
||||
openai_official: "[GPT]"
|
||||
rev_chatgpt: "[Rev]"
|
||||
rev_edgegpt: "[RevBing]"
|
||||
|
||||
# 百度内容审核服务
|
||||
# 新用户免费5万次调用。https://cloud.baidu.com/doc/ANTIPORN/index.html
|
||||
baidu_aip:
|
||||
enable: false
|
||||
app_id:
|
||||
api_key:
|
||||
secret_key:
|
||||
|
||||
|
||||
|
||||
|
||||
###############语言模型设置#################
|
||||
|
||||
|
||||
# OpenAI官方API
|
||||
# 注意:已支持多key自动切换,方法:
|
||||
# key:
|
||||
# - sk-xxxxxx
|
||||
# - sk-xxxxxx
|
||||
# 在下方非注释的地方使用以上格式
|
||||
# 关于api_base:可以使用一些云函数(如腾讯、阿里)来避免国内被墙的问题。
|
||||
# 详见:
|
||||
# https://github.com/Ice-Hazymoon/openai-scf-proxy
|
||||
# https://github.com/Soulter/QQChannelChatGPT/issues/42
|
||||
# 设置为none则表示使用官方默认api地址
|
||||
openai:
|
||||
key:
|
||||
-
|
||||
api_base: none
|
||||
# 这里是GPT配置,语言模型默认使用gpt-3.5-turbo
|
||||
chatGPTConfigs:
|
||||
model: gpt-3.5-turbo
|
||||
max_tokens: 3000
|
||||
temperature: 0.9
|
||||
top_p: 1
|
||||
frequency_penalty: 0
|
||||
presence_penalty: 0
|
||||
|
||||
total_tokens_limit: 5000
|
||||
|
||||
# 逆向文心一言【暂时不可用,请勿使用】
|
||||
rev_ernie:
|
||||
enable: false
|
||||
|
||||
# 逆向New Bing
|
||||
# 需要在项目根目录下创建cookies.json并粘贴cookies进去。
|
||||
# 详见:https://soulter.top/posts/qpdg.html
|
||||
rev_edgegpt:
|
||||
enable: false
|
||||
|
||||
# 逆向ChatGPT库
|
||||
# https://github.com/acheong08/ChatGPT
|
||||
# 优点:免费(无免费额度限制);
|
||||
# 缺点:速度相对慢。OpenAI 速率限制:免费帐户每小时 50 个请求。您可以通过多帐户循环来绕过它
|
||||
# enable设置为true后,将会停止使用上面正常的官方API调用而使用本逆向项目
|
||||
#
|
||||
# 多账户可以保证每个请求都能得到及时的回复。
|
||||
# 关于account的格式
|
||||
# account:
|
||||
# - email: 第1个账户
|
||||
# password: 第1个账户密码
|
||||
# - email: 第2个账户
|
||||
# password: 第2个账户密码
|
||||
# - ....
|
||||
# 支持使用access_token登录
|
||||
# 例:
|
||||
# - session_token: xxxxx
|
||||
# - access_token: xxxx
|
||||
# 请严格按照上面这个格式填写。
|
||||
# 逆向ChatGPT库的email-password登录方式不工作,建议使用access_token登录
|
||||
# 获取access_token的方法,详见:https://soulter.top/posts/qpdg.html
|
||||
rev_ChatGPT:
|
||||
enable: false
|
||||
account:
|
||||
- access_token:
|
||||
```
|
||||
|
||||
@@ -1,26 +0,0 @@
|
||||
from aip import AipContentCensor
|
||||
|
||||
class BaiduJudge:
|
||||
def __init__(self, baidu_configs) -> None:
|
||||
if 'app_id' in baidu_configs and 'api_key' in baidu_configs and 'secret_key' in baidu_configs:
|
||||
self.app_id = str(baidu_configs['app_id'])
|
||||
self.api_key = baidu_configs['api_key']
|
||||
self.secret_key = baidu_configs['secret_key']
|
||||
self.client = AipContentCensor(self.app_id, self.api_key, self.secret_key)
|
||||
else:
|
||||
raise ValueError("Baidu configs error! 请填写百度内容审核服务相关配置!")
|
||||
def judge(self, text):
|
||||
res = self.client.textCensorUserDefined(text)
|
||||
if 'conclusionType' not in res:
|
||||
return False, "百度审核服务未知错误"
|
||||
if res['conclusionType'] == 1:
|
||||
return True, "合规"
|
||||
else:
|
||||
if 'data' not in res:
|
||||
return False, "百度审核服务未知错误"
|
||||
count = len(res['data'])
|
||||
info = f"百度审核服务发现 {count} 处违规:\n"
|
||||
for i in res['data']:
|
||||
info += f"{i['msg']};\n"
|
||||
info += "\n判断结果:"+res['conclusion']
|
||||
return False, info
|
||||
@@ -1,5 +0,0 @@
|
||||
# helloworld
|
||||
|
||||
QQChannelChatGPT项目的测试插件
|
||||
|
||||
A test plugin for QQChannelChatGPT plugin feature
|
||||
@@ -1,79 +0,0 @@
|
||||
from nakuru.entities.components import *
|
||||
from nakuru import (
|
||||
GroupMessage,
|
||||
FriendMessage
|
||||
)
|
||||
from botpy.message import Message, DirectMessage
|
||||
from model.platform.qq import QQ
|
||||
import time
|
||||
import threading
|
||||
|
||||
class HelloWorldPlugin:
|
||||
"""
|
||||
初始化函数, 可以选择直接pass
|
||||
"""
|
||||
def __init__(self) -> None:
|
||||
self.myThread = None # 线程对象,如果要使用线程,需要在此处定义。在run处定义会被释放掉
|
||||
print("这是HelloWorld测试插件, 发送 helloworld 即可触发此插件。")
|
||||
|
||||
"""
|
||||
入口函数,机器人会调用此函数。
|
||||
参数规范: message: 消息文本; role: 身份; platform: 消息平台; message_obj: 消息对象; qq_platform: QQ平台对象,可以通过调用qq_platform.send()直接发送消息。详见Helloworld插件示例
|
||||
参数详情: role为admin或者member; platform为qqchan或者gocq; message_obj为nakuru的GroupMessage对象或者FriendMessage对象或者频道的Message, DirectMessage对象。
|
||||
返回规范: bool: 是否hit到此插件(所有的消息均会调用每一个载入的插件, 如果没有hit到, 则应返回False)
|
||||
Tuple: None或者长度为3的元组。当没有hit到时, 返回None. hit到时, 第1个参数为指令是否调用成功, 第2个参数为返回的消息文本或者gocq的消息链列表, 第3个参数为指令名称
|
||||
例子:做一个名为"yuanshen"的插件;当接收到消息为“原神 可莉”, 如果不想要处理此消息,则返回False, None;如果想要处理,但是执行失败了,返回True, tuple([False, "请求失败啦~", "yuanshen"])
|
||||
;执行成功了,返回True, tuple([True, "结果文本", "yuanshen"])
|
||||
"""
|
||||
def run(self, message: str, role: str, platform: str, message_obj, qq_platform: QQ):
|
||||
|
||||
if platform == "gocq":
|
||||
"""
|
||||
QQ平台指令处理逻辑
|
||||
"""
|
||||
img_url = "https://gchat.qpic.cn/gchatpic_new/905617992/720871955-2246763964-C6EE1A52CC668EC982453065C4FA8747/0?term=2&is_origin=0"
|
||||
if message == "helloworld":
|
||||
return True, tuple([True, [Plain("Hello World!!"), Image.fromURL(url=img_url)], "helloworld"])
|
||||
elif message == "hiloop":
|
||||
if self.myThread is None:
|
||||
self.myThread = threading.Thread(target=self.helloworldThread, args=(message_obj, qq_platform))
|
||||
self.myThread.start()
|
||||
return True, tuple([True, [Plain("A lot of Helloworlds!!"), Image.fromURL(url=img_url)], "helloworld"])
|
||||
else:
|
||||
return False, None
|
||||
elif platform == "qqchan":
|
||||
"""
|
||||
频道处理逻辑(频道暂时只支持回复字符串类型的信息,返回的信息都会被转成字符串,如果不想处理某一个平台的信息,直接返回False, None就行)
|
||||
"""
|
||||
if message == "helloworld":
|
||||
return True, tuple([True, "Hello World!!", "helloworld"])
|
||||
else:
|
||||
return False, None
|
||||
"""
|
||||
帮助函数,当用户输入 plugin v 插件名称 时,会调用此函数,返回帮助信息
|
||||
返回参数要求(必填):dict{
|
||||
"name": str, # 插件名称
|
||||
"desc": str, # 插件简短描述
|
||||
"help": str, # 插件帮助信息
|
||||
"version": str, # 插件版本
|
||||
"author": str, # 插件作者
|
||||
}
|
||||
"""
|
||||
def info(self):
|
||||
return {
|
||||
"name": "helloworld",
|
||||
"desc": "测试插件",
|
||||
"help": "测试插件, 回复helloworld即可触发",
|
||||
"version": "v1.0.1 beta",
|
||||
"author": "Soulter"
|
||||
}
|
||||
|
||||
def helloworldThread(self, meseage_obj, qq_platform: QQ):
|
||||
while True:
|
||||
qq_platform.send(meseage_obj, [Plain("Hello World!!")]) # 第一个参数可以是message_obj, 也可以是qq群号
|
||||
time.sleep(3) # 睡眠3秒。 用while True一定要记得sleep,不然会卡死
|
||||
|
||||
|
||||
# 热知识:检测消息开头指令,使用以下方法
|
||||
# if message.startswith("原神"):
|
||||
# pass
|
||||
2
astrbot/__init__.py
Normal file
2
astrbot/__init__.py
Normal file
@@ -0,0 +1,2 @@
|
||||
from .core.log import LogManager
|
||||
logger = LogManager.GetLogger(log_name='astrbot')
|
||||
13
astrbot/api/__init__.py
Normal file
13
astrbot/api/__init__.py
Normal file
@@ -0,0 +1,13 @@
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from astrbot import logger
|
||||
from astrbot.core import html_renderer
|
||||
from astrbot.core import sp
|
||||
from astrbot.core.star.register import register_llm_tool as llm_tool
|
||||
|
||||
__all__ = [
|
||||
"AstrBotConfig",
|
||||
"logger",
|
||||
"html_renderer",
|
||||
"llm_tool",
|
||||
"sp"
|
||||
]
|
||||
40
astrbot/api/all.py
Normal file
40
astrbot/api/all.py
Normal file
@@ -0,0 +1,40 @@
|
||||
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from astrbot import logger
|
||||
from astrbot.core import html_renderer
|
||||
from astrbot.core.star.register import register_llm_tool as llm_tool
|
||||
|
||||
# event
|
||||
from astrbot.core.message.message_event_result import (
|
||||
MessageEventResult, MessageChain, CommandResult, EventResultType
|
||||
)
|
||||
from astrbot.core.platform import AstrMessageEvent
|
||||
|
||||
# star register
|
||||
from astrbot.core.star.register import (
|
||||
register_command as command,
|
||||
register_command_group as command_group,
|
||||
register_event_message_type as event_message_type,
|
||||
register_regex as regex,
|
||||
register_platform_adapter_type as platform_adapter_type,
|
||||
)
|
||||
from astrbot.core.star.filter.event_message_type import EventMessageTypeFilter, EventMessageType
|
||||
from astrbot.core.star.filter.platform_adapter_type import PlatformAdapterTypeFilter, PlatformAdapterType
|
||||
from astrbot.core.star.register import (
|
||||
register_star as register # 注册插件(Star)
|
||||
)
|
||||
from astrbot.core.star import Context, Star
|
||||
from astrbot.core.star.config import *
|
||||
|
||||
|
||||
# provider
|
||||
from astrbot.core.provider import Provider, Personality, ProviderMetaData
|
||||
|
||||
# platform
|
||||
from astrbot.core.platform import (
|
||||
AstrMessageEvent, Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
)
|
||||
|
||||
from astrbot.core.platform.register import register_platform_adapter
|
||||
|
||||
from .message_components import *
|
||||
18
astrbot/api/event/__init__.py
Normal file
18
astrbot/api/event/__init__.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from astrbot.core.message.message_event_result import (
|
||||
MessageEventResult,
|
||||
MessageChain,
|
||||
CommandResult,
|
||||
EventResultType,
|
||||
ResultContentType,
|
||||
)
|
||||
|
||||
from astrbot.core.platform import AstrMessageEvent
|
||||
|
||||
__all__ = [
|
||||
"MessageEventResult",
|
||||
"MessageChain",
|
||||
"CommandResult",
|
||||
"EventResultType",
|
||||
"AstrMessageEvent",
|
||||
"ResultContentType",
|
||||
]
|
||||
35
astrbot/api/event/filter/__init__.py
Normal file
35
astrbot/api/event/filter/__init__.py
Normal file
@@ -0,0 +1,35 @@
|
||||
from astrbot.core.star.register import (
|
||||
register_command as command,
|
||||
register_command_group as command_group,
|
||||
register_event_message_type as event_message_type,
|
||||
register_regex as regex,
|
||||
register_platform_adapter_type as platform_adapter_type,
|
||||
register_permission_type as permission_type,
|
||||
register_on_llm_request as on_llm_request,
|
||||
register_llm_tool as llm_tool,
|
||||
register_on_decorating_result as on_decorating_result,
|
||||
register_after_message_sent as after_message_sent
|
||||
)
|
||||
|
||||
from astrbot.core.star.filter.event_message_type import EventMessageTypeFilter, EventMessageType
|
||||
from astrbot.core.star.filter.platform_adapter_type import PlatformAdapterTypeFilter, PlatformAdapterType
|
||||
from astrbot.core.star.filter.permission import PermissionTypeFilter, PermissionType
|
||||
|
||||
__all__ = [
|
||||
'command',
|
||||
'command_group',
|
||||
'event_message_type',
|
||||
'regex',
|
||||
'platform_adapter_type',
|
||||
'permission_type',
|
||||
'EventMessageTypeFilter',
|
||||
'EventMessageType',
|
||||
'PlatformAdapterTypeFilter',
|
||||
'PlatformAdapterType',
|
||||
'PermissionTypeFilter',
|
||||
'PermissionType',
|
||||
'on_llm_request',
|
||||
'llm_tool',
|
||||
'on_decorating_result',
|
||||
'after_message_sent'
|
||||
]
|
||||
1
astrbot/api/message_components.py
Normal file
1
astrbot/api/message_components.py
Normal file
@@ -0,0 +1 @@
|
||||
from astrbot.core.message.components import *
|
||||
5
astrbot/api/platform/__init__.py
Normal file
5
astrbot/api/platform/__init__.py
Normal file
@@ -0,0 +1,5 @@
|
||||
from astrbot.core.platform import (
|
||||
AstrMessageEvent, Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
)
|
||||
|
||||
from astrbot.core.platform.register import register_platform_adapter
|
||||
2
astrbot/api/provider/__init__.py
Normal file
2
astrbot/api/provider/__init__.py
Normal file
@@ -0,0 +1,2 @@
|
||||
from astrbot.core.provider import Provider, STTProvider, Personality
|
||||
from astrbot.core.provider.entites import ProviderRequest, ProviderType, ProviderMetaData
|
||||
6
astrbot/api/star/__init__.py
Normal file
6
astrbot/api/star/__init__.py
Normal file
@@ -0,0 +1,6 @@
|
||||
from astrbot.core.star.register import (
|
||||
register_star as register # 注册插件(Star)
|
||||
)
|
||||
|
||||
from astrbot.core.star import Context, Star
|
||||
from astrbot.core.star.config import *
|
||||
25
astrbot/core/__init__.py
Normal file
25
astrbot/core/__init__.py
Normal file
@@ -0,0 +1,25 @@
|
||||
import os
|
||||
import asyncio
|
||||
from .log import LogManager, LogBroker
|
||||
from astrbot.core.utils.t2i.renderer import HtmlRenderer
|
||||
from astrbot.core.utils.shared_preferences import SharedPreferences
|
||||
from astrbot.core.utils.pip_installer import PipInstaller
|
||||
from astrbot.core.db.sqlite import SQLiteDatabase
|
||||
from astrbot.core.config.default import DB_PATH
|
||||
from astrbot.core.config import AstrBotConfig
|
||||
|
||||
os.makedirs("data", exist_ok=True)
|
||||
|
||||
astrbot_config = AstrBotConfig()
|
||||
html_renderer = HtmlRenderer()
|
||||
logger = LogManager.GetLogger(log_name='astrbot')
|
||||
|
||||
if os.environ.get('TESTING', ""):
|
||||
logger.setLevel('DEBUG')
|
||||
|
||||
db_helper = SQLiteDatabase(DB_PATH)
|
||||
sp = SharedPreferences() # 简单的偏好设置存储
|
||||
pip_installer = PipInstaller(astrbot_config.get('pip_install_arg', ''))
|
||||
web_chat_queue = asyncio.Queue(maxsize=32)
|
||||
web_chat_back_queue = asyncio.Queue(maxsize=32)
|
||||
WEBUI_SK = "Advanced_System_for_Text_Response_and_Bot_Operations_Tool"
|
||||
2
astrbot/core/config/__init__.py
Normal file
2
astrbot/core/config/__init__.py
Normal file
@@ -0,0 +1,2 @@
|
||||
from .default import DEFAULT_CONFIG, VERSION, DB_PATH
|
||||
from .astrbot_config import *
|
||||
84
astrbot/core/config/astrbot_config.py
Normal file
84
astrbot/core/config/astrbot_config.py
Normal file
@@ -0,0 +1,84 @@
|
||||
import os
|
||||
import json
|
||||
import logging
|
||||
import enum
|
||||
from .default import DEFAULT_CONFIG
|
||||
from typing import Dict
|
||||
|
||||
ASTRBOT_CONFIG_PATH = "data/cmd_config.json"
|
||||
logger = logging.getLogger("astrbot")
|
||||
|
||||
class RateLimitStrategy(enum.Enum):
|
||||
STALL = "stall"
|
||||
DISCARD = "discard"
|
||||
|
||||
class AstrBotConfig(dict):
|
||||
'''从配置文件中加载的配置,支持直接通过点号操作符访问配置项'''
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
if not self.check_exist():
|
||||
'''不存在时载入默认配置'''
|
||||
with open(ASTRBOT_CONFIG_PATH, "w", encoding="utf-8-sig") as f:
|
||||
json.dump(DEFAULT_CONFIG, f, indent=4, ensure_ascii=False)
|
||||
|
||||
with open(ASTRBOT_CONFIG_PATH, "r", encoding="utf-8-sig") as f:
|
||||
conf_str = f.read()
|
||||
if conf_str.startswith(u'/ufeff'): # remove BOM
|
||||
conf_str = conf_str.encode('utf8')[3:].decode('utf8')
|
||||
conf = json.loads(conf_str)
|
||||
|
||||
# 检查配置完整性,并插入
|
||||
has_new = self.check_config_integrity(DEFAULT_CONFIG, conf)
|
||||
self.update(conf)
|
||||
if has_new:
|
||||
self.save_config()
|
||||
|
||||
self.update(conf)
|
||||
|
||||
def check_config_integrity(self, refer_conf: Dict, conf: Dict, path=""):
|
||||
'''检查配置完整性,如果有新的配置项则返回 True'''
|
||||
has_new = False
|
||||
for key, value in refer_conf.items():
|
||||
if key not in conf:
|
||||
# logger.info(f"检查到配置项 {path + "." + key if path else key} 不存在,已插入默认值 {value}")
|
||||
path_ = path + "." + key if path else key
|
||||
logger.info(f"检查到配置项 {path_} 不存在,已插入默认值 {value}")
|
||||
conf[key] = value
|
||||
has_new = True
|
||||
else:
|
||||
if conf[key] is None:
|
||||
conf[key] = value
|
||||
has_new = True
|
||||
elif isinstance(value, dict):
|
||||
has_new |= self.check_config_integrity(value, conf[key], path + "." + key if path else key)
|
||||
return has_new
|
||||
|
||||
def save_config(self, replace_config: Dict = None):
|
||||
'''将配置写入文件
|
||||
|
||||
如果传入 replace_config,则将配置替换为 replace_config
|
||||
'''
|
||||
if replace_config:
|
||||
self.update(replace_config)
|
||||
with open(ASTRBOT_CONFIG_PATH, "w", encoding="utf-8-sig") as f:
|
||||
json.dump(self, f, indent=2, ensure_ascii=False)
|
||||
|
||||
def __getattr__(self, item):
|
||||
try:
|
||||
return self[item]
|
||||
except KeyError:
|
||||
return None
|
||||
|
||||
def __delattr__(self, key):
|
||||
try:
|
||||
del self[key]
|
||||
self.save_config()
|
||||
except KeyError:
|
||||
raise AttributeError(f"没有找到 Key: '{key}'")
|
||||
|
||||
def __setattr__(self, key, value):
|
||||
self[key] = value
|
||||
|
||||
def check_exist(self) -> bool:
|
||||
return os.path.exists(ASTRBOT_CONFIG_PATH)
|
||||
785
astrbot/core/config/default.py
Normal file
785
astrbot/core/config/default.py
Normal file
@@ -0,0 +1,785 @@
|
||||
"""
|
||||
如需修改配置,请在 `data/cmd_config.json` 中修改或者在管理面板中可视化修改。
|
||||
"""
|
||||
|
||||
VERSION = "3.4.13"
|
||||
DB_PATH = "data/data_v3.db"
|
||||
|
||||
# 默认配置
|
||||
DEFAULT_CONFIG = {
|
||||
"config_version": 2,
|
||||
"platform_settings": {
|
||||
"unique_session": False,
|
||||
"rate_limit": {
|
||||
"time": 60,
|
||||
"count": 30,
|
||||
"strategy": "stall", # stall, discard
|
||||
},
|
||||
"reply_prefix": "",
|
||||
"forward_threshold": 200,
|
||||
"enable_id_white_list": True,
|
||||
"id_whitelist": [],
|
||||
"id_whitelist_log": True,
|
||||
"wl_ignore_admin_on_group": True,
|
||||
"wl_ignore_admin_on_friend": True,
|
||||
"reply_with_mention": False,
|
||||
"reply_with_quote": False,
|
||||
"path_mapping": [],
|
||||
"segmented_reply": {
|
||||
"enable": False,
|
||||
"only_llm_result": True,
|
||||
"interval": "1.5,3.5",
|
||||
"regex": ".*?[。?!~…]+|.+$"
|
||||
}
|
||||
},
|
||||
"provider": [],
|
||||
"provider_settings": {
|
||||
"enable": True,
|
||||
"wake_prefix": "",
|
||||
"web_search": False,
|
||||
"identifier": False,
|
||||
"datetime_system_prompt": True,
|
||||
"default_personality": "default",
|
||||
"prompt_prefix": "",
|
||||
},
|
||||
"provider_stt_settings": {
|
||||
"enable": False,
|
||||
"provider_id": "",
|
||||
},
|
||||
"provider_tts_settings": {
|
||||
"enable": False,
|
||||
"provider_id": "",
|
||||
},
|
||||
"content_safety": {
|
||||
"internal_keywords": {"enable": True, "extra_keywords": []},
|
||||
"baidu_aip": {"enable": False, "app_id": "", "api_key": "", "secret_key": ""},
|
||||
},
|
||||
"admins_id": [],
|
||||
"t2i": False,
|
||||
"http_proxy": "",
|
||||
"dashboard": {
|
||||
"enable": True,
|
||||
"username": "astrbot",
|
||||
"password": "77b90590a8945a7d36c963981a307dc9",
|
||||
},
|
||||
"platform": [],
|
||||
"wake_prefix": ["/"],
|
||||
"log_level": "INFO",
|
||||
"t2i_endpoint": "",
|
||||
"pip_install_arg": "",
|
||||
"plugin_repo_mirror": "",
|
||||
"knowledge_db": {},
|
||||
"persona": [
|
||||
{
|
||||
"name": "default",
|
||||
"prompt": "如果用户寻求帮助或者打招呼,请告诉他可以用 /help 查看 AstrBot 帮助。",
|
||||
"begin_dialogs": [],
|
||||
"mood_imitation_dialogs": [],
|
||||
}
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
# 配置项的中文描述、值类型
|
||||
CONFIG_METADATA_2 = {
|
||||
"platform_group": {
|
||||
"name": "消息平台",
|
||||
"metadata": {
|
||||
"platform": {
|
||||
"description": "消息平台适配器",
|
||||
"type": "list",
|
||||
"config_template": {
|
||||
"qq_official(QQ)": {
|
||||
"id": "default",
|
||||
"type": "qq_official",
|
||||
"enable": False,
|
||||
"appid": "",
|
||||
"secret": "",
|
||||
"enable_group_c2c": True,
|
||||
"enable_guild_direct_message": True,
|
||||
},
|
||||
"aiocqhtp(QQ)": {
|
||||
"id": "default",
|
||||
"type": "aiocqhttp",
|
||||
"enable": False,
|
||||
"ws_reverse_host": "",
|
||||
"ws_reverse_port": 6199,
|
||||
},
|
||||
"vchat(微信)": {"id": "default", "type": "vchat", "enable": False},
|
||||
"gewechat(微信)": {
|
||||
"id": "gwchat",
|
||||
"type": "gewechat",
|
||||
"enable": False,
|
||||
"base_url": "http://localhost:2531",
|
||||
"nickname": "soulter",
|
||||
"host": "localhost",
|
||||
"port": 11451,
|
||||
},
|
||||
},
|
||||
"items": {
|
||||
"id": {
|
||||
"description": "ID",
|
||||
"type": "string",
|
||||
"hint": "提供商 ID 名,用于在多实例下方便管理和识别。自定义,ID 不能重复。",
|
||||
},
|
||||
"type": {
|
||||
"description": "适配器类型",
|
||||
"type": "string",
|
||||
"invisible": True,
|
||||
},
|
||||
"enable": {
|
||||
"description": "启用",
|
||||
"type": "bool",
|
||||
"hint": "是否启用该适配器。未启用的适配器对应的消息平台将不会接收到消息。",
|
||||
},
|
||||
"appid": {
|
||||
"description": "appid",
|
||||
"type": "string",
|
||||
"hint": "必填项。QQ 官方机器人平台的 appid。如何获取请参考文档。",
|
||||
},
|
||||
"secret": {
|
||||
"description": "secret",
|
||||
"type": "string",
|
||||
"hint": "必填项。QQ 官方机器人平台的 secret。如何获取请参考文档。",
|
||||
},
|
||||
"enable_group_c2c": {
|
||||
"description": "启用消息列表单聊",
|
||||
"type": "bool",
|
||||
"hint": "启用后,机器人可以接收到 QQ 消息列表中的私聊消息。你可能需要在 QQ 机器人平台上通过扫描二维码的方式添加机器人为你的好友。详见文档。",
|
||||
},
|
||||
"enable_guild_direct_message": {
|
||||
"description": "启用频道私聊",
|
||||
"type": "bool",
|
||||
"hint": "启用后,机器人可以接收到频道的私聊消息。",
|
||||
},
|
||||
"ws_reverse_host": {
|
||||
"description": "反向 Websocket 主机地址",
|
||||
"type": "string",
|
||||
"hint": "aiocqhttp 适配器的反向 Websocket 服务器 IP 地址,不包含端口号。",
|
||||
},
|
||||
"ws_reverse_port": {
|
||||
"description": "反向 Websocket 端口",
|
||||
"type": "int",
|
||||
"hint": "aiocqhttp 适配器的反向 Websocket 端口。",
|
||||
},
|
||||
},
|
||||
},
|
||||
"platform_settings": {
|
||||
"description": "平台设置",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"unique_session": {
|
||||
"description": "会话隔离",
|
||||
"type": "bool",
|
||||
"hint": "启用后,在群组或者频道中,每个人的消息上下文都是独立的。",
|
||||
},
|
||||
"rate_limit": {
|
||||
"description": "速率限制",
|
||||
"hint": "每个会话在 `time` 秒内最多只能发送 `count` 条消息。",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"time": {"description": "消息速率限制时间", "type": "int"},
|
||||
"count": {"description": "消息速率限制计数", "type": "int"},
|
||||
"strategy": {
|
||||
"description": "速率限制策略",
|
||||
"type": "string",
|
||||
"options": ["stall", "discard"],
|
||||
"hint": "当消息速率超过限制时的处理策略。stall 为等待,discard 为丢弃。",
|
||||
},
|
||||
},
|
||||
},
|
||||
"segmented_reply": {
|
||||
"description": "分段回复",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"enable": {
|
||||
"description": "启用分段回复",
|
||||
"type": "bool",
|
||||
},
|
||||
"only_llm_result": {
|
||||
"description": "仅对 LLM 结果分段",
|
||||
"type": "bool",
|
||||
},
|
||||
"interval": {
|
||||
"description": "随机间隔时间(秒)",
|
||||
"type": "string",
|
||||
"hint": "每一段回复的间隔时间,格式为 `最小时间,最大时间`。如 `0.75,2.5`",
|
||||
},
|
||||
"regex": {
|
||||
"description": "正则表达式",
|
||||
"type": "string",
|
||||
"obvious_hint": True,
|
||||
"hint": "用于分隔一段消息。默认情况下会根据句号、问号等标点符号分隔。re.findall(r'<regex>', text)",
|
||||
},
|
||||
},
|
||||
},
|
||||
"reply_prefix": {
|
||||
"description": "回复前缀",
|
||||
"type": "string",
|
||||
"hint": "机器人回复消息时带有的前缀。",
|
||||
},
|
||||
"forward_threshold": {
|
||||
"description": "转发消息的字数阈值",
|
||||
"type": "int",
|
||||
"hint": "超过一定字数后,机器人会将消息折叠成 QQ 群聊的 “转发消息”,以防止刷屏。目前仅 QQ 平台适配器适用。",
|
||||
},
|
||||
"enable_id_white_list": {
|
||||
"description": "启用 ID 白名单",
|
||||
"type": "bool",
|
||||
},
|
||||
"id_whitelist": {
|
||||
"description": "ID 白名单",
|
||||
"type": "list",
|
||||
"items": {"type": "int"},
|
||||
"hint": "填写后,将只处理所填写的 ID 发来的消息事件。为空时表示不启用白名单过滤。可以使用 /myid 指令获取在某个平台上的会话 ID。也可在 AstrBot 日志内获取会话 ID,当一条消息没通过白名单时,会输出 INFO 级别的日志。会话 ID 类似 aiocqhttp:GroupMessage:547540978",
|
||||
},
|
||||
"id_whitelist_log": {
|
||||
"description": "打印白名单日志",
|
||||
"type": "bool",
|
||||
"hint": "启用后,当一条消息没通过白名单时,会输出 INFO 级别的日志。",
|
||||
},
|
||||
"wl_ignore_admin_on_group": {
|
||||
"description": "管理员群组消息无视 ID 白名单",
|
||||
"type": "bool",
|
||||
},
|
||||
"wl_ignore_admin_on_friend": {
|
||||
"description": "管理员私聊消息无视 ID 白名单",
|
||||
"type": "bool",
|
||||
},
|
||||
"reply_with_mention": {
|
||||
"description": "回复时 @ 发送者",
|
||||
"type": "bool",
|
||||
"hint": "启用后,机器人回复消息时会 @ 发送者。实际效果以具体的平台适配器为准。",
|
||||
},
|
||||
"reply_with_quote": {
|
||||
"description": "回复时引用消息",
|
||||
"type": "bool",
|
||||
"hint": "启用后,机器人回复消息时会引用原消息。实际效果以具体的平台适配器为准。",
|
||||
},
|
||||
"path_mapping": {
|
||||
"description": "路径映射",
|
||||
"type": "list",
|
||||
"obvious_hint": True,
|
||||
"hint": "此功能解决由于文件系统不一致导致路径不存在的问题。格式为 <原路径>:<映射路径>。如 `/app/.config/QQ:/var/lib/docker/volumes/xxxx/_data`。这样,当消息平台下发的事件中图片和语音路径以 `/app/.config/QQ` 开头时,开头被替换为 `/var/lib/docker/volumes/xxxx/_data`。这在 AstrBot 或者平台协议端使用 Docker 部署时特别有用。",
|
||||
}
|
||||
},
|
||||
},
|
||||
"content_safety": {
|
||||
"description": "内容安全",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"baidu_aip": {
|
||||
"description": "百度内容审核配置",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"enable": {
|
||||
"description": "启用百度内容审核",
|
||||
"type": "bool",
|
||||
"hint": "启用此功能前,您需要手动在设备中安装 baidu-aip 库。一般来说,安装指令如下: `pip3 install baidu-aip`",
|
||||
},
|
||||
"app_id": {"description": "APP ID", "type": "string"},
|
||||
"api_key": {"description": "API Key", "type": "string"},
|
||||
"secret_key": {
|
||||
"description": "Secret Key",
|
||||
"type": "string",
|
||||
},
|
||||
},
|
||||
},
|
||||
"internal_keywords": {
|
||||
"description": "内部关键词过滤",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"enable": {
|
||||
"description": "启用内部关键词过滤",
|
||||
"type": "bool",
|
||||
},
|
||||
"extra_keywords": {
|
||||
"description": "额外关键词",
|
||||
"type": "list",
|
||||
"items": {"type": "string"},
|
||||
"hint": "额外的屏蔽关键词列表,支持正则表达式。",
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
"provider_group": {
|
||||
"name": "服务提供商",
|
||||
"metadata": {
|
||||
"provider": {
|
||||
"description": "服务提供商配置",
|
||||
"type": "list",
|
||||
"config_template": {
|
||||
"openai": {
|
||||
"id": "default",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "",
|
||||
"model_config": {
|
||||
"model": "gpt-4o-mini",
|
||||
},
|
||||
},
|
||||
"ollama": {
|
||||
"id": "ollama_default",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
"key": ["ollama"], # ollama 的 key 默认是 ollama
|
||||
"api_base": "http://localhost:11434/v1",
|
||||
"model_config": {
|
||||
"model": "llama3.1-8b",
|
||||
},
|
||||
},
|
||||
"gemini(OpenAI兼容)": {
|
||||
"id": "gemini_default",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "https://generativelanguage.googleapis.com/v1beta/openai/",
|
||||
"model_config": {
|
||||
"model": "gemini-1.5-flash",
|
||||
},
|
||||
},
|
||||
"gemini(googlegenai原生)": {
|
||||
"id": "gemini_default",
|
||||
"type": "googlegenai_chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "https://generativelanguage.googleapis.com/",
|
||||
"model_config": {
|
||||
"model": "gemini-1.5-flash",
|
||||
},
|
||||
},
|
||||
"deepseek": {
|
||||
"id": "deepseek_default",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "https://api.deepseek.com/v1",
|
||||
"model_config": {
|
||||
"model": "deepseek-chat",
|
||||
},
|
||||
},
|
||||
"zhipu": {
|
||||
"id": "zhipu_default",
|
||||
"type": "zhipu_chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "https://open.bigmodel.cn/api/paas/v4/",
|
||||
"model_config": {
|
||||
"model": "glm-4-flash",
|
||||
},
|
||||
},
|
||||
"llmtuner": {
|
||||
"id": "llmtuner_default",
|
||||
"type": "llm_tuner",
|
||||
"enable": True,
|
||||
"base_model_path": "",
|
||||
"adapter_model_path": "",
|
||||
"llmtuner_template": "",
|
||||
"finetuning_type": "lora",
|
||||
"quantization_bit": 4,
|
||||
},
|
||||
"dify": {
|
||||
"id": "dify_app_default",
|
||||
"type": "dify",
|
||||
"enable": True,
|
||||
"dify_api_type": "chat",
|
||||
"dify_api_key": "",
|
||||
"dify_api_base": "https://api.dify.ai/v1",
|
||||
"dify_workflow_output_key": "",
|
||||
},
|
||||
"whisper(API)": {
|
||||
"id": "whisper",
|
||||
"type": "openai_whisper_api",
|
||||
"enable": False,
|
||||
"api_key": "",
|
||||
"api_base": "",
|
||||
"model": "whisper-1",
|
||||
},
|
||||
"whisper(本地加载)": {
|
||||
"whisper_hint": "(不用修改我)",
|
||||
"enable": False,
|
||||
"id": "whisper",
|
||||
"type": "openai_whisper_selfhost",
|
||||
"model": "tiny",
|
||||
},
|
||||
"openai_tts(API)": {
|
||||
"id": "openai_tts",
|
||||
"type": "openai_tts_api",
|
||||
"enable": False,
|
||||
"api_key": "",
|
||||
"api_base": "",
|
||||
"model": "tts-1",
|
||||
},
|
||||
},
|
||||
"items": {
|
||||
"whisper_hint": {
|
||||
"description": "本地部署 Whisper 模型须知",
|
||||
"type": "string",
|
||||
"hint": "启用前请 pip 安装 openai-whisper 库(N卡用户大约下载 2GB,主要是 torch 和 cuda,CPU 用户大约下载 1 GB),并且安装 ffmpeg。否则将无法正常转文字。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"id": {
|
||||
"description": "ID",
|
||||
"type": "string",
|
||||
"hint": "提供商 ID 名,用于在多实例下方便管理和识别。自定义,ID 不能重复。",
|
||||
},
|
||||
"type": {
|
||||
"description": "模型提供商类型",
|
||||
"type": "string",
|
||||
"invisible": True,
|
||||
},
|
||||
"enable": {
|
||||
"description": "启用",
|
||||
"type": "bool",
|
||||
"hint": "是否启用该模型。未启用的模型将不会被使用。",
|
||||
},
|
||||
"key": {
|
||||
"description": "API Key",
|
||||
"type": "list",
|
||||
"items": {"type": "string"},
|
||||
"hint": "API Key 列表。填写好后输入回车即可添加 API Key。支持多个 API Key。",
|
||||
},
|
||||
"api_base": {
|
||||
"description": "API Base URL",
|
||||
"type": "string",
|
||||
"hint": "API Base URL 请在在模型提供商处获得。如使用时出现了 404 报错,可以尝试在地址末尾加上 `/v1`。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"base_model_path": {
|
||||
"description": "基座模型路径",
|
||||
"type": "string",
|
||||
"hint": "基座模型路径。",
|
||||
},
|
||||
"adapter_model_path": {
|
||||
"description": "Adapter 模型路径",
|
||||
"type": "string",
|
||||
"hint": "Adapter 模型路径。如 Lora",
|
||||
},
|
||||
"llmtuner_template": {
|
||||
"description": "template",
|
||||
"type": "string",
|
||||
"hint": "基座模型的类型。如 llama3, qwen, 请参考 LlamaFactory 文档。",
|
||||
},
|
||||
"finetuning_type": {
|
||||
"description": "微调类型",
|
||||
"type": "string",
|
||||
"hint": "微调类型。如 `lora`",
|
||||
},
|
||||
"quantization_bit": {
|
||||
"description": "量化位数",
|
||||
"type": "int",
|
||||
"hint": "量化位数。如 4",
|
||||
},
|
||||
"model_config": {
|
||||
"description": "文本生成模型",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"model": {
|
||||
"description": "模型名称",
|
||||
"type": "string",
|
||||
"hint": "大语言模型的名称,一般是小写的英文。如 gpt-4o-mini, deepseek-chat 等。",
|
||||
},
|
||||
"max_tokens": {
|
||||
"description": "模型最大输出长度(tokens)",
|
||||
"type": "int",
|
||||
},
|
||||
"temperature": {"description": "温度", "type": "float"},
|
||||
"top_p": {"description": "Top P值", "type": "float"},
|
||||
},
|
||||
},
|
||||
"dify_api_key": {
|
||||
"description": "API Key",
|
||||
"type": "string",
|
||||
"hint": "Dify API Key。此项必填。",
|
||||
},
|
||||
"dify_api_base": {
|
||||
"description": "API Base URL",
|
||||
"type": "string",
|
||||
"hint": "Dify API Base URL。默认为 https://api.dify.ai/v1",
|
||||
},
|
||||
"dify_api_type": {
|
||||
"description": "Dify 应用类型",
|
||||
"type": "string",
|
||||
"hint": "Dify API 类型。根据 Dify 官网,目前支持 chat, agent, workflow 三种应用类型",
|
||||
"options": ["chat", "agent", "workflow"],
|
||||
},
|
||||
"dify_workflow_output_key": {
|
||||
"description": "Dify Workflow 输出变量名",
|
||||
"type": "string",
|
||||
"hint": "Dify Workflow 输出变量名。当应用类型为 workflow 时才使用。默认为 astrbot_wf_output。",
|
||||
},
|
||||
},
|
||||
},
|
||||
"provider_settings": {
|
||||
"description": "大语言模型设置",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"enable": {
|
||||
"description": "启用大语言模型聊天",
|
||||
"type": "bool",
|
||||
"hint": "如需切换大语言模型提供商,请使用 `/provider` 命令。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"wake_prefix": {
|
||||
"description": "LLM 聊天额外唤醒前缀",
|
||||
"type": "string",
|
||||
"hint": "使用 LLM 聊天额外的触发条件。如填写 `chat`,则需要消息前缀加上 `/chat` 才能触发 LLM 聊天,是一个防止滥用的手段。",
|
||||
},
|
||||
"web_search": {
|
||||
"description": "启用网页搜索",
|
||||
"type": "bool",
|
||||
"hint": "能访问 Google 时效果最佳。如果 Google 访问失败,程序会依次访问 Bing, Sogo 搜索引擎。",
|
||||
},
|
||||
"identifier": {
|
||||
"description": "启动识别群员",
|
||||
"type": "bool",
|
||||
"hint": "在 Prompt 前加上群成员的名字以让模型更好地了解群聊状态。启用将略微增加 token 开销。",
|
||||
},
|
||||
"datetime_system_prompt": {
|
||||
"description": "启用日期时间系统提示",
|
||||
"type": "bool",
|
||||
"hint": "启用后,会在系统提示词中加上当前机器的日期时间。",
|
||||
},
|
||||
"default_personality": {
|
||||
"description": "默认采用的人格情景的名称",
|
||||
"type": "string",
|
||||
"hint": "",
|
||||
},
|
||||
"prompt_prefix": {
|
||||
"description": "Prompt 前缀文本",
|
||||
"type": "string",
|
||||
"hint": "添加之后,会在每次对话的 Prompt 前加上此文本。",
|
||||
},
|
||||
},
|
||||
},
|
||||
"persona": {
|
||||
"description": "人格情景设置",
|
||||
"type": "list",
|
||||
"config_template": {
|
||||
"新人格情景": {
|
||||
"name": "",
|
||||
"prompt": "",
|
||||
"begin_dialogs": [],
|
||||
"mood_imitation_dialogs": [],
|
||||
}
|
||||
},
|
||||
"tmpl_display_title": "name",
|
||||
"items": {
|
||||
"name": {
|
||||
"description": "人格名称",
|
||||
"type": "string",
|
||||
"hint": "人格名称,用于在多个人格中区分。使用 /persona 指令可切换人格。在 大语言模型设置 处可以设置默认人格。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"prompt": {
|
||||
"description": "设定(系统提示词)",
|
||||
"type": "text",
|
||||
"hint": "填写人格的身份背景、性格特征、兴趣爱好、个人经历、口头禅等。",
|
||||
},
|
||||
"begin_dialogs": {
|
||||
"description": "预设对话",
|
||||
"type": "list",
|
||||
"items": {},
|
||||
"hint": "可选。在每个对话前会插入这些预设对话。格式要求:第一句为用户,第二句为助手,以此类推。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"mood_imitation_dialogs": {
|
||||
"description": "对话风格模仿",
|
||||
"type": "list",
|
||||
"items": {},
|
||||
"hint": "旨在让模型尽可能模仿学习到所填写的对话的语气风格。格式和 `预设对话` 一样。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
},
|
||||
},
|
||||
"provider_stt_settings": {
|
||||
"description": "语音转文本(STT)",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"enable": {
|
||||
"description": "启用语音转文本(STT)",
|
||||
"type": "bool",
|
||||
"hint": "启用前请在 服务提供商配置 处创建支持 语音转文本任务 的提供商。如 whisper。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"provider_id": {
|
||||
"description": "提供商 ID,不填则默认第一个STT提供商",
|
||||
"type": "string",
|
||||
"hint": "语音转文本提供商 ID。如果不填写将使用载入的第一个提供商。",
|
||||
},
|
||||
},
|
||||
},
|
||||
"provider_tts_settings": {
|
||||
"description": "文本转语音(TTS)",
|
||||
"type": "object",
|
||||
"items": {
|
||||
"enable": {
|
||||
"description": "启用文本转语音(TTS)",
|
||||
"type": "bool",
|
||||
"hint": "启用前请在 服务提供商配置 处创建支持 语音转文本任务 的提供商。如 openai_tts。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"provider_id": {
|
||||
"description": "提供商 ID,不填则默认第一个TTS提供商",
|
||||
"type": "string",
|
||||
"hint": "文本转语音提供商 ID。如果不填写将使用载入的第一个提供商。",
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
"misc_config_group": {
|
||||
"name": "其他配置",
|
||||
"metadata": {
|
||||
"wake_prefix": {
|
||||
"description": "机器人唤醒前缀",
|
||||
"type": "list",
|
||||
"items": {"type": "string"},
|
||||
"hint": "在不 @ 机器人的情况下,可以通过外加消息前缀来唤醒机器人。",
|
||||
},
|
||||
"t2i": {
|
||||
"description": "文本转图像",
|
||||
"type": "bool",
|
||||
"hint": "启用后,超出一定长度的文本将会通过 AstrBot API 渲染成 Markdown 图片发送。可以缓解审核和消息过长刷屏的问题,并提高 Markdown 文本的可读性。",
|
||||
},
|
||||
"admins_id": {
|
||||
"description": "管理员 ID",
|
||||
"type": "list",
|
||||
"items": {"type": "int"},
|
||||
"hint": "管理员 ID 列表,管理员可以使用一些特权命令,如 `update`, `plugin` 等。ID 可以通过 `/myid` 指令获得。回车添加,可添加多个。",
|
||||
},
|
||||
"http_proxy": {
|
||||
"description": "HTTP 代理",
|
||||
"type": "string",
|
||||
"hint": "启用后,会以添加环境变量的方式设置代理。格式为 `http://ip:port`",
|
||||
},
|
||||
"log_level": {
|
||||
"description": "控制台日志级别",
|
||||
"type": "string",
|
||||
"hint": "控制台输出日志的级别。",
|
||||
"options": ["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"],
|
||||
},
|
||||
"t2i_endpoint": {
|
||||
"description": "文本转图像服务接口",
|
||||
"type": "string",
|
||||
"hint": "为空时使用 AstrBot API 服务",
|
||||
},
|
||||
"pip_install_arg": {
|
||||
"description": "pip 安装参数",
|
||||
"type": "string",
|
||||
"hint": "安装插件依赖时,会使用 Python 的 pip 工具。这里可以填写额外的参数,如 `--break-system-package` 等。",
|
||||
},
|
||||
"plugin_repo_mirror": {
|
||||
"description": "插件仓库镜像",
|
||||
"type": "string",
|
||||
"hint": "插件仓库的镜像地址,用于加速插件的下载。",
|
||||
"options": [
|
||||
"default",
|
||||
"https://ghp.ci/",
|
||||
"https://github-mirror.us.kg/",
|
||||
],
|
||||
},
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
DEFAULT_VALUE_MAP = {
|
||||
"int": 0,
|
||||
"float": 0.0,
|
||||
"bool": False,
|
||||
"string": "",
|
||||
"text": "",
|
||||
"list": [],
|
||||
"object": {},
|
||||
}
|
||||
|
||||
|
||||
# "project_atri": {
|
||||
# "description": "Project ATRI 配置",
|
||||
# "type": "object",
|
||||
# "items": {
|
||||
# "enable": {"description": "启用", "type": "bool"},
|
||||
# "long_term_memory": {
|
||||
# "description": "长期记忆",
|
||||
# "type": "object",
|
||||
# "items": {
|
||||
# "enable": {"description": "启用", "type": "bool"},
|
||||
# "summary_threshold_cnt": {
|
||||
# "description": "摘要阈值",
|
||||
# "type": "int",
|
||||
# "hint": "当一个会话的对话记录数量超过该阈值时,会自动进行摘要。",
|
||||
# },
|
||||
# "embedding_provider_id": {
|
||||
# "description": "Embedding provider ID",
|
||||
# "type": "string",
|
||||
# "hint": "只有当启用了长期记忆时,才需要填写此项。将会使用指定的 provider 来获取 Embedding,请确保所填的 provider id 在 `配置页` 中存在并且设置了 Embedding 配置",
|
||||
# "obvious_hint": True,
|
||||
# },
|
||||
# "summarize_provider_id": {
|
||||
# "description": "Summary provider ID",
|
||||
# "type": "string",
|
||||
# "hint": "只有当启用了长期记忆时,才需要填写此项。将会使用指定的 provider 来获取 Summary,请确保所填的 provider id 在 `配置页` 中存在。",
|
||||
# "obvious_hint": True,
|
||||
# },
|
||||
# },
|
||||
# },
|
||||
# "active_message": {
|
||||
# "description": "主动消息",
|
||||
# "type": "object",
|
||||
# "items": {
|
||||
# "enable": {"description": "启用", "type": "bool"},
|
||||
# },
|
||||
# },
|
||||
# "vision": {
|
||||
# "description": "视觉理解",
|
||||
# "type": "object",
|
||||
# "items": {
|
||||
# "enable": {"description": "启用", "type": "bool"},
|
||||
# "provider_id_or_ofa_model_path": {
|
||||
# "description": "提供商 ID 或 OFA 模型路径",
|
||||
# "type": "string",
|
||||
# "hint": "将会使用指定的 provider 来进行视觉处理,请确保所填的 provider id 在 `配置页` 中存在。",
|
||||
# },
|
||||
# },
|
||||
# },
|
||||
# "split_response": {
|
||||
# "description": "是否分割回复",
|
||||
# "type": "bool",
|
||||
# "hint": "启用后,将会根据句子分割回复以更像人类回复。每次回复之间具有随机的时间间隔。默认启用。",
|
||||
# },
|
||||
# "persona": {
|
||||
# "description": "人格",
|
||||
# "type": "string",
|
||||
# "hint": "默认人格。当启动 ATRI 之后,在 Provider 处设置的人格将会失效。",
|
||||
# "obvious_hint": True,
|
||||
# },
|
||||
# "chat_provider_id": {
|
||||
# "description": "Chat provider ID",
|
||||
# "type": "string",
|
||||
# "hint": "将会使用指定的 provider 来进行文本聊天,请确保所填的 provider id 在 `配置页` 中存在。",
|
||||
# "obvious_hint": True,
|
||||
# },
|
||||
# "chat_base_model_path": {
|
||||
# "description": "用于聊天的基座模型路径",
|
||||
# "type": "string",
|
||||
# "hint": "用于聊天的基座模型路径。当填写此项和 Lora 路径后,将会忽略上面设置的 Chat provider ID。",
|
||||
# "obvious_hint": True,
|
||||
# },
|
||||
# "chat_adapter_model_path": {
|
||||
# "description": "用于聊天的 Lora 模型路径",
|
||||
# "type": "string",
|
||||
# "hint": "Lora 模型路径。",
|
||||
# "obvious_hint": True,
|
||||
# },
|
||||
# "quantization_bit": {
|
||||
# "description": "量化位数",
|
||||
# "type": "int",
|
||||
# "hint": "模型量化位数。如果你不知道这是什么,请不要修改。默认为 4。",
|
||||
# "obvious_hint": True,
|
||||
# },
|
||||
# },
|
||||
# },
|
||||
134
astrbot/core/core_lifecycle.py
Normal file
134
astrbot/core/core_lifecycle.py
Normal file
@@ -0,0 +1,134 @@
|
||||
import traceback
|
||||
import asyncio
|
||||
import time
|
||||
import threading
|
||||
import os
|
||||
from .event_bus import EventBus
|
||||
from . import astrbot_config
|
||||
from asyncio import Queue
|
||||
from typing import List
|
||||
from astrbot.core.pipeline.scheduler import PipelineScheduler, PipelineContext
|
||||
from astrbot.core.star import PluginManager
|
||||
from astrbot.core.platform.manager import PlatformManager
|
||||
from astrbot.core.star.context import Context
|
||||
from astrbot.core.provider.manager import ProviderManager
|
||||
from astrbot.core import LogBroker
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot.core.updator import AstrBotUpdator
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.config.default import VERSION
|
||||
from astrbot.core.rag.knowledge_db_mgr import KnowledgeDBManager
|
||||
|
||||
class AstrBotCoreLifecycle:
|
||||
def __init__(self, log_broker: LogBroker, db: BaseDatabase):
|
||||
self.log_broker = log_broker
|
||||
self.astrbot_config = astrbot_config
|
||||
self.db = db
|
||||
|
||||
if self.astrbot_config['http_proxy']:
|
||||
os.environ['https_proxy'] = self.astrbot_config['http_proxy']
|
||||
os.environ['http_proxy'] = self.astrbot_config['http_proxy']
|
||||
|
||||
async def initialize(self):
|
||||
logger.info("AstrBot v"+ VERSION)
|
||||
if os.environ.get("TESTING", ""):
|
||||
logger.setLevel("DEBUG")
|
||||
else:
|
||||
logger.setLevel(self.astrbot_config['log_level'])
|
||||
self.event_queue = Queue()
|
||||
self.event_queue.closed = False
|
||||
|
||||
self.provider_manager = ProviderManager(self.astrbot_config, self.db)
|
||||
|
||||
self.platform_manager = PlatformManager(self.astrbot_config, self.event_queue)
|
||||
|
||||
self.knowledge_db_manager = KnowledgeDBManager(self.astrbot_config)
|
||||
|
||||
self.star_context = Context(
|
||||
self.event_queue,
|
||||
self.astrbot_config,
|
||||
self.db,
|
||||
self.provider_manager,
|
||||
self.platform_manager,
|
||||
self.knowledge_db_manager
|
||||
)
|
||||
self.plugin_manager = PluginManager(self.star_context, self.astrbot_config)
|
||||
|
||||
await self.plugin_manager.reload()
|
||||
'''扫描、注册插件、实例化插件类'''
|
||||
|
||||
await self.provider_manager.initialize()
|
||||
'''根据配置实例化各个 Provider'''
|
||||
|
||||
await self.platform_manager.initialize()
|
||||
'''根据配置实例化各个平台适配器'''
|
||||
|
||||
self.pipeline_scheduler = PipelineScheduler(PipelineContext(self.astrbot_config, self.plugin_manager))
|
||||
await self.pipeline_scheduler.initialize()
|
||||
'''初始化消息事件流水线调度器'''
|
||||
|
||||
self.astrbot_updator = AstrBotUpdator(self.astrbot_config['plugin_repo_mirror'])
|
||||
self.event_bus = EventBus(self.event_queue, self.pipeline_scheduler)
|
||||
self.start_time = int(time.time())
|
||||
self.curr_tasks: List[asyncio.Task] = []
|
||||
|
||||
def _load(self):
|
||||
|
||||
platform_tasks = self.load_platform()
|
||||
event_bus_task = asyncio.create_task(self.event_bus.dispatch(), name="event_bus")
|
||||
|
||||
extra_tasks = []
|
||||
for task in self.star_context._register_tasks:
|
||||
extra_tasks.append(asyncio.create_task(task, name=task.__name__))
|
||||
|
||||
# self.curr_tasks = [event_bus_task, *platform_tasks, *extra_tasks]
|
||||
|
||||
tasks_ = [event_bus_task, *platform_tasks, *extra_tasks]
|
||||
for task in tasks_:
|
||||
self.curr_tasks.append(asyncio.create_task(self._task_wrapper(task), name=task.get_name()))
|
||||
|
||||
self.start_time = int(time.time())
|
||||
|
||||
async def _task_wrapper(self, task: asyncio.Task):
|
||||
try:
|
||||
await task
|
||||
except asyncio.CancelledError:
|
||||
pass
|
||||
except Exception as e:
|
||||
|
||||
logger.error(f"------- 任务 {task.get_name()} 发生错误: {e}")
|
||||
for line in traceback.format_exc().split("\n"):
|
||||
logger.error(f"| {line}")
|
||||
logger.error("-------")
|
||||
|
||||
async def start(self):
|
||||
self._load()
|
||||
logger.info("AstrBot 启动完成。")
|
||||
|
||||
await asyncio.gather(*self.curr_tasks, return_exceptions=True)
|
||||
|
||||
async def stop(self):
|
||||
self.event_queue.closed = True
|
||||
for task in self.curr_tasks:
|
||||
task.cancel()
|
||||
|
||||
await self.provider_manager.terminate()
|
||||
|
||||
for task in self.curr_tasks:
|
||||
try:
|
||||
await task
|
||||
except asyncio.CancelledError:
|
||||
pass
|
||||
except Exception as e:
|
||||
logger.error(f"任务 {task.get_name()} 发生错误: {e}")
|
||||
|
||||
def restart(self):
|
||||
self.event_queue.closed = True
|
||||
threading.Thread(target=self.astrbot_updator._reboot, name="restart", daemon=True).start()
|
||||
|
||||
def load_platform(self) -> List[asyncio.Task]:
|
||||
tasks = []
|
||||
platform_insts = self.platform_manager.get_insts()
|
||||
for platform_inst in platform_insts:
|
||||
tasks.append(asyncio.create_task(platform_inst.run(), name=platform_inst.meta().name))
|
||||
return tasks
|
||||
103
astrbot/core/db/__init__.py
Normal file
103
astrbot/core/db/__init__.py
Normal file
@@ -0,0 +1,103 @@
|
||||
import abc
|
||||
from dataclasses import dataclass
|
||||
from typing import List
|
||||
from astrbot.core.db.po import Stats, LLMHistory, ATRIVision, WebChatConversation
|
||||
|
||||
@dataclass
|
||||
class BaseDatabase(abc.ABC):
|
||||
'''
|
||||
数据库基类
|
||||
'''
|
||||
def __init__(self) -> None:
|
||||
pass
|
||||
|
||||
def insert_base_metrics(self, metrics: dict):
|
||||
'''插入基础指标数据'''
|
||||
self.insert_platform_metrics(metrics['platform_stats'])
|
||||
self.insert_plugin_metrics(metrics['plugin_stats'])
|
||||
self.insert_command_metrics(metrics['command_stats'])
|
||||
self.insert_llm_metrics(metrics['llm_stats'])
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_platform_metrics(self, metrics: dict):
|
||||
'''插入平台指标数据'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_plugin_metrics(self, metrics: dict):
|
||||
'''插入插件指标数据'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_command_metrics(self, metrics: dict):
|
||||
'''插入指令指标数据'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_llm_metrics(self, metrics: dict):
|
||||
'''插入 LLM 指标数据'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def update_llm_history(self, session_id: str, content: str, provider_type: str):
|
||||
'''更新 LLM 历史记录。当不存在 session_id 时插入'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_llm_history(self, session_id: str = None, provider_type: str = None) -> List[LLMHistory]:
|
||||
'''获取 LLM 历史记录, 如果 session_id 为 None, 返回所有'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_base_stats(self, offset_sec: int = 86400) -> Stats:
|
||||
'''获取基础统计数据'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_total_message_count(self) -> int:
|
||||
'''获取总消息数'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_grouped_base_stats(self, offset_sec: int = 86400) -> Stats:
|
||||
'''获取基础统计数据(合并)'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_atri_vision_data(self, vision_data: ATRIVision):
|
||||
'''插入 ATRI 视觉数据'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_atri_vision_data(self) -> List[ATRIVision]:
|
||||
'''获取 ATRI 视觉数据'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_atri_vision_data_by_path_or_id(self, url_or_path: str, id: str) -> ATRIVision:
|
||||
'''通过 url 或 path 获取 ATRI 视觉数据'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_webchat_conversation_by_user_id(self, user_id: str, cid: str) -> WebChatConversation:
|
||||
'''通过 user_id 和 cid 获取 WebChatConversation'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def webchat_new_conversation(self, user_id: str, cid: str):
|
||||
'''新建 WebChatConversation'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_webchat_conversations(self, user_id: str) -> List[WebChatConversation]:
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def update_webchat_conversation(self, user_id: str, cid: str, history: str):
|
||||
'''更新 WebChatConversation'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def delete_webchat_conversation(self, user_id: str, cid: str):
|
||||
'''删除 WebChatConversation'''
|
||||
raise NotImplementedError
|
||||
65
astrbot/core/db/po.py
Normal file
65
astrbot/core/db/po.py
Normal file
@@ -0,0 +1,65 @@
|
||||
'''指标数据'''
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import List
|
||||
|
||||
@dataclass
|
||||
class Platform():
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
@dataclass
|
||||
class Provider():
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
@dataclass
|
||||
class Plugin():
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
@dataclass
|
||||
class Command():
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
@dataclass
|
||||
class Stats():
|
||||
platform: List[Platform] = field(default_factory=list)
|
||||
command: List[Command] = field(default_factory=list)
|
||||
llm: List[Provider] = field(default_factory=list)
|
||||
|
||||
'''LLM 聊天时持久化的信息'''
|
||||
|
||||
@dataclass
|
||||
class LLMHistory():
|
||||
provider_type: str
|
||||
session_id: str
|
||||
content: str
|
||||
|
||||
@dataclass
|
||||
class ATRIVision():
|
||||
id: str
|
||||
url_or_path: str
|
||||
caption: str
|
||||
is_meme: bool
|
||||
keywords: List[str]
|
||||
platform_name: str
|
||||
session_id: str
|
||||
sender_nickname: str
|
||||
timestamp: int = -1
|
||||
|
||||
|
||||
|
||||
@dataclass
|
||||
class WebChatConversation():
|
||||
user_id: str
|
||||
cid: str
|
||||
history: str = ""
|
||||
created_at: int = 0
|
||||
updated_at: int = 0
|
||||
|
||||
312
astrbot/core/db/sqlite.py
Normal file
312
astrbot/core/db/sqlite.py
Normal file
@@ -0,0 +1,312 @@
|
||||
import sqlite3
|
||||
import os
|
||||
import time
|
||||
from astrbot.core.db.po import (
|
||||
Platform,
|
||||
Stats,
|
||||
LLMHistory,
|
||||
ATRIVision,
|
||||
WebChatConversation
|
||||
)
|
||||
from . import BaseDatabase
|
||||
from typing import Tuple
|
||||
|
||||
|
||||
class SQLiteDatabase(BaseDatabase):
|
||||
def __init__(self, db_path: str) -> None:
|
||||
super().__init__()
|
||||
self.db_path = db_path
|
||||
|
||||
with open(os.path.dirname(__file__) + "/sqlite_init.sql", "r") as f:
|
||||
sql = f.read()
|
||||
|
||||
# 初始化数据库
|
||||
self.conn = self._get_conn(self.db_path)
|
||||
c = self.conn.cursor()
|
||||
c.executescript(sql)
|
||||
self.conn.commit()
|
||||
|
||||
def _get_conn(self, db_path: str) -> sqlite3.Connection:
|
||||
conn = sqlite3.connect(self.db_path)
|
||||
conn.text_factory = str
|
||||
return conn
|
||||
|
||||
def _exec_sql(self, sql: str, params: Tuple = None):
|
||||
conn = self.conn
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
conn = self._get_conn(self.db_path)
|
||||
c = conn.cursor()
|
||||
|
||||
if params:
|
||||
c.execute(sql, params)
|
||||
c.close()
|
||||
else:
|
||||
c.execute(sql)
|
||||
c.close()
|
||||
|
||||
conn.commit()
|
||||
|
||||
def insert_platform_metrics(self, metrics: dict):
|
||||
for k, v in metrics.items():
|
||||
self._exec_sql(
|
||||
'''
|
||||
INSERT INTO platform(name, count, timestamp) VALUES (?, ?, ?)
|
||||
''', (k, v, int(time.time()))
|
||||
)
|
||||
|
||||
def insert_plugin_metrics(self, metrics: dict):
|
||||
pass
|
||||
|
||||
def insert_command_metrics(self, metrics: dict):
|
||||
for k, v in metrics.items():
|
||||
self._exec_sql(
|
||||
'''
|
||||
INSERT INTO command(name, count, timestamp) VALUES (?, ?, ?)
|
||||
''', (k, v, int(time.time()))
|
||||
)
|
||||
|
||||
def insert_llm_metrics(self, metrics: dict):
|
||||
for k, v in metrics.items():
|
||||
self._exec_sql(
|
||||
'''
|
||||
INSERT INTO llm(name, count, timestamp) VALUES (?, ?, ?)
|
||||
''', (k, v, int(time.time()))
|
||||
)
|
||||
|
||||
def update_llm_history(self, session_id: str, content: str, provider_type: str):
|
||||
res = self.get_llm_history(session_id, provider_type)
|
||||
if res:
|
||||
self._exec_sql(
|
||||
'''
|
||||
UPDATE llm_history SET content = ? WHERE session_id = ? AND provider_type = ?
|
||||
''', (content, session_id, provider_type)
|
||||
)
|
||||
else:
|
||||
self._exec_sql(
|
||||
'''
|
||||
INSERT INTO llm_history(provider_type, session_id, content) VALUES (?, ?, ?)
|
||||
''', (provider_type, session_id, content)
|
||||
)
|
||||
|
||||
def get_llm_history(self, session_id: str = None, provider_type: str = None) -> Tuple:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
where_clause = ""
|
||||
if session_id or provider_type:
|
||||
where_clause += " WHERE "
|
||||
has = False
|
||||
if session_id:
|
||||
where_clause += f"session_id = '{session_id}'"
|
||||
has = True
|
||||
if provider_type:
|
||||
if has:
|
||||
where_clause += " AND "
|
||||
where_clause += f"provider_type = '{provider_type}'"
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
SELECT * FROM llm_history
|
||||
''' + where_clause
|
||||
)
|
||||
res = c.fetchall()
|
||||
histories = []
|
||||
for row in res:
|
||||
histories.append(LLMHistory(*row))
|
||||
c.close()
|
||||
return histories
|
||||
|
||||
def get_base_stats(self, offset_sec: int = 86400) -> Stats:
|
||||
'''获取 offset_sec 秒前到现在的基础统计数据'''
|
||||
where_clause = f" WHERE timestamp >= {int(time.time()) - offset_sec}"
|
||||
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
SELECT * FROM platform
|
||||
''' + where_clause
|
||||
)
|
||||
|
||||
platform = []
|
||||
for row in c.fetchall():
|
||||
platform.append(Platform(*row))
|
||||
|
||||
# c.execute(
|
||||
# '''
|
||||
# SELECT * FROM command
|
||||
# ''' + where_clause
|
||||
# )
|
||||
|
||||
# command = []
|
||||
# for row in c.fetchall():
|
||||
# command.append(Command(*row))
|
||||
|
||||
# c.execute(
|
||||
# '''
|
||||
# SELECT * FROM llm
|
||||
# ''' + where_clause
|
||||
# )
|
||||
|
||||
# llm = []
|
||||
# for row in c.fetchall():
|
||||
# llm.append(Provider(*row))
|
||||
|
||||
c.close()
|
||||
|
||||
return Stats(platform, [], [])
|
||||
|
||||
def get_total_message_count(self) -> int:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
SELECT SUM(count) FROM platform
|
||||
'''
|
||||
)
|
||||
res = c.fetchone()
|
||||
c.close()
|
||||
return res[0]
|
||||
|
||||
def get_grouped_base_stats(self, offset_sec: int = 86400) -> Stats:
|
||||
'''获取 offset_sec 秒前到现在的基础统计数据(合并)'''
|
||||
where_clause = f" WHERE timestamp >= {int(time.time()) - offset_sec}"
|
||||
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
SELECT name, SUM(count), timestamp FROM platform
|
||||
''' + where_clause + " GROUP BY name"
|
||||
)
|
||||
|
||||
platform = []
|
||||
for row in c.fetchall():
|
||||
platform.append(Platform(*row))
|
||||
|
||||
c.close()
|
||||
|
||||
return Stats(platform, [], [])
|
||||
|
||||
|
||||
def get_webchat_conversation_by_user_id(self, user_id: str, cid: str) -> WebChatConversation:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
SELECT * FROM webchat_conversation WHERE user_id = ? AND cid = ?
|
||||
''', (user_id, cid)
|
||||
)
|
||||
|
||||
res = c.fetchone()
|
||||
c.close()
|
||||
return WebChatConversation(*res)
|
||||
|
||||
def webchat_new_conversation(self, user_id: str, cid: str):
|
||||
history = "[]"
|
||||
updated_at = int(time.time())
|
||||
created_at = updated_at
|
||||
self._exec_sql(
|
||||
'''
|
||||
INSERT INTO webchat_conversation(user_id, cid, history, updated_at, created_at) VALUES (?, ?, ?, ?, ?)
|
||||
''', (user_id, cid, history, updated_at, created_at)
|
||||
)
|
||||
|
||||
def get_webchat_conversations(self, user_id: str) -> Tuple:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
SELECT cid, created_at, updated_at FROM webchat_conversation WHERE user_id = ? ORDER BY updated_at DESC
|
||||
''', (user_id,)
|
||||
)
|
||||
|
||||
res = c.fetchall()
|
||||
c.close()
|
||||
conversations = []
|
||||
for row in res:
|
||||
cid = row[0]
|
||||
created_at = row[1]
|
||||
updated_at = row[2]
|
||||
conversations.append(WebChatConversation("", cid, '[]', created_at, updated_at))
|
||||
return conversations
|
||||
|
||||
def update_webchat_conversation(self, user_id: str, cid: str, history: str):
|
||||
self._exec_sql(
|
||||
'''
|
||||
UPDATE webchat_conversation SET history = ? WHERE user_id = ? AND cid = ?
|
||||
''', (history, user_id, cid)
|
||||
)
|
||||
|
||||
def delete_webchat_conversation(self, user_id: str, cid: str):
|
||||
self._exec_sql(
|
||||
'''
|
||||
DELETE FROM webchat_conversation WHERE user_id = ? AND cid = ?
|
||||
''', (user_id, cid)
|
||||
)
|
||||
|
||||
|
||||
def insert_atri_vision_data(self, vision: ATRIVision):
|
||||
ts = int(time.time())
|
||||
keywords = ",".join(vision.keywords)
|
||||
self._exec_sql(
|
||||
'''
|
||||
INSERT INTO atri_vision(id, url_or_path, caption, is_meme, keywords, platform_name, session_id, sender_nickname, timestamp) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
|
||||
''', (vision.id, vision.url_or_path, vision.caption, vision.is_meme, keywords, vision.platform_name, vision.session_id, vision.sender_nickname, ts)
|
||||
)
|
||||
|
||||
def get_atri_vision_data(self) -> Tuple:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
SELECT * FROM atri_vision
|
||||
'''
|
||||
)
|
||||
|
||||
res = c.fetchall()
|
||||
visions = []
|
||||
for row in res:
|
||||
visions.append(ATRIVision(*row))
|
||||
c.close()
|
||||
return visions
|
||||
|
||||
def get_atri_vision_data_by_path_or_id(self, url_or_path: str, id: str) -> ATRIVision:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
SELECT * FROM atri_vision WHERE url_or_path = ? OR id = ?
|
||||
''', (url_or_path, id)
|
||||
)
|
||||
|
||||
res = c.fetchone()
|
||||
c.close()
|
||||
if res:
|
||||
return ATRIVision(*res)
|
||||
return None
|
||||
46
astrbot/core/db/sqlite_init.sql
Normal file
46
astrbot/core/db/sqlite_init.sql
Normal file
@@ -0,0 +1,46 @@
|
||||
CREATE TABLE IF NOT EXISTS platform(
|
||||
name VARCHAR(32),
|
||||
count INTEGER,
|
||||
timestamp INTEGER
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS llm(
|
||||
name VARCHAR(32),
|
||||
count INTEGER,
|
||||
timestamp INTEGER
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS plugin(
|
||||
name VARCHAR(32),
|
||||
count INTEGER,
|
||||
timestamp INTEGER
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS command(
|
||||
name VARCHAR(32),
|
||||
count INTEGER,
|
||||
timestamp INTEGER
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS llm_history(
|
||||
provider_type VARCHAR(32),
|
||||
session_id VARCHAR(32),
|
||||
content TEXT
|
||||
);
|
||||
|
||||
-- ATRI
|
||||
CREATE TABLE IF NOT EXISTS atri_vision(
|
||||
id TEXT,
|
||||
url_or_path TEXT,
|
||||
caption TEXT,
|
||||
is_meme BOOLEAN,
|
||||
keywords TEXT,
|
||||
platform_name VARCHAR(32),
|
||||
session_id VARCHAR(32),
|
||||
sender_nickname VARCHAR(32),
|
||||
timestamp INTEGER
|
||||
);
|
||||
|
||||
CREATE TABLE IF NOT EXISTS webchat_conversation(
|
||||
user_id TEXT,
|
||||
cid TEXT,
|
||||
history TEXT,
|
||||
created_at INTEGER,
|
||||
updated_at INTEGER
|
||||
);
|
||||
23
astrbot/core/event_bus.py
Normal file
23
astrbot/core/event_bus.py
Normal file
@@ -0,0 +1,23 @@
|
||||
import asyncio
|
||||
from asyncio import Queue
|
||||
from astrbot.core.pipeline.scheduler import PipelineScheduler
|
||||
from astrbot.core import logger
|
||||
from .platform import AstrMessageEvent
|
||||
|
||||
class EventBus:
|
||||
def __init__(self, event_queue: Queue, pipeline_scheduler: PipelineScheduler):
|
||||
self.event_queue = event_queue
|
||||
self.pipeline_scheduler = pipeline_scheduler
|
||||
|
||||
async def dispatch(self):
|
||||
logger.info("事件总线已打开。")
|
||||
while True:
|
||||
event: AstrMessageEvent = await self.event_queue.get()
|
||||
self._print_event(event)
|
||||
asyncio.create_task(self.pipeline_scheduler.execute(event))
|
||||
|
||||
def _print_event(self, event: AstrMessageEvent):
|
||||
if event.get_sender_name():
|
||||
logger.info(f"[{event.get_platform_name()}] {event.get_sender_name()}/{event.get_sender_id()}: {event.get_message_outline()}")
|
||||
else:
|
||||
logger.info(f"[{event.get_platform_name()}] {event.get_sender_id()}: {event.get_message_outline()}")
|
||||
79
astrbot/core/log.py
Normal file
79
astrbot/core/log.py
Normal file
@@ -0,0 +1,79 @@
|
||||
import logging
|
||||
import colorlog
|
||||
import asyncio
|
||||
from collections import deque
|
||||
from asyncio import Queue
|
||||
from typing import List
|
||||
|
||||
CACHED_SIZE = 200
|
||||
log_color_config = {
|
||||
'DEBUG': 'bold_blue', 'INFO': 'bold_cyan',
|
||||
'WARNING': 'bold_yellow', 'ERROR': 'red',
|
||||
'CRITICAL': 'bold_red', 'RESET': 'reset',
|
||||
'asctime': 'green'
|
||||
}
|
||||
|
||||
class LogBroker:
|
||||
def __init__(self):
|
||||
self.log_cache = deque(maxlen=CACHED_SIZE)
|
||||
self.subscribers: List[Queue] = []
|
||||
|
||||
def register(self) -> Queue:
|
||||
'''给每个订阅者返回一个带有日志缓存的队列'''
|
||||
q = Queue(maxsize=CACHED_SIZE + 10)
|
||||
for log in self.log_cache:
|
||||
q.put_nowait(log)
|
||||
self.subscribers.append(q)
|
||||
return q
|
||||
|
||||
def unregister(self, q: Queue):
|
||||
'''取消订阅'''
|
||||
self.subscribers.remove(q)
|
||||
|
||||
def publish(self, log_entry: str):
|
||||
'''发布消息'''
|
||||
self.log_cache.append(log_entry)
|
||||
for q in self.subscribers:
|
||||
try:
|
||||
q.put_nowait(log_entry)
|
||||
except asyncio.QueueFull:
|
||||
pass
|
||||
|
||||
class LogQueueHandler(logging.Handler):
|
||||
def __init__(self, log_broker: LogBroker):
|
||||
super().__init__()
|
||||
self.log_broker = log_broker
|
||||
|
||||
def emit(self, record):
|
||||
log_entry = self.format(record)
|
||||
self.log_broker.publish(log_entry)
|
||||
|
||||
class LogManager:
|
||||
|
||||
@classmethod
|
||||
def GetLogger(cls, log_name: str = 'default'):
|
||||
logger = logging.getLogger(log_name)
|
||||
if logger.hasHandlers():
|
||||
return logger
|
||||
console_handler = logging.StreamHandler()
|
||||
console_handler.setLevel(logging.DEBUG)
|
||||
console_formatter = colorlog.ColoredFormatter(
|
||||
fmt='%(log_color)s [%(asctime)s| %(levelname)s] [%(filename)s:%(lineno)d]: %(message)s %(reset)s',
|
||||
datefmt='%H:%M:%S',
|
||||
log_colors=log_color_config
|
||||
)
|
||||
console_handler.setFormatter(console_formatter)
|
||||
logger.setLevel(logging.DEBUG)
|
||||
logger.addHandler(console_handler)
|
||||
|
||||
return logger
|
||||
|
||||
@classmethod
|
||||
def set_queue_handler(cls, logger: logging.Logger, log_broker: LogBroker):
|
||||
handler = LogQueueHandler(log_broker)
|
||||
handler.setLevel(logging.DEBUG)
|
||||
if logger.handlers:
|
||||
handler.setFormatter(logger.handlers[0].formatter)
|
||||
else:
|
||||
handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
|
||||
logger.addHandler(handler)
|
||||
458
astrbot/core/message/components.py
Normal file
458
astrbot/core/message/components.py
Normal file
@@ -0,0 +1,458 @@
|
||||
'''
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2021 Lxns-Network
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
'''
|
||||
|
||||
import base64
|
||||
import json
|
||||
import os
|
||||
import typing as T
|
||||
from enum import Enum
|
||||
from pydantic.v1 import BaseModel
|
||||
|
||||
class ComponentType(Enum):
|
||||
Plain = "Plain"
|
||||
Face = "Face"
|
||||
Record = "Record"
|
||||
Video = "Video"
|
||||
At = "At"
|
||||
RPS = "RPS" # TODO
|
||||
Dice = "Dice" # TODO
|
||||
Shake = "Shake" # TODO
|
||||
Anonymous = "Anonymous" # TODO
|
||||
Share = "Share"
|
||||
Contact = "Contact" # TODO
|
||||
Location = "Location" # TODO
|
||||
Music = "Music"
|
||||
Image = "Image"
|
||||
Reply = "Reply"
|
||||
RedBag = "RedBag"
|
||||
Poke = "Poke"
|
||||
Forward = "Forward"
|
||||
Node = "Node"
|
||||
Xml = "Xml"
|
||||
Json = "Json"
|
||||
CardImage = "CardImage"
|
||||
TTS = "TTS"
|
||||
Unknown = "Unknown"
|
||||
File = "File"
|
||||
|
||||
|
||||
class BaseMessageComponent(BaseModel):
|
||||
type: ComponentType
|
||||
|
||||
def toString(self):
|
||||
output = f"[CQ:{self.type.lower()}"
|
||||
for k, v in self.__dict__.items():
|
||||
if k == "type" or v is None:
|
||||
continue
|
||||
if k == "_type":
|
||||
k = "type"
|
||||
if isinstance(v, bool):
|
||||
v = 1 if v else 0
|
||||
output += ",%s=%s" % (k, str(v).replace("&", "&") \
|
||||
.replace(",", ",") \
|
||||
.replace("[", "[") \
|
||||
.replace("]", "]"))
|
||||
output += "]"
|
||||
return output
|
||||
|
||||
def toDict(self):
|
||||
data = dict()
|
||||
for k, v in self.__dict__.items():
|
||||
if k == "type" or v is None:
|
||||
continue
|
||||
if k == "_type":
|
||||
k = "type"
|
||||
data[k] = v
|
||||
return {
|
||||
"type": self.type.lower(),
|
||||
"data": data
|
||||
}
|
||||
|
||||
|
||||
class Plain(BaseMessageComponent):
|
||||
type: ComponentType = "Plain"
|
||||
text: str
|
||||
convert: T.Optional[bool] = True # 若为 False 则直接发送未转换 CQ 码的消息
|
||||
|
||||
def __init__(self, text: str, convert: bool = True, **_):
|
||||
super().__init__(text=text, convert=convert, **_)
|
||||
|
||||
def toString(self): # 没有 [CQ:plain] 这种东西,所以直接导出纯文本
|
||||
if not self.convert:
|
||||
return self.text
|
||||
return self.text.replace("&", "&") \
|
||||
.replace("[", "[") \
|
||||
.replace("]", "]")
|
||||
|
||||
|
||||
class Face(BaseMessageComponent):
|
||||
type: ComponentType = "Face"
|
||||
id: int
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Record(BaseMessageComponent):
|
||||
type: ComponentType = "Record"
|
||||
file: T.Optional[str] = ""
|
||||
magic: T.Optional[bool] = False
|
||||
url: T.Optional[str] = ""
|
||||
cache: T.Optional[bool] = True
|
||||
proxy: T.Optional[bool] = True
|
||||
timeout: T.Optional[int] = 0
|
||||
# 额外
|
||||
path: T.Optional[str]
|
||||
|
||||
def __init__(self, file: T.Optional[str], **_):
|
||||
for k in _.keys():
|
||||
if k == "url":
|
||||
pass
|
||||
# Protocol.warn(f"go-cqhttp doesn't support send {self.type} by {k}")
|
||||
super().__init__(file=file, **_)
|
||||
|
||||
@staticmethod
|
||||
def fromFileSystem(path, **_):
|
||||
return Record(file=f"file:///{os.path.abspath(path)}", path=path, **_)
|
||||
|
||||
@staticmethod
|
||||
def fromURL(url: str, **_):
|
||||
if url.startswith("http://") or url.startswith("https://"):
|
||||
return Record(file=url, **_)
|
||||
raise Exception("not a valid url")
|
||||
|
||||
|
||||
class Video(BaseMessageComponent):
|
||||
type: ComponentType = "Video"
|
||||
file: str
|
||||
cover: T.Optional[str] = ""
|
||||
c: T.Optional[int] = 2
|
||||
# 额外
|
||||
path: T.Optional[str] = ""
|
||||
|
||||
def __init__(self, file: str, **_):
|
||||
# for k in _.keys():
|
||||
# if k == "c" and _[k] not in [2, 3]:
|
||||
# logger.warn(f"Protocol: {k}={_[k]} doesn't match values")
|
||||
super().__init__(file=file, **_)
|
||||
|
||||
@staticmethod
|
||||
def fromFileSystem(path, **_):
|
||||
return Video(file=f"file:///{os.path.abspath(path)}", path=path, **_)
|
||||
|
||||
@staticmethod
|
||||
def fromURL(url: str, **_):
|
||||
if url.startswith("http://") or url.startswith("https://"):
|
||||
return Video(file=url, **_)
|
||||
raise Exception("not a valid url")
|
||||
|
||||
|
||||
class At(BaseMessageComponent):
|
||||
type: ComponentType = "At"
|
||||
qq: T.Union[int, str] # 此处str为all时代表所有人
|
||||
name: T.Optional[str] = ""
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class AtAll(At):
|
||||
qq: str = "all"
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class RPS(BaseMessageComponent): # TODO
|
||||
type: ComponentType = "RPS"
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Dice(BaseMessageComponent): # TODO
|
||||
type: ComponentType = "Dice"
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Shake(BaseMessageComponent): # TODO
|
||||
type: ComponentType = "Shake"
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Anonymous(BaseMessageComponent): # TODO
|
||||
type: ComponentType = "Anonymous"
|
||||
ignore: T.Optional[bool] = False
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Share(BaseMessageComponent):
|
||||
type: ComponentType = "Share"
|
||||
url: str
|
||||
title: str
|
||||
content: T.Optional[str] = ""
|
||||
image: T.Optional[str] = ""
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Contact(BaseMessageComponent): # TODO
|
||||
type: ComponentType = "Contact"
|
||||
_type: str # type 字段冲突
|
||||
id: T.Optional[int] = 0
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Location(BaseMessageComponent): # TODO
|
||||
type: ComponentType = "Location"
|
||||
lat: float
|
||||
lon: float
|
||||
title: T.Optional[str] = ""
|
||||
content: T.Optional[str] = ""
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Music(BaseMessageComponent):
|
||||
type: ComponentType = "Music"
|
||||
_type: str
|
||||
id: T.Optional[int] = 0
|
||||
url: T.Optional[str] = ""
|
||||
audio: T.Optional[str] = ""
|
||||
title: T.Optional[str] = ""
|
||||
content: T.Optional[str] = ""
|
||||
image: T.Optional[str] = ""
|
||||
|
||||
def __init__(self, **_):
|
||||
# for k in _.keys():
|
||||
# if k == "_type" and _[k] not in ["qq", "163", "xm", "custom"]:
|
||||
# logger.warn(f"Protocol: {k}={_[k]} doesn't match values")
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Image(BaseMessageComponent):
|
||||
type: ComponentType = "Image"
|
||||
file: T.Optional[str] = ""
|
||||
_type: T.Optional[str] = ""
|
||||
subType: T.Optional[int] = 0
|
||||
url: T.Optional[str] = ""
|
||||
cache: T.Optional[bool] = True
|
||||
id: T.Optional[int] = 40000
|
||||
c: T.Optional[int] = 2
|
||||
# 额外
|
||||
path: T.Optional[str] = ""
|
||||
file_unique: T.Optional[str] = "" # 某些平台可能有图片缓存的唯一标识
|
||||
|
||||
def __init__(self, file: T.Optional[str], **_):
|
||||
# for k in _.keys():
|
||||
# if (k == "_type" and _[k] not in ["flash", "show", None]) or \
|
||||
# (k == "c" and _[k] not in [2, 3]):
|
||||
# logger.warn(f"Protocol: {k}={_[k]} doesn't match values")
|
||||
super().__init__(file=file, **_)
|
||||
|
||||
@staticmethod
|
||||
def fromURL(url: str, **_):
|
||||
if url.startswith("http://") or url.startswith("https://"):
|
||||
return Image(file=url, **_)
|
||||
raise Exception("not a valid url")
|
||||
|
||||
@staticmethod
|
||||
def fromFileSystem(path, **_):
|
||||
return Image(file=f"file:///{os.path.abspath(path)}", path=path, **_)
|
||||
|
||||
@staticmethod
|
||||
def fromBase64(base64: str, **_):
|
||||
return Image(f"base64://{base64}", **_)
|
||||
|
||||
@staticmethod
|
||||
def fromBytes(byte: bytes):
|
||||
return Image.fromBase64(base64.b64encode(byte).decode())
|
||||
|
||||
@staticmethod
|
||||
def fromIO(IO):
|
||||
return Image.fromBytes(IO.read())
|
||||
|
||||
|
||||
class Reply(BaseMessageComponent):
|
||||
type: ComponentType = "Reply"
|
||||
id: int
|
||||
text: T.Optional[str] = ""
|
||||
qq: T.Optional[int] = 0
|
||||
time: T.Optional[int] = 0
|
||||
seq: T.Optional[int] = 0
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class RedBag(BaseMessageComponent):
|
||||
type: ComponentType = "RedBag"
|
||||
title: str
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Poke(BaseMessageComponent):
|
||||
type: ComponentType = "Poke"
|
||||
qq: int
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Forward(BaseMessageComponent):
|
||||
type: ComponentType = "Forward"
|
||||
id: str
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Node(BaseMessageComponent): # 该 component 仅支持使用 sendGroupForwardMessage 发送
|
||||
type: ComponentType = "Node"
|
||||
id: T.Optional[int] = 0
|
||||
name: T.Optional[str] = ""
|
||||
uin: T.Optional[int] = 0
|
||||
content: T.Optional[T.Union[str, list]] = ""
|
||||
seq: T.Optional[T.Union[str, list]] = "" # 不清楚是什么
|
||||
time: T.Optional[int] = 0
|
||||
|
||||
def __init__(self, content: T.Union[str, list], **_):
|
||||
if isinstance(content, list):
|
||||
_content = ""
|
||||
for chain in content:
|
||||
_content += chain.toString()
|
||||
content = _content
|
||||
super().__init__(content=content, **_)
|
||||
|
||||
def toString(self):
|
||||
# logger.warn("Protocol: node doesn't support stringify")
|
||||
return ""
|
||||
|
||||
|
||||
class Xml(BaseMessageComponent):
|
||||
type: ComponentType = "Xml"
|
||||
data: str
|
||||
resid: T.Optional[int] = 0
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Json(BaseMessageComponent):
|
||||
type: ComponentType = "Json"
|
||||
data: T.Union[str, dict]
|
||||
resid: T.Optional[int] = 0
|
||||
|
||||
def __init__(self, data, **_):
|
||||
if isinstance(data, dict):
|
||||
data = json.dumps(data)
|
||||
super().__init__(data=data, **_)
|
||||
|
||||
|
||||
class CardImage(BaseMessageComponent):
|
||||
type: ComponentType = "CardImage"
|
||||
file: str
|
||||
cache: T.Optional[bool] = True
|
||||
minwidth: T.Optional[int] = 400
|
||||
minheight: T.Optional[int] = 400
|
||||
maxwidth: T.Optional[int] = 500
|
||||
maxheight: T.Optional[int] = 500
|
||||
source: T.Optional[str] = ""
|
||||
icon: T.Optional[str] = ""
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
@staticmethod
|
||||
def fromFileSystem(path, **_):
|
||||
return CardImage(file=f"file:///{os.path.abspath(path)}", **_)
|
||||
|
||||
|
||||
class TTS(BaseMessageComponent):
|
||||
type: ComponentType = "TTS"
|
||||
text: str
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Unknown(BaseMessageComponent):
|
||||
type: ComponentType = "Unknown"
|
||||
text: str
|
||||
|
||||
def toString(self):
|
||||
return ""
|
||||
|
||||
class File(BaseMessageComponent):
|
||||
'''
|
||||
目前此消息段只适配了 Napcat。
|
||||
'''
|
||||
type: ComponentType = "File"
|
||||
name: T.Optional[str] = "" # 名字
|
||||
file: T.Optional[str] = "" # url(本地路径)
|
||||
|
||||
def __init__(self, name: str, file: str):
|
||||
super().__init__(name=name, file=file)
|
||||
|
||||
|
||||
ComponentTypes = {
|
||||
"plain": Plain,
|
||||
"text": Plain,
|
||||
"face": Face,
|
||||
"record": Record,
|
||||
"video": Video,
|
||||
"at": At,
|
||||
"rps": RPS,
|
||||
"dice": Dice,
|
||||
"shake": Shake,
|
||||
"anonymous": Anonymous,
|
||||
"share": Share,
|
||||
"contact": Contact,
|
||||
"location": Location,
|
||||
"music": Music,
|
||||
"image": Image,
|
||||
"reply": Reply,
|
||||
"redbag": RedBag,
|
||||
"poke": Poke,
|
||||
"forward": Forward,
|
||||
"node": Node,
|
||||
"xml": Xml,
|
||||
"json": Json,
|
||||
"cardimage": CardImage,
|
||||
"tts": TTS,
|
||||
"unknown": Unknown,
|
||||
'file': File,
|
||||
}
|
||||
144
astrbot/core/message/message_event_result.py
Normal file
144
astrbot/core/message/message_event_result.py
Normal file
@@ -0,0 +1,144 @@
|
||||
import enum
|
||||
|
||||
from typing import List, Optional
|
||||
from dataclasses import dataclass, field
|
||||
from astrbot.core.message.components import BaseMessageComponent, Plain, Image
|
||||
from typing_extensions import deprecated
|
||||
|
||||
@dataclass
|
||||
class MessageChain():
|
||||
'''MessageChain 描述了一整条消息中带有的所有组件。
|
||||
现代消息平台的一条富文本消息中可能由多个组件构成,如文本、图片、At 等,并且保留了顺序。
|
||||
|
||||
Attributes:
|
||||
`chain` (list): 用于顺序存储各个组件。
|
||||
`use_t2i_` (bool): 用于标记是否使用文本转图片服务。默认为 None,即跟随用户的设置。当设置为 True 时,将会使用文本转图片服务。
|
||||
'''
|
||||
|
||||
chain: List[BaseMessageComponent] = field(default_factory=list)
|
||||
use_t2i_: Optional[bool] = None # None 为跟随用户设置
|
||||
|
||||
def message(self, message: str):
|
||||
'''添加一条文本消息到消息链 `chain` 中。
|
||||
|
||||
Example:
|
||||
|
||||
CommandResult().message("Hello ").message("world!")
|
||||
# 输出 Hello world!
|
||||
|
||||
'''
|
||||
self.chain.append(Plain(message))
|
||||
return self
|
||||
|
||||
@deprecated("请使用 message 方法代替。")
|
||||
def error(self, message: str):
|
||||
'''添加一条错误消息到消息链 `chain` 中
|
||||
|
||||
Example:
|
||||
|
||||
CommandResult().error("解析失败")
|
||||
|
||||
'''
|
||||
self.chain.append(Plain(message))
|
||||
return self
|
||||
|
||||
def url_image(self, url: str):
|
||||
'''添加一条图片消息(https 链接)到消息链 `chain` 中。
|
||||
|
||||
Note:
|
||||
如果需要发送本地图片,请使用 `file_image` 方法。
|
||||
|
||||
Example:
|
||||
|
||||
CommandResult().image("https://example.com/image.jpg")
|
||||
|
||||
'''
|
||||
self.chain.append(Image.fromURL(url))
|
||||
return self
|
||||
|
||||
def file_image(self, path: str):
|
||||
'''添加一条图片消息(本地文件路径)到消息链 `chain` 中。
|
||||
|
||||
Note:
|
||||
如果需要发送网络图片,请使用 `url_image` 方法。
|
||||
|
||||
CommandResult().image("image.jpg")
|
||||
'''
|
||||
self.chain.append(Image.fromFileSystem(path))
|
||||
return self
|
||||
|
||||
def use_t2i(self, use_t2i: bool):
|
||||
'''设置是否使用文本转图片服务。
|
||||
|
||||
Args:
|
||||
use_t2i (bool): 是否使用文本转图片服务。默认为 None,即跟随用户的设置。当设置为 True 时,将会使用文本转图片服务。
|
||||
'''
|
||||
self.use_t2i_ = use_t2i
|
||||
return self
|
||||
|
||||
class EventResultType(enum.Enum):
|
||||
'''用于描述事件处理的结果类型。
|
||||
|
||||
Attributes:
|
||||
CONTINUE: 事件将会继续传播
|
||||
STOP: 事件将会终止传播
|
||||
'''
|
||||
CONTINUE = enum.auto()
|
||||
STOP = enum.auto()
|
||||
|
||||
class ResultContentType(enum.Enum):
|
||||
'''用于描述事件结果的内容的类型。
|
||||
'''
|
||||
LLM_RESULT = enum.auto()
|
||||
'''调用 LLM 产生的结果'''
|
||||
GENERAL_RESULT = enum.auto()
|
||||
'''普通的消息结果'''
|
||||
@dataclass
|
||||
class MessageEventResult(MessageChain):
|
||||
'''MessageEventResult 描述了一整条消息中带有的所有组件以及事件处理的结果。
|
||||
现代消息平台的一条富文本消息中可能由多个组件构成,如文本、图片、At 等,并且保留了顺序。
|
||||
|
||||
Attributes:
|
||||
`chain` (list): 用于顺序存储各个组件。
|
||||
`use_t2i_` (bool): 用于标记是否使用文本转图片服务。默认为 None,即跟随用户的设置。当设置为 True 时,将会使用文本转图片服务。
|
||||
`result_type` (EventResultType): 事件处理的结果类型。
|
||||
'''
|
||||
|
||||
result_type: Optional[EventResultType] = field(default_factory=lambda: EventResultType.CONTINUE)
|
||||
|
||||
result_content_type: Optional[ResultContentType] = field(default_factory=lambda: ResultContentType.GENERAL_RESULT)
|
||||
|
||||
def stop_event(self) -> 'MessageEventResult':
|
||||
'''终止事件传播。
|
||||
'''
|
||||
self.result_type = EventResultType.STOP
|
||||
return self
|
||||
|
||||
def continue_event(self) -> 'MessageEventResult':
|
||||
'''继续事件传播。
|
||||
'''
|
||||
self.result_type = EventResultType.CONTINUE
|
||||
return self
|
||||
|
||||
def is_stopped(self) -> bool:
|
||||
'''
|
||||
是否终止事件传播。
|
||||
'''
|
||||
return self.result_type == EventResultType.STOP
|
||||
|
||||
def set_result_content_type(self, typ: ResultContentType) -> 'MessageEventResult':
|
||||
'''设置事件处理的结果类型。
|
||||
|
||||
Args:
|
||||
result_type (EventResultType): 事件处理的结果类型。
|
||||
'''
|
||||
self.result_content_type = typ
|
||||
return self
|
||||
|
||||
def is_llm_result(self) -> bool:
|
||||
'''是否为 LLM 结果。
|
||||
'''
|
||||
return self.result_content_type == ResultContentType.LLM_RESULT
|
||||
|
||||
|
||||
CommandResult = MessageEventResult
|
||||
32
astrbot/core/pipeline/__init__.py
Normal file
32
astrbot/core/pipeline/__init__.py
Normal file
@@ -0,0 +1,32 @@
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, EventResultType
|
||||
|
||||
from .waking_check.stage import WakingCheckStage
|
||||
from .whitelist_check.stage import WhitelistCheckStage
|
||||
from .content_safety_check.stage import ContentSafetyCheckStage
|
||||
from .preprocess_stage.stage import PreProcessStage
|
||||
from .process_stage.stage import ProcessStage
|
||||
from .result_decorate.stage import ResultDecorateStage
|
||||
from .respond.stage import RespondStage
|
||||
|
||||
STAGES_ORDER = [
|
||||
"WakingCheckStage", # 检查是否需要唤醒
|
||||
"WhitelistCheckStage", # 检查是否在群聊/私聊白名单
|
||||
"RateLimitCheckStage", # 检查会话是否超过频率限制
|
||||
"ContentSafetyCheckStage", # 检查内容安全
|
||||
"PreProcessStage", # 预处理
|
||||
"ProcessStage", # 交由 Stars 处理(a.k.a 插件),或者 LLM 调用
|
||||
"ResultDecorateStage", # 处理结果,比如添加回复前缀、t2i、转换为语音 等
|
||||
"RespondStage" # 发送消息
|
||||
]
|
||||
|
||||
__all__ = [
|
||||
"WakingCheckStage",
|
||||
"WhitelistCheckStage",
|
||||
"ContentSafetyCheckStage",
|
||||
"PreProcessStage",
|
||||
"ProcessStage",
|
||||
"ResultDecorateStage",
|
||||
"RespondStage",
|
||||
"MessageEventResult",
|
||||
"EventResultType"
|
||||
]
|
||||
28
astrbot/core/pipeline/content_safety_check/stage.py
Normal file
28
astrbot/core/pipeline/content_safety_check/stage.py
Normal file
@@ -0,0 +1,28 @@
|
||||
from typing import Union, AsyncGenerator
|
||||
from ..stage import Stage, register_stage
|
||||
from ..context import PipelineContext
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult
|
||||
from astrbot.core import logger
|
||||
from .strategies.strategy import StrategySelector
|
||||
|
||||
@register_stage
|
||||
class ContentSafetyCheckStage(Stage):
|
||||
'''检查内容安全
|
||||
|
||||
当前只会检查文本的。
|
||||
'''
|
||||
|
||||
async def initialize(self, ctx: PipelineContext):
|
||||
config = ctx.astrbot_config['content_safety']
|
||||
self.strategy_selector = StrategySelector(config)
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
'''检查内容安全'''
|
||||
ok, info = self.strategy_selector.check(event.get_message_str())
|
||||
if not ok:
|
||||
event.set_result(MessageEventResult().message("你的消息中包含不适当的内容,已被屏蔽。"))
|
||||
event.stop_event()
|
||||
logger.info(f"内容安全检查不通过,原因:{info}")
|
||||
return
|
||||
event.continue_event()
|
||||
@@ -0,0 +1,8 @@
|
||||
import abc
|
||||
from typing import Tuple
|
||||
|
||||
class ContentSafetyStrategy(abc.ABC):
|
||||
|
||||
@abc.abstractmethod
|
||||
def check(self, content: str) -> Tuple[bool, str]:
|
||||
raise NotImplementedError
|
||||
@@ -0,0 +1,30 @@
|
||||
'''
|
||||
使用此功能应该先 pip install baidu-aip
|
||||
'''
|
||||
from . import ContentSafetyStrategy
|
||||
from aip import AipContentCensor
|
||||
|
||||
class BaiduAipStrategy(ContentSafetyStrategy):
|
||||
def __init__(self, appid: str, ak: str, sk: str) -> None:
|
||||
self.app_id = appid
|
||||
self.api_key = ak
|
||||
self.secret_key = sk
|
||||
self.client = AipContentCensor(self.app_id,
|
||||
self.api_key,
|
||||
self.secret_key)
|
||||
|
||||
def check(self, content: str):
|
||||
res = self.client.textCensorUserDefined(content)
|
||||
if 'conclusionType' not in res:
|
||||
return False, ""
|
||||
if res['conclusionType'] == 1:
|
||||
return True, ""
|
||||
else:
|
||||
if 'data' not in res:
|
||||
return False, ""
|
||||
count = len(res['data'])
|
||||
info = f"百度审核服务发现 {count} 处违规:\n"
|
||||
for i in res['data']:
|
||||
info += f"{i['msg']};\n"
|
||||
info += "\n判断结果:"+res['conclusion']
|
||||
return False, info
|
||||
@@ -0,0 +1,23 @@
|
||||
import re
|
||||
import os
|
||||
import json
|
||||
import base64
|
||||
from . import ContentSafetyStrategy
|
||||
|
||||
class KeywordsStrategy(ContentSafetyStrategy):
|
||||
def __init__(self, extra_keywords: list) -> None:
|
||||
self.keywords = []
|
||||
if extra_keywords is None:
|
||||
extra_keywords = []
|
||||
self.keywords.extend(extra_keywords)
|
||||
keywords_path = os.path.join(os.path.dirname(__file__), 'unfit_words')
|
||||
# internal keywords
|
||||
if os.path.exists(keywords_path):
|
||||
with open(keywords_path, "r", encoding="utf-8") as f:
|
||||
self.keywords.extend(json.loads(base64.b64decode(f.read()).decode("utf-8"))['keywords'])
|
||||
|
||||
def check(self, content: str) -> bool:
|
||||
for keyword in self.keywords:
|
||||
if re.search(keyword, content):
|
||||
return False, "内容安全检查不通过,匹配到敏感词。"
|
||||
return True, ""
|
||||
@@ -0,0 +1,33 @@
|
||||
from . import ContentSafetyStrategy
|
||||
from typing import List, Tuple
|
||||
from astrbot import logger
|
||||
|
||||
class StrategySelector:
|
||||
def __init__(self, config: dict) -> None:
|
||||
self.enabled_strategies: List[ContentSafetyStrategy] = []
|
||||
if config["internal_keywords"]["enable"]:
|
||||
from .keywords import KeywordsStrategy
|
||||
|
||||
self.enabled_strategies.append(
|
||||
KeywordsStrategy(config["internal_keywords"]["extra_keywords"])
|
||||
)
|
||||
if config["baidu_aip"]["enable"]:
|
||||
try:
|
||||
from .baidu_aip import BaiduAipStrategy
|
||||
except ImportError:
|
||||
logger.warning("使用百度内容审核应该先 pip install baidu-aip")
|
||||
return
|
||||
self.enabled_strategies.append(
|
||||
BaiduAipStrategy(
|
||||
config["baidu_aip"]["app_id"],
|
||||
config["baidu_aip"]["api_key"],
|
||||
config["baidu_aip"]["secret_key"],
|
||||
)
|
||||
)
|
||||
|
||||
def check(self, content: str) -> Tuple[bool, str]:
|
||||
for strategy in self.enabled_strategies:
|
||||
ok, info = strategy.check(content)
|
||||
if not ok:
|
||||
return False, info
|
||||
return True, ""
|
||||
@@ -0,0 +1 @@
|
||||
ewogICAgImtleXdvcmRzIjogWwogICAgICAgICLkuaDov5HlubMiLAogICAgICAgICLog6HplKbmtpsiLAogICAgICAgICLmsZ/ms73msJEiLAogICAgICAgICLmuKnlrrblrp0iLAogICAgICAgICLmnY7lhYvlvLoiLAogICAgICAgICLmnY7plb/mmKUiLAogICAgICAgICLmr5vms73kuJwiLAogICAgICAgICLpgpPlsI/lubMiLAogICAgICAgICLlkajmganmnaUiLAogICAgICAgICLnpL7kvJrkuLvkuYkiLAogICAgICAgICLlhbHkuqflhZoiLAogICAgICAgICLlhbHkuqfkuLvkuYkiLAogICAgICAgICLlpKfpmYblrpjmlrkiLAogICAgICAgICLljJfkuqzmlL/mnYMiLAogICAgICAgICLkuK3ljY7luJ3lm70iLAogICAgICAgICLkuK3lm73mlL/lupwiLAogICAgICAgICLlhbHni5ciLAogICAgICAgICLlha3lm5vkuovku7YiLAogICAgICAgICLlpKnlronpl6giLAogICAgICAgICLlha3lm5siLAogICAgICAgICLmlL/msrvlsYDluLjlp5QiLAogICAgICAgICLlrabmva4iLAogICAgICAgICLlhavkuZ0iLAogICAgICAgICLkuozljYHlpKciLAogICAgICAgICLmsJHov5vlhZoiLAogICAgICAgICLlj7Dni6wiLAogICAgICAgICLlj7Dmub7ni6znq4siLAogICAgICAgICLlj7Dmub7lm70iLAogICAgICAgICLlm73msJHlhZoiLAogICAgICAgICLlj7Dmub7msJHlm70iLAogICAgICAgICLkuK3ljY7msJHlm70iLAogICAgICAgICJwb3JuaHViIiwKICAgICAgICAiUG9ybmh1YiIsCiAgICAgICAgIuS9nOeIsSIsCiAgICAgICAgIuWBmueIsSIsCiAgICAgICAgIuaAp+S6pCIsCiAgICAgICAgIuiHquaFsCIsCiAgICAgICAgIumYtOiMjiIsCiAgICAgICAgIua3q+WmhyIsCiAgICAgICAgIuiCm+S6pCIsCiAgICAgICAgIuS6pOmFjSIsCiAgICAgICAgIuaAp+WFs+ezuyIsCiAgICAgICAgIuaAp+a0u+WKqCIsCiAgICAgICAgIuiJsuaDhSIsCiAgICAgICAgIuiJsuWbviIsCiAgICAgICAgIuijuOS9kyIsCiAgICAgICAgIuWwj+eptCIsCiAgICAgICAgIua3q+iNoSIsCiAgICAgICAgIuaAp+eIsSIsCiAgICAgICAgIua4r+eLrCIsCiAgICAgICAgIuazlei9ruWKnyIsCiAgICAgICAgIuWFreWbmyIKICAgIF0KfQ==
|
||||
8
astrbot/core/pipeline/context.py
Normal file
8
astrbot/core/pipeline/context.py
Normal file
@@ -0,0 +1,8 @@
|
||||
from dataclasses import dataclass
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from astrbot.core.star import PluginManager
|
||||
|
||||
@dataclass
|
||||
class PipelineContext:
|
||||
astrbot_config: AstrBotConfig
|
||||
plugin_manager: PluginManager
|
||||
70
astrbot/core/pipeline/preprocess_stage/stage.py
Normal file
70
astrbot/core/pipeline/preprocess_stage/stage.py
Normal file
@@ -0,0 +1,70 @@
|
||||
import traceback
|
||||
import asyncio
|
||||
from typing import Union, AsyncGenerator
|
||||
from ..stage import Stage, register_stage
|
||||
from ..context import PipelineContext
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.message.components import Plain, Record, Image
|
||||
|
||||
@register_stage
|
||||
class PreProcessStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
self.config = ctx.astrbot_config
|
||||
self.plugin_manager = ctx.plugin_manager
|
||||
|
||||
self.stt_settings: dict = self.config.get('provider_stt_settings', {})
|
||||
self.platform_settings: dict = self.config.get('platform_settings', {})
|
||||
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
'''在处理事件之前的预处理'''
|
||||
# 路径映射
|
||||
if mappings := self.platform_settings.get('path_mapping', []):
|
||||
# 支持 Record,Image 消息段的路径映射。
|
||||
message_chain = event.get_messages()
|
||||
|
||||
for idx, component in enumerate(message_chain):
|
||||
if isinstance(component, (Record, Image)) and component.url:
|
||||
for mapping in mappings:
|
||||
from_, to_ = mapping.split(":")
|
||||
from_ = from_.removesuffix("/")
|
||||
to_ = to_.removesuffix("/")
|
||||
|
||||
url = component.url.removeprefix("file://")
|
||||
if url.startswith(from_):
|
||||
component.url = url.replace(from_, to_, 1)
|
||||
logger.debug(f"路径映射: {url} -> {component.url}")
|
||||
message_chain[idx] = component
|
||||
|
||||
# STT
|
||||
if self.stt_settings.get('enable', False):
|
||||
# TODO: 独立
|
||||
stt_provider = self.plugin_manager.context.provider_manager.curr_stt_provider_inst
|
||||
if stt_provider:
|
||||
message_chain = event.get_messages()
|
||||
for idx, component in enumerate(message_chain):
|
||||
if isinstance(component, Record) and component.url:
|
||||
path = component.url.removeprefix("file://")
|
||||
retry = 5
|
||||
for i in range(retry):
|
||||
try:
|
||||
result = await stt_provider.get_text(audio_url=path)
|
||||
if result:
|
||||
logger.info("语音转文本结果: " + result)
|
||||
message_chain[idx] = Plain(result)
|
||||
event.message_str += result
|
||||
event.message_obj.message_str += result
|
||||
break
|
||||
except FileNotFoundError as e:
|
||||
# napcat workaround
|
||||
logger.warning(e)
|
||||
logger.warning(f"重试中: {i + 1}/{retry}")
|
||||
await asyncio.sleep(0.5)
|
||||
continue
|
||||
except BaseException as e:
|
||||
logger.error(traceback.format_exc())
|
||||
logger.error(f"语音转文本失败: {e}")
|
||||
break
|
||||
60
astrbot/core/pipeline/process_stage/method/dify_request.py
Normal file
60
astrbot/core/pipeline/process_stage/method/dify_request.py
Normal file
@@ -0,0 +1,60 @@
|
||||
'''
|
||||
Dify 调用 Stage
|
||||
'''
|
||||
import traceback
|
||||
from typing import Union, AsyncGenerator
|
||||
from ...context import PipelineContext
|
||||
from ..stage import Stage
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, ResultContentType
|
||||
from astrbot.core.message.components import Image
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
from astrbot.core.provider.entites import ProviderRequest
|
||||
|
||||
class DifyRequestSubStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
req: ProviderRequest = None
|
||||
|
||||
provider = self.ctx.plugin_manager.context.get_using_provider()
|
||||
if provider.meta().type != "dify":
|
||||
return
|
||||
|
||||
if event.get_extra("provider_request"):
|
||||
req = event.get_extra("provider_request")
|
||||
assert isinstance(req, ProviderRequest), "provider_request 必须是 ProviderRequest 类型。"
|
||||
else:
|
||||
req = ProviderRequest(prompt="", image_urls=[])
|
||||
if self.ctx.astrbot_config['provider_settings']['wake_prefix']:
|
||||
if not event.message_str.startswith(self.ctx.astrbot_config['provider_settings']['wake_prefix']):
|
||||
return
|
||||
req.prompt = event.message_str[len(self.ctx.astrbot_config['provider_settings']['wake_prefix']):]
|
||||
for comp in event.message_obj.message:
|
||||
if isinstance(comp, Image):
|
||||
image_url = comp.url if comp.url else comp.file
|
||||
req.image_urls.append(image_url)
|
||||
req.session_id = event.session_id
|
||||
event.set_extra("provider_request", req)
|
||||
|
||||
if not req.prompt:
|
||||
return
|
||||
|
||||
try:
|
||||
logger.debug(f"Dify 请求 Payload: {req.__dict__}")
|
||||
llm_response = await provider.text_chat(**req.__dict__) # 请求 LLM
|
||||
await Metric.upload(llm_tick=1, model_name=provider.get_model(), provider_type=provider.meta().type)
|
||||
|
||||
if llm_response.role == 'assistant':
|
||||
# text completion
|
||||
event.set_result(MessageEventResult().message(llm_response.completion_text)
|
||||
.set_result_content_type(ResultContentType.LLM_RESULT))
|
||||
yield # rick roll
|
||||
|
||||
except BaseException as e:
|
||||
logger.error(traceback.format_exc())
|
||||
event.set_result(MessageEventResult().message("AstrBot 请求 Dify 失败:" + str(e)))
|
||||
return
|
||||
109
astrbot/core/pipeline/process_stage/method/llm_request.py
Normal file
109
astrbot/core/pipeline/process_stage/method/llm_request.py
Normal file
@@ -0,0 +1,109 @@
|
||||
'''
|
||||
本地 Agent 模式的 LLM 调用 Stage
|
||||
'''
|
||||
import traceback
|
||||
from typing import Union, AsyncGenerator
|
||||
from ...context import PipelineContext
|
||||
from ..stage import Stage
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, ResultContentType
|
||||
from astrbot.core.message.components import Image
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
from astrbot.core.provider.entites import ProviderRequest
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
|
||||
class LLMRequestSubStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
self.bot_wake_prefixs = ctx.astrbot_config['wake_prefix'] # list
|
||||
self.provider_wake_prefix = ctx.astrbot_config['provider_settings']['wake_prefix'] # str
|
||||
|
||||
for bwp in self.bot_wake_prefixs:
|
||||
if self.provider_wake_prefix.startswith(bwp):
|
||||
logger.info(f"识别 LLM 聊天额外唤醒前缀 {self.provider_wake_prefix} 以机器人唤醒前缀 {bwp} 开头,已自动去除。")
|
||||
self.provider_wake_prefix = self.provider_wake_prefix[len(bwp):]
|
||||
|
||||
async def process(self, event: AstrMessageEvent, _nested: bool = False) -> Union[None, AsyncGenerator[None, None]]:
|
||||
req: ProviderRequest = None
|
||||
|
||||
provider = self.ctx.plugin_manager.context.get_using_provider()
|
||||
if provider is None:
|
||||
return
|
||||
|
||||
if event.get_extra("provider_request"):
|
||||
req = event.get_extra("provider_request")
|
||||
assert isinstance(req, ProviderRequest), "provider_request 必须是 ProviderRequest 类型。"
|
||||
else:
|
||||
req = ProviderRequest(prompt="", image_urls=[])
|
||||
if self.provider_wake_prefix:
|
||||
if not event.message_str.startswith(self.provider_wake_prefix):
|
||||
return
|
||||
req.prompt = event.message_str[len(self.provider_wake_prefix):]
|
||||
req.func_tool = self.ctx.plugin_manager.context.get_llm_tool_manager()
|
||||
for comp in event.message_obj.message:
|
||||
if isinstance(comp, Image):
|
||||
image_url = comp.url if comp.url else comp.file
|
||||
req.image_urls.append(image_url)
|
||||
req.session_id = event.session_id
|
||||
event.set_extra("provider_request", req)
|
||||
session_provider_context = provider.session_memory.get(event.session_id)
|
||||
req.contexts = session_provider_context if session_provider_context else []
|
||||
|
||||
if not req.prompt and not req.image_urls:
|
||||
return
|
||||
|
||||
# 执行请求 LLM 前事件。
|
||||
# 装饰 system_prompt 等功能
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(EventType.OnLLMRequestEvent)
|
||||
for handler in handlers:
|
||||
try:
|
||||
await handler.handler(event, req)
|
||||
except BaseException:
|
||||
logger.error(traceback.format_exc())
|
||||
|
||||
try:
|
||||
logger.debug(f"提供商请求 Payload: {req.__dict__}")
|
||||
if _nested:
|
||||
req.func_tool = None # 暂时不支持递归工具调用
|
||||
llm_response = await provider.text_chat(**req.__dict__) # 请求 LLM
|
||||
await Metric.upload(llm_tick=1, model_name=provider.get_model(), provider_type=provider.meta().type)
|
||||
|
||||
if llm_response.role == 'assistant':
|
||||
# text completion
|
||||
event.set_result(MessageEventResult().message(llm_response.completion_text)
|
||||
.set_result_content_type(ResultContentType.LLM_RESULT))
|
||||
elif llm_response.role == 'tool':
|
||||
# function calling
|
||||
function_calling_result = {}
|
||||
for func_tool_name, func_tool_args in zip(llm_response.tools_call_name, llm_response.tools_call_args):
|
||||
func_tool = req.func_tool.get_func(func_tool_name)
|
||||
logger.info(f"调用工具函数:{func_tool_name},参数:{func_tool_args}")
|
||||
try:
|
||||
# 尝试调用工具函数
|
||||
wrapper = self._call_handler(self.ctx, event, func_tool.handler, **func_tool_args)
|
||||
async for resp in wrapper:
|
||||
if resp is not None:
|
||||
function_calling_result[func_tool_name] = resp
|
||||
else:
|
||||
yield
|
||||
event.clear_result() # 清除上一个 handler 的结果
|
||||
except BaseException as e:
|
||||
logger.warning(traceback.format_exc())
|
||||
function_calling_result[func_tool_name] = "When calling the function, an error occurred: " + str(e)
|
||||
if function_calling_result:
|
||||
# 工具返回 LLM 资源。比如 RAG、网页 得到的相关结果等。
|
||||
# 我们重新执行一遍这个 stage
|
||||
req.func_tool = None # 暂时不支持递归工具调用
|
||||
extra_prompt = "\n\nSystem executed some external tools for this task and here are the results:\n"
|
||||
for tool_name, tool_result in function_calling_result.items():
|
||||
extra_prompt += f"Tool: {tool_name}\nTool Result: {tool_result}\n"
|
||||
req.prompt += extra_prompt
|
||||
async for _ in self.process(event, _nested=True):
|
||||
yield
|
||||
|
||||
except BaseException as e:
|
||||
logger.error(traceback.format_exc())
|
||||
event.set_result(MessageEventResult().message(f"AstrBot 请求失败。\n错误类型: {type(e).__name__}\n错误信息: {str(e)}"))
|
||||
return
|
||||
46
astrbot/core/pipeline/process_stage/method/star_request.py
Normal file
46
astrbot/core/pipeline/process_stage/method/star_request.py
Normal file
@@ -0,0 +1,46 @@
|
||||
'''
|
||||
本地 Agent 模式的 AstrBot 插件调用 Stage
|
||||
'''
|
||||
from ...context import PipelineContext
|
||||
from ..stage import Stage
|
||||
from typing import Dict, Any, List, AsyncGenerator, Union
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.star.star_handler import StarHandlerMetadata
|
||||
from astrbot.core.star.star import star_map
|
||||
import traceback
|
||||
|
||||
class StarRequestSubStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.curr_provider = ctx.plugin_manager.context.get_using_provider()
|
||||
self.prompt_prefix = ctx.astrbot_config['provider_settings']['prompt_prefix']
|
||||
self.identifier = ctx.astrbot_config['provider_settings']['identifier']
|
||||
self.ctx = ctx
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
activated_handlers: List[StarHandlerMetadata] = event.get_extra("activated_handlers")
|
||||
handlers_parsed_params: Dict[str, Dict[str, Any]] = event.get_extra("handlers_parsed_params")
|
||||
if not handlers_parsed_params:
|
||||
handlers_parsed_params = {}
|
||||
for handler in activated_handlers:
|
||||
params = handlers_parsed_params.get(handler.handler_full_name, {})
|
||||
try:
|
||||
if handler.handler_module_path not in star_map:
|
||||
# 孤立无援的 star handler
|
||||
continue
|
||||
|
||||
logger.debug(f"执行 Star Handler {handler.handler_full_name}")
|
||||
wrapper = self._call_handler(self.ctx, event, handler.handler, **params)
|
||||
async for ret in wrapper:
|
||||
yield ret
|
||||
event.clear_result() # 清除上一个 handler 的结果
|
||||
except Exception as e:
|
||||
logger.error(traceback.format_exc())
|
||||
logger.error(f"Star {handler.handler_full_name} handle error: {e}")
|
||||
ret = f":(\n\n在调用插件 {star_map.get(handler.handler_module_path).name} 的处理函数 {handler.handler_name} 时出现异常:{e}"
|
||||
event.set_result(MessageEventResult().message(ret))
|
||||
yield
|
||||
event.clear_result()
|
||||
event.stop_event()
|
||||
58
astrbot/core/pipeline/process_stage/stage.py
Normal file
58
astrbot/core/pipeline/process_stage/stage.py
Normal file
@@ -0,0 +1,58 @@
|
||||
from typing import List, Union, AsyncGenerator
|
||||
from ..stage import Stage, register_stage
|
||||
from ..context import PipelineContext
|
||||
from .method.llm_request import LLMRequestSubStage
|
||||
from .method.star_request import StarRequestSubStage
|
||||
from .method.dify_request import DifyRequestSubStage
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.star.star_handler import StarHandlerMetadata
|
||||
from astrbot.core.provider.entites import ProviderRequest
|
||||
from astrbot.core import logger
|
||||
|
||||
@register_stage
|
||||
class ProcessStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
self.config = ctx.astrbot_config
|
||||
self.plugin_manager = ctx.plugin_manager
|
||||
self.llm_request_sub_stage = LLMRequestSubStage()
|
||||
await self.llm_request_sub_stage.initialize(ctx)
|
||||
|
||||
self.star_request_sub_stage = StarRequestSubStage()
|
||||
await self.star_request_sub_stage.initialize(ctx)
|
||||
|
||||
self.dify_request_sub_stage = DifyRequestSubStage()
|
||||
await self.dify_request_sub_stage.initialize(ctx)
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
'''处理事件
|
||||
'''
|
||||
activated_handlers: List[StarHandlerMetadata] = event.get_extra("activated_handlers")
|
||||
# 有插件 Handler 被激活
|
||||
if activated_handlers:
|
||||
async for resp in self.star_request_sub_stage.process(event):
|
||||
# 生成器返回值处理
|
||||
if isinstance(resp, ProviderRequest):
|
||||
# Handler 的 LLM 请求
|
||||
logger.debug(f"llm request -> {resp.prompt}")
|
||||
event.set_extra("provider_request", resp)
|
||||
async for _ in self.llm_request_sub_stage.process(event):
|
||||
yield
|
||||
else:
|
||||
yield
|
||||
|
||||
# 调用提供商相关请求
|
||||
if not self.ctx.astrbot_config['provider_settings'].get('enable', True):
|
||||
return
|
||||
|
||||
if not event._has_send_oper and event.is_at_or_wake_command:
|
||||
if (event.get_result() and not event.get_result().is_stopped()) or not event.get_result():
|
||||
provider = self.ctx.plugin_manager.context.get_using_provider()
|
||||
match provider.meta().type:
|
||||
case "dify":
|
||||
async for _ in self.dify_request_sub_stage.process(event):
|
||||
yield
|
||||
case _:
|
||||
async for _ in self.llm_request_sub_stage.process(event):
|
||||
yield
|
||||
87
astrbot/core/pipeline/rate_limit_check/stage.py
Normal file
87
astrbot/core/pipeline/rate_limit_check/stage.py
Normal file
@@ -0,0 +1,87 @@
|
||||
import asyncio
|
||||
from datetime import datetime, timedelta
|
||||
from collections import defaultdict, deque
|
||||
from typing import DefaultDict, Deque, Union, AsyncGenerator
|
||||
from ..stage import Stage, register_stage
|
||||
from ..context import PipelineContext
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.config.astrbot_config import RateLimitStrategy
|
||||
|
||||
|
||||
@register_stage
|
||||
class RateLimitStage(Stage):
|
||||
"""
|
||||
检查是否需要限制消息发送的限流器。
|
||||
|
||||
使用 Fixed Window 算法。
|
||||
如果触发限流,将 stall 流水线,直到下一个时间窗口来临时自动唤醒。
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
# 存储每个会话的请求时间队列
|
||||
self.event_timestamps: DefaultDict[str, Deque[datetime]] = defaultdict(deque)
|
||||
# 为每个会话设置一个锁,避免并发冲突
|
||||
self.locks: DefaultDict[str, asyncio.Lock] = defaultdict(asyncio.Lock)
|
||||
# 限流参数
|
||||
self.rate_limit_count: int = 0
|
||||
self.rate_limit_time: timedelta = timedelta(0)
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
"""
|
||||
初始化限流器,根据配置设置限流参数。
|
||||
"""
|
||||
self.rate_limit_count = ctx.astrbot_config['platform_settings']['rate_limit']['count']
|
||||
self.rate_limit_time = timedelta(seconds=ctx.astrbot_config['platform_settings']['rate_limit']['time'])
|
||||
self.rl_strategy = ctx.astrbot_config['platform_settings']['rate_limit']['strategy'] # stall or discard
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
"""
|
||||
检查并处理限流逻辑。如果触发限流,流水线会 stall 并在窗口期后自动恢复。
|
||||
|
||||
Args:
|
||||
event (AstrMessageEvent): 当前消息事件。
|
||||
ctx (PipelineContext): 流水线上下文。
|
||||
|
||||
Returns:
|
||||
MessageEventResult: 继续或停止事件处理的结果。
|
||||
"""
|
||||
session_id = event.session_id
|
||||
now = datetime.now()
|
||||
|
||||
async with self.locks[session_id]: # 确保同一会话不会并发修改队列
|
||||
timestamps = self.event_timestamps[session_id]
|
||||
|
||||
self._remove_expired_timestamps(timestamps, now)
|
||||
|
||||
if len(timestamps) >= self.rate_limit_count:
|
||||
# 达到限流阈值,计算下一个窗口的时间
|
||||
next_window_time = timestamps[0] + self.rate_limit_time
|
||||
stall_duration = (next_window_time - now).total_seconds()
|
||||
|
||||
match self.rl_strategy:
|
||||
case RateLimitStrategy.STALL:
|
||||
logger.info(f"会话 {session_id} 被限流。根据限流策略,此会话处理将被暂停 {stall_duration:.2f} 秒。")
|
||||
await asyncio.sleep(stall_duration)
|
||||
case RateLimitStrategy.DISCARD:
|
||||
event.set_result(MessageEventResult().message(f"会话 {session_id} 被限流。根据限流策略,此请求已被丢弃,直到您的限额于 {stall_duration:.2f} 秒后重置。"))
|
||||
return event.stop_event()
|
||||
|
||||
self._remove_expired_timestamps(timestamps, now + timedelta(seconds=stall_duration))
|
||||
|
||||
timestamps.append(now)
|
||||
|
||||
return event.continue_event()
|
||||
|
||||
def _remove_expired_timestamps(self, timestamps: Deque[datetime], now: datetime) -> None:
|
||||
"""
|
||||
移除时间窗口外的时间戳。
|
||||
|
||||
Args:
|
||||
timestamps (Deque[datetime]): 当前会话的时间戳队列。
|
||||
now (datetime): 当前时间,用于计算过期时间。
|
||||
"""
|
||||
expiry_threshold: datetime = now - self.rate_limit_time
|
||||
while timestamps and timestamps[0] < expiry_threshold:
|
||||
timestamps.popleft()
|
||||
49
astrbot/core/pipeline/respond/stage.py
Normal file
49
astrbot/core/pipeline/respond/stage.py
Normal file
@@ -0,0 +1,49 @@
|
||||
import random
|
||||
import asyncio
|
||||
from typing import Union, AsyncGenerator
|
||||
from ..stage import register_stage, Stage
|
||||
from ..context import PipelineContext
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageChain
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
|
||||
@register_stage
|
||||
class RespondStage(Stage):
|
||||
async def initialize(self, ctx: PipelineContext):
|
||||
self.ctx = ctx
|
||||
|
||||
# 分段回复
|
||||
self.enable_seg: bool = ctx.astrbot_config['platform_settings']['segmented_reply']['enable']
|
||||
interval_str: str = ctx.astrbot_config['platform_settings']['segmented_reply']['interval']
|
||||
interval_str_ls = interval_str.replace(" ", "").split(",")
|
||||
try:
|
||||
self.interval = [float(t) for t in interval_str_ls]
|
||||
except BaseException as e:
|
||||
logger.error(f'解析分段回复的间隔时间失败。{e}')
|
||||
self.interval = [1.5, 3.5]
|
||||
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
result = event.get_result()
|
||||
if result is None:
|
||||
return
|
||||
|
||||
if len(result.chain) > 0:
|
||||
await event._pre_send()
|
||||
if self.enable_seg:
|
||||
# 分段回复
|
||||
for comp in result.chain:
|
||||
await event.send(MessageChain([comp]))
|
||||
await asyncio.sleep(random.uniform(self.interval[0], self.interval[1]))
|
||||
else:
|
||||
await event.send(result)
|
||||
await event._post_send()
|
||||
logger.info(f"AstrBot -> {event.get_sender_name()}/{event.get_sender_id()}: {event._outline_chain(result.chain)}")
|
||||
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(EventType.OnAfterMessageSentEvent)
|
||||
for handler in handlers:
|
||||
# TODO: 如何让这里的 handler 也能使用 LLM 能力。也许需要将 LLMRequestSubStage 提取出来。
|
||||
await handler.handler(event)
|
||||
|
||||
event.clear_result()
|
||||
111
astrbot/core/pipeline/result_decorate/stage.py
Normal file
111
astrbot/core/pipeline/result_decorate/stage.py
Normal file
@@ -0,0 +1,111 @@
|
||||
import time
|
||||
import re
|
||||
import traceback
|
||||
from typing import Union, AsyncGenerator
|
||||
from ..stage import register_stage
|
||||
from ..context import PipelineContext
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.platform.message_type import MessageType
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.message.components import Plain, Image, At, Reply, Record
|
||||
from astrbot.core import html_renderer
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
|
||||
@register_stage
|
||||
class ResultDecorateStage:
|
||||
async def initialize(self, ctx: PipelineContext):
|
||||
self.ctx = ctx
|
||||
self.reply_prefix = ctx.astrbot_config['platform_settings']['reply_prefix']
|
||||
self.reply_with_mention = ctx.astrbot_config['platform_settings']['reply_with_mention']
|
||||
self.reply_with_quote = ctx.astrbot_config['platform_settings']['reply_with_quote']
|
||||
self.use_tts = ctx.astrbot_config['provider_tts_settings']['enable']
|
||||
self.t2i = ctx.astrbot_config['t2i']
|
||||
|
||||
# 分段回复
|
||||
self.enable_segmented_reply = ctx.astrbot_config['platform_settings']['segmented_reply']['enable']
|
||||
self.only_llm_result = ctx.astrbot_config['platform_settings']['segmented_reply']['only_llm_result']
|
||||
self.regex = ctx.astrbot_config['platform_settings']['segmented_reply']['regex']
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
result = event.get_result()
|
||||
if result is None:
|
||||
return
|
||||
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(EventType.OnDecoratingResultEvent)
|
||||
for handler in handlers:
|
||||
# TODO: 如何让这里的 handler 也能使用 LLM 能力。也许需要将 LLMRequestSubStage 提取出来。
|
||||
await handler.handler(event)
|
||||
|
||||
if len(result.chain) > 0:
|
||||
# 回复前缀
|
||||
if self.reply_prefix:
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Plain):
|
||||
comp.text = self.reply_prefix + comp.text
|
||||
break
|
||||
|
||||
# 分段回复
|
||||
if self.enable_segmented_reply:
|
||||
if (self.only_llm_result and result.is_llm_result()) or not self.only_llm_result:
|
||||
new_chain = []
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Plain):
|
||||
split_response = re.findall(r".*?[。?!~…]+|.+$", comp.text)
|
||||
if not split_response:
|
||||
new_chain.append(comp)
|
||||
continue
|
||||
for seg in split_response:
|
||||
new_chain.append(Plain(seg))
|
||||
else:
|
||||
# 非 Plain 类型的消息段不分段
|
||||
new_chain.append(comp)
|
||||
result.chain = new_chain
|
||||
|
||||
# TTS
|
||||
if self.use_tts and result.is_llm_result():
|
||||
tts_provider = self.ctx.plugin_manager.context.provider_manager.curr_tts_provider_inst
|
||||
new_chain = []
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Plain) and len(comp.text) > 1:
|
||||
try:
|
||||
logger.info("TTS 请求: " + plain_str)
|
||||
audio_path = await tts_provider.get_audio(plain_str)
|
||||
logger.info("TTS 结果: " + audio_path)
|
||||
if audio_path:
|
||||
new_chain.append(Record(file=audio_path, url=audio_path))
|
||||
else:
|
||||
logger.error(f"由于 TTS 音频文件没找到,消息段转语音失败: {comp.text}")
|
||||
new_chain.append(comp)
|
||||
except BaseException:
|
||||
traceback.print_exc()
|
||||
logger.error("TTS 失败,使用文本发送。")
|
||||
new_chain.append(comp)
|
||||
else:
|
||||
new_chain.append(comp)
|
||||
result.chain = new_chain
|
||||
|
||||
# 文本转图片
|
||||
elif (result.use_t2i_ is None and self.t2i) or result.use_t2i_:
|
||||
plain_str = ""
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Plain):
|
||||
plain_str += "\n\n" + comp.text
|
||||
else:
|
||||
break
|
||||
if plain_str and len(plain_str) > 150:
|
||||
render_start = time.time()
|
||||
try:
|
||||
url = await html_renderer.render_t2i(plain_str, return_url=True)
|
||||
except BaseException:
|
||||
logger.error("文本转图片失败,使用文本发送。")
|
||||
return
|
||||
if time.time() - render_start > 3:
|
||||
logger.warning("文本转图片耗时超过了 3 秒,如果觉得很慢可以使用 /t2i 关闭文本转图片模式。")
|
||||
if url:
|
||||
result.chain = [Image.fromURL(url)]
|
||||
|
||||
if self.reply_with_mention and event.get_message_type() != MessageType.FRIEND_MESSAGE:
|
||||
result.chain.insert(0, At(qq=event.get_sender_id()))
|
||||
|
||||
if self.reply_with_quote:
|
||||
result.chain.insert(0, Reply(id=event.message_obj.message_id))
|
||||
48
astrbot/core/pipeline/scheduler.py
Normal file
48
astrbot/core/pipeline/scheduler.py
Normal file
@@ -0,0 +1,48 @@
|
||||
from . import STAGES_ORDER
|
||||
from .stage import registered_stages
|
||||
from .context import PipelineContext
|
||||
from typing import AsyncGenerator
|
||||
from astrbot.core.platform import AstrMessageEvent
|
||||
from astrbot.core import logger
|
||||
|
||||
class PipelineScheduler():
|
||||
def __init__(self, context: PipelineContext):
|
||||
registered_stages.sort(key=lambda x: STAGES_ORDER.index(x.__class__ .__name__))
|
||||
self.ctx = context
|
||||
|
||||
async def initialize(self):
|
||||
for stage in registered_stages:
|
||||
logger.debug(f"初始化阶段 {stage.__class__ .__name__}")
|
||||
|
||||
await stage.initialize(self.ctx)
|
||||
|
||||
async def _process_stages(self, event: AstrMessageEvent, from_stage=0):
|
||||
for i in range(from_stage, len(registered_stages)):
|
||||
stage = registered_stages[i]
|
||||
logger.debug(f"执行阶段 {stage.__class__ .__name__}")
|
||||
coro = stage.process(event)
|
||||
if isinstance(coro, AsyncGenerator):
|
||||
async for _ in coro:
|
||||
if event.is_stopped():
|
||||
logger.debug(f"阶段 {stage.__class__ .__name__} 已终止事件传播。")
|
||||
break
|
||||
await self._process_stages(event, i + 1)
|
||||
else:
|
||||
await coro
|
||||
|
||||
if event.is_stopped():
|
||||
logger.debug(f"阶段 {stage.__class__ .__name__} 已终止事件传播。")
|
||||
break
|
||||
|
||||
if event.is_stopped():
|
||||
logger.debug(f"阶段 {stage.__class__ .__name__} 已终止事件传播。")
|
||||
break
|
||||
|
||||
async def execute(self, event: AstrMessageEvent):
|
||||
'''执行 pipeline'''
|
||||
await self._process_stages(event)
|
||||
|
||||
if not event._has_send_oper and event.get_platform_name() == "webchat":
|
||||
await event.send(None)
|
||||
|
||||
logger.debug("pipeline 执行完毕。")
|
||||
65
astrbot/core/pipeline/stage.py
Normal file
65
astrbot/core/pipeline/stage.py
Normal file
@@ -0,0 +1,65 @@
|
||||
from __future__ import annotations
|
||||
import abc
|
||||
import inspect
|
||||
from typing import List, AsyncGenerator, Union, Awaitable
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from .context import PipelineContext
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, CommandResult
|
||||
|
||||
registered_stages: List[Stage] = []
|
||||
'''维护了所有已注册的 Stage 实现类'''
|
||||
|
||||
def register_stage(cls):
|
||||
'''一个简单的装饰器,用于注册 pipeline 包下的 Stage 实现类
|
||||
'''
|
||||
registered_stages.append(cls())
|
||||
return cls
|
||||
|
||||
class Stage(abc.ABC):
|
||||
'''描述一个 Pipeline 的某个阶段
|
||||
'''
|
||||
|
||||
@abc.abstractmethod
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
'''初始化阶段
|
||||
'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
'''处理事件
|
||||
'''
|
||||
raise NotImplementedError
|
||||
|
||||
async def _call_handler(
|
||||
self,
|
||||
ctx: PipelineContext,
|
||||
event: AstrMessageEvent,
|
||||
handler: Awaitable,
|
||||
**params
|
||||
) -> AsyncGenerator[None, None]:
|
||||
'''调用 Handler。'''
|
||||
# 判断 handler 是否是类方法(通过装饰器注册的没有 __self__ 属性)
|
||||
ready_to_call = None
|
||||
try:
|
||||
ready_to_call = handler(event, **params)
|
||||
except TypeError as e:
|
||||
# 向下兼容
|
||||
ready_to_call = handler(event, ctx.plugin_manager.context, **params)
|
||||
|
||||
if isinstance(ready_to_call, AsyncGenerator):
|
||||
async for ret in ready_to_call:
|
||||
# 如果处理函数是生成器,返回值只能是 MessageEventResult 或者 None(无返回值)
|
||||
if isinstance(ret, (MessageEventResult, CommandResult)):
|
||||
event.set_result(ret)
|
||||
yield
|
||||
else:
|
||||
yield ret
|
||||
elif inspect.iscoroutine(ready_to_call):
|
||||
# 如果只是一个 coroutine
|
||||
ret = await ready_to_call
|
||||
if isinstance(ret, (MessageEventResult, CommandResult)):
|
||||
event.set_result(ret)
|
||||
yield
|
||||
else:
|
||||
yield ret
|
||||
128
astrbot/core/pipeline/waking_check/stage.py
Normal file
128
astrbot/core/pipeline/waking_check/stage.py
Normal file
@@ -0,0 +1,128 @@
|
||||
from ..stage import Stage, register_stage
|
||||
from ..context import PipelineContext
|
||||
from typing import Union, AsyncGenerator
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult
|
||||
from astrbot.core.message.components import At
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
from astrbot.core.star.filter.command_group import CommandGroupFilter
|
||||
|
||||
|
||||
@register_stage
|
||||
class WakingCheckStage(Stage):
|
||||
"""检查是否需要唤醒。唤醒机器人有如下几点条件:
|
||||
|
||||
1. 机器人被 @ 了
|
||||
2. 机器人的消息被提到了
|
||||
3. 以 wake_prefix 前缀开头,并且消息没有以 At 消息段开头
|
||||
4. 插件(Star)的 handler filter 通过
|
||||
5. 私聊情况下,位于 admins_id 列表中的管理员的消息(在白名单阶段中)
|
||||
"""
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
# 设置 sender 身份
|
||||
event.message_str = event.message_str.strip()
|
||||
for admin_id in self.ctx.astrbot_config["admins_id"]:
|
||||
if event.get_sender_id() == admin_id:
|
||||
event.role = "admin"
|
||||
break
|
||||
|
||||
# 检查 wake
|
||||
wake_prefixes = self.ctx.astrbot_config["wake_prefix"]
|
||||
messages = event.get_messages()
|
||||
is_wake = False
|
||||
for wake_prefix in wake_prefixes:
|
||||
if event.message_str.startswith(wake_prefix):
|
||||
if (
|
||||
not event.is_private_chat()
|
||||
and isinstance(messages[0], At)
|
||||
and str(messages[0].qq) != str(event.get_self_id())
|
||||
and str(messages[0].qq) != "all"
|
||||
):
|
||||
# 如果是群聊,且第一个消息段是 At 消息,但不是 At 机器人或 At 全体成员,则不唤醒
|
||||
break
|
||||
is_wake = True
|
||||
event.is_at_or_wake_command = True
|
||||
event.is_wake = True
|
||||
event.message_str = event.message_str[len(wake_prefix) :].strip()
|
||||
break
|
||||
if not is_wake:
|
||||
# 检查是否有 at 消息
|
||||
for message in messages:
|
||||
if isinstance(message, At) and (
|
||||
str(message.qq) == str(event.get_self_id())
|
||||
or str(message.qq) == "all"
|
||||
):
|
||||
is_wake = True
|
||||
event.is_wake = True
|
||||
wake_prefix = ""
|
||||
event.is_at_or_wake_command = True
|
||||
break
|
||||
# 检查是否是私聊
|
||||
if event.is_private_chat():
|
||||
is_wake = True
|
||||
event.is_wake = True
|
||||
event.is_at_or_wake_command = True
|
||||
wake_prefix = ""
|
||||
|
||||
# 检查插件的 handler filter
|
||||
activated_handlers = []
|
||||
handlers_parsed_params = {} # 注册了指令的 handler
|
||||
for handler in star_handlers_registry.get_handlers_by_event_type(EventType.AdapterMessageEvent):
|
||||
# filter 需要满足 AND 的逻辑关系
|
||||
passed = True
|
||||
child_command_handler_md = None
|
||||
|
||||
if len(handler.event_filters) == 0:
|
||||
# 不可能有这种情况, 也不允许有这种情况
|
||||
continue
|
||||
|
||||
for filter in handler.event_filters:
|
||||
try:
|
||||
if isinstance(filter, CommandGroupFilter):
|
||||
"""如果指令组过滤成功, 会返回叶子指令的 StarHandlerMetadata"""
|
||||
ok, child_command_handler_md = filter.filter(
|
||||
event, self.ctx.astrbot_config
|
||||
)
|
||||
if not ok:
|
||||
passed = False
|
||||
else:
|
||||
handler = child_command_handler_md # handler 覆盖
|
||||
break
|
||||
else:
|
||||
if not filter.filter(event, self.ctx.astrbot_config):
|
||||
passed = False
|
||||
break
|
||||
except Exception as e:
|
||||
# event.set_result(MessageEventResult().message(f"插件 {handler.handler_full_name} 报错:{e}"))
|
||||
# yield
|
||||
await event.send(
|
||||
MessageEventResult().message(
|
||||
f"插件 {handler.handler_full_name} 报错:{e}"
|
||||
)
|
||||
)
|
||||
event.stop_event()
|
||||
passed = False
|
||||
break
|
||||
|
||||
if passed:
|
||||
is_wake = True
|
||||
event.is_wake = True
|
||||
|
||||
activated_handlers.append(handler)
|
||||
if "parsed_params" in event.get_extra():
|
||||
handlers_parsed_params[handler.handler_full_name] = event.get_extra(
|
||||
"parsed_params"
|
||||
)
|
||||
event.clear_extra()
|
||||
|
||||
event.set_extra("activated_handlers", activated_handlers)
|
||||
event.set_extra("handlers_parsed_params", handlers_parsed_params)
|
||||
|
||||
if not is_wake:
|
||||
event.stop_event()
|
||||
37
astrbot/core/pipeline/whitelist_check/stage.py
Normal file
37
astrbot/core/pipeline/whitelist_check/stage.py
Normal file
@@ -0,0 +1,37 @@
|
||||
from ..stage import Stage, register_stage
|
||||
from ..context import PipelineContext
|
||||
from typing import AsyncGenerator, Union
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.platform.message_type import MessageType
|
||||
from astrbot.core import logger
|
||||
|
||||
@register_stage
|
||||
class WhitelistCheckStage(Stage):
|
||||
'''检查是否在群聊/私聊白名单
|
||||
'''
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.enable_whitelist_check = ctx.astrbot_config['platform_settings']['enable_id_white_list']
|
||||
self.whitelist = ctx.astrbot_config['platform_settings']['id_whitelist']
|
||||
self.wl_ignore_admin_on_group = ctx.astrbot_config['platform_settings']['wl_ignore_admin_on_group']
|
||||
self.wl_ignore_admin_on_friend = ctx.astrbot_config['platform_settings']['wl_ignore_admin_on_friend']
|
||||
self.wl_log = ctx.astrbot_config['platform_settings']['id_whitelist_log']
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
if not self.enable_whitelist_check:
|
||||
return
|
||||
|
||||
if event.get_platform_name() == 'webchat':
|
||||
# WebChat 豁免
|
||||
return
|
||||
|
||||
# 检查是否在白名单
|
||||
if self.wl_ignore_admin_on_group:
|
||||
if event.role == 'admin' and event.get_message_type() == MessageType.GROUP_MESSAGE:
|
||||
return
|
||||
if self.wl_ignore_admin_on_friend:
|
||||
if event.role == 'admin' and event.get_message_type() == MessageType.FRIEND_MESSAGE:
|
||||
return
|
||||
if event.unified_msg_origin not in self.whitelist:
|
||||
if self.wl_log:
|
||||
logger.info(f"会话 ID {event.unified_msg_origin} 不在会话白名单中,已终止事件传播。请在配置文件中添加该会话 ID 到白名单。")
|
||||
event.stop_event()
|
||||
4
astrbot/core/platform/__init__.py
Normal file
4
astrbot/core/platform/__init__.py
Normal file
@@ -0,0 +1,4 @@
|
||||
from .platform import Platform
|
||||
from .astr_message_event import AstrMessageEvent
|
||||
from .platform_metadata import PlatformMetadata
|
||||
from .astrbot_message import AstrBotMessage, MessageMember, MessageType
|
||||
321
astrbot/core/platform/astr_message_event.py
Normal file
321
astrbot/core/platform/astr_message_event.py
Normal file
@@ -0,0 +1,321 @@
|
||||
import abc
|
||||
from dataclasses import dataclass
|
||||
from .astrbot_message import AstrBotMessage
|
||||
from .platform_metadata import PlatformMetadata
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, MessageChain
|
||||
from astrbot.core.platform.message_type import MessageType
|
||||
from typing import List, Union
|
||||
from astrbot.core.message.components import Plain, Image, BaseMessageComponent, Face, At, AtAll, Forward
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
from astrbot.core.provider.entites import ProviderRequest
|
||||
|
||||
|
||||
@dataclass
|
||||
class MessageSesion:
|
||||
platform_name: str
|
||||
message_type: MessageType
|
||||
session_id: str
|
||||
|
||||
def __str__(self):
|
||||
return f"{self.platform_name}:{self.message_type.value}:{self.session_id}"
|
||||
|
||||
@staticmethod
|
||||
def from_str(session_str: str):
|
||||
platform_name, message_type, session_id = session_str.split(":")
|
||||
return MessageSesion(platform_name, MessageType(message_type), session_id)
|
||||
|
||||
class AstrMessageEvent(abc.ABC):
|
||||
def __init__(self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,):
|
||||
self.message_str = message_str
|
||||
self.message_obj = message_obj
|
||||
self.platform_meta = platform_meta
|
||||
self.session_id = session_id
|
||||
self.role = "member"
|
||||
self.is_wake = False # 是否通过 WakingStage
|
||||
self.is_at_or_wake_command = False # 是否是 At 机器人或者带有唤醒词或者是私聊(事件监听器会让 is_wake 设为 True)
|
||||
self._extras = {}
|
||||
self.session = MessageSesion(
|
||||
platform_name=platform_meta.name,
|
||||
message_type=message_obj.type,
|
||||
session_id=session_id
|
||||
)
|
||||
self.unified_msg_origin = str(self.session)
|
||||
|
||||
self._result: MessageEventResult = None
|
||||
'''消息事件的结果'''
|
||||
|
||||
self._has_send_oper = False
|
||||
'''是否有过至少一次发送操作'''
|
||||
|
||||
|
||||
# back_compability
|
||||
self.platform = platform_meta
|
||||
|
||||
def get_platform_name(self):
|
||||
return self.platform_meta.name
|
||||
|
||||
def get_message_str(self) -> str:
|
||||
'''
|
||||
获取消息字符串。
|
||||
'''
|
||||
return self.message_str
|
||||
|
||||
def _outline_chain(self, chain: List[BaseMessageComponent]) -> str:
|
||||
outline = ""
|
||||
for i in chain:
|
||||
if isinstance(i, Plain):
|
||||
outline += i.text
|
||||
elif isinstance(i, Image):
|
||||
outline += "[图片]"
|
||||
elif isinstance(i, Face):
|
||||
outline += f"[表情:{i.id}]"
|
||||
elif isinstance(i, At):
|
||||
outline += f"[At:{i.qq}]"
|
||||
elif isinstance(i, AtAll):
|
||||
outline += "[At:全体成员]"
|
||||
elif isinstance(i, Forward):
|
||||
# 转发消息
|
||||
outline += "[转发消息]"
|
||||
else:
|
||||
outline += f"[{i.type}]"
|
||||
return outline
|
||||
|
||||
def get_message_outline(self) -> str:
|
||||
'''
|
||||
获取消息概要。
|
||||
|
||||
除了文本消息外,其他消息类型会被转换为对应的占位符。如图片消息会被转换为 [图片]。
|
||||
'''
|
||||
return self._outline_chain(self.message_obj.message)
|
||||
|
||||
def get_messages(self) -> List[BaseMessageComponent]:
|
||||
'''
|
||||
获取消息链。
|
||||
'''
|
||||
return self.message_obj.message
|
||||
|
||||
def get_message_type(self) -> MessageType:
|
||||
'''
|
||||
获取消息类型。
|
||||
'''
|
||||
return self.message_obj.type
|
||||
|
||||
def get_session_id(self) -> str:
|
||||
'''
|
||||
获取会话id。
|
||||
'''
|
||||
return self.session_id
|
||||
|
||||
def get_group_id(self) -> str:
|
||||
'''
|
||||
获取群组id。如果不是群组消息,返回空字符串。
|
||||
'''
|
||||
return self.message_obj.group_id
|
||||
|
||||
def get_self_id(self) -> str:
|
||||
'''
|
||||
获取机器人自身的id。
|
||||
'''
|
||||
return self.message_obj.self_id
|
||||
|
||||
def get_sender_id(self) -> str:
|
||||
'''
|
||||
获取消息发送者的id。
|
||||
'''
|
||||
return self.message_obj.sender.user_id
|
||||
|
||||
def get_sender_name(self) -> str:
|
||||
'''
|
||||
获取消息发送者的名称。(可能会返回空字符串)
|
||||
'''
|
||||
return self.message_obj.sender.nickname
|
||||
|
||||
def set_extra(self, key, value):
|
||||
'''
|
||||
设置额外的信息。
|
||||
'''
|
||||
self._extras[key] = value
|
||||
|
||||
def get_extra(self, key = None):
|
||||
'''
|
||||
获取额外的信息。
|
||||
'''
|
||||
if key is None:
|
||||
return self._extras
|
||||
return self._extras.get(key, None)
|
||||
|
||||
def clear_extra(self):
|
||||
'''
|
||||
清除额外的信息。
|
||||
'''
|
||||
self._extras.clear()
|
||||
|
||||
def is_private_chat(self) -> bool:
|
||||
'''
|
||||
是否是私聊。
|
||||
'''
|
||||
return self.message_obj.type.value == (MessageType.FRIEND_MESSAGE).value
|
||||
|
||||
def is_wake_up(self) -> bool:
|
||||
'''
|
||||
是否是唤醒机器人的事件。
|
||||
'''
|
||||
return self.is_wake
|
||||
|
||||
def is_admin(self) -> bool:
|
||||
'''
|
||||
是否是管理员。
|
||||
'''
|
||||
return self.role == "admin"
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
'''
|
||||
发送消息到消息平台。
|
||||
'''
|
||||
await Metric.upload(msg_event_tick = 1, adapter_name = self.platform_meta.name)
|
||||
self._has_send_oper = True
|
||||
|
||||
async def _pre_send(self):
|
||||
'''调度器会在执行 send() 前调用该方法'''
|
||||
pass
|
||||
|
||||
async def _post_send(self):
|
||||
'''调度器会在执行 send() 后调用该方法'''
|
||||
pass
|
||||
|
||||
|
||||
def set_result(self, result: Union[MessageEventResult, str]):
|
||||
'''设置消息事件的结果。
|
||||
|
||||
Note:
|
||||
事件处理器可以通过设置结果来控制事件是否继续传播,并向消息适配器发送消息。
|
||||
|
||||
如果没有设置 `MessageEventResult` 中的 result_type,默认为 CONTINUE。即事件将会继续向后面的 listener 或者 command 传播。
|
||||
|
||||
Example:
|
||||
```
|
||||
async def ban_handler(self, event: AstrMessageEvent):
|
||||
if event.get_sender_id() in self.blacklist:
|
||||
event.set_result(MessageEventResult().set_console_log("由于用户在黑名单,因此消息事件中断处理。")).set_result_type(EventResultType.STOP)
|
||||
return
|
||||
|
||||
async def check_count(self, event: AstrMessageEvent):
|
||||
self.count += 1
|
||||
event.set_result(MessageEventResult().set_console_log("数量已增加", logging.DEBUG).set_result_type(EventResultType.CONTINUE))
|
||||
return
|
||||
```
|
||||
'''
|
||||
if isinstance(result, str):
|
||||
result = MessageEventResult().message(result)
|
||||
self._result = result
|
||||
|
||||
def stop_event(self):
|
||||
'''终止事件传播。
|
||||
'''
|
||||
if self._result is None:
|
||||
self.set_result(MessageEventResult().stop_event())
|
||||
else:
|
||||
self._result.stop_event()
|
||||
|
||||
def continue_event(self):
|
||||
'''继续事件传播。
|
||||
'''
|
||||
if self._result is None:
|
||||
self.set_result(MessageEventResult().continue_event())
|
||||
else:
|
||||
self._result.continue_event()
|
||||
|
||||
def is_stopped(self) -> bool:
|
||||
'''
|
||||
是否终止事件传播。
|
||||
'''
|
||||
if self._result is None:
|
||||
return False # 默认是继续传播
|
||||
return self._result.is_stopped()
|
||||
|
||||
def get_result(self) -> MessageEventResult:
|
||||
'''
|
||||
获取消息事件的结果。
|
||||
'''
|
||||
return self._result
|
||||
|
||||
def clear_result(self):
|
||||
'''
|
||||
清除消息事件的结果。
|
||||
'''
|
||||
self._result = None
|
||||
|
||||
'''消息链相关'''
|
||||
|
||||
def make_result(self) -> MessageEventResult:
|
||||
'''
|
||||
创建一个空的消息事件结果。
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
# 纯文本回复
|
||||
yield event.make_result().message("Hi")
|
||||
# 发送图片
|
||||
yield event.make_result().url_image("https://example.com/image.jpg")
|
||||
yield event.make_result().file_image("image.jpg")
|
||||
```
|
||||
'''
|
||||
return MessageEventResult()
|
||||
|
||||
def plain_result(self, text: str) -> MessageEventResult:
|
||||
'''
|
||||
创建一个空的消息事件结果,只包含一条文本消息。
|
||||
'''
|
||||
return MessageEventResult().message(text)
|
||||
|
||||
def image_result(self, url_or_path: str) -> MessageEventResult:
|
||||
'''
|
||||
创建一个空的消息事件结果,只包含一条图片消息。
|
||||
|
||||
根据开头是否包含 http 来判断是网络图片还是本地图片。
|
||||
'''
|
||||
if url_or_path.startswith("http"):
|
||||
return MessageEventResult().url_image(url_or_path)
|
||||
return MessageEventResult().file_image(url_or_path)
|
||||
|
||||
def chain_result(self, chain: List[BaseMessageComponent]) -> MessageEventResult:
|
||||
'''
|
||||
创建一个空的消息事件结果,包含指定的消息链。
|
||||
'''
|
||||
mer = MessageEventResult()
|
||||
mer.chain = chain
|
||||
return mer
|
||||
|
||||
'''LLM 请求相关'''
|
||||
|
||||
def request_llm(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str = None,
|
||||
image_urls: List[str] = None,
|
||||
contexts: List = None,
|
||||
system_prompt: str = ""
|
||||
) -> ProviderRequest:
|
||||
'''
|
||||
创建一个 LLM 请求。
|
||||
|
||||
Examples:
|
||||
```py
|
||||
yield event.request_llm(prompt="hi")
|
||||
```
|
||||
|
||||
image_urls: 可以是 base64:// 或者 http:// 开头的图片链接,也可以是本地图片路径。
|
||||
contexts: 当指定 contexts 时,将会**只**使用 contexts 作为上下文。
|
||||
'''
|
||||
return ProviderRequest(
|
||||
prompt = prompt,
|
||||
session_id = session_id,
|
||||
image_urls = image_urls,
|
||||
contexts = contexts,
|
||||
system_prompt = system_prompt
|
||||
)
|
||||
31
astrbot/core/platform/astrbot_message.py
Normal file
31
astrbot/core/platform/astrbot_message.py
Normal file
@@ -0,0 +1,31 @@
|
||||
import time
|
||||
from typing import List
|
||||
from dataclasses import dataclass
|
||||
from astrbot.core.message.components import BaseMessageComponent
|
||||
from .message_type import MessageType
|
||||
|
||||
@dataclass
|
||||
class MessageMember():
|
||||
user_id: str # 发送者id
|
||||
nickname: str = None
|
||||
|
||||
class AstrBotMessage:
|
||||
'''
|
||||
AstrBot 的消息对象
|
||||
'''
|
||||
type: MessageType # 消息类型
|
||||
self_id: str # 机器人的识别id
|
||||
session_id: str # 会话id。取决于 unique_session 的设置。
|
||||
message_id: str # 消息id
|
||||
group_id: str = "" # 群组id,如果为私聊,则为空
|
||||
sender: MessageMember # 发送者
|
||||
message: List[BaseMessageComponent] # 消息链使用 Nakuru 的消息链格式
|
||||
message_str: str # 最直观的纯文本消息字符串
|
||||
raw_message: object
|
||||
timestamp: int # 消息时间戳
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.timestamp = int(time.time())
|
||||
|
||||
def __str__(self) -> str:
|
||||
return str(self.__dict__)
|
||||
47
astrbot/core/platform/manager.py
Normal file
47
astrbot/core/platform/manager.py
Normal file
@@ -0,0 +1,47 @@
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from .platform import Platform
|
||||
from typing import List
|
||||
from asyncio import Queue
|
||||
from .register import platform_cls_map
|
||||
from astrbot.core import logger
|
||||
from .sources.webchat.webchat_adapter import WebChatAdapter
|
||||
|
||||
class PlatformManager():
|
||||
def __init__(self, config: AstrBotConfig, event_queue: Queue):
|
||||
self.platform_insts: List[Platform] = []
|
||||
'''加载的 Platform 的实例'''
|
||||
|
||||
self.platforms_config = config['platform']
|
||||
self.settings = config['platform_settings']
|
||||
self.event_queue = event_queue
|
||||
|
||||
for platform in self.platforms_config:
|
||||
if not platform['enable']:
|
||||
continue
|
||||
match platform['type']:
|
||||
case "aiocqhttp":
|
||||
from .sources.aiocqhttp.aiocqhttp_platform_adapter import AiocqhttpAdapter # noqa: F401
|
||||
case "qq_official":
|
||||
from .sources.qqofficial.qqofficial_platform_adapter import QQOfficialPlatformAdapter # noqa: F401
|
||||
case "vchat":
|
||||
from .sources.vchat.vchat_platform_adapter import VChatPlatformAdapter # noqa: F401
|
||||
case "gewechat":
|
||||
from .sources.gewechat.gewechat_platform_adapter import GewechatPlatformAdapter # noqa: F401
|
||||
|
||||
|
||||
async def initialize(self):
|
||||
for platform in self.platforms_config:
|
||||
if not platform['enable']:
|
||||
continue
|
||||
if platform['type'] not in platform_cls_map:
|
||||
logger.error(f"未找到适用于 {platform['type']}({platform['id']}) 平台适配器,请检查是否已经安装或者名称填写错误。已跳过。")
|
||||
continue
|
||||
cls_type = platform_cls_map[platform['type']]
|
||||
logger.info(f"尝试实例化 {platform['type']}({platform['id']}) 平台适配器 ...")
|
||||
inst = cls_type(platform, self.settings, self.event_queue)
|
||||
self.platform_insts.append(inst)
|
||||
|
||||
self.platform_insts.append(WebChatAdapter({}, self.settings, self.event_queue))
|
||||
|
||||
def get_insts(self):
|
||||
return self.platform_insts
|
||||
6
astrbot/core/platform/message_type.py
Normal file
6
astrbot/core/platform/message_type.py
Normal file
@@ -0,0 +1,6 @@
|
||||
from enum import Enum
|
||||
|
||||
class MessageType(Enum):
|
||||
GROUP_MESSAGE = 'GroupMessage' # 群组形式的消息
|
||||
FRIEND_MESSAGE = 'FriendMessage' # 私聊、好友等单聊消息
|
||||
OTHER_MESSAGE = 'OtherMessage' # 其他类型的消息,如系统消息等
|
||||
42
astrbot/core/platform/platform.py
Normal file
42
astrbot/core/platform/platform.py
Normal file
@@ -0,0 +1,42 @@
|
||||
import abc
|
||||
from typing import Awaitable, Any
|
||||
from asyncio import Queue
|
||||
from .platform_metadata import PlatformMetadata
|
||||
from .astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageChain
|
||||
from .astr_message_event import MessageSesion
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
|
||||
class Platform(abc.ABC):
|
||||
def __init__(self, event_queue: Queue):
|
||||
super().__init__()
|
||||
# 维护了消息平台的事件队列,EventBus 会从这里取出事件并处理。
|
||||
self._event_queue = event_queue
|
||||
|
||||
@abc.abstractmethod
|
||||
def run(self) -> Awaitable[Any]:
|
||||
'''
|
||||
得到一个平台的运行实例,需要返回一个协程对象。
|
||||
'''
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def meta(self) -> PlatformMetadata:
|
||||
'''
|
||||
得到一个平台的元数据。
|
||||
'''
|
||||
raise NotImplementedError
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain) -> Awaitable[Any]:
|
||||
'''
|
||||
通过会话发送消息。该方法旨在让插件能够直接通过**可持久化的会话数据**发送消息,而不需要保存 event 对象。
|
||||
|
||||
异步方法。
|
||||
'''
|
||||
await Metric.upload(msg_event_tick = 1, adapter_name = self.meta().name)
|
||||
|
||||
def commit_event(self, event: AstrMessageEvent):
|
||||
'''
|
||||
提交一个事件到事件队列。
|
||||
'''
|
||||
self._event_queue.put_nowait(event)
|
||||
12
astrbot/core/platform/platform_metadata.py
Normal file
12
astrbot/core/platform/platform_metadata.py
Normal file
@@ -0,0 +1,12 @@
|
||||
from dataclasses import dataclass
|
||||
@dataclass
|
||||
class PlatformMetadata():
|
||||
name: str
|
||||
'''平台的名称'''
|
||||
description: str
|
||||
'''平台的描述'''
|
||||
|
||||
default_config_tmpl: dict = None
|
||||
'''平台的默认配置模板'''
|
||||
adapter_display_name: str = None
|
||||
'''显示在 WebUI 配置页中的平台名称,如空则是 name'''
|
||||
44
astrbot/core/platform/register.py
Normal file
44
astrbot/core/platform/register.py
Normal file
@@ -0,0 +1,44 @@
|
||||
from typing import List, Dict, Type
|
||||
from .platform_metadata import PlatformMetadata
|
||||
from astrbot.core import logger
|
||||
|
||||
platform_registry: List[PlatformMetadata] = []
|
||||
'''维护了通过装饰器注册的平台适配器'''
|
||||
platform_cls_map: Dict[str, Type] = {}
|
||||
'''维护了平台适配器名称和适配器类的映射'''
|
||||
|
||||
def register_platform_adapter(
|
||||
adapter_name: str,
|
||||
desc: str,
|
||||
default_config_tmpl: dict = None,
|
||||
adapter_display_name: str = None
|
||||
):
|
||||
'''用于注册平台适配器的带参装饰器。
|
||||
|
||||
default_config_tmpl 指定了平台适配器的默认配置模板。用户填写好后将会作为 platform_config 传入你的 Platform 类的实现类。
|
||||
'''
|
||||
def decorator(cls):
|
||||
if adapter_name in platform_cls_map:
|
||||
raise ValueError(f"平台适配器 {adapter_name} 已经注册过了,可能发生了适配器命名冲突。")
|
||||
|
||||
# 添加必备选项
|
||||
if default_config_tmpl:
|
||||
if 'type' not in default_config_tmpl:
|
||||
default_config_tmpl['type'] = adapter_name
|
||||
if 'enable' not in default_config_tmpl:
|
||||
default_config_tmpl['enable'] = False
|
||||
if 'id' not in default_config_tmpl:
|
||||
default_config_tmpl['id'] = adapter_name
|
||||
|
||||
pm = PlatformMetadata(
|
||||
name=adapter_name,
|
||||
description=desc,
|
||||
default_config_tmpl=default_config_tmpl,
|
||||
adapter_display_name=adapter_display_name
|
||||
)
|
||||
platform_registry.append(pm)
|
||||
platform_cls_map[adapter_name] = cls
|
||||
logger.debug(f"平台适配器 {adapter_name} 已注册")
|
||||
return cls
|
||||
|
||||
return decorator
|
||||
@@ -0,0 +1,44 @@
|
||||
import os
|
||||
import random
|
||||
import asyncio
|
||||
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.message_components import Plain, Image, Record
|
||||
from aiocqhttp import CQHttp
|
||||
from astrbot.core.utils.io import file_to_base64, download_image_by_url
|
||||
|
||||
class AiocqhttpMessageEvent(AstrMessageEvent):
|
||||
def __init__(self, message_str, message_obj, platform_meta, session_id, bot: CQHttp):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.bot = bot
|
||||
|
||||
@staticmethod
|
||||
async def _parse_onebot_json(message_chain: MessageChain):
|
||||
'''解析成 OneBot json 格式'''
|
||||
ret = []
|
||||
for segment in message_chain.chain:
|
||||
d = segment.toDict()
|
||||
if isinstance(segment, Plain):
|
||||
d['type'] = 'text'
|
||||
if isinstance(segment, (Image, Record)):
|
||||
# convert to base64
|
||||
if segment.file and segment.file.startswith("file:///"):
|
||||
bs64_data = file_to_base64(segment.file[8:])
|
||||
image_file_path = segment.file[8:]
|
||||
elif segment.file and segment.file.startswith("http"):
|
||||
image_file_path = await download_image_by_url(segment.file)
|
||||
bs64_data = file_to_base64(image_file_path)
|
||||
else:
|
||||
bs64_data = file_to_base64(segment.file)
|
||||
d['data'] = {
|
||||
'file': bs64_data,
|
||||
}
|
||||
ret.append(d)
|
||||
return ret
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
ret = await AiocqhttpMessageEvent._parse_onebot_json(message)
|
||||
if os.environ.get('TEST_MODE', 'off') == 'on':
|
||||
return
|
||||
await self.bot.send(self.message_obj.raw_message, ret)
|
||||
await super().send(message)
|
||||
@@ -0,0 +1,169 @@
|
||||
import os
|
||||
import time
|
||||
import asyncio
|
||||
import logging
|
||||
from typing import Awaitable, Any
|
||||
from aiocqhttp import CQHttp, Event
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
from astrbot.api.event import MessageChain
|
||||
from .aiocqhttp_message_event import * # noqa: F403
|
||||
from astrbot.api.message_components import * # noqa: F403
|
||||
from astrbot.api import logger
|
||||
from .aiocqhttp_message_event import AiocqhttpMessageEvent
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from ...register import register_platform_adapter
|
||||
from aiocqhttp.exceptions import ActionFailed
|
||||
from astrbot.core.utils.io import download_file
|
||||
|
||||
@register_platform_adapter("aiocqhttp", "适用于 OneBot 标准的消息平台适配器,支持反向 WebSockets。")
|
||||
class AiocqhttpAdapter(Platform):
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
super().__init__(event_queue)
|
||||
|
||||
self.config = platform_config
|
||||
self.settings = platform_settings
|
||||
self.unique_session = platform_settings['unique_session']
|
||||
self.host = platform_config['ws_reverse_host']
|
||||
self.port = platform_config['ws_reverse_port']
|
||||
|
||||
self.metadata = PlatformMetadata(
|
||||
"aiocqhttp",
|
||||
"适用于 OneBot 标准的消息平台适配器,支持反向 WebSockets。",
|
||||
)
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
ret = await AiocqhttpMessageEvent._parse_onebot_json(message_chain)
|
||||
match session.message_type.value:
|
||||
case MessageType.GROUP_MESSAGE.value:
|
||||
if "_" in session.session_id:
|
||||
# 独立会话
|
||||
_, group_id = session.session_id.split("_")
|
||||
await self.bot.send_group_msg(group_id=group_id, message=ret)
|
||||
else:
|
||||
await self.bot.send_group_msg(group_id=session.session_id, message=ret)
|
||||
case MessageType.FRIEND_MESSAGE.value:
|
||||
await self.bot.send_private_msg(user_id=session.session_id, message=ret)
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
async def convert_message(self, event: Event) -> AstrBotMessage:
|
||||
abm = AstrBotMessage()
|
||||
abm.self_id = str(event.self_id)
|
||||
abm.tag = "aiocqhttp"
|
||||
|
||||
abm.sender = MessageMember(str(event.sender['user_id']), event.sender['nickname'])
|
||||
|
||||
if event['message_type'] == 'group':
|
||||
abm.type = MessageType.GROUP_MESSAGE
|
||||
abm.group_id = str(event.group_id)
|
||||
elif event['message_type'] == 'private':
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
|
||||
if self.unique_session:
|
||||
abm.session_id = abm.sender.user_id + "_" + str(event.group_id) # 也保留群组 id
|
||||
else:
|
||||
abm.session_id = str(event.group_id) if abm.type == MessageType.GROUP_MESSAGE else abm.sender.user_id
|
||||
|
||||
abm.message_id = str(event.message_id)
|
||||
abm.message = []
|
||||
|
||||
message_str = ""
|
||||
if not isinstance(event.message, list):
|
||||
err = f"aiocqhttp: 无法识别的消息类型: {str(event.message)},此条消息将被忽略。如果您在使用 go-cqhttp,请将其配置文件中的 message.post-format 更改为 array。"
|
||||
logger.critical(err)
|
||||
try:
|
||||
self.bot.send(event, err)
|
||||
except BaseException as e:
|
||||
logger.error(f"回复消息失败: {e}")
|
||||
return
|
||||
logger.debug(f"aiocqhttp: 收到消息: {event.message}")
|
||||
for m in event.message:
|
||||
t = m['type']
|
||||
a = None
|
||||
if t == 'text':
|
||||
message_str += m['data']['text'].strip()
|
||||
elif t == 'file':
|
||||
if m['data']['url'] and m['data']['url'].startswith("http"):
|
||||
# Lagrange
|
||||
logger.info("guessing lagrange")
|
||||
|
||||
file_name = m['data'].get('file_name', "file")
|
||||
path = os.path.join("data/temp", file_name)
|
||||
await download_file(m['data']['url'], path)
|
||||
|
||||
m['data'] = {
|
||||
"file": path,
|
||||
"name": file_name
|
||||
}
|
||||
|
||||
else:
|
||||
try:
|
||||
# Napcat, LLBot
|
||||
ret = await self.bot.call_action(action="get_file", file_id=event.message[0]['data']['file_id'])
|
||||
if not ret.get('file', None):
|
||||
raise ValueError(f"无法解析文件响应: {ret}")
|
||||
if not os.path.exists(ret['file']):
|
||||
raise FileNotFoundError(f"文件不存在: {ret['file']}。如果您使用 Docker 部署了 AstrBot 或者消息协议端(Napcat等),暂时无法获取用户上传的文件。")
|
||||
|
||||
m['data'] = {
|
||||
"file": ret['file'],
|
||||
"name": ret['file_name']
|
||||
}
|
||||
except ActionFailed as e:
|
||||
logger.error(f"获取文件失败: {e},此消息段将被忽略。")
|
||||
except BaseException as e:
|
||||
logger.error(f"获取文件失败: {e},此消息段将被忽略。")
|
||||
|
||||
a = ComponentTypes[t](**m['data']) # noqa: F405
|
||||
abm.message.append(a)
|
||||
abm.timestamp = int(time.time())
|
||||
abm.message_str = message_str
|
||||
abm.raw_message = event
|
||||
return abm
|
||||
|
||||
def run(self) -> Awaitable[Any]:
|
||||
if not self.host or not self.port:
|
||||
return
|
||||
self.bot = CQHttp(use_ws_reverse=True, import_name='aiocqhttp', api_timeout_sec=180)
|
||||
@self.bot.on_message('group')
|
||||
async def group(event: Event):
|
||||
abm = await self.convert_message(event)
|
||||
if abm:
|
||||
await self.handle_msg(abm)
|
||||
|
||||
@self.bot.on_message('private')
|
||||
async def private(event: Event):
|
||||
abm = await self.convert_message(event)
|
||||
if abm:
|
||||
await self.handle_msg(abm)
|
||||
|
||||
@self.bot.on_websocket_connection
|
||||
def on_websocket_connection(_):
|
||||
logger.info("aiocqhttp 适配器已连接。")
|
||||
|
||||
bot = self.bot.run_task(host=self.host, port=int(self.port), shutdown_trigger=self.shutdown_trigger_placeholder)
|
||||
|
||||
for handler in logging.root.handlers[:]:
|
||||
logging.root.removeHandler(handler)
|
||||
logging.getLogger('aiocqhttp').setLevel(logging.ERROR)
|
||||
|
||||
return bot
|
||||
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return self.metadata
|
||||
|
||||
async def shutdown_trigger_placeholder(self):
|
||||
while not self._event_queue.closed:
|
||||
await asyncio.sleep(1)
|
||||
logger.info("aiocqhttp 适配器已关闭。")
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
|
||||
message_event = AiocqhttpMessageEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id,
|
||||
bot=self.bot
|
||||
)
|
||||
|
||||
self.commit_event(message_event)
|
||||
345
astrbot/core/platform/sources/gewechat/client.py
Normal file
345
astrbot/core/platform/sources/gewechat/client.py
Normal file
@@ -0,0 +1,345 @@
|
||||
import threading
|
||||
import asyncio
|
||||
import aiohttp
|
||||
import quart
|
||||
import base64
|
||||
|
||||
from astrbot.api.platform import AstrBotMessage, MessageMember, MessageType
|
||||
from astrbot.api.message_components import Plain, Image, At, Record
|
||||
from astrbot.api import logger, sp
|
||||
from .downloader import GeweDownloader
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
|
||||
|
||||
class SimpleGewechatClient():
|
||||
'''针对 Gewechat 的简单实现。
|
||||
|
||||
@author: Soulter
|
||||
@website: https://github.com/Soulter
|
||||
'''
|
||||
def __init__(self, base_url: str, nickname: str, host: str, port: int, event_queue: asyncio.Queue):
|
||||
self.base_url = base_url
|
||||
if self.base_url.endswith('/'):
|
||||
self.base_url = self.base_url[:-1]
|
||||
|
||||
self.download_base_url = self.base_url.split(':')[:-1] # 去掉端口
|
||||
self.download_base_url = ':'.join(self.download_base_url) + ":2532/download/"
|
||||
|
||||
self.base_url += "/v2/api"
|
||||
|
||||
logger.info(f"Gewechat API: {self.base_url}")
|
||||
logger.info(f"Gewechat 下载 API: {self.download_base_url}")
|
||||
|
||||
if isinstance(port, str):
|
||||
port = int(port)
|
||||
|
||||
self.token = None
|
||||
self.headers = {}
|
||||
self.nickname = nickname
|
||||
self.appid = sp.get(f"gewechat-appid-{nickname}", "")
|
||||
|
||||
self.server = quart.Quart(__name__)
|
||||
self.server.add_url_rule('/astrbot-gewechat/callback', view_func=self.callback, methods=['POST'])
|
||||
self.server.add_url_rule('/astrbot-gewechat/file/<file_id>', view_func=self.handle_file, methods=['GET'])
|
||||
|
||||
self.host = host
|
||||
self.port = port
|
||||
self.callback_url = f"http://{self.host}:{self.port}/astrbot-gewechat/callback"
|
||||
self.file_server_url = f"http://{self.host}:{self.port}/astrbot-gewechat/file"
|
||||
|
||||
self.event_queue = event_queue
|
||||
|
||||
self.multimedia_downloader = None
|
||||
|
||||
async def get_token_id(self):
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(f"{self.base_url}/tools/getTokenId") as resp:
|
||||
json_blob = await resp.json()
|
||||
self.token = json_blob['data']
|
||||
logger.info(f"获取到 Gewechat Token: {self.token}")
|
||||
self.headers = {
|
||||
"X-GEWE-TOKEN": self.token
|
||||
}
|
||||
|
||||
async def _convert(self, data: dict) -> AstrBotMessage:
|
||||
type_name = data['TypeName']
|
||||
if type_name == "Offline":
|
||||
logger.critical("收到 gewechat 下线通知。")
|
||||
return
|
||||
abm = AstrBotMessage()
|
||||
d = data['Data']
|
||||
|
||||
from_user_name = d['FromUserName']['string'] # 消息来源
|
||||
d['to_wxid'] = from_user_name # 用于发信息
|
||||
|
||||
abm.message_id = str(d.get('MsgId'))
|
||||
abm.session_id = from_user_name
|
||||
abm.self_id = data['Wxid'] # 机器人的 wxid
|
||||
|
||||
user_id = "" # 发送人 wxid
|
||||
content = d['Content']['string'] # 消息内容
|
||||
|
||||
at_me = False
|
||||
if "@chatroom" in from_user_name:
|
||||
abm.type = MessageType.GROUP_MESSAGE
|
||||
_t = content.split(':\n')
|
||||
user_id = _t[0]
|
||||
content = _t[1]
|
||||
if '\u2005' in content:
|
||||
# at
|
||||
content = content.split('\u2005')[1]
|
||||
abm.group_id = from_user_name
|
||||
# at
|
||||
msg_source = d['MsgSource']
|
||||
if f'<atuserlist><![CDATA[,{abm.self_id}]]>' in msg_source \
|
||||
or f'<atuserlist><![CDATA[{abm.self_id}]]>' in msg_source:
|
||||
at_me = True
|
||||
else:
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
user_id = from_user_name
|
||||
|
||||
abm.message = []
|
||||
if at_me:
|
||||
abm.message.insert(0, At(qq=abm.self_id))
|
||||
|
||||
user_real_name = d['PushContent'].split(' : ')[0] \
|
||||
.replace('在群聊中@了你', '') \
|
||||
.replace('在群聊中发了一段语音', '') # 真实昵称
|
||||
abm.sender = MessageMember(user_id, user_real_name)
|
||||
abm.raw_message = d
|
||||
abm.message_str = ""
|
||||
# 不同消息类型
|
||||
match d['MsgType']:
|
||||
case 1:
|
||||
# 文本消息
|
||||
abm.message.append(Plain(content))
|
||||
abm.message_str = content
|
||||
case 3:
|
||||
# 图片消息
|
||||
file_url = await self.multimedia_downloader.download_image(
|
||||
self.appid,
|
||||
content
|
||||
)
|
||||
logger.debug(f"下载图片: {file_url}")
|
||||
file_path = await download_image_by_url(file_url)
|
||||
abm.message.append(Image(file=file_path, url=file_path))
|
||||
|
||||
case 34:
|
||||
# 语音消息
|
||||
# data = await self.multimedia_downloader.download_voice(
|
||||
# self.appid,
|
||||
# content,
|
||||
# abm.message_id
|
||||
# )
|
||||
# print(data)
|
||||
if 'ImgBuf' in d and 'buffer' in d['ImgBuf']:
|
||||
voice_data = base64.b64decode(d['ImgBuf']['buffer'])
|
||||
file_path = f"data/temp/gewe_voice_{abm.message_id}.silk"
|
||||
with open(file_path, "wb") as f:
|
||||
f.write(voice_data)
|
||||
abm.message.append(Record(file=file_path, url=file_path))
|
||||
|
||||
case _:
|
||||
logger.error(f"未实现的消息类型: {d['MsgType']}")
|
||||
return
|
||||
|
||||
logger.info(f"abm: {abm}")
|
||||
return abm
|
||||
|
||||
async def callback(self):
|
||||
data = await quart.request.json
|
||||
logger.debug(f"收到 gewechat 回调: {data}")
|
||||
|
||||
if data.get('testMsg', None):
|
||||
return quart.jsonify({"r": "AstrBot ACK"})
|
||||
|
||||
abm = await self._convert(data)
|
||||
|
||||
if abm:
|
||||
coro = getattr(self, "on_event_received")
|
||||
if coro:
|
||||
await coro(abm)
|
||||
|
||||
return quart.jsonify({"r": "AstrBot ACK"})
|
||||
|
||||
async def handle_file(self, file_id):
|
||||
file_path = f"data/temp/{file_id}"
|
||||
return await quart.send_file(file_path)
|
||||
|
||||
async def _set_callback_url(self):
|
||||
logger.info("设置回调,请等待...")
|
||||
await asyncio.sleep(3)
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/tools/setCallback",
|
||||
headers=self.headers,
|
||||
json={
|
||||
"token": self.token,
|
||||
"callbackUrl": self.callback_url
|
||||
}
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.info(f"设置回调结果: {json_blob}")
|
||||
if json_blob['ret'] != 200:
|
||||
raise Exception(f"设置回调失败: {json_blob}")
|
||||
logger.info(f"将在 {self.callback_url} 上接收 gewechat 下发的消息。如果一直没收到消息请先尝试重启 AstrBot。")
|
||||
|
||||
async def start_polling(self):
|
||||
threading.Thread(target=asyncio.run, args=(self._set_callback_url(),)).start()
|
||||
await self.server.run_task(
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
shutdown_trigger=self.shutdown_trigger_placeholder
|
||||
)
|
||||
|
||||
async def shutdown_trigger_placeholder(self):
|
||||
while not self.event_queue.closed:
|
||||
await asyncio.sleep(1)
|
||||
logger.info("gewechat 适配器已关闭。")
|
||||
|
||||
async def check_online(self, appid: str):
|
||||
# /login/checkOnline
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/login/checkOnline",
|
||||
headers=self.headers,
|
||||
json={
|
||||
"appId": appid
|
||||
}
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
return json_blob['data']
|
||||
|
||||
async def logout(self):
|
||||
if self.appid:
|
||||
online = await self.check_online(self.appid)
|
||||
if online:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/login/logout",
|
||||
headers=self.headers,
|
||||
json={
|
||||
"appId": self.appid
|
||||
}
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.info(f"登出结果: {json_blob}")
|
||||
|
||||
async def login(self):
|
||||
if self.token is None:
|
||||
await self.get_token_id()
|
||||
|
||||
self.multimedia_downloader = GeweDownloader(self.base_url, self.download_base_url, self.token)
|
||||
|
||||
if self.appid:
|
||||
online = await self.check_online(self.appid)
|
||||
if online:
|
||||
logger.info(f"APPID: {self.appid} 已在线")
|
||||
return
|
||||
|
||||
payload = {
|
||||
"appId": self.appid
|
||||
}
|
||||
|
||||
if self.appid:
|
||||
logger.info(f"使用 APPID: {self.appid}, {self.nickname}")
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/login/getLoginQrCode",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
if json_blob['ret'] != 200:
|
||||
raise Exception(f"获取二维码失败: {json_blob}")
|
||||
qr_data = json_blob['data']['qrData']
|
||||
qr_uuid = json_blob['data']['uuid']
|
||||
appid = json_blob['data']['appId']
|
||||
logger.info(f"APPID: {appid}")
|
||||
logger.warning(f"请打开该网址,然后使用微信扫描二维码登录: https://api.cl2wm.cn/api/qrcode/code?text={qr_data}")
|
||||
|
||||
# 执行登录
|
||||
retry_cnt = 64
|
||||
payload.update({
|
||||
"uuid": qr_uuid,
|
||||
"appId": appid
|
||||
})
|
||||
while retry_cnt > 0:
|
||||
retry_cnt -= 1
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/login/checkLogin",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.info(f"检查登录状态: {json_blob}")
|
||||
status = json_blob['data']['status']
|
||||
nickname = json_blob['data'].get('nickName', '')
|
||||
if status == 1:
|
||||
logger.info(f"等待确认...{nickname}")
|
||||
elif status == 2:
|
||||
logger.info(f"绿泡泡平台登录成功: {nickname}")
|
||||
break
|
||||
elif status == 0:
|
||||
logger.info("等待扫码...")
|
||||
else:
|
||||
logger.warning(f"未知状态: {status}")
|
||||
await asyncio.sleep(5)
|
||||
|
||||
if appid:
|
||||
sp.put(f"gewechat-appid-{nickname}", appid)
|
||||
self.appid = appid
|
||||
logger.info(f"已保存 APPID: {appid}")
|
||||
|
||||
async def post_text(self, to_wxid, content: str):
|
||||
payload = {
|
||||
"appId": self.appid,
|
||||
"toWxid": to_wxid,
|
||||
"content": content,
|
||||
}
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/message/postText",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.debug(f"发送消息结果: {json_blob}")
|
||||
|
||||
async def post_image(self, to_wxid, image_url: str):
|
||||
payload = {
|
||||
"appId": self.appid,
|
||||
"toWxid": to_wxid,
|
||||
"imgUrl": image_url,
|
||||
}
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/message/postImage",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.debug(f"发送图片结果: {json_blob}")
|
||||
|
||||
async def post_voice(self, to_wxid, voice_url: str, voice_duration: int):
|
||||
payload = {
|
||||
"appId": self.appid,
|
||||
"toWxid": to_wxid,
|
||||
"voiceUrl": voice_url,
|
||||
"voiceDuration": voice_duration
|
||||
}
|
||||
|
||||
logger.debug(f"发送语音: {payload}")
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/message/postVoice",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.debug(f"发送语音结果: {json_blob}")
|
||||
51
astrbot/core/platform/sources/gewechat/downloader.py
Normal file
51
astrbot/core/platform/sources/gewechat/downloader.py
Normal file
@@ -0,0 +1,51 @@
|
||||
from astrbot import logger
|
||||
import aiohttp
|
||||
import json
|
||||
|
||||
class GeweDownloader():
|
||||
def __init__(self, base_url: str, download_base_url: str, token: str):
|
||||
self.base_url = base_url
|
||||
self.download_base_url = download_base_url
|
||||
self.headers = {
|
||||
"Content-Type": "application/json",
|
||||
"X-GEWE-TOKEN": token
|
||||
}
|
||||
|
||||
async def _post_json(self, baseurl: str, route: str, payload: dict):
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{baseurl}{route}",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
) as resp:
|
||||
return await resp.read()
|
||||
|
||||
async def download_voice(self, appid: str, xml: str, msg_id: str):
|
||||
payload = {
|
||||
"appId": appid,
|
||||
"xml": xml,
|
||||
"msgId": msg_id
|
||||
}
|
||||
return await self._post_json(self.base_url, "/message/downloadVoice", payload)
|
||||
|
||||
async def download_image(self, appid: str, xml: str) -> str:
|
||||
'''返回一个可下载的 URL'''
|
||||
choices = [2, 3] # 2:常规图片 3:缩略图
|
||||
|
||||
for choice in choices:
|
||||
try:
|
||||
payload = {
|
||||
"appId": appid,
|
||||
"xml": xml,
|
||||
"type": choice
|
||||
}
|
||||
data = await self._post_json(self.base_url, "/message/downloadImage", payload)
|
||||
json_blob = json.loads(data)
|
||||
if 'fileUrl' in json_blob['data']:
|
||||
return self.download_base_url + json_blob['data']['fileUrl']
|
||||
|
||||
except BaseException as e:
|
||||
logger.error(f"gewe download image: {e}")
|
||||
continue
|
||||
|
||||
raise Exception("无法下载图片")
|
||||
102
astrbot/core/platform/sources/gewechat/gewechat_event.py
Normal file
102
astrbot/core/platform/sources/gewechat/gewechat_event.py
Normal file
@@ -0,0 +1,102 @@
|
||||
import wave
|
||||
import uuid
|
||||
import os
|
||||
from astrbot.core.utils.io import save_temp_img, download_image_by_url, download_file
|
||||
from astrbot.core.utils.tencent_record_helper import wav_to_tencent_silk
|
||||
from astrbot.api import logger
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.platform import AstrBotMessage, PlatformMetadata
|
||||
from astrbot.api.message_components import Plain, Image, Record
|
||||
from .client import SimpleGewechatClient
|
||||
|
||||
def get_wav_duration(file_path):
|
||||
with wave.open(file_path, 'rb') as wav_file:
|
||||
file_size = os.path.getsize(file_path)
|
||||
n_channels, sampwidth, framerate, n_frames = wav_file.getparams()[:4]
|
||||
if n_frames == 2147483647:
|
||||
duration = (file_size - 44) / (n_channels * sampwidth * framerate)
|
||||
else:
|
||||
duration = n_frames / float(framerate)
|
||||
return duration
|
||||
|
||||
class GewechatPlatformEvent(AstrMessageEvent):
|
||||
def __init__(
|
||||
self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,
|
||||
client: SimpleGewechatClient
|
||||
):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.client = client
|
||||
|
||||
@staticmethod
|
||||
async def send_with_client(message: MessageChain, user_name: str):
|
||||
pass
|
||||
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
to_wxid = self.message_obj.raw_message.get('to_wxid', None)
|
||||
|
||||
if not to_wxid:
|
||||
logger.error("无法获取到 to_wxid。")
|
||||
return
|
||||
|
||||
for comp in message.chain:
|
||||
if isinstance(comp, Plain):
|
||||
await self.client.post_text(to_wxid, comp.text)
|
||||
elif isinstance(comp, Image):
|
||||
img_url = comp.file
|
||||
img_path = ""
|
||||
if img_url.startswith("file:///"):
|
||||
img_path = img_url[8:]
|
||||
elif comp.file and comp.file.startswith("http"):
|
||||
img_path = await download_image_by_url(comp.file)
|
||||
else:
|
||||
img_path = img_url
|
||||
|
||||
# 检查 record_path 是否在 data/temp 目录中, record_path 可能是绝对路径
|
||||
temp_directory = os.path.abspath('data/temp')
|
||||
img_path = os.path.abspath(img_path)
|
||||
if os.path.commonpath([temp_directory, img_path]) != temp_directory:
|
||||
with open(img_path, "rb") as f:
|
||||
img_path = save_temp_img(f.read())
|
||||
|
||||
file_id = os.path.basename(img_path)
|
||||
img_url = f"{self.client.file_server_url}/{file_id}"
|
||||
logger.debug(f"gewe callback img url: {img_url}")
|
||||
await self.client.post_image(to_wxid, img_url)
|
||||
elif isinstance(comp, Record):
|
||||
# 默认已经存在 data/temp 中
|
||||
record_url = comp.file
|
||||
record_path = ""
|
||||
|
||||
if record_url.startswith("file:///"):
|
||||
record_path = record_url[8:]
|
||||
elif record_url.startswith("http"):
|
||||
await download_file(record_url, f"data/temp/{uuid.uuid4()}.wav")
|
||||
else:
|
||||
record_path = record_url
|
||||
|
||||
silk_path = f"data/temp/{uuid.uuid4()}.silk"
|
||||
duration = await wav_to_tencent_silk(record_path, silk_path)
|
||||
|
||||
print(f"duration: {duration}, {silk_path}")
|
||||
|
||||
# 检查 record_path 是否在 data/temp 目录中, record_path 可能是绝对路径
|
||||
# temp_directory = os.path.abspath('data/temp')
|
||||
# record_path = os.path.abspath(record_path)
|
||||
# if os.path.commonpath([temp_directory, record_path]) != temp_directory:
|
||||
# with open(record_path, "rb") as f:
|
||||
# record_path = f"data/temp/{uuid.uuid4()}.wav"
|
||||
# with open(record_path, "wb") as f2:
|
||||
# f2.write(f.read())
|
||||
|
||||
if duration == 0:
|
||||
duration = get_wav_duration(record_path)
|
||||
|
||||
file_id = os.path.basename(silk_path)
|
||||
record_url = f"{self.client.file_server_url}/{file_id}"
|
||||
await self.client.post_voice(to_wxid, record_url, duration*1000)
|
||||
await super().send(message)
|
||||
@@ -0,0 +1,93 @@
|
||||
import sys
|
||||
import asyncio
|
||||
import os
|
||||
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageType, PlatformMetadata
|
||||
from astrbot.api.event import MessageChain
|
||||
from astrbot.api import logger
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from ...register import register_platform_adapter
|
||||
from .gewechat_event import GewechatPlatformEvent
|
||||
from .client import SimpleGewechatClient
|
||||
from astrbot.core.message.components import Plain
|
||||
|
||||
if sys.version_info >= (3, 12):
|
||||
from typing import override
|
||||
else:
|
||||
from typing_extensions import override
|
||||
|
||||
|
||||
@register_platform_adapter("gewechat", "基于 gewechat 的 Wechat 适配器")
|
||||
class GewechatPlatformAdapter(Platform):
|
||||
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
super().__init__(event_queue)
|
||||
self.config = platform_config
|
||||
self.settingss = platform_settings
|
||||
self.test_mode = os.environ.get('TEST_MODE', 'off') == 'on'
|
||||
self.client = None
|
||||
|
||||
@override
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
to_wxid = session.session_id
|
||||
if "_" in to_wxid:
|
||||
# 群聊,开启了独立会话
|
||||
_, to_wxid = to_wxid.split("_")
|
||||
|
||||
if not to_wxid:
|
||||
logger.error("无法获取到 to_wxid。")
|
||||
return
|
||||
|
||||
for comp in message_chain.chain:
|
||||
if isinstance(comp, Plain):
|
||||
await self.client.post_text(to_wxid, comp.text)
|
||||
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
@override
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
"gewechat",
|
||||
"基于 gewechat 的 Wechat 适配器",
|
||||
)
|
||||
|
||||
@override
|
||||
def run(self):
|
||||
self.client = SimpleGewechatClient(
|
||||
self.config['base_url'],
|
||||
self.config['nickname'],
|
||||
self.config['host'],
|
||||
self.config['port'],
|
||||
self._event_queue,
|
||||
)
|
||||
|
||||
async def on_event_received(abm: AstrBotMessage):
|
||||
await self.handle_msg(abm)
|
||||
|
||||
self.client.on_event_received = on_event_received
|
||||
|
||||
return self._run()
|
||||
|
||||
async def logout(self):
|
||||
await self.client.logout()
|
||||
|
||||
async def _run(self):
|
||||
await self.client.login()
|
||||
|
||||
await self.client.start_polling()
|
||||
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
if message.type == MessageType.GROUP_MESSAGE:
|
||||
if self.settingss['unique_session']:
|
||||
message.session_id = message.sender.user_id + "_" + message.group_id
|
||||
|
||||
message_event = GewechatPlatformEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id,
|
||||
client=self.client
|
||||
)
|
||||
|
||||
self.commit_event(message_event)
|
||||
@@ -0,0 +1,96 @@
|
||||
import botpy
|
||||
import botpy.message
|
||||
import botpy.types
|
||||
import botpy.types.message
|
||||
from astrbot.core.utils.io import file_to_base64, download_image_by_url
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.platform import AstrBotMessage, PlatformMetadata
|
||||
from astrbot.api.message_components import Plain, Image
|
||||
from botpy import Client
|
||||
from botpy.http import Route
|
||||
|
||||
|
||||
class QQOfficialMessageEvent(AstrMessageEvent):
|
||||
def __init__(self, message_str: str, message_obj: AstrBotMessage, platform_meta: PlatformMetadata, session_id: str, bot: Client):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.bot = bot
|
||||
self.send_buffer = None
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
if not self.send_buffer:
|
||||
self.send_buffer = message
|
||||
else:
|
||||
self.send_buffer.chain.extend(message.chain)
|
||||
|
||||
async def _post_send(self):
|
||||
'''QQ 官方 API 仅支持回复一次'''
|
||||
source = self.message_obj.raw_message
|
||||
assert isinstance(source, (botpy.message.Message, botpy.message.GroupMessage, botpy.message.DirectMessage, botpy.message.C2CMessage))
|
||||
|
||||
plain_text, image_base64, image_path = await QQOfficialMessageEvent._parse_to_qqofficial(self.send_buffer)
|
||||
|
||||
payload = {
|
||||
'content': plain_text,
|
||||
'msg_id': self.message_obj.message_id,
|
||||
}
|
||||
|
||||
match type(source):
|
||||
case botpy.message.GroupMessage:
|
||||
if image_base64:
|
||||
media = await self.upload_group_and_c2c_image(image_base64, 1, group_openid=source.group_openid)
|
||||
payload['media'] = media
|
||||
payload['msg_type'] = 7
|
||||
await self.bot.api.post_group_message(group_openid=source.group_openid, **payload)
|
||||
case botpy.message.C2CMessage:
|
||||
if image_base64:
|
||||
media = await self.upload_group_and_c2c_image(image_base64, 1, openid=source.author.user_openid)
|
||||
payload['media'] = media
|
||||
payload['msg_type'] = 7
|
||||
await self.bot.api.post_c2c_message(openid=source.author.user_openid, **payload)
|
||||
case botpy.message.Message:
|
||||
if image_path:
|
||||
payload['file_image'] = image_path
|
||||
await self.bot.api.post_message(channel_id=source.channel_id, **payload)
|
||||
case botpy.message.DirectMessage:
|
||||
if image_path:
|
||||
payload['file_image'] = image_path
|
||||
await self.bot.api.post_dms(guild_id=source.guild_id, **payload)
|
||||
|
||||
await super().send(self.send_buffer)
|
||||
|
||||
self.send_buffer = None
|
||||
|
||||
async def upload_group_and_c2c_image(self, image_base64: str, file_type: int, **kwargs) -> botpy.types.message.Media:
|
||||
payload = {
|
||||
'file_data': image_base64,
|
||||
'file_type': file_type,
|
||||
"srv_send_msg": False
|
||||
}
|
||||
if 'openid' in kwargs:
|
||||
payload['openid'] = kwargs['openid']
|
||||
route = Route("POST", "/v2/users/{openid}/files", openid=kwargs['openid'])
|
||||
return await self.bot.api._http.request(route, json=payload)
|
||||
elif 'group_openid' in kwargs:
|
||||
payload['group_openid'] = kwargs['group_openid']
|
||||
route = Route("POST", "/v2/groups/{group_openid}/files", group_openid=kwargs['group_openid'])
|
||||
return await self.bot.api._http.request(route, json=payload)
|
||||
|
||||
@staticmethod
|
||||
async def _parse_to_qqofficial(message: MessageChain):
|
||||
plain_text = ""
|
||||
image_base64 = None # only one img supported
|
||||
image_file_path = None
|
||||
for i in message.chain:
|
||||
if isinstance(i, Plain):
|
||||
plain_text += i.text
|
||||
elif isinstance(i, Image) and not image_base64:
|
||||
if i.file and i.file.startswith("file:///"):
|
||||
image_base64 = file_to_base64(i.file[8:]).replace("base64://", "")
|
||||
image_file_path = i.file[8:]
|
||||
elif i.file and i.file.startswith("http"):
|
||||
image_file_path = await download_image_by_url(i.file)
|
||||
image_base64 = file_to_base64(image_file_path).replace("base64://", "")
|
||||
else:
|
||||
image_base64 = file_to_base64(i.file).replace("base64://", "")
|
||||
image_file_path = i.file
|
||||
return plain_text, image_base64, image_file_path
|
||||
@@ -0,0 +1,179 @@
|
||||
import botpy
|
||||
import logging
|
||||
import time
|
||||
import asyncio
|
||||
import botpy.message
|
||||
import botpy.types
|
||||
import botpy.types.message
|
||||
import os
|
||||
|
||||
from botpy import Client
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
from astrbot.api.event import MessageChain
|
||||
from typing import Union, List
|
||||
from astrbot.api.message_components import Image, Plain, At
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from .qqofficial_message_event import QQOfficialMessageEvent
|
||||
from ...register import register_platform_adapter
|
||||
from astrbot.core.message.components import BaseMessageComponent
|
||||
|
||||
# remove logger handler
|
||||
for handler in logging.root.handlers[:]:
|
||||
logging.root.removeHandler(handler)
|
||||
|
||||
# QQ 机器人官方框架
|
||||
class botClient(Client):
|
||||
def set_platform(self, platform: 'QQOfficialPlatformAdapter'):
|
||||
self.platform = platform
|
||||
|
||||
# 收到群消息
|
||||
async def on_group_at_message_create(self, message: botpy.message.GroupMessage):
|
||||
abm = self.platform._parse_from_qqofficial(message, MessageType.GROUP_MESSAGE)
|
||||
abm.session_id = abm.sender.user_id if self.platform.unique_session else message.group_openid
|
||||
self._commit(abm)
|
||||
|
||||
# 收到频道消息
|
||||
async def on_at_message_create(self, message: botpy.message.Message):
|
||||
abm = self.platform._parse_from_qqofficial(message, MessageType.GROUP_MESSAGE)
|
||||
abm.session_id = abm.sender.user_id if self.platform.unique_session else message.channel_id
|
||||
self._commit(abm)
|
||||
|
||||
# 收到私聊消息
|
||||
async def on_direct_message_create(self, message: botpy.message.DirectMessage):
|
||||
abm = self.platform._parse_from_qqofficial(message, MessageType.FRIEND_MESSAGE)
|
||||
abm.session_id = abm.sender.user_id
|
||||
self._commit(abm)
|
||||
|
||||
# 收到 C2C 消息
|
||||
async def on_c2c_message_create(self, message: botpy.message.C2CMessage):
|
||||
abm = self.platform._parse_from_qqofficial(message, MessageType.FRIEND_MESSAGE)
|
||||
abm.session_id = abm.sender.user_id
|
||||
self._commit(abm)
|
||||
|
||||
def _commit(self, abm: AstrBotMessage):
|
||||
self.platform.commit_event(QQOfficialMessageEvent(
|
||||
abm.message_str,
|
||||
abm,
|
||||
self.platform.meta(),
|
||||
abm.session_id,
|
||||
self.platform.client
|
||||
))
|
||||
@register_platform_adapter("qq_official", "QQ 机器人官方 API 适配器")
|
||||
class QQOfficialPlatformAdapter(Platform):
|
||||
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
super().__init__(event_queue)
|
||||
|
||||
self.config = platform_config
|
||||
|
||||
self.appid = platform_config['appid']
|
||||
self.secret = platform_config['secret']
|
||||
self.unique_session = platform_settings['unique_session']
|
||||
qq_group = platform_config['enable_group_c2c']
|
||||
guild_dm = platform_config['enable_guild_direct_message']
|
||||
|
||||
if qq_group:
|
||||
self.intents = botpy.Intents(
|
||||
public_messages=True,
|
||||
public_guild_messages=True,
|
||||
direct_message=guild_dm
|
||||
)
|
||||
else:
|
||||
self.intents = botpy.Intents(
|
||||
public_guild_messages=True,
|
||||
direct_message=guild_dm
|
||||
)
|
||||
self.client = botClient(
|
||||
intents=self.intents,
|
||||
bot_log=False,
|
||||
timeout=20,
|
||||
)
|
||||
|
||||
self.client.set_platform(self)
|
||||
|
||||
self.test_mode = os.environ.get('TEST_MODE', 'off') == 'on'
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
raise NotImplementedError("QQ 机器人官方 API 适配器不支持 send_by_session")
|
||||
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
"qq_official",
|
||||
"QQ 机器人官方 API 适配器",
|
||||
)
|
||||
|
||||
def _parse_from_qqofficial(self, message: Union[botpy.message.Message, botpy.message.GroupMessage],
|
||||
message_type: MessageType):
|
||||
abm = AstrBotMessage()
|
||||
abm.type = message_type
|
||||
abm.timestamp = int(time.time())
|
||||
abm.raw_message = message
|
||||
abm.message_id = message.id
|
||||
abm.tag = "qq_official"
|
||||
msg: List[BaseMessageComponent] = []
|
||||
|
||||
|
||||
if isinstance(message, botpy.message.GroupMessage) or isinstance(message, botpy.message.C2CMessage):
|
||||
if isinstance(message, botpy.message.GroupMessage):
|
||||
abm.sender = MessageMember(
|
||||
message.author.member_openid,
|
||||
""
|
||||
)
|
||||
abm.group_id = message.group_openid
|
||||
else:
|
||||
abm.sender = MessageMember(
|
||||
message.author.user_openid,
|
||||
""
|
||||
)
|
||||
abm.message_str = message.content.strip()
|
||||
abm.self_id = "unknown_selfid"
|
||||
msg.append(At(qq="qq_official"))
|
||||
msg.append(Plain(abm.message_str))
|
||||
if message.attachments:
|
||||
for i in message.attachments:
|
||||
if i.content_type.startswith("image"):
|
||||
url = i.url
|
||||
if not url.startswith("http"):
|
||||
url = "https://"+url
|
||||
img = Image.fromURL(url)
|
||||
msg.append(img)
|
||||
abm.message = msg
|
||||
|
||||
elif isinstance(message, botpy.message.Message) or isinstance(message, botpy.message.DirectMessage):
|
||||
try:
|
||||
abm.self_id = str(message.mentions[0].id)
|
||||
except BaseException as _:
|
||||
abm.self_id = ""
|
||||
|
||||
plain_content = message.content.replace(
|
||||
"<@!"+str(abm.self_id)+">", "").strip()
|
||||
|
||||
if message.attachments:
|
||||
for i in message.attachments:
|
||||
if i.content_type.startswith("image"):
|
||||
url = i.url
|
||||
if not url.startswith("http"):
|
||||
url = "https://"+url
|
||||
img = Image.fromURL(url)
|
||||
msg.append(img)
|
||||
abm.message = msg
|
||||
abm.message_str = plain_content
|
||||
abm.sender = MessageMember(
|
||||
str(message.author.id),
|
||||
str(message.author.username)
|
||||
)
|
||||
msg.append(At(qq="qq_official"))
|
||||
msg.append(Plain(plain_content))
|
||||
|
||||
if isinstance(message, botpy.message.Message):
|
||||
abm.group_id = message.channel_id
|
||||
else:
|
||||
raise ValueError(f"Unknown message type: {message_type}")
|
||||
abm.self_id = "qq_official"
|
||||
return abm
|
||||
|
||||
def run(self):
|
||||
return self.client.start(
|
||||
appid=self.appid,
|
||||
secret=self.secret
|
||||
)
|
||||
44
astrbot/core/platform/sources/vchat/vchat_message_event.py
Normal file
44
astrbot/core/platform/sources/vchat/vchat_message_event.py
Normal file
@@ -0,0 +1,44 @@
|
||||
import random
|
||||
import asyncio
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
from astrbot.api import logger
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.platform import AstrBotMessage, PlatformMetadata
|
||||
from astrbot.api.message_components import Plain, Image
|
||||
from vchat import Core
|
||||
|
||||
class VChatPlatformEvent(AstrMessageEvent):
|
||||
def __init__(self, message_str: str, message_obj: AstrBotMessage, platform_meta: PlatformMetadata, session_id: str, client: Core):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.client = client
|
||||
|
||||
@staticmethod
|
||||
async def send_with_client(client: Core, message: MessageChain, user_name: str):
|
||||
plain = ""
|
||||
for comp in message.chain:
|
||||
if isinstance(comp, Plain):
|
||||
if message.is_split_:
|
||||
await client.send_msg(comp.text, user_name)
|
||||
else:
|
||||
plain += comp.text
|
||||
elif isinstance(comp, Image):
|
||||
if comp.file and comp.file.startswith("file:///"):
|
||||
file_path = comp.file.replace("file:///", "")
|
||||
with open(file_path, "rb") as f:
|
||||
await client.send_image(user_name, fd=f)
|
||||
elif comp.file and comp.file.startswith("http"):
|
||||
image_path = await download_image_by_url(comp.file)
|
||||
with open(image_path, "rb") as f:
|
||||
await client.send_image(user_name, fd=f)
|
||||
else:
|
||||
logger.error(f"不支持的 vchat(微信适配器) 消息类型: {comp}")
|
||||
await asyncio.sleep(random.uniform(0.5, 1.5)) # 🤓
|
||||
|
||||
if plain:
|
||||
await client.send_msg(plain, user_name)
|
||||
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
await VChatPlatformEvent.send_with_client(self.client, message, self.message_obj.raw_message.from_.username)
|
||||
await super().send(message)
|
||||
|
||||
120
astrbot/core/platform/sources/vchat/vchat_platform_adapter.py
Normal file
120
astrbot/core/platform/sources/vchat/vchat_platform_adapter.py
Normal file
@@ -0,0 +1,120 @@
|
||||
import sys
|
||||
import time
|
||||
import uuid
|
||||
import asyncio
|
||||
import os
|
||||
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
from astrbot.api.event import MessageChain
|
||||
from astrbot.api.message_components import *
|
||||
from astrbot.api import logger
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from .vchat_message_event import VChatPlatformEvent
|
||||
from ...register import register_platform_adapter
|
||||
|
||||
from vchat import Core
|
||||
from vchat import model
|
||||
|
||||
if sys.version_info >= (3, 12):
|
||||
from typing import override
|
||||
else:
|
||||
from typing_extensions import override
|
||||
|
||||
@register_platform_adapter("vchat", "基于 VChat 的 Wechat 适配器")
|
||||
class VChatPlatformAdapter(Platform):
|
||||
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
super().__init__(event_queue)
|
||||
self.config = platform_config
|
||||
self.settingss = platform_settings
|
||||
self.test_mode = os.environ.get('TEST_MODE', 'off') == 'on'
|
||||
self.client_self_id = uuid.uuid4().hex[:8]
|
||||
|
||||
@override
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
from_username = session.session_id.split('$$')[0]
|
||||
await VChatPlatformEvent.send_with_client(self.client, message_chain, from_username)
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
@override
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
"vchat",
|
||||
"基于 VChat 的 Wechat 适配器",
|
||||
)
|
||||
|
||||
@override
|
||||
def run(self):
|
||||
self.client = Core()
|
||||
@self.client.msg_register(msg_types=model.ContentTypes.TEXT,
|
||||
contact_type=model.ContactTypes.CHATROOM | model.ContactTypes.USER)
|
||||
async def _(msg: model.Message):
|
||||
if isinstance(msg.content, model.UselessContent):
|
||||
return
|
||||
if msg.create_time < self.start_time:
|
||||
logger.debug(f"忽略旧消息: {msg}")
|
||||
return
|
||||
logger.debug(f"收到消息: {msg.todict()}")
|
||||
abmsg = self.convert_message(msg)
|
||||
# await self.handle_msg(abmsg) # 不能直接调用,否则会阻塞
|
||||
asyncio.create_task(self.handle_msg(abmsg))
|
||||
|
||||
# TODO: 对齐微信服务器时间
|
||||
self.start_time = int(time.time())
|
||||
return self._run()
|
||||
|
||||
|
||||
async def _run(self):
|
||||
await self.client.init()
|
||||
await self.client.auto_login(hot_reload=True, enable_cmd_qr=True)
|
||||
await self.client.run()
|
||||
|
||||
def convert_message(self, msg: model.Message) -> AstrBotMessage:
|
||||
# credits: https://github.com/z2z63/astrbot_plugin_vchat/blob/master/main.py#L49
|
||||
assert isinstance(msg.content, model.TextContent)
|
||||
amsg = AstrBotMessage()
|
||||
amsg.message = [Plain(msg.content.content)]
|
||||
amsg.self_id = self.client_self_id
|
||||
if msg.content.is_at_me:
|
||||
amsg.message.insert(0, At(qq=amsg.self_id))
|
||||
|
||||
sender = msg.chatroom_sender or msg.from_
|
||||
amsg.sender = MessageMember(sender.username, sender.nickname)
|
||||
|
||||
if msg.content.is_at_me:
|
||||
amsg.message_str = msg.content.content.split("\u2005")[1].strip()
|
||||
else:
|
||||
amsg.message_str = msg.content.content
|
||||
amsg.message_id = msg.message_id
|
||||
if isinstance(msg.from_, model.User):
|
||||
amsg.type = MessageType.FRIEND_MESSAGE
|
||||
elif isinstance(msg.from_, model.Chatroom):
|
||||
amsg.type = MessageType.GROUP_MESSAGE
|
||||
amsg.group_id = msg.from_.username
|
||||
else:
|
||||
logger.error(f"不支持的 Wechat 消息类型: {msg.from_}")
|
||||
|
||||
amsg.raw_message = msg
|
||||
|
||||
if self.settingss['unique_session']:
|
||||
session_id = msg.from_.username + "$$" + msg.to.username
|
||||
if msg.chatroom_sender is not None:
|
||||
session_id += '$$' + msg.chatroom_sender.username
|
||||
else:
|
||||
session_id = msg.from_.username
|
||||
|
||||
amsg.session_id = session_id
|
||||
return amsg
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
message_event = VChatPlatformEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id,
|
||||
client=self.client
|
||||
)
|
||||
|
||||
logger.info(f"处理消息: {message_event}")
|
||||
|
||||
self.commit_event(message_event)
|
||||
112
astrbot/core/platform/sources/webchat/webchat_adapter.py
Normal file
112
astrbot/core/platform/sources/webchat/webchat_adapter.py
Normal file
@@ -0,0 +1,112 @@
|
||||
import time
|
||||
import asyncio
|
||||
import uuid
|
||||
import os
|
||||
from typing import Awaitable, Any
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
from astrbot.api.event import MessageChain
|
||||
from astrbot.api.message_components import Plain, Image, Record # noqa: F403
|
||||
from astrbot.api import logger
|
||||
from astrbot.core import web_chat_queue, web_chat_back_queue
|
||||
from .webchat_event import WebChatMessageEvent
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from ...register import register_platform_adapter
|
||||
|
||||
class QueueListener:
|
||||
def __init__(self, queue: asyncio.Queue, callback: callable) -> None:
|
||||
self.queue = queue
|
||||
self.callback = callback
|
||||
|
||||
async def run(self):
|
||||
while True:
|
||||
data = await self.queue.get()
|
||||
await self.callback(data)
|
||||
|
||||
@register_platform_adapter("webchat", "webchat")
|
||||
class WebChatAdapter(Platform):
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
super().__init__(event_queue)
|
||||
|
||||
self.config = platform_config
|
||||
self.settings = platform_settings
|
||||
self.unique_session = platform_settings['unique_session']
|
||||
self.imgs_dir = "data/webchat/imgs"
|
||||
|
||||
self.metadata = PlatformMetadata(
|
||||
"webchat",
|
||||
"webchat",
|
||||
)
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
# abm.session_id = f"webchat!{username}!{cid}"
|
||||
plain = ""
|
||||
cid = session.session_id.split("!")[-1]
|
||||
for comp in message_chain.chain:
|
||||
if isinstance(comp, Plain):
|
||||
plain += comp.text
|
||||
web_chat_back_queue.put_nowait((plain, cid))
|
||||
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
async def convert_message(self, data: tuple) -> AstrBotMessage:
|
||||
username, cid, payload = data
|
||||
|
||||
|
||||
abm = AstrBotMessage()
|
||||
abm.self_id = "webchat"
|
||||
abm.tag = "webchat"
|
||||
abm.sender = MessageMember(username, username)
|
||||
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
|
||||
abm.session_id = f"webchat!{username}!{cid}"
|
||||
|
||||
abm.message_id = str(uuid.uuid4())
|
||||
abm.message = []
|
||||
|
||||
if payload['message']:
|
||||
abm.message.append(Plain(payload['message']))
|
||||
if payload['image_url']:
|
||||
if isinstance(payload['image_url'], list):
|
||||
for img in payload['image_url']:
|
||||
abm.message.append(Image.fromFileSystem(os.path.join(self.imgs_dir, img)))
|
||||
else:
|
||||
abm.message.append(Image.fromFileSystem(os.path.join(self.imgs_dir, payload['image_url'])))
|
||||
if payload['audio_url']:
|
||||
if isinstance(payload['audio_url'], list):
|
||||
for audio in payload['audio_url']:
|
||||
path = os.path.join(self.imgs_dir, audio)
|
||||
abm.message.append(Record(file=path, path=path))
|
||||
else:
|
||||
path = os.path.join(self.imgs_dir, payload['audio_url'])
|
||||
abm.message.append(Record(file=path, path=path))
|
||||
|
||||
logger.debug(f"WebChatAdapter: {abm.message}")
|
||||
|
||||
message_str = payload['message']
|
||||
abm.timestamp = int(time.time())
|
||||
abm.message_str = message_str
|
||||
abm.raw_message = data
|
||||
return abm
|
||||
|
||||
def run(self) -> Awaitable[Any]:
|
||||
async def callback(data: tuple):
|
||||
abm = await self.convert_message(data)
|
||||
await self.handle_msg(abm)
|
||||
|
||||
bot = QueueListener(web_chat_queue, callback)
|
||||
return bot.run()
|
||||
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return self.metadata
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
|
||||
message_event = WebChatMessageEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id
|
||||
)
|
||||
|
||||
self.commit_event(message_event)
|
||||
41
astrbot/core/platform/sources/webchat/webchat_event.py
Normal file
41
astrbot/core/platform/sources/webchat/webchat_event.py
Normal file
@@ -0,0 +1,41 @@
|
||||
import os
|
||||
import uuid
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.message_components import Plain, Image
|
||||
from astrbot.core.utils.io import file_to_base64, download_image_by_url
|
||||
from astrbot.core import web_chat_back_queue
|
||||
|
||||
class WebChatMessageEvent(AstrMessageEvent):
|
||||
def __init__(self, message_str, message_obj, platform_meta, session_id):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.imgs_dir = "data/webchat/imgs"
|
||||
os.makedirs(self.imgs_dir, exist_ok=True)
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
if not message:
|
||||
web_chat_back_queue.put_nowait(None)
|
||||
return
|
||||
|
||||
cid = self.session_id.split("!")[-1]
|
||||
|
||||
for comp in message.chain:
|
||||
if isinstance(comp, Plain):
|
||||
web_chat_back_queue.put_nowait((comp.text, cid))
|
||||
elif isinstance(comp, Image):
|
||||
# save image to local
|
||||
filename = str(uuid.uuid4()) + ".jpg"
|
||||
path = os.path.join(self.imgs_dir, filename)
|
||||
if comp.file and comp.file.startswith("file:///"):
|
||||
ph = comp.file[8:]
|
||||
with open(path, "wb") as f:
|
||||
with open(ph, "rb") as f2:
|
||||
f.write(f2.read())
|
||||
elif comp.file and comp.file.startswith("http"):
|
||||
await download_image_by_url(comp.file, path=path)
|
||||
else:
|
||||
with open(path, "wb") as f:
|
||||
with open(comp.file, "rb") as f2:
|
||||
f.write(f2.read())
|
||||
web_chat_back_queue.put_nowait((f"[IMAGE]{filename}", cid))
|
||||
web_chat_back_queue.put_nowait(None)
|
||||
await super().send(message)
|
||||
10
astrbot/core/provider/__init__.py
Normal file
10
astrbot/core/provider/__init__.py
Normal file
@@ -0,0 +1,10 @@
|
||||
from .provider import Provider, Personality, STTProvider
|
||||
|
||||
from .entites import ProviderMetaData
|
||||
|
||||
__all__ = [
|
||||
"Provider",
|
||||
"Personality",
|
||||
"ProviderMetaData",
|
||||
"STTProvider"
|
||||
]
|
||||
54
astrbot/core/provider/entites.py
Normal file
54
astrbot/core/provider/entites.py
Normal file
@@ -0,0 +1,54 @@
|
||||
import enum
|
||||
from dataclasses import dataclass, field
|
||||
from typing import List, Dict, Type
|
||||
from .func_tool_manager import FuncCall
|
||||
|
||||
|
||||
class ProviderType(enum.Enum):
|
||||
CHAT_COMPLETION = "chat_completion"
|
||||
SPEECH_TO_TEXT = "speech_to_text"
|
||||
TEXT_TO_SPEECH = "text_to_speech"
|
||||
|
||||
@dataclass
|
||||
class ProviderMetaData():
|
||||
type: str
|
||||
'''提供商适配器名称,如 openai, ollama'''
|
||||
desc: str = ""
|
||||
'''提供商适配器描述.'''
|
||||
provider_type: ProviderType = ProviderType.CHAT_COMPLETION
|
||||
cls_type: Type = None
|
||||
|
||||
default_config_tmpl: dict = None
|
||||
'''平台的默认配置模板'''
|
||||
provider_display_name: str = None
|
||||
'''显示在 WebUI 配置页中的提供商名称,如空则是 type'''
|
||||
|
||||
@dataclass
|
||||
class ProviderRequest():
|
||||
prompt: str
|
||||
'''提示词'''
|
||||
session_id: str = ""
|
||||
'''会话 ID'''
|
||||
image_urls: List[str] = None
|
||||
'''图片 URL 列表'''
|
||||
func_tool: FuncCall = None
|
||||
'''工具'''
|
||||
contexts: List = None
|
||||
'''上下文。格式与 openai 的上下文格式一致:
|
||||
参考 https://platform.openai.com/docs/api-reference/chat/create#chat-create-messages
|
||||
'''
|
||||
|
||||
system_prompt: str = ""
|
||||
'''系统提示词'''
|
||||
|
||||
|
||||
@dataclass
|
||||
class LLMResponse:
|
||||
role: str
|
||||
'''角色'''
|
||||
completion_text: str = ""
|
||||
'''LLM 返回的文本'''
|
||||
tools_call_args: List[Dict[str, any]] = field(default_factory=list)
|
||||
'''工具调用参数'''
|
||||
tools_call_name: List[str] = field(default_factory=list)
|
||||
'''工具调用名称'''
|
||||
198
astrbot/core/provider/func_tool_manager.py
Normal file
198
astrbot/core/provider/func_tool_manager.py
Normal file
@@ -0,0 +1,198 @@
|
||||
import json
|
||||
import textwrap
|
||||
from typing import Dict, List, Awaitable
|
||||
from dataclasses import dataclass
|
||||
|
||||
|
||||
@dataclass
|
||||
class FuncTool:
|
||||
"""
|
||||
用于描述一个函数调用工具。
|
||||
"""
|
||||
|
||||
name: str
|
||||
parameters: Dict
|
||||
description: str
|
||||
handler: Awaitable
|
||||
handler_module_path: str = None # 必须要保留这个,handler 在初始化会被 functools.partial 包装,导致 handler 的 __module__ 为 functools
|
||||
|
||||
active: bool = True
|
||||
'''是否激活'''
|
||||
|
||||
SUPPORTED_TYPES = [
|
||||
"string",
|
||||
"number",
|
||||
"object",
|
||||
"array",
|
||||
"boolean",
|
||||
] # json schema 支持的数据类型
|
||||
|
||||
|
||||
class FuncCall:
|
||||
def __init__(self) -> None:
|
||||
self.func_list: List[FuncTool] = []
|
||||
|
||||
def empty(self) -> bool:
|
||||
return len(self.func_list) == 0
|
||||
|
||||
def add_func(
|
||||
self,
|
||||
name: str,
|
||||
func_args: list,
|
||||
desc: str,
|
||||
handler: Awaitable,
|
||||
) -> None:
|
||||
"""
|
||||
为函数调用(function-calling / tools-use)添加工具。
|
||||
|
||||
@param name: 函数名
|
||||
@param func_args: 函数参数列表,格式为 [{"type": "string", "name": "arg_name", "description": "arg_description"}, ...]
|
||||
@param desc: 函数描述
|
||||
@param func_obj: 处理函数
|
||||
"""
|
||||
params = {
|
||||
"type": "object", # hard-coded here
|
||||
"properties": {},
|
||||
}
|
||||
for param in func_args:
|
||||
params["properties"][param["name"]] = {
|
||||
"type": param["type"],
|
||||
"description": param["description"],
|
||||
}
|
||||
_func = FuncTool(
|
||||
name=name,
|
||||
parameters=params,
|
||||
description=desc,
|
||||
handler=handler,
|
||||
)
|
||||
self.func_list.append(_func)
|
||||
|
||||
def remove_func(self, name: str) -> None:
|
||||
"""
|
||||
删除一个函数调用工具。
|
||||
"""
|
||||
for i, f in enumerate(self.func_list):
|
||||
if f["name"] == name:
|
||||
self.func_list.pop(i)
|
||||
break
|
||||
|
||||
def get_func(self, name) -> FuncTool:
|
||||
for f in self.func_list:
|
||||
if f.name == name:
|
||||
return f
|
||||
return None
|
||||
|
||||
def get_func_desc_openai_style(self) -> list:
|
||||
"""
|
||||
获得 OpenAI API 风格的**已经激活**的工具描述
|
||||
"""
|
||||
_l = []
|
||||
for f in self.func_list:
|
||||
if not f.active:
|
||||
continue
|
||||
_l.append(
|
||||
{
|
||||
"type": "function",
|
||||
"function": {
|
||||
"name": f.name,
|
||||
"parameters": f.parameters,
|
||||
"description": f.description,
|
||||
},
|
||||
}
|
||||
)
|
||||
return _l
|
||||
|
||||
def get_func_desc_google_genai_style(self) -> Dict:
|
||||
declarations = {}
|
||||
tools = []
|
||||
for f in self.func_list:
|
||||
if not f.active:
|
||||
continue
|
||||
tools.append(
|
||||
{
|
||||
"name": f.name,
|
||||
"parameters": f.parameters,
|
||||
"description": f.description,
|
||||
}
|
||||
)
|
||||
declarations["function_declarations"] = tools
|
||||
return declarations
|
||||
|
||||
|
||||
async def func_call(self, question: str, session_id: str, provider) -> tuple:
|
||||
_l = []
|
||||
for f in self.func_list:
|
||||
if not f.active:
|
||||
continue
|
||||
_l.append(
|
||||
{
|
||||
"name": f["name"],
|
||||
"parameters": f["parameters"],
|
||||
"description": f["description"],
|
||||
}
|
||||
)
|
||||
func_definition = json.dumps(_l, ensure_ascii=False)
|
||||
|
||||
prompt = textwrap.dedent(f"""
|
||||
ROLE:
|
||||
你是一个 Function calling AI Agent, 你的任务是将用户的提问转化为函数调用。
|
||||
|
||||
TOOLS:
|
||||
可用的函数列表:
|
||||
|
||||
{func_definition}
|
||||
|
||||
LIMIT:
|
||||
1. 你返回的内容应当能够被 Python 的 json 模块解析的 Json 格式字符串。
|
||||
2. 你的 Json 返回的格式如下:`[{{"name": "<func_name>", "args": <arg_dict>}}, ...]`。参数根据上面提供的函数列表中的参数来填写。
|
||||
3. 允许必要时返回多个函数调用,但需保证这些函数调用的顺序正确。
|
||||
4. 如果用户的提问中不需要用到给定的函数,请直接返回 `{{"res": False}}`。
|
||||
|
||||
EXAMPLE:
|
||||
1. `用户提问`:请问一下天气怎么样? `函数调用`:[{{"name": "get_weather", "args": {{"city": "北京"}}}}]
|
||||
|
||||
用户的提问是:{question}
|
||||
""")
|
||||
|
||||
_c = 0
|
||||
while _c < 3:
|
||||
try:
|
||||
res = await provider.text_chat(prompt, session_id)
|
||||
if res.find("```") != -1:
|
||||
res = res[res.find("```json") + 7 : res.rfind("```")]
|
||||
res = json.loads(res)
|
||||
break
|
||||
except Exception as e:
|
||||
_c += 1
|
||||
if _c == 3:
|
||||
raise e
|
||||
if "The message you submitted was too long" in str(e):
|
||||
raise e
|
||||
|
||||
if "res" in res and not res["res"]:
|
||||
return "", False
|
||||
|
||||
tool_call_result = []
|
||||
for tool in res:
|
||||
# 说明有函数调用
|
||||
func_name = tool["name"]
|
||||
args = tool["args"]
|
||||
# 调用函数
|
||||
tool_callable = None
|
||||
for func in self.func_list:
|
||||
if func.name == func_name:
|
||||
tool_callable = func.star_handler_metadata.handler
|
||||
break
|
||||
if not tool_callable:
|
||||
raise Exception(f"Request function {func_name} not found.")
|
||||
ret = await tool_callable(**args)
|
||||
if ret:
|
||||
tool_call_result.append(str(ret))
|
||||
return tool_call_result, True
|
||||
|
||||
|
||||
def __str__(self):
|
||||
return str(self.func_list)
|
||||
|
||||
def __repr__(self):
|
||||
return str(self.func_list)
|
||||
211
astrbot/core/provider/manager.py
Normal file
211
astrbot/core/provider/manager.py
Normal file
@@ -0,0 +1,211 @@
|
||||
import traceback
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from .provider import Provider, STTProvider, TTSProvider, Personality
|
||||
from .entites import ProviderType
|
||||
from typing import List
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from collections import defaultdict
|
||||
from .register import provider_cls_map, llm_tools
|
||||
from astrbot.core import logger, sp
|
||||
|
||||
class ProviderManager():
|
||||
def __init__(self, config: AstrBotConfig, db_helper: BaseDatabase):
|
||||
self.providers_config: List = config['provider']
|
||||
self.provider_settings: dict = config['provider_settings']
|
||||
self.provider_stt_settings: dict = config.get('provider_stt_settings', {})
|
||||
self.persona_configs: list = config.get('persona', [])
|
||||
|
||||
self.default_persona_name = self.provider_settings.get('default_personality', 'default')
|
||||
self.personas: List[Personality] = []
|
||||
self.selected_default_persona = None
|
||||
for persona in self.persona_configs:
|
||||
begin_dialogs = persona.get("begin_dialogs", [])
|
||||
mood_imitation_dialogs = persona.get("mood_imitation_dialogs", [])
|
||||
bd_processed = []
|
||||
mid_processed = ""
|
||||
if begin_dialogs:
|
||||
if len(begin_dialogs) % 2 != 0:
|
||||
logger.error(f"{persona['name']} 人格情景预设对话格式不对,条数应该为偶数。")
|
||||
continue
|
||||
user_turn = True
|
||||
for dialog in begin_dialogs:
|
||||
bd_processed.append({
|
||||
"role": "user" if user_turn else "assistant",
|
||||
"content": dialog,
|
||||
"_no_save": None # 不持久化到 db
|
||||
})
|
||||
user_turn = not user_turn
|
||||
if mood_imitation_dialogs:
|
||||
if len(mood_imitation_dialogs) % 2 != 0:
|
||||
logger.error(f"{persona['name']} 对话风格对话格式不对,条数应该为偶数。")
|
||||
continue
|
||||
user_turn = True
|
||||
for dialog in begin_dialogs:
|
||||
role = "A" if user_turn else "B"
|
||||
mid_processed += f"{role}: {dialog}\n"
|
||||
if not user_turn:
|
||||
mid_processed += '\n'
|
||||
user_turn = not user_turn
|
||||
|
||||
try:
|
||||
persona = Personality(
|
||||
**persona,
|
||||
_begin_dialogs_processed=bd_processed,
|
||||
_mood_imitation_dialogs_processed=mid_processed
|
||||
)
|
||||
if persona['name'] == self.default_persona_name:
|
||||
self.selected_default_persona = persona
|
||||
self.personas.append(persona)
|
||||
except Exception as e:
|
||||
logger.error(f"解析 Persona 配置失败:{e}")
|
||||
|
||||
|
||||
self.provider_insts: List[Provider] = []
|
||||
'''加载的 Provider 的实例'''
|
||||
self.stt_provider_insts: List[STTProvider] = []
|
||||
'''加载的 Speech To Text Provider 的实例'''
|
||||
self.tts_provider_insts: List[TTSProvider] = []
|
||||
'''加载的 Text To Speech Provider 的实例'''
|
||||
self.llm_tools = llm_tools
|
||||
self.curr_provider_inst: Provider = None
|
||||
'''当前使用的 Provider 实例'''
|
||||
self.curr_stt_provider_inst: STTProvider = None
|
||||
'''当前使用的 Speech To Text Provider 实例'''
|
||||
self.curr_tts_provider_inst: TTSProvider = None
|
||||
'''当前使用的 Text To Speech Provider 实例'''
|
||||
self.loaded_ids = defaultdict(bool)
|
||||
self.db_helper = db_helper
|
||||
|
||||
# kdb(experimental)
|
||||
self.curr_kdb_name = ""
|
||||
kdb_cfg = config.get("knowledge_db", {})
|
||||
if kdb_cfg and len(kdb_cfg):
|
||||
self.curr_kdb_name = list(kdb_cfg.keys())[0]
|
||||
|
||||
for provider_cfg in self.providers_config:
|
||||
if not provider_cfg['enable']:
|
||||
continue
|
||||
|
||||
if provider_cfg['id'] in self.loaded_ids:
|
||||
raise ValueError(f"Provider ID 重复:{provider_cfg['id']}。")
|
||||
self.loaded_ids[provider_cfg['id']] = True
|
||||
|
||||
try:
|
||||
match provider_cfg['type']:
|
||||
case "openai_chat_completion":
|
||||
from .sources.openai_source import ProviderOpenAIOfficial # noqa: F401
|
||||
case "zhipu_chat_completion":
|
||||
from .sources.zhipu_source import ProviderZhipu # noqa: F401
|
||||
case "llm_tuner":
|
||||
logger.info("加载 LLM Tuner 工具 ...")
|
||||
from .sources.llmtuner_source import LLMTunerModelLoader # noqa: F401
|
||||
case "dify":
|
||||
from .sources.dify_source import ProviderDify # noqa: F401
|
||||
case "googlegenai_chat_completion":
|
||||
from .sources.gemini_source import ProviderGoogleGenAI # noqa: F401
|
||||
case "openai_whisper_api":
|
||||
from .sources.whisper_api_source import ProviderOpenAIWhisperAPI # noqa: F401
|
||||
case "openai_whisper_selfhost":
|
||||
from .sources.whisper_selfhosted_source import ProviderOpenAIWhisperSelfHost # noqa: F401
|
||||
case "openai_tts_api":
|
||||
from .sources.openai_tts_api_source import ProviderOpenAITTSAPI # noqa: F401
|
||||
except (ImportError, ModuleNotFoundError) as e:
|
||||
logger.critical(f"加载 {provider_cfg['type']}({provider_cfg['id']}) 提供商适配器失败:{e}。可能是因为有未安装的依赖。")
|
||||
continue
|
||||
except Exception as e:
|
||||
logger.critical(f"加载 {provider_cfg['type']}({provider_cfg['id']}) 提供商适配器失败:{e}。未知原因")
|
||||
continue
|
||||
|
||||
async def initialize(self):
|
||||
|
||||
selected_provider_id = sp.get("curr_provider")
|
||||
selected_stt_provider_id = self.provider_stt_settings.get("provider_id")
|
||||
selected_tts_provider_id = self.provider_settings.get("provider_id")
|
||||
provider_enabled = self.provider_settings.get("enable", False)
|
||||
stt_enabled = self.provider_stt_settings.get("enable", False)
|
||||
tts_enabled = self.provider_settings.get("enable", False)
|
||||
|
||||
for provider_config in self.providers_config:
|
||||
if not provider_config['enable']:
|
||||
continue
|
||||
if provider_config['type'] not in provider_cls_map:
|
||||
logger.error(f"未找到适用于 {provider_config['type']}({provider_config['id']}) 的提供商适配器,请检查是否已经安装或者名称填写错误。已跳过。")
|
||||
continue
|
||||
|
||||
provider_metadata = provider_cls_map[provider_config['type']]
|
||||
logger.info(f"尝试实例化 {provider_config['type']}({provider_config['id']}) 提供商适配器 ...")
|
||||
try:
|
||||
# 按任务实例化提供商
|
||||
|
||||
if provider_metadata.provider_type == ProviderType.SPEECH_TO_TEXT:
|
||||
# STT 任务
|
||||
inst = provider_metadata.cls_type(provider_config, self.provider_settings)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.stt_provider_insts.append(inst)
|
||||
if selected_stt_provider_id == provider_config['id'] and stt_enabled:
|
||||
self.curr_stt_provider_inst = inst
|
||||
logger.info(f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前语音转文本提供商适配器。")
|
||||
|
||||
elif provider_metadata.provider_type == ProviderType.TEXT_TO_SPEECH:
|
||||
# TTS 任务
|
||||
inst = provider_metadata.cls_type(provider_config, self.provider_settings)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.tts_provider_insts.append(inst)
|
||||
if selected_tts_provider_id == provider_config['id'] and tts_enabled:
|
||||
self.curr_tts_provider_inst = inst
|
||||
logger.info(f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前文本转语音提供商适配器。")
|
||||
|
||||
elif provider_metadata.provider_type == ProviderType.CHAT_COMPLETION:
|
||||
# 文本生成任务
|
||||
inst = provider_metadata.cls_type(
|
||||
provider_config,
|
||||
self.provider_settings,
|
||||
self.db_helper,
|
||||
self.provider_settings.get('persistant_history', True),
|
||||
self.selected_default_persona
|
||||
)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.provider_insts.append(inst)
|
||||
if selected_provider_id == provider_config['id'] and provider_enabled:
|
||||
self.curr_provider_inst = inst
|
||||
logger.info(f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前提供商适配器。")
|
||||
|
||||
except Exception as e:
|
||||
traceback.print_exc()
|
||||
logger.error(f"实例化 {provider_config['type']}({provider_config['id']}) 提供商适配器失败:{e}")
|
||||
|
||||
if len(self.provider_insts) > 0 and not self.curr_provider_inst and provider_enabled:
|
||||
self.curr_provider_inst = self.provider_insts[0]
|
||||
|
||||
if len(self.stt_provider_insts) > 0 and not self.curr_stt_provider_inst and stt_enabled:
|
||||
self.curr_stt_provider_inst = self.stt_provider_insts[0]
|
||||
|
||||
if len(self.tts_provider_insts) > 0 and not self.curr_tts_provider_inst and tts_enabled:
|
||||
self.curr_tts_provider_inst = self.tts_provider_insts[0]
|
||||
|
||||
if not self.curr_provider_inst:
|
||||
logger.warning("未启用任何用于 文本生成 的提供商适配器。")
|
||||
|
||||
if stt_enabled and not self.curr_stt_provider_inst:
|
||||
logger.warning("未启用任何用于 语音转文本 的提供商适配器。")
|
||||
|
||||
if tts_enabled and not self.curr_tts_provider_inst:
|
||||
logger.warning("未启用任何用于 文本转语音 的提供商适配器。")
|
||||
|
||||
|
||||
def get_insts(self):
|
||||
return self.provider_insts
|
||||
|
||||
async def terminate(self):
|
||||
for provider_inst in self.provider_insts:
|
||||
if hasattr(provider_inst, "terminate"):
|
||||
await provider_inst.terminate()
|
||||
171
astrbot/core/provider/provider.py
Normal file
171
astrbot/core/provider/provider.py
Normal file
@@ -0,0 +1,171 @@
|
||||
import abc
|
||||
import json
|
||||
from collections import defaultdict
|
||||
from typing import List
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot.core import logger
|
||||
from typing import TypedDict
|
||||
from astrbot.core.provider.func_tool_manager import FuncCall
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
from dataclasses import dataclass
|
||||
class Personality(TypedDict):
|
||||
prompt: str = ""
|
||||
name: str = ""
|
||||
begin_dialogs: List[str] = []
|
||||
mood_imitation_dialogs: List[str] = []
|
||||
|
||||
# cache
|
||||
_begin_dialogs_processed: List[dict]
|
||||
_mood_imitation_dialogs_processed: str
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProviderMeta():
|
||||
id: str
|
||||
model: str
|
||||
type: str
|
||||
|
||||
|
||||
class AbstractProvider(abc.ABC):
|
||||
def __init__(self, provider_config: dict) -> None:
|
||||
super().__init__()
|
||||
self.model_name = ""
|
||||
self.provider_config = provider_config
|
||||
|
||||
def set_model(self, model_name: str):
|
||||
'''设置当前使用的模型名称'''
|
||||
self.model_name = model_name
|
||||
|
||||
def get_model(self) -> str:
|
||||
'''获得当前使用的模型名称'''
|
||||
return self.model_name
|
||||
|
||||
def meta(self) -> ProviderMeta:
|
||||
'''获取 Provider 的元数据'''
|
||||
return ProviderMeta(
|
||||
id=self.provider_config['id'],
|
||||
model=self.get_model(),
|
||||
type=self.provider_config['type']
|
||||
)
|
||||
|
||||
|
||||
class Provider(AbstractProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
persistant_history: bool = True,
|
||||
db_helper: BaseDatabase = None,
|
||||
default_persona: Personality = None
|
||||
) -> None:
|
||||
super().__init__(provider_config)
|
||||
|
||||
self.session_memory = defaultdict(list)
|
||||
'''维护了 session_id 的上下文,**不包含 system 指令**。'''
|
||||
|
||||
self.provider_settings = provider_settings
|
||||
|
||||
self.curr_personality: Personality = default_persona
|
||||
'''维护了当前的使用的 persona,即人格。可能为 None'''
|
||||
|
||||
self.db_helper = db_helper
|
||||
'''用于持久化的数据库操作对象。'''
|
||||
|
||||
if persistant_history:
|
||||
# 读取历史记录
|
||||
try:
|
||||
for history in db_helper.get_llm_history(provider_type=provider_config['type']):
|
||||
self.session_memory[history.session_id] = json.loads(history.content)
|
||||
except BaseException as e:
|
||||
logger.warning(f"读取 LLM 对话历史记录 失败:{e}。仍可正常使用。")
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_current_key(self) -> str:
|
||||
raise NotImplementedError()
|
||||
|
||||
def get_keys(self) -> List[str]:
|
||||
'''获得提供商 Key'''
|
||||
return self.provider_config.get("key", [])
|
||||
|
||||
@abc.abstractmethod
|
||||
def set_key(self, key: str):
|
||||
raise NotImplementedError()
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_models(self) -> List[str]:
|
||||
'''获得支持的模型列表'''
|
||||
raise NotImplementedError()
|
||||
|
||||
@abc.abstractmethod
|
||||
async def get_human_readable_context(self, session_id: str, page: int, page_size: int):
|
||||
'''获取人类可读的上下文
|
||||
|
||||
page 从 1 开始
|
||||
|
||||
Example:
|
||||
|
||||
["User: 你好", "Assistant: 你好!"]
|
||||
|
||||
Return:
|
||||
contexts: List[str]: 上下文列表
|
||||
total_pages: int: 总页数
|
||||
'''
|
||||
raise NotImplementedError()
|
||||
|
||||
@abc.abstractmethod
|
||||
async def text_chat(self,
|
||||
prompt: str,
|
||||
session_id: str=None,
|
||||
image_urls: List[str]=None,
|
||||
func_tool: FuncCall=None,
|
||||
contexts: List=None,
|
||||
system_prompt: str=None,
|
||||
**kwargs) -> LLMResponse:
|
||||
'''获得 LLM 的文本对话结果。会使用当前的模型进行对话。
|
||||
|
||||
Args:
|
||||
prompt: 提示词
|
||||
session_id: 会话 ID
|
||||
image_urls: 图片 URL 列表
|
||||
tools: Function-calling 工具
|
||||
contexts: 上下文
|
||||
kwargs: 其他参数
|
||||
|
||||
Notes:
|
||||
- 如果传入了 contexts,将会提前加上上下文。否则使用 session_memory 中的上下文。
|
||||
- 可以选择性地传入 session_id,如果传入了 session_id,将会使用 session_id 对应的上下文进行对话,
|
||||
并且也会记录相应的对话上下文,实现多轮对话。如果不传入则不会记录上下文。
|
||||
- 如果传入了 image_urls,将会在对话时附上图片。如果模型不支持图片输入,将会抛出错误。
|
||||
- 如果传入了 tools,将会使用 tools 进行 Function-calling。如果模型不支持 Function-calling,将会抛出错误。
|
||||
'''
|
||||
raise NotImplementedError()
|
||||
|
||||
@abc.abstractmethod
|
||||
async def forget(self, session_id: str) -> bool:
|
||||
'''重置某一个 session_id 的上下文'''
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
|
||||
class STTProvider(AbstractProvider):
|
||||
def __init__(self, provider_config: dict, provider_settings: dict) -> None:
|
||||
super().__init__(provider_config)
|
||||
self.provider_config = provider_config
|
||||
self.provider_settings = provider_settings
|
||||
|
||||
@abc.abstractmethod
|
||||
async def get_text(self, audio_url: str) -> str:
|
||||
'''获取音频的文本'''
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
class TTSProvider(AbstractProvider):
|
||||
def __init__(self, provider_config: dict, provider_settings: dict) -> None:
|
||||
super().__init__(provider_config)
|
||||
self.provider_config = provider_config
|
||||
self.provider_settings = provider_settings
|
||||
|
||||
@abc.abstractmethod
|
||||
async def get_audio(self, text: str) -> str:
|
||||
'''获取文本的音频,返回音频文件路径'''
|
||||
raise NotImplementedError()
|
||||
47
astrbot/core/provider/register.py
Normal file
47
astrbot/core/provider/register.py
Normal file
@@ -0,0 +1,47 @@
|
||||
from typing import List, Dict, Type
|
||||
from .entites import ProviderMetaData, ProviderType
|
||||
from astrbot.core import logger
|
||||
from .func_tool_manager import FuncCall
|
||||
|
||||
provider_registry: List[ProviderMetaData] = []
|
||||
'''维护了通过装饰器注册的 Provider'''
|
||||
provider_cls_map: Dict[str, ProviderMetaData] = {}
|
||||
'''维护了 Provider 类型名称和 ProviderMetadata 的映射'''
|
||||
|
||||
llm_tools = FuncCall()
|
||||
|
||||
def register_provider_adapter(
|
||||
provider_type_name: str,
|
||||
desc: str,
|
||||
provider_type: ProviderType = ProviderType.CHAT_COMPLETION,
|
||||
default_config_tmpl: dict = None,
|
||||
provider_display_name: str = None
|
||||
):
|
||||
'''用于注册平台适配器的带参装饰器'''
|
||||
def decorator(cls):
|
||||
if provider_type_name in provider_cls_map:
|
||||
raise ValueError(f"检测到大模型提供商适配器 {provider_type_name} 已经注册,可能发生了大模型提供商适配器类型命名冲突。")
|
||||
|
||||
# 添加必备选项
|
||||
if default_config_tmpl:
|
||||
if 'type' not in default_config_tmpl:
|
||||
default_config_tmpl['type'] = provider_type_name
|
||||
if 'enable' not in default_config_tmpl:
|
||||
default_config_tmpl['enable'] = False
|
||||
if 'id' not in default_config_tmpl:
|
||||
default_config_tmpl['id'] = provider_type_name
|
||||
|
||||
pm = ProviderMetaData(
|
||||
type=provider_type_name,
|
||||
desc=desc,
|
||||
provider_type=provider_type,
|
||||
cls_type=cls,
|
||||
default_config_tmpl=default_config_tmpl,
|
||||
provider_display_name=provider_display_name
|
||||
)
|
||||
provider_registry.append(pm)
|
||||
provider_cls_map[provider_type_name] = pm
|
||||
logger.debug(f"服务提供商 Provider {provider_type_name} 已注册")
|
||||
return cls
|
||||
|
||||
return decorator
|
||||
138
astrbot/core/provider/sources/dify_source.py
Normal file
138
astrbot/core/provider/sources/dify_source.py
Normal file
@@ -0,0 +1,138 @@
|
||||
from typing import List
|
||||
from .. import Provider, Personality
|
||||
from ..entites import LLMResponse
|
||||
from ..func_tool_manager import FuncCall
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core.utils.dify_api_client import DifyAPIClient
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
from astrbot.core import logger, sp
|
||||
|
||||
@register_provider_adapter("dify", "Dify APP 适配器。")
|
||||
class ProviderDify(Provider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history=False,
|
||||
default_persona: Personality=None
|
||||
) -> None:
|
||||
super().__init__(
|
||||
provider_config, provider_settings, persistant_history, db_helper, default_persona
|
||||
)
|
||||
self.api_key = provider_config.get("dify_api_key", "")
|
||||
if not self.api_key:
|
||||
raise Exception("Dify API Key 不能为空。")
|
||||
api_base = provider_config.get("dify_api_base", "https://api.dify.ai/v1")
|
||||
self.api_client = DifyAPIClient(self.api_key, api_base)
|
||||
self.api_type = provider_config.get("dify_api_type", "")
|
||||
if not self.api_type:
|
||||
raise Exception("Dify API 类型不能为空。")
|
||||
self.model_name = "dify"
|
||||
self.workflow_output_key = provider_config.get("dify_workflow_output_key", "astrbot_wf_output")
|
||||
|
||||
self.conversation_ids = {}
|
||||
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str = None,
|
||||
image_urls: List[str] = None,
|
||||
func_tool: FuncCall = None,
|
||||
contexts: List = None,
|
||||
system_prompt: str = None,
|
||||
**kwargs,
|
||||
) -> LLMResponse:
|
||||
result = ""
|
||||
conversation_id = self.conversation_ids.get(session_id, "")
|
||||
|
||||
files_payload = []
|
||||
for image_url in image_urls:
|
||||
if image_url.startswith("http"):
|
||||
image_path = await download_image_by_url(image_url)
|
||||
file_response = await self.api_client.file_upload(image_path, user=session_id)
|
||||
if 'id' not in file_response:
|
||||
logger.warning(f"上传图片后得到未知的 Dify 响应:{file_response},图片将忽略。")
|
||||
continue
|
||||
files_payload.append({
|
||||
"type": "image",
|
||||
"transfer_method": "local_file",
|
||||
"upload_file_id": file_response['id'],
|
||||
})
|
||||
else:
|
||||
# TODO: 处理更多情况
|
||||
logger.warning(f"未知的图片链接:{image_url},图片将忽略。")
|
||||
|
||||
logger.debug(files_payload)
|
||||
|
||||
# 获得会话变量
|
||||
session_vars = sp.get("session_variables", {})
|
||||
session_var = session_vars.get(session_id, {})
|
||||
|
||||
match self.api_type:
|
||||
case "chat" | "agent":
|
||||
async for chunk in self.api_client.chat_messages(
|
||||
inputs={
|
||||
**session_var
|
||||
},
|
||||
query=prompt,
|
||||
user=session_id,
|
||||
conversation_id=conversation_id,
|
||||
files=files_payload
|
||||
):
|
||||
logger.debug(f"dify resp chunk: {chunk}")
|
||||
if chunk['event'] == "message" or \
|
||||
chunk['event'] == "agent_message":
|
||||
result += chunk['answer']
|
||||
if not conversation_id:
|
||||
self.conversation_ids[session_id] = chunk['conversation_id']
|
||||
conversation_id = chunk['conversation_id']
|
||||
|
||||
case "workflow":
|
||||
async for chunk in self.api_client.workflow_run(
|
||||
inputs={
|
||||
"astrbot_text_query": prompt,
|
||||
"astrbot_session_id": session_id,
|
||||
**session_var
|
||||
},
|
||||
user=session_id,
|
||||
files=files_payload
|
||||
):
|
||||
match chunk['event']:
|
||||
case "workflow_started":
|
||||
logger.info(f"Dify 工作流(ID: {chunk['workflow_run_id']})开始运行。")
|
||||
case "node_finished":
|
||||
logger.debug(f"Dify 工作流节点(ID: {chunk['data']['node_id']} Title: {chunk['data'].get('title', '')})运行结束。")
|
||||
case "workflow_finished":
|
||||
logger.info(f"Dify 工作流(ID: {chunk['workflow_run_id']})运行结束。")
|
||||
if chunk['data']['error']:
|
||||
logger.error(f"Dify 工作流出现错误:{chunk['data']['error']}")
|
||||
raise Exception(f"Dify 工作流出现错误:{chunk['data']['error']}")
|
||||
if self.workflow_output_key not in chunk['data']['outputs']:
|
||||
raise Exception(f"Dify 工作流的输出不包含指定的键名:{self.workflow_output_key}")
|
||||
result = chunk['data']['outputs'][self.workflow_output_key]
|
||||
case _:
|
||||
raise Exception(f"未知的 Dify API 类型:{self.api_type}")
|
||||
|
||||
return LLMResponse(role="assistant", completion_text=result)
|
||||
|
||||
async def forget(self, session_id):
|
||||
self.conversation_ids.pop(session_id, None)
|
||||
return True
|
||||
|
||||
async def get_current_key(self):
|
||||
return self.api_key
|
||||
|
||||
async def set_key(self, key):
|
||||
raise Exception("Dify 适配器不支持设置 API Key。")
|
||||
|
||||
async def get_models(self):
|
||||
return [self.get_model()]
|
||||
|
||||
async def get_human_readable_context(self, session_id, page, page_size):
|
||||
raise Exception("暂不支持获得 Dify 的历史消息记录。")
|
||||
|
||||
async def terminate(self):
|
||||
await self.api_client.close()
|
||||
304
astrbot/core/provider/sources/gemini_source.py
Normal file
304
astrbot/core/provider/sources/gemini_source.py
Normal file
@@ -0,0 +1,304 @@
|
||||
import traceback
|
||||
import base64
|
||||
import json
|
||||
import aiohttp
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot.api.provider import Provider, Personality
|
||||
from astrbot import logger
|
||||
from astrbot.core.provider.func_tool_manager import FuncCall
|
||||
from typing import List
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
|
||||
class SimpleGoogleGenAIClient():
|
||||
def __init__(self, api_key: str, api_base: str):
|
||||
self.api_key = api_key
|
||||
if api_base.endswith("/"):
|
||||
self.api_base = api_base[:-1]
|
||||
else:
|
||||
self.api_base = api_base
|
||||
self.client = aiohttp.ClientSession(trust_env=True)
|
||||
|
||||
async def models_list(self) -> List[str]:
|
||||
request_url = f"{self.api_base}/v1beta/models?key={self.api_key}"
|
||||
async with self.client.get(request_url, timeout=10) as resp:
|
||||
response = await resp.json()
|
||||
|
||||
models = []
|
||||
for model in response["models"]:
|
||||
if 'generateContent' in model["supportedGenerationMethods"]:
|
||||
models.append(model["name"].replace("models/", ""))
|
||||
return models
|
||||
|
||||
async def generate_content(
|
||||
self,
|
||||
contents: List[dict],
|
||||
model: str="gemini-1.5-flash",
|
||||
system_instruction: str="",
|
||||
tools: dict=None
|
||||
):
|
||||
payload = {}
|
||||
if system_instruction:
|
||||
payload["system_instruction"] = {
|
||||
"parts": {"text": system_instruction}
|
||||
}
|
||||
if tools:
|
||||
payload["tools"] = [tools]
|
||||
payload["contents"] = contents
|
||||
logger.debug(f"payload: {payload}")
|
||||
request_url = f"{self.api_base}/v1beta/models/{model}:generateContent?key={self.api_key}"
|
||||
async with self.client.post(request_url, json=payload, timeout=10) as resp:
|
||||
response = await resp.json()
|
||||
return response
|
||||
|
||||
|
||||
@register_provider_adapter("googlegenai_chat_completion", "Google Gemini Chat Completion 提供商适配器")
|
||||
class ProviderGoogleGenAI(Provider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history = True,
|
||||
default_persona: Personality=None
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings, persistant_history, db_helper, default_persona)
|
||||
self.chosen_api_key = None
|
||||
self.api_keys: List = provider_config.get("key", [])
|
||||
self.chosen_api_key = self.api_keys[0] if len(self.api_keys) > 0 else None
|
||||
|
||||
self.client = SimpleGoogleGenAIClient(
|
||||
api_key=self.chosen_api_key,
|
||||
api_base=provider_config.get("api_base", None)
|
||||
)
|
||||
self.set_model(provider_config['model_config']['model'])
|
||||
|
||||
async def get_human_readable_context(self, session_id, page, page_size):
|
||||
if session_id not in self.session_memory:
|
||||
raise Exception("会话 ID 不存在")
|
||||
contexts = []
|
||||
temp_contexts = []
|
||||
for record in self.session_memory[session_id]:
|
||||
if record['role'] == "user":
|
||||
temp_contexts.append(f"User: {record['content']}")
|
||||
elif record['role'] == "assistant":
|
||||
temp_contexts.append(f"Assistant: {record['content']}")
|
||||
contexts.insert(0, temp_contexts)
|
||||
temp_contexts = []
|
||||
|
||||
# 展平 contexts 列表
|
||||
contexts = [item for sublist in contexts for item in sublist]
|
||||
|
||||
# 计算分页
|
||||
paged_contexts = contexts[(page-1)*page_size:page*page_size]
|
||||
total_pages = len(contexts) // page_size
|
||||
if len(contexts) % page_size != 0:
|
||||
total_pages += 1
|
||||
|
||||
return paged_contexts, total_pages
|
||||
|
||||
async def get_models(self):
|
||||
return await self.client.models_list()
|
||||
|
||||
async def pop_record(self, session_id: str, pop_system_prompt: bool = False):
|
||||
'''
|
||||
弹出第一条记录
|
||||
'''
|
||||
if session_id not in self.session_memory:
|
||||
raise Exception("会话 ID 不存在")
|
||||
|
||||
if len(self.session_memory[session_id]) == 0:
|
||||
return None
|
||||
|
||||
for i in range(len(self.session_memory[session_id])):
|
||||
# 检查是否是 system prompt
|
||||
if not pop_system_prompt and self.session_memory[session_id][i]['user']['role'] == "system":
|
||||
# 如果只有一个 system prompt,才不删掉
|
||||
f = False
|
||||
for j in range(i+1, len(self.session_memory[session_id])):
|
||||
if self.session_memory[session_id][j]['user']['role'] == "system":
|
||||
f = True
|
||||
break
|
||||
if not f:
|
||||
continue
|
||||
record = self.session_memory[session_id].pop(i)
|
||||
break
|
||||
|
||||
return record
|
||||
|
||||
async def _query(self, payloads: dict, tools: FuncCall) -> LLMResponse:
|
||||
tool = None
|
||||
if tools:
|
||||
tool = tools.get_func_desc_google_genai_style()
|
||||
if not tool:
|
||||
tool = None
|
||||
|
||||
system_instruction = ""
|
||||
for message in payloads["messages"]:
|
||||
if message["role"] == "system":
|
||||
system_instruction = message["content"]
|
||||
break
|
||||
|
||||
google_genai_conversation = []
|
||||
for message in payloads["messages"]:
|
||||
if message["role"] == "user":
|
||||
if isinstance(message["content"], str):
|
||||
google_genai_conversation.append({
|
||||
"role": "user",
|
||||
"parts": [{"text": message["content"]}]
|
||||
})
|
||||
elif isinstance(message["content"], list):
|
||||
# images
|
||||
parts = []
|
||||
for part in message["content"]:
|
||||
if part["type"] == "text":
|
||||
parts.append({"text": part["text"]})
|
||||
elif part["type"] == "image_url":
|
||||
parts.append({"inline_data": {
|
||||
"mime_type": "image/jpeg",
|
||||
"data": part["image_url"]["url"].replace("data:image/jpeg;base64,", "") # base64
|
||||
}})
|
||||
google_genai_conversation.append({
|
||||
"role": "user",
|
||||
"parts": parts
|
||||
})
|
||||
|
||||
elif message["role"] == "assistant":
|
||||
google_genai_conversation.append({
|
||||
"role": "model",
|
||||
"parts": [{"text": message["content"]}]
|
||||
})
|
||||
|
||||
|
||||
logger.debug(f"google_genai_conversation: {google_genai_conversation}")
|
||||
|
||||
result = await self.client.generate_content(
|
||||
contents=google_genai_conversation,
|
||||
model=self.get_model(),
|
||||
system_instruction=system_instruction,
|
||||
tools=tool
|
||||
)
|
||||
logger.debug(f"result: {result}")
|
||||
|
||||
candidates = result["candidates"][0]['content']['parts']
|
||||
llm_response = LLMResponse("assistant")
|
||||
for candidate in candidates:
|
||||
if 'text' in candidate:
|
||||
llm_response.completion_text += candidate['text']
|
||||
elif 'functionCall' in candidate:
|
||||
llm_response.role = "tool"
|
||||
llm_response.tools_call_args.append(candidate['functionCall']['args'])
|
||||
llm_response.tools_call_name.append(candidate['functionCall']['name'])
|
||||
|
||||
return llm_response
|
||||
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str,
|
||||
image_urls: List[str]=None,
|
||||
func_tool: FuncCall=None,
|
||||
contexts=None,
|
||||
system_prompt=None,
|
||||
**kwargs
|
||||
) -> LLMResponse:
|
||||
new_record = await self.assemble_context(prompt, image_urls)
|
||||
context_query = []
|
||||
if not contexts:
|
||||
context_query = [*self.session_memory[session_id], new_record]
|
||||
else:
|
||||
context_query = [*contexts, new_record]
|
||||
if system_prompt:
|
||||
context_query.insert(0, {"role": "system", "content": system_prompt})
|
||||
|
||||
for part in context_query:
|
||||
if '_no_save' in part:
|
||||
del part['_no_save']
|
||||
|
||||
payloads = {
|
||||
"messages": context_query,
|
||||
**self.provider_config.get("model_config", {})
|
||||
}
|
||||
|
||||
try:
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
await self.save_history(contexts, new_record, session_id, llm_response)
|
||||
return llm_response
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt = 10
|
||||
while retry_cnt > 0:
|
||||
logger.warning(f"请求失败:{e}。上下文长度超过限制。尝试弹出最早的记录然后重试。")
|
||||
try:
|
||||
self.pop_record(session_id)
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
break
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt -= 1
|
||||
else:
|
||||
raise e
|
||||
else:
|
||||
raise e
|
||||
|
||||
async def save_history(self, contexts: List, new_record: dict, session_id: str, llm_response: LLMResponse):
|
||||
if llm_response.role == "assistant" and session_id:
|
||||
# 文本回复
|
||||
if not contexts:
|
||||
# 添加用户 record
|
||||
self.session_memory[session_id].append(new_record)
|
||||
# 添加 assistant record
|
||||
self.session_memory[session_id].append({
|
||||
"role": "assistant",
|
||||
"content": llm_response.completion_text
|
||||
})
|
||||
else:
|
||||
contexts_to_save = list(filter(lambda item: '_no_save' not in item, contexts))
|
||||
self.session_memory[session_id] = [*contexts_to_save, new_record, {
|
||||
"role": "assistant",
|
||||
"content": llm_response.completion_text
|
||||
}]
|
||||
self.db_helper.update_llm_history(session_id, json.dumps(self.session_memory[session_id]), self.provider_config['type'])
|
||||
|
||||
async def forget(self, session_id: str) -> bool:
|
||||
self.session_memory[session_id] = []
|
||||
return True
|
||||
|
||||
def get_current_key(self) -> str:
|
||||
return self.client.api_key
|
||||
|
||||
def get_keys(self) -> List[str]:
|
||||
return self.api_keys
|
||||
|
||||
def set_key(self, key):
|
||||
self.client.api_key = key
|
||||
|
||||
async def assemble_context(self, text: str, image_urls: List[str] = None):
|
||||
'''
|
||||
组装上下文。
|
||||
'''
|
||||
if image_urls:
|
||||
user_content = {"role": "user","content": [{"type": "text", "text": text}]}
|
||||
for image_url in image_urls:
|
||||
if image_url.startswith("http"):
|
||||
image_path = await download_image_by_url(image_url)
|
||||
image_data = await self.encode_image_bs64(image_path)
|
||||
else:
|
||||
image_data = await self.encode_image_bs64(image_url)
|
||||
user_content["content"].append({"type": "image_url", "image_url": {"url": image_data}})
|
||||
return user_content
|
||||
else:
|
||||
return {"role": "user","content": text}
|
||||
|
||||
async def encode_image_bs64(self, image_url: str) -> str:
|
||||
'''
|
||||
将图片转换为 base64
|
||||
'''
|
||||
if image_url.startswith("base64://"):
|
||||
return image_url.replace("base64://", "data:image/jpeg;base64,")
|
||||
with open(image_url, "rb") as f:
|
||||
image_bs64 = base64.b64encode(f.read()).decode('utf-8')
|
||||
return "data:image/jpeg;base64," + image_bs64
|
||||
return ''
|
||||
158
astrbot/core/provider/sources/llmtuner_source.py
Normal file
158
astrbot/core/provider/sources/llmtuner_source.py
Normal file
@@ -0,0 +1,158 @@
|
||||
import json
|
||||
import os
|
||||
from llmtuner.chat import ChatModel
|
||||
from typing import List
|
||||
from .. import Provider, Personality
|
||||
from ..entites import LLMResponse
|
||||
from ..func_tool_manager import FuncCall
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from ..register import register_provider_adapter
|
||||
|
||||
|
||||
@register_provider_adapter(
|
||||
"llm_tuner", "LLMTuner 适配器, 用于装载使用 LlamaFactory 微调后的模型"
|
||||
)
|
||||
class LLMTunerModelLoader(Provider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history=True,
|
||||
default_persona=None,
|
||||
) -> None:
|
||||
super().__init__(
|
||||
provider_config, provider_settings, persistant_history, db_helper, default_persona
|
||||
)
|
||||
if not os.path.exists(provider_config["base_model_path"]) or not os.path.exists(
|
||||
provider_config["adapter_model_path"]
|
||||
):
|
||||
raise FileNotFoundError("模型文件路径不存在。")
|
||||
self.base_model_path = provider_config["base_model_path"]
|
||||
self.adapter_model_path = provider_config["adapter_model_path"]
|
||||
self.model = ChatModel(
|
||||
{
|
||||
"model_name_or_path": self.base_model_path,
|
||||
"adapter_name_or_path": self.adapter_model_path,
|
||||
"template": provider_config["llmtuner_template"],
|
||||
"finetuning_type": provider_config["finetuning_type"],
|
||||
"quantization_bit": provider_config["quantization_bit"],
|
||||
}
|
||||
)
|
||||
self.set_model(
|
||||
os.path.basename(self.base_model_path)
|
||||
+ "_"
|
||||
+ os.path.basename(self.adapter_model_path)
|
||||
)
|
||||
|
||||
async def assemble_context(self, text: str, image_urls: List[str] = None):
|
||||
"""
|
||||
组装上下文。
|
||||
"""
|
||||
return {"role": "user", "content": text}
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str = None,
|
||||
image_urls: List[str] = None,
|
||||
func_tool: FuncCall = None,
|
||||
contexts: List = None,
|
||||
system_prompt: str = None,
|
||||
**kwargs,
|
||||
) -> LLMResponse:
|
||||
system_prompt = ""
|
||||
new_record = {"role": "user", "content": prompt}
|
||||
if not contexts:
|
||||
query_context = [
|
||||
*self.session_memory[session_id],
|
||||
new_record,
|
||||
]
|
||||
system_prompt = self.curr_personality["prompt"]
|
||||
else:
|
||||
query_context = [*contexts, new_record]
|
||||
|
||||
# 提取出系统提示
|
||||
system_idxs = []
|
||||
for idx, context in enumerate(query_context):
|
||||
if context["role"] == "system":
|
||||
system_idxs.append(idx)
|
||||
|
||||
if '_no_save' in context:
|
||||
del context['_no_save']
|
||||
|
||||
for idx in reversed(system_idxs):
|
||||
system_prompt += " " + query_context.pop(idx)["content"]
|
||||
|
||||
conf = {
|
||||
"messages": query_context,
|
||||
"system": system_prompt,
|
||||
}
|
||||
if func_tool:
|
||||
tool_list = func_tool.get_func_desc_openai_style()
|
||||
if tool_list:
|
||||
conf['tools'] = tool_list
|
||||
|
||||
responses = await self.model.achat(**conf)
|
||||
|
||||
llm_response = LLMResponse("assistant", responses[-1].response_text)
|
||||
|
||||
await self.save_history(contexts, new_record, session_id, llm_response)
|
||||
|
||||
return llm_response
|
||||
|
||||
async def save_history(self, contexts: List, new_record: dict, session_id: str, llm_response: LLMResponse):
|
||||
if llm_response.role == "assistant" and session_id:
|
||||
# 文本回复
|
||||
if not contexts:
|
||||
# 添加用户 record
|
||||
self.session_memory[session_id].append(new_record)
|
||||
# 添加 assistant record
|
||||
self.session_memory[session_id].append({
|
||||
"role": "assistant",
|
||||
"content": llm_response.completion_text
|
||||
})
|
||||
else:
|
||||
contexts_to_save = list(filter(lambda item: '_no_save' not in item, contexts))
|
||||
self.session_memory[session_id] = [*contexts_to_save, new_record, {
|
||||
"role": "assistant",
|
||||
"content": llm_response.completion_text
|
||||
}]
|
||||
self.db_helper.update_llm_history(session_id, json.dumps(self.session_memory[session_id]), self.provider_config['type'])
|
||||
|
||||
async def forget(self, session_id):
|
||||
self.session_memory[session_id] = []
|
||||
return True
|
||||
|
||||
async def get_current_key(self):
|
||||
return "none"
|
||||
|
||||
async def set_key(self, key):
|
||||
pass
|
||||
|
||||
async def get_models(self):
|
||||
return [self.get_model()]
|
||||
|
||||
async def get_human_readable_context(self, session_id, page, page_size):
|
||||
if session_id not in self.session_memory:
|
||||
raise Exception("会话 ID 不存在")
|
||||
contexts = []
|
||||
temp_contexts = []
|
||||
for record in self.session_memory[session_id]:
|
||||
if record["role"] == "user":
|
||||
temp_contexts.append(f"User: {record['content']}")
|
||||
elif record["role"] == "assistant":
|
||||
temp_contexts.append(f"Assistant: {record['content']}")
|
||||
contexts.insert(0, temp_contexts)
|
||||
temp_contexts = []
|
||||
|
||||
# 展平 contexts 列表
|
||||
contexts = [item for sublist in contexts for item in sublist]
|
||||
|
||||
# 计算分页
|
||||
paged_contexts = contexts[(page - 1) * page_size : page * page_size]
|
||||
total_pages = len(contexts) // page_size
|
||||
if len(contexts) % page_size != 0:
|
||||
total_pages += 1
|
||||
|
||||
return paged_contexts, total_pages
|
||||
246
astrbot/core/provider/sources/openai_source.py
Normal file
246
astrbot/core/provider/sources/openai_source.py
Normal file
@@ -0,0 +1,246 @@
|
||||
import base64
|
||||
import json
|
||||
|
||||
from openai import AsyncOpenAI, NOT_GIVEN
|
||||
from openai.types.chat.chat_completion import ChatCompletion
|
||||
from openai._exceptions import NotFoundError
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot.api.provider import Provider, Personality
|
||||
from astrbot import logger
|
||||
from astrbot.core.provider.func_tool_manager import FuncCall
|
||||
from typing import List
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
|
||||
@register_provider_adapter("openai_chat_completion", "OpenAI API Chat Completion 提供商适配器")
|
||||
class ProviderOpenAIOfficial(Provider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history = True,
|
||||
default_persona: Personality = None
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings, persistant_history, db_helper, default_persona)
|
||||
self.chosen_api_key = None
|
||||
self.api_keys: List = provider_config.get("key", [])
|
||||
self.chosen_api_key = self.api_keys[0] if len(self.api_keys) > 0 else None
|
||||
|
||||
self.client = AsyncOpenAI(
|
||||
api_key=self.chosen_api_key,
|
||||
base_url=provider_config.get("api_base", None),
|
||||
timeout=provider_config.get("timeout", NOT_GIVEN),
|
||||
)
|
||||
self.set_model(provider_config['model_config']['model'])
|
||||
|
||||
async def get_human_readable_context(self, session_id, page, page_size):
|
||||
if session_id not in self.session_memory:
|
||||
raise Exception("会话 ID 不存在")
|
||||
contexts = []
|
||||
temp_contexts = []
|
||||
for record in self.session_memory[session_id]:
|
||||
if record['role'] == "user":
|
||||
temp_contexts.append(f"User: {record['content']}")
|
||||
elif record['role'] == "assistant":
|
||||
temp_contexts.append(f"Assistant: {record['content']}")
|
||||
contexts.insert(0, temp_contexts)
|
||||
temp_contexts = []
|
||||
|
||||
# 展平 contexts 列表
|
||||
contexts = [item for sublist in contexts for item in sublist]
|
||||
|
||||
# 计算分页
|
||||
paged_contexts = contexts[(page-1)*page_size:page*page_size]
|
||||
total_pages = len(contexts) // page_size
|
||||
if len(contexts) % page_size != 0:
|
||||
total_pages += 1
|
||||
|
||||
return paged_contexts, total_pages
|
||||
|
||||
async def get_models(self):
|
||||
try:
|
||||
models_str = []
|
||||
models = await self.client.models.list()
|
||||
models = models.data
|
||||
for model in models:
|
||||
models_str.append(model.id)
|
||||
return models_str
|
||||
except NotFoundError as e:
|
||||
raise Exception(f"获取模型列表失败:{e}")
|
||||
|
||||
async def pop_record(self, session_id: str, pop_system_prompt: bool = False):
|
||||
'''
|
||||
弹出第一条记录
|
||||
'''
|
||||
if session_id not in self.session_memory:
|
||||
raise Exception("会话 ID 不存在")
|
||||
|
||||
if len(self.session_memory[session_id]) == 0:
|
||||
return None
|
||||
|
||||
for i in range(len(self.session_memory[session_id])):
|
||||
# 检查是否是 system prompt
|
||||
if not pop_system_prompt and self.session_memory[session_id][i]['user']['role'] == "system":
|
||||
# 如果只有一个 system prompt,才不删掉
|
||||
f = False
|
||||
for j in range(i+1, len(self.session_memory[session_id])):
|
||||
if self.session_memory[session_id][j]['user']['role'] == "system":
|
||||
f = True
|
||||
break
|
||||
if not f:
|
||||
continue
|
||||
record = self.session_memory[session_id].pop(i)
|
||||
break
|
||||
|
||||
return record
|
||||
|
||||
async def _query(self, payloads: dict, tools: FuncCall) -> LLMResponse:
|
||||
if tools:
|
||||
tool_list = tools.get_func_desc_openai_style()
|
||||
if tool_list:
|
||||
payloads['tools'] = tool_list
|
||||
|
||||
completion = await self.client.chat.completions.create(
|
||||
**payloads,
|
||||
stream=False
|
||||
)
|
||||
|
||||
assert isinstance(completion, ChatCompletion)
|
||||
logger.debug(f"completion: {completion}")
|
||||
|
||||
if len(completion.choices) == 0:
|
||||
raise Exception("API 返回的 completion 为空。")
|
||||
choice = completion.choices[0]
|
||||
|
||||
if choice.message.content:
|
||||
# text completion
|
||||
completion_text = str(choice.message.content).strip()
|
||||
return LLMResponse("assistant", completion_text)
|
||||
elif choice.message.tool_calls:
|
||||
# tools call (function calling)
|
||||
args_ls = []
|
||||
func_name_ls = []
|
||||
for tool_call in choice.message.tool_calls:
|
||||
for tool in tools.func_list:
|
||||
if tool.name == tool_call.function.name:
|
||||
args = json.loads(tool_call.function.arguments)
|
||||
args_ls.append(args)
|
||||
func_name_ls.append(tool_call.function.name)
|
||||
return LLMResponse(role="tool", tools_call_args=args_ls, tools_call_name=func_name_ls)
|
||||
else:
|
||||
raise Exception("Internal Error")
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str,
|
||||
image_urls: List[str]=None,
|
||||
func_tool: FuncCall=None,
|
||||
contexts=None,
|
||||
system_prompt=None,
|
||||
**kwargs
|
||||
) -> LLMResponse:
|
||||
new_record = await self.assemble_context(prompt, image_urls)
|
||||
context_query = []
|
||||
if not contexts:
|
||||
context_query = [*self.session_memory[session_id], new_record]
|
||||
else:
|
||||
context_query = [*contexts, new_record]
|
||||
if system_prompt:
|
||||
context_query.insert(0, {"role": "system", "content": system_prompt})
|
||||
|
||||
for part in context_query:
|
||||
if '_no_save' in part:
|
||||
del part['_no_save']
|
||||
|
||||
payloads = {
|
||||
"messages": context_query,
|
||||
**self.provider_config.get("model_config", {})
|
||||
}
|
||||
|
||||
try:
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
await self.save_history(contexts, new_record, session_id, llm_response)
|
||||
return llm_response
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt = 10
|
||||
while retry_cnt > 0:
|
||||
logger.warning(f"请求失败:{e}。上下文长度超过限制。尝试弹出最早的记录然后重试。")
|
||||
try:
|
||||
self.pop_record(session_id)
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
break
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt -= 1
|
||||
else:
|
||||
raise e
|
||||
else:
|
||||
raise e
|
||||
|
||||
|
||||
async def save_history(self, contexts: List, new_record: dict, session_id: str, llm_response: LLMResponse):
|
||||
if llm_response.role == "assistant" and session_id:
|
||||
# 文本回复
|
||||
if not contexts:
|
||||
# 添加用户 record
|
||||
self.session_memory[session_id].append(new_record)
|
||||
# 添加 assistant record
|
||||
self.session_memory[session_id].append({
|
||||
"role": "assistant",
|
||||
"content": llm_response.completion_text
|
||||
})
|
||||
else:
|
||||
contexts_to_save = list(filter(lambda item: '_no_save' not in item, contexts))
|
||||
self.session_memory[session_id] = [*contexts_to_save, new_record, {
|
||||
"role": "assistant",
|
||||
"content": llm_response.completion_text
|
||||
}]
|
||||
self.db_helper.update_llm_history(session_id, json.dumps(self.session_memory[session_id]), self.provider_config['type'])
|
||||
|
||||
async def forget(self, session_id: str) -> bool:
|
||||
self.session_memory[session_id] = []
|
||||
return True
|
||||
|
||||
def get_current_key(self) -> str:
|
||||
return self.client.api_key
|
||||
|
||||
def get_keys(self) -> List[str]:
|
||||
return self.api_keys
|
||||
|
||||
def set_key(self, key):
|
||||
self.client.api_key = key
|
||||
|
||||
async def assemble_context(self, text: str, image_urls: List[str] = None):
|
||||
'''
|
||||
组装上下文。
|
||||
'''
|
||||
if image_urls:
|
||||
user_content = {"role": "user","content": [{"type": "text", "text": text}]}
|
||||
for image_url in image_urls:
|
||||
if image_url.startswith("http"):
|
||||
image_path = await download_image_by_url(image_url)
|
||||
image_data = await self.encode_image_bs64(image_path)
|
||||
else:
|
||||
if image_url.startswith("file:///"):
|
||||
image_url = image_url.replace("file:///", "")
|
||||
image_data = await self.encode_image_bs64(image_url)
|
||||
user_content["content"].append({"type": "image_url", "image_url": {"url": image_data}})
|
||||
return user_content
|
||||
else:
|
||||
return {"role": "user","content": text}
|
||||
|
||||
async def encode_image_bs64(self, image_url: str) -> str:
|
||||
'''
|
||||
将图片转换为 base64
|
||||
'''
|
||||
if image_url.startswith("base64://"):
|
||||
return image_url.replace("base64://", "data:image/jpeg;base64,")
|
||||
with open(image_url, "rb") as f:
|
||||
image_bs64 = base64.b64encode(f.read()).decode('utf-8')
|
||||
return "data:image/jpeg;base64," + image_bs64
|
||||
return ''
|
||||
40
astrbot/core/provider/sources/openai_tts_api_source.py
Normal file
40
astrbot/core/provider/sources/openai_tts_api_source.py
Normal file
@@ -0,0 +1,40 @@
|
||||
import uuid
|
||||
import os
|
||||
from openai import AsyncOpenAI, NOT_GIVEN
|
||||
from ..provider import TTSProvider
|
||||
from ..entites import ProviderType
|
||||
from ..register import register_provider_adapter
|
||||
|
||||
|
||||
@register_provider_adapter("openai_tts_api", "OpenAI TTS API", provider_type=ProviderType.TEXT_TO_SPEECH)
|
||||
class ProviderOpenAITTSAPI(TTSProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
self.chosen_api_key = provider_config.get("api_key", "")
|
||||
self.voice = provider_config.get("voice", "alloy")
|
||||
|
||||
self.client = AsyncOpenAI(
|
||||
api_key=self.chosen_api_key,
|
||||
base_url=provider_config.get("api_base", None),
|
||||
timeout=provider_config.get("timeout", NOT_GIVEN),
|
||||
)
|
||||
|
||||
self.set_model(provider_config.get("model", None))
|
||||
|
||||
|
||||
async def get_audio(self, text: str) -> str:
|
||||
path = f'data/temp/openai_tts_api_{uuid.uuid4()}.wav'
|
||||
async with self.client.audio.speech.with_streaming_response.create(
|
||||
model=self.model_name,
|
||||
voice=self.voice,
|
||||
response_format='wav',
|
||||
input=text
|
||||
) as response:
|
||||
with open(path, 'wb') as f:
|
||||
async for chunk in response.iter_bytes(chunk_size=1024):
|
||||
f.write(chunk)
|
||||
return path
|
||||
74
astrbot/core/provider/sources/whisper_api_source.py
Normal file
74
astrbot/core/provider/sources/whisper_api_source.py
Normal file
@@ -0,0 +1,74 @@
|
||||
import uuid
|
||||
import os
|
||||
from openai import AsyncOpenAI, NOT_GIVEN
|
||||
from ..provider import STTProvider
|
||||
from ..entites import ProviderType
|
||||
from astrbot.core.utils.io import download_file
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.tencent_record_helper import tencent_silk_to_wav
|
||||
|
||||
@register_provider_adapter("openai_whisper_api", "OpenAI Whisper API", provider_type=ProviderType.SPEECH_TO_TEXT)
|
||||
class ProviderOpenAIWhisperAPI(STTProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
self.chosen_api_key = provider_config.get("api_key", "")
|
||||
|
||||
self.client = AsyncOpenAI(
|
||||
api_key=self.chosen_api_key,
|
||||
base_url=provider_config.get("api_base", None),
|
||||
timeout=provider_config.get("timeout", NOT_GIVEN),
|
||||
)
|
||||
|
||||
self.set_model(provider_config.get("model", None))
|
||||
|
||||
async def _convert_audio(self, path: str) -> str:
|
||||
from pyffmpeg import FFmpeg
|
||||
filename = str(uuid.uuid4()) + '.mp3'
|
||||
ff = FFmpeg()
|
||||
output_path = ff.convert(path, os.path.join('data/temp', filename))
|
||||
return output_path
|
||||
|
||||
async def _is_silk_file(self, file_path):
|
||||
silk_header = b"SILK"
|
||||
with open(file_path, "rb") as f:
|
||||
file_header = f.read(8)
|
||||
|
||||
if silk_header in file_header:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
async def get_text(self, audio_url: str) -> str:
|
||||
'''only supports mp3, mp4, mpeg, m4a, wav, webm'''
|
||||
is_tencent = False
|
||||
|
||||
if audio_url.startswith("http"):
|
||||
if "multimedia.nt.qq.com.cn" in audio_url:
|
||||
is_tencent = True
|
||||
|
||||
name = str(uuid.uuid4())
|
||||
path = os.path.join("data/temp", name)
|
||||
await download_file(audio_url, path)
|
||||
audio_url = path
|
||||
|
||||
if not os.path.exists(audio_url):
|
||||
raise FileNotFoundError(f"文件不存在: {audio_url}")
|
||||
|
||||
if audio_url.endswith(".amr") or audio_url.endswith(".silk") or is_tencent:
|
||||
is_silk = await self._is_silk_file(audio_url)
|
||||
if is_silk:
|
||||
logger.info("Converting silk file to wav ...")
|
||||
output_path = os.path.join('data/temp', str(uuid.uuid4()) + '.wav')
|
||||
await tencent_silk_to_wav(audio_url, output_path)
|
||||
audio_url = output_path
|
||||
|
||||
result = await self.client.audio.transcriptions.create(
|
||||
model=self.model_name,
|
||||
file=open(audio_url, "rb"),
|
||||
)
|
||||
return result.text
|
||||
72
astrbot/core/provider/sources/whisper_selfhosted_source.py
Normal file
72
astrbot/core/provider/sources/whisper_selfhosted_source.py
Normal file
@@ -0,0 +1,72 @@
|
||||
import uuid
|
||||
import os
|
||||
import asyncio
|
||||
import whisper
|
||||
from ..provider import STTProvider
|
||||
from ..entites import ProviderType
|
||||
from astrbot.core.utils.io import download_file
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.tencent_record_helper import tencent_silk_to_wav
|
||||
|
||||
@register_provider_adapter("openai_whisper_selfhost", "OpenAI Whisper 模型部署", provider_type=ProviderType.SPEECH_TO_TEXT)
|
||||
class ProviderOpenAIWhisperSelfHost(STTProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
self.set_model(provider_config.get("model", None))
|
||||
self.model = None
|
||||
|
||||
async def initialize(self):
|
||||
loop = asyncio.get_event_loop()
|
||||
logger.info("下载或者加载 Whisper 模型中,这可能需要一些时间 ...")
|
||||
self.model = await loop.run_in_executor(None, whisper.load_model, self.model_name)
|
||||
logger.info("Whisper 模型加载完成。")
|
||||
|
||||
async def _convert_audio(self, path: str) -> str:
|
||||
from pyffmpeg import FFmpeg
|
||||
filename = str(uuid.uuid4()) + '.mp3'
|
||||
ff = FFmpeg()
|
||||
output_path = ff.convert(path, os.path.join('data/temp', filename))
|
||||
return output_path
|
||||
|
||||
async def _is_silk_file(self, file_path):
|
||||
silk_header = b"SILK"
|
||||
with open(file_path, "rb") as f:
|
||||
file_header = f.read(8)
|
||||
|
||||
if silk_header in file_header:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
async def get_text(self, audio_url: str) -> str:
|
||||
loop = asyncio.get_event_loop()
|
||||
|
||||
is_tencent = False
|
||||
|
||||
if audio_url.startswith("http"):
|
||||
if "multimedia.nt.qq.com.cn" in audio_url:
|
||||
is_tencent = True
|
||||
|
||||
name = str(uuid.uuid4())
|
||||
path = os.path.join("data/temp", name)
|
||||
await download_file(audio_url, path)
|
||||
audio_url = path
|
||||
|
||||
if not os.path.exists(audio_url):
|
||||
raise FileNotFoundError(f"文件不存在: {audio_url}")
|
||||
|
||||
if audio_url.endswith(".amr") or audio_url.endswith(".silk") or is_tencent:
|
||||
is_silk = await self._is_silk_file(audio_url)
|
||||
if is_silk:
|
||||
logger.info("Converting silk file to wav ...")
|
||||
output_path = os.path.join('data/temp', str(uuid.uuid4()) + '.wav')
|
||||
await tencent_silk_to_wav(audio_url, output_path)
|
||||
audio_url = output_path
|
||||
|
||||
result = await loop.run_in_executor(None, self.model.transcribe, audio_url)
|
||||
return result['text']
|
||||
82
astrbot/core/provider/sources/zhipu_source.py
Normal file
82
astrbot/core/provider/sources/zhipu_source.py
Normal file
@@ -0,0 +1,82 @@
|
||||
import traceback
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot import logger
|
||||
from astrbot.core.provider.func_tool_manager import FuncCall
|
||||
from typing import List
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
from .openai_source import ProviderOpenAIOfficial
|
||||
|
||||
@register_provider_adapter("zhipu_chat_completion", "智浦 Chat Completion 提供商适配器")
|
||||
class ProviderZhipu(ProviderOpenAIOfficial):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history = True,
|
||||
default_persona = None
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings, db_helper, persistant_history, default_persona)
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str,
|
||||
image_urls: List[str]=None,
|
||||
func_tool: FuncCall=None,
|
||||
contexts=None,
|
||||
system_prompt=None,
|
||||
**kwargs
|
||||
) -> LLMResponse:
|
||||
new_record = await self.assemble_context(prompt, image_urls)
|
||||
context_query = []
|
||||
|
||||
if not contexts:
|
||||
context_query = [*self.session_memory[session_id], new_record]
|
||||
else:
|
||||
context_query = [*contexts, new_record]
|
||||
|
||||
model_cfgs: dict = self.provider_config.get("model_config", {})
|
||||
# glm-4v-flash 只支持一张图片
|
||||
model: str = model_cfgs.get("model", "")
|
||||
if model.lower() == 'glm-4v-flash' and image_urls and len(context_query) > 1:
|
||||
logger.debug("glm-4v-flash 只支持一张图片,将只保留最后一张图片")
|
||||
logger.debug(context_query)
|
||||
new_context_query_ = []
|
||||
for i in range(0, len(context_query) - 1, 2):
|
||||
if isinstance(context_query[i].get("content", ""), list):
|
||||
continue
|
||||
new_context_query_.append(context_query[i])
|
||||
new_context_query_.append(context_query[i+1])
|
||||
new_context_query_.append(context_query[-1]) # 保留最后一条记录
|
||||
context_query = new_context_query_
|
||||
logger.debug(context_query)
|
||||
|
||||
if system_prompt:
|
||||
context_query.insert(0, {"role": "system", "content": system_prompt})
|
||||
|
||||
payloads = {
|
||||
"messages": context_query,
|
||||
**model_cfgs
|
||||
}
|
||||
try:
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
await self.save_history(contexts, new_record, session_id, llm_response)
|
||||
return llm_response
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt = 10
|
||||
while retry_cnt > 0:
|
||||
logger.warning(f"请求失败:{e}。上下文长度超过限制。尝试弹出最早的记录然后重试。")
|
||||
try:
|
||||
self.pop_record(session_id)
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
break
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt -= 1
|
||||
else:
|
||||
raise e
|
||||
else:
|
||||
raise e
|
||||
25
astrbot/core/rag/embedding/openai_source.py
Normal file
25
astrbot/core/rag/embedding/openai_source.py
Normal file
@@ -0,0 +1,25 @@
|
||||
from typing import List
|
||||
from openai import AsyncOpenAI
|
||||
|
||||
class SimpleOpenAIEmbedding():
|
||||
def __init__(
|
||||
self,
|
||||
model,
|
||||
api_key,
|
||||
api_base=None,
|
||||
) -> None:
|
||||
self.client = AsyncOpenAI(
|
||||
api_key=api_key,
|
||||
base_url=api_base
|
||||
)
|
||||
self.model = model
|
||||
|
||||
async def get_embedding(self, text) -> List[float]:
|
||||
'''
|
||||
获取文本的嵌入
|
||||
'''
|
||||
embedding = await self.client.embeddings.create(
|
||||
input=text,
|
||||
model=self.model
|
||||
)
|
||||
return embedding.data[0].embedding
|
||||
92
astrbot/core/rag/knowledge_db_mgr.py
Normal file
92
astrbot/core/rag/knowledge_db_mgr.py
Normal file
@@ -0,0 +1,92 @@
|
||||
import os
|
||||
from typing import List, Dict
|
||||
from astrbot.core import logger
|
||||
from .store import Store
|
||||
from astrbot.core.config import AstrBotConfig
|
||||
|
||||
class KnowledgeDBManager():
|
||||
def __init__(self, astrbot_config: AstrBotConfig) -> None:
|
||||
self.db_path = "data/knowledge_db/"
|
||||
self.config = astrbot_config.get("knowledge_db", {})
|
||||
self.astrbot_config = astrbot_config
|
||||
if not os.path.exists(self.db_path):
|
||||
os.makedirs(self.db_path)
|
||||
self.store_insts: Dict[str, Store] = {}
|
||||
for name, cfg in self.config.items():
|
||||
if cfg["strategy"] == "embedding":
|
||||
logger.info(f"加载 Chroma Vector Store:{name}")
|
||||
try:
|
||||
from .store.chroma_db import ChromaVectorStore
|
||||
except ImportError as ie:
|
||||
logger.error(f"{ie} 可能未安装 chromadb 库。")
|
||||
continue
|
||||
self.store_insts[name] = ChromaVectorStore(name, cfg["embedding_config"])
|
||||
else:
|
||||
logger.error(f"不支持的策略:{cfg['strategy']}")
|
||||
|
||||
|
||||
async def list_knowledge_db(self) -> List[str]:
|
||||
return [f for f in os.listdir(self.db_path) if os.path.isfile(os.path.join(self.db_path, f))]
|
||||
|
||||
|
||||
async def create_knowledge_db(self, name: str, config: Dict):
|
||||
'''
|
||||
config 格式:
|
||||
```
|
||||
{
|
||||
"strategy": "embedding", # 目前只支持 embedding
|
||||
"chunk_method": {
|
||||
"strategy": "fixed",
|
||||
"chunk_size": 100,
|
||||
"overlap_size": 10
|
||||
},
|
||||
"embedding_config": {
|
||||
"strategy": "openai",
|
||||
"base_url": "",
|
||||
"model": "",
|
||||
"api_key": ""
|
||||
}
|
||||
}
|
||||
```
|
||||
'''
|
||||
if name in self.config:
|
||||
raise ValueError(f"知识库已存在:{name}")
|
||||
|
||||
self.config[name] = config
|
||||
self.astrbot_config["knowledge_db"] = self.config
|
||||
self.astrbot_config.save_config()
|
||||
|
||||
|
||||
async def insert_record(self, name: str, text: str):
|
||||
if name not in self.store_insts:
|
||||
raise ValueError(f"未找到知识库:{name}")
|
||||
|
||||
ret = []
|
||||
match self.config[name]["chunk_method"]['strategy']:
|
||||
case "fixed":
|
||||
chunk_size = self.config[name]["chunk_method"]["chunk_size"]
|
||||
chunk_overlap = self.config[name]["chunk_method"]["overlap_size"]
|
||||
ret = self._fixed_chunk(text, chunk_size, chunk_overlap)
|
||||
case _:
|
||||
pass
|
||||
|
||||
for chunk in ret:
|
||||
await self.store_insts[name].save(chunk)
|
||||
|
||||
|
||||
async def retrive_records(self, name: str, query: str, top_n: int = 3) -> List[str]:
|
||||
if name not in self.store_insts:
|
||||
raise ValueError(f"未找到知识库:{name}")
|
||||
|
||||
inst = self.store_insts[name]
|
||||
return await inst.query(query, top_n)
|
||||
|
||||
|
||||
def _fixed_chunk(self, text: str, chunk_size: int, chunk_overlap: int) -> List[str]:
|
||||
chunks = []
|
||||
start = 0
|
||||
while start < len(text):
|
||||
end = start + chunk_size
|
||||
chunks.append(text[start:end])
|
||||
start += chunk_size - chunk_overlap
|
||||
return chunks
|
||||
8
astrbot/core/rag/store/__init__.py
Normal file
8
astrbot/core/rag/store/__init__.py
Normal file
@@ -0,0 +1,8 @@
|
||||
from typing import List
|
||||
|
||||
class Store():
|
||||
async def save(self, text: str):
|
||||
pass
|
||||
|
||||
async def query(self, query: str, top_n: int = 3) -> List[str]:
|
||||
pass
|
||||
39
astrbot/core/rag/store/chroma_db.py
Normal file
39
astrbot/core/rag/store/chroma_db.py
Normal file
@@ -0,0 +1,39 @@
|
||||
import chromadb
|
||||
import uuid
|
||||
from typing import List, Dict
|
||||
from astrbot.api import logger
|
||||
from ..embedding.openai_source import SimpleOpenAIEmbedding
|
||||
from . import Store
|
||||
|
||||
class ChromaVectorStore(Store):
|
||||
def __init__(self, name: str, embedding_cfg: Dict) -> None:
|
||||
self.chroma_client = chromadb.PersistentClient(path='data/long_term_memory_chroma.db')
|
||||
self.collection = self.chroma_client.get_or_create_collection(name=name)
|
||||
self.embedding = None
|
||||
if embedding_cfg["strategy"] == "openai":
|
||||
self.embedding = SimpleOpenAIEmbedding(
|
||||
model=embedding_cfg["model"],
|
||||
api_key=embedding_cfg["api_key"],
|
||||
api_base=embedding_cfg.get("base_url", None)
|
||||
)
|
||||
|
||||
async def save(self, text: str, metadata: Dict = None):
|
||||
logger.debug(f"Saving text: {text}")
|
||||
embedding = await self.embedding.get_embedding(text)
|
||||
|
||||
self.collection.upsert(
|
||||
documents=text,
|
||||
metadatas=metadata,
|
||||
ids=str(uuid.uuid4()),
|
||||
embeddings=embedding
|
||||
)
|
||||
|
||||
async def query(self, query: str, top_n=3, metadata_filter: Dict = None) -> List[str]:
|
||||
embedding = await self.embedding.get_embedding(query)
|
||||
|
||||
results = self.collection.query(
|
||||
query_embeddings=embedding,
|
||||
n_results=top_n,
|
||||
where=metadata_filter
|
||||
)
|
||||
return results['documents'][0]
|
||||
5
astrbot/core/star/README.md
Normal file
5
astrbot/core/star/README.md
Normal file
@@ -0,0 +1,5 @@
|
||||
# AstrBot Star
|
||||
|
||||
`AstrBot Star` 就是插件。
|
||||
|
||||
在 AstrBot v4.0 版本后,AstrBot 内部将插件命名为 `star`。插件的 handler 称作 `star_handler`。
|
||||
19
astrbot/core/star/__init__.py
Normal file
19
astrbot/core/star/__init__.py
Normal file
@@ -0,0 +1,19 @@
|
||||
from .star import StarMetadata
|
||||
from .star_manager import PluginManager
|
||||
from .context import Context
|
||||
from astrbot.core.provider import Provider
|
||||
from astrbot.core.utils.command_parser import CommandParserMixin
|
||||
from astrbot.core import html_renderer
|
||||
|
||||
class Star(CommandParserMixin):
|
||||
'''所有插件(Star)的父类,所有插件都应该继承于这个类'''
|
||||
def __init__(self, context: Context):
|
||||
self.context = context
|
||||
|
||||
async def text_to_image(self, text: str, return_url = True) -> str:
|
||||
'''将文本转换为图片'''
|
||||
return await html_renderer.render_t2i(text, return_url=return_url)
|
||||
|
||||
async def html_render(self, tmpl: str, data: dict, return_url = True) -> str:
|
||||
'''渲染 HTML'''
|
||||
return await html_renderer.render_custom_template(tmpl, data, return_url=return_url)
|
||||
82
astrbot/core/star/config.py
Normal file
82
astrbot/core/star/config.py
Normal file
@@ -0,0 +1,82 @@
|
||||
from typing import Union
|
||||
import os
|
||||
import json
|
||||
|
||||
def load_config(namespace: str) -> Union[dict, bool]:
|
||||
'''
|
||||
从配置文件中加载配置。
|
||||
namespace: str, 配置的唯一识别符,也就是配置文件的名字。
|
||||
返回值: 当配置文件存在时,返回 namespace 对应配置文件的内容dict,否则返回 False。
|
||||
'''
|
||||
path = f"data/config/{namespace}.json"
|
||||
if not os.path.exists(path):
|
||||
return False
|
||||
with open(path, "r", encoding="utf-8-sig") as f:
|
||||
ret = {}
|
||||
data = json.load(f)
|
||||
for k in data:
|
||||
ret[k] = data[k]["value"]
|
||||
return ret
|
||||
|
||||
def put_config(namespace: str, name: str, key: str, value, description: str):
|
||||
'''
|
||||
将配置项写入以namespace为名字的配置文件,如果key不存在于目标配置文件中。当前 value 仅支持 str, int, float, bool, list 类型(暂不支持 dict)。
|
||||
namespace: str, 配置的唯一识别符,也就是配置文件的名字。
|
||||
name: str, 配置项的显示名字。
|
||||
key: str, 配置项的键。
|
||||
value: str, int, float, bool, list, 配置项的值。
|
||||
description: str, 配置项的描述。
|
||||
注意:只有当 namespace 为插件名(info 函数中的 name)时,该配置才会显示到可视化面板上。
|
||||
注意:value一定要是该配置项对应类型的值,否则类型判断会乱。
|
||||
'''
|
||||
if namespace == "":
|
||||
raise ValueError("namespace 不能为空。")
|
||||
if namespace.startswith("internal_"):
|
||||
raise ValueError("namespace 不能以 internal_ 开头。")
|
||||
if not isinstance(key, str):
|
||||
raise ValueError("key 只支持 str 类型。")
|
||||
if not isinstance(value, (str, int, float, bool, list)):
|
||||
raise ValueError("value 只支持 str, int, float, bool, list 类型。")
|
||||
path = f"data/config/{namespace}.json"
|
||||
if not os.path.exists(path):
|
||||
with open(path, "w", encoding="utf-8-sig") as f:
|
||||
f.write("{}")
|
||||
with open(path, "r", encoding="utf-8-sig") as f:
|
||||
d = json.load(f)
|
||||
assert(isinstance(d, dict))
|
||||
if key not in d:
|
||||
d[key] = {
|
||||
"config_type": "item",
|
||||
"name": name,
|
||||
"description": description,
|
||||
"path": key,
|
||||
"value": value,
|
||||
"val_type": type(value).__name__
|
||||
}
|
||||
with open(path, "w", encoding="utf-8-sig") as f:
|
||||
json.dump(d, f, indent=2, ensure_ascii=False)
|
||||
f.flush()
|
||||
|
||||
def update_config(namespace: str, key: str, value):
|
||||
'''
|
||||
更新配置文件中的配置项。
|
||||
namespace: str, 配置的唯一识别符,也就是配置文件的名字。
|
||||
key: str, 配置项的键。
|
||||
value: str, int, float, bool, list, 配置项的值。
|
||||
'''
|
||||
path = f"data/config/{namespace}.json"
|
||||
if not os.path.exists(path):
|
||||
raise FileNotFoundError(f"配置文件 {namespace}.json 不存在。")
|
||||
with open(path, "r", encoding="utf-8-sig") as f:
|
||||
d = json.load(f)
|
||||
assert(isinstance(d, dict))
|
||||
if key not in d:
|
||||
raise KeyError(f"配置项 {key} 不存在。")
|
||||
d[key]["value"] = value
|
||||
with open(path, "w", encoding="utf-8-sig") as f:
|
||||
json.dump(d, f, indent=2, ensure_ascii=False)
|
||||
f.flush()
|
||||
|
||||
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user