Compare commits
204 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
611a902000 | ||
|
|
c1b3f9dd29 | ||
|
|
7c5a88a6a6 | ||
|
|
be9abfef58 | ||
|
|
b549c9377e | ||
|
|
a5b00dbf74 | ||
|
|
90e2e14cd7 | ||
|
|
14bb245424 | ||
|
|
b63a0f3a45 | ||
|
|
e1f8842d7f | ||
|
|
3dda5fb268 | ||
|
|
248e0c5240 | ||
|
|
0297a43de6 | ||
|
|
2b4f66e0cf | ||
|
|
e622af2cc3 | ||
|
|
f527b1b5a6 | ||
|
|
c15b13a107 | ||
|
|
bc06acdd25 | ||
|
|
5252870733 | ||
|
|
3cac6a47a5 | ||
|
|
49bba9bf98 | ||
|
|
f4d12e4e5e | ||
|
|
d305211a36 | ||
|
|
9ec44d6f97 | ||
|
|
175bb3ee01 | ||
|
|
036c78750f | ||
|
|
a18de9de7d | ||
|
|
59fbbd5987 | ||
|
|
7e89fbc907 | ||
|
|
0956f240b3 | ||
|
|
f9db97c6b0 | ||
|
|
a2443c4ac1 | ||
|
|
095bd95044 | ||
|
|
b569209647 | ||
|
|
9057cac2b9 | ||
|
|
f9a6c685df | ||
|
|
208eb4f454 | ||
|
|
b3cb9e6714 | ||
|
|
5f9233f9b7 | ||
|
|
16447ae597 | ||
|
|
103edd5260 | ||
|
|
928089bf0f | ||
|
|
e5bd74695a | ||
|
|
f796969465 | ||
|
|
10756175b7 | ||
|
|
5637a71486 | ||
|
|
bcebd0fb62 | ||
|
|
3817d3ca87 | ||
|
|
4dd714e814 | ||
|
|
61e8bb49ec | ||
|
|
103dcd3761 | ||
|
|
54ac135fc8 | ||
|
|
86582809fc | ||
|
|
974d648f19 | ||
|
|
a79afc9597 | ||
|
|
e4883241d9 | ||
|
|
babf223745 | ||
|
|
c7d91730b6 | ||
|
|
71246b65c9 | ||
|
|
50076b647e | ||
|
|
a1a788dce8 | ||
|
|
a611b4f346 | ||
|
|
7f6ed674b4 | ||
|
|
aa3cfd887a | ||
|
|
2649d46d8d | ||
|
|
e23ffe6f02 | ||
|
|
96f3c3729a | ||
|
|
11e9d47ce2 | ||
|
|
efbc8e4383 | ||
|
|
bc7404409f | ||
|
|
8677d70baf | ||
|
|
f39253f0e1 | ||
|
|
68c1957267 | ||
|
|
a275aa2e4d | ||
|
|
cadbac9948 | ||
|
|
82673e8ddd | ||
|
|
bee51024b3 | ||
|
|
3437cb73ec | ||
|
|
d01d1a8520 | ||
|
|
5aa842cf66 | ||
|
|
03282dee0f | ||
|
|
98e8ecb8e2 | ||
|
|
9451dc3fd4 | ||
|
|
e1d3759f55 | ||
|
|
0ec382c86b | ||
|
|
756087c9f1 | ||
|
|
3e7c47e873 | ||
|
|
e3ffdbc308 | ||
|
|
645cace4d6 | ||
|
|
0959d5986b | ||
|
|
89605c29a7 | ||
|
|
e527f31213 | ||
|
|
a0dbd99928 | ||
|
|
17d39c7a4a | ||
|
|
54edaebbd9 | ||
|
|
d587a6f64c | ||
|
|
2371c32be5 | ||
|
|
c9abb8352c | ||
|
|
8995e62e73 | ||
|
|
316147a8db | ||
|
|
1fdcfc7a30 | ||
|
|
8e2c633cd4 | ||
|
|
786b0e4a54 | ||
|
|
c38c1c3c35 | ||
|
|
7d856756f4 | ||
|
|
f0d1d365e0 | ||
|
|
8e2d666ff8 | ||
|
|
38d7be1d5f | ||
|
|
431e2fad72 | ||
|
|
b3b63be8fc | ||
|
|
071fc7d6ef | ||
|
|
2a37f7edac | ||
|
|
c656ad5e2c | ||
|
|
da14a89490 | ||
|
|
cf22eae467 | ||
|
|
b199bddb0b | ||
|
|
2188ea82de | ||
|
|
1fa13d0177 | ||
|
|
ed508af424 | ||
|
|
5df26864d5 | ||
|
|
837111b17e | ||
|
|
a6b363b433 | ||
|
|
2807e1e892 | ||
|
|
0a2abd8214 | ||
|
|
8beb7acdb1 | ||
|
|
466c80b94d | ||
|
|
36c0cfc9a9 | ||
|
|
35ba1b3345 | ||
|
|
d00821d1c7 | ||
|
|
6c1b3f242b | ||
|
|
9f9da1e0c9 | ||
|
|
14fb4b70bd | ||
|
|
b1049540a4 | ||
|
|
5e2909df33 | ||
|
|
c122dad21f | ||
|
|
48ae686602 | ||
|
|
bf2c3a1a81 | ||
|
|
96e7a93886 | ||
|
|
dba1ed1e19 | ||
|
|
a24514876b | ||
|
|
466a1c1c41 | ||
|
|
a2d5e9f40f | ||
|
|
1bbff1d161 | ||
|
|
0948bae99b | ||
|
|
850db41596 | ||
|
|
7bafc87e2b | ||
|
|
1a0de02a15 | ||
|
|
6d5d278624 | ||
|
|
3b4cc48fa0 | ||
|
|
c908461088 | ||
|
|
53d1398d30 | ||
|
|
782c0367d0 | ||
|
|
4678222e9b | ||
|
|
f71dc3e4be | ||
|
|
f6233893bd | ||
|
|
6427bcf130 | ||
|
|
8fa41b706c | ||
|
|
4706c4438d | ||
|
|
0c8ebc2b06 | ||
|
|
b3b5ebc2ca | ||
|
|
b8aa23ccc5 | ||
|
|
364843db29 | ||
|
|
aa56c8f7e6 | ||
|
|
8e9fd27058 | ||
|
|
b75908cb2a | ||
|
|
af6df49ce1 | ||
|
|
bd3bdb5769 | ||
|
|
98fe193b21 | ||
|
|
26cbc9e8b1 | ||
|
|
ebb8c43fd0 | ||
|
|
8c7344f1c4 | ||
|
|
5c32a17787 | ||
|
|
aff520e69a | ||
|
|
45e627c33c | ||
|
|
7a1b158f83 | ||
|
|
6374c5d49d | ||
|
|
fd460b19d4 | ||
|
|
dff7cc4ca5 | ||
|
|
d013320bec | ||
|
|
fc6dcfaf21 | ||
|
|
a001270bd2 | ||
|
|
9e67883fbd | ||
|
|
f1a448708c | ||
|
|
a4bfa96502 | ||
|
|
595b83a256 | ||
|
|
8d34f77321 | ||
|
|
67095f97b1 | ||
|
|
50740c94ab | ||
|
|
4db4cfeda2 | ||
|
|
ad13cef89c | ||
|
|
855fc6fcd1 | ||
|
|
8f12244e51 | ||
|
|
fe0213465c | ||
|
|
f984047004 | ||
|
|
19e9e2d090 | ||
|
|
7fe3b97d00 | ||
|
|
9cd243da47 | ||
|
|
e43208c2e9 | ||
|
|
dc016fc22f | ||
|
|
c6f037cae2 | ||
|
|
f049830e28 | ||
|
|
dd1995ae0b | ||
|
|
7155b4f0ac | ||
|
|
0021cfc4bc |
@@ -1,3 +0,0 @@
|
||||
comment:
|
||||
layout: "condensed_header, condensed_files, condensed_footer"
|
||||
hide_project_coverage: TRUE
|
||||
@@ -1,5 +0,0 @@
|
||||
[run]
|
||||
omit =
|
||||
*/site-packages/*
|
||||
*/dist-packages/*
|
||||
your_package_name/tests/*
|
||||
39
.github/ISSUE_TEMPLATE/PLUGIN_PUBLISH.yml
vendored
Normal file
39
.github/ISSUE_TEMPLATE/PLUGIN_PUBLISH.yml
vendored
Normal file
@@ -0,0 +1,39 @@
|
||||
name: '🥳 发布插件'
|
||||
title: "[Plugin] 插件名"
|
||||
description: 提交插件到插件市场
|
||||
labels: [ "plugin-publish" ]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
欢迎发布插件到插件市场!
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 插件仓库
|
||||
description: 插件的 GitHub 仓库链接
|
||||
placeholder: >
|
||||
如 https://github.com/Soulter/astrbot-github-cards
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 描述
|
||||
value: |
|
||||
插件名:
|
||||
插件作者:
|
||||
插件简介:
|
||||
标签: (可选)
|
||||
社交链接: (可选, 将会在插件市场作者名称上作为可点击的链接)
|
||||
description: 必填。请以列表的字段按顺序将插件名、插件作者、插件简介放在这里。
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Code of Conduct
|
||||
options:
|
||||
- label: >
|
||||
我已阅读并同意遵守该项目的 [行为准则](https://docs.github.com/zh/site-policy/github-terms/github-community-code-of-conduct)。
|
||||
required: true
|
||||
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: "❤️"
|
||||
10
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
10
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -28,7 +28,7 @@ body:
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: AstrBot 版本与部署方式
|
||||
label: AstrBot 版本、部署方式(如 Windows Docker Desktop 部署)、使用的提供商、使用的消息平台适配器
|
||||
description: >
|
||||
请提供您的 AstrBot 版本和部署方式。
|
||||
placeholder: >
|
||||
@@ -53,9 +53,9 @@ body:
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: 额外信息
|
||||
label: 报错日志
|
||||
description: >
|
||||
任何额外信息,如报错日志、截图等。
|
||||
如报错日志、截图等。请提供完整的 Debug 级别的日志,不要介意它很长!
|
||||
placeholder: >
|
||||
请提供完整的报错日志或截图。
|
||||
validations:
|
||||
@@ -65,7 +65,7 @@ body:
|
||||
attributes:
|
||||
label: 你愿意提交 PR 吗?
|
||||
description: >
|
||||
这绝对不是必需的,但我们很乐意在贡献过程中为您提供指导特别是如果你已经很好地理解了如何实现修复。
|
||||
这不是必需的,但我们很乐意在贡献过程中为您提供指导特别是如果你已经很好地理解了如何实现修复。
|
||||
options:
|
||||
- label: 是的,我愿意提交 PR!
|
||||
|
||||
@@ -79,4 +79,4 @@ body:
|
||||
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: "感谢您填写我们的表单!"
|
||||
value: "感谢您填写我们的表单!"
|
||||
|
||||
4
.gitignore
vendored
4
.gitignore
vendored
@@ -17,10 +17,12 @@ addons/plugins
|
||||
|
||||
tests/astrbot_plugin_openai
|
||||
chroma
|
||||
node_modules/
|
||||
dashboard/node_modules/
|
||||
dashboard/dist/
|
||||
.DS_Store
|
||||
package-lock.json
|
||||
package.json
|
||||
venv/*
|
||||
packages/python_interpreter/workplace
|
||||
.venv/*
|
||||
.conda/
|
||||
|
||||
13
.pre-commit-config.yaml
Normal file
13
.pre-commit-config.yaml
Normal file
@@ -0,0 +1,13 @@
|
||||
default_install_hook_types: [pre-commit, prepare-commit-msg]
|
||||
ci:
|
||||
autofix_commit_msg: ":balloon: auto fixes by pre-commit hooks"
|
||||
autofix_prs: true
|
||||
autoupdate_branch: master
|
||||
autoupdate_schedule: weekly
|
||||
autoupdate_commit_msg: ":balloon: pre-commit autoupdate"
|
||||
repos:
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
rev: v0.9.9
|
||||
hooks:
|
||||
- id: ruff
|
||||
- id: ruff-format
|
||||
4
LICENSE
4
LICENSE
@@ -629,8 +629,8 @@ to attach them to the start of each source file to most effectively
|
||||
state the exclusion of warranty; and each file should have at least
|
||||
the "copyright" line and a pointer to where the full notice is found.
|
||||
|
||||
<one line to give the program's name and a brief idea of what it does.>
|
||||
Copyright (C) <year> <name of author>
|
||||
AstrBot is a llm-powered chatbot and develop framework.
|
||||
Copyright (C) 2022-2099 Soulter
|
||||
|
||||
This program is free software: you can redistribute it and/or modify
|
||||
it under the terms of the GNU Affero General Public License as published
|
||||
|
||||
49
README.md
49
README.md
@@ -13,11 +13,13 @@ _✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨_
|
||||
[](https://github.com/Soulter/AstrBot/releases/latest)
|
||||
<img src="https://img.shields.io/badge/python-3.10+-blue.svg" alt="python">
|
||||
<a href="https://hub.docker.com/r/soulter/astrbot"><img alt="Docker pull" src="https://img.shields.io/docker/pulls/soulter/astrbot.svg"/></a>
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/QQ群-630166526-purple">
|
||||
<a href="https://qm.qq.com/cgi-bin/qm/qr?k=wtbaNx7EioxeaqS9z7RQWVXPIxg2zYr7&jump_from=webapi&authKey=vlqnv/AV2DbJEvGIcxdlNSpfxVy+8vVqijgreRdnVKOaydpc+YSw4MctmEbr0k5"><img alt="Static Badge" src="https://img.shields.io/badge/QQ群-630166526-purple"></a>
|
||||
[](https://wakatime.com/badge/user/915e5316-99c6-4563-a483-ef186cf000c9/project/018e705a-a1a7-409a-a849-3013485e6c8e)
|
||||

|
||||
[](https://codecov.io/gh/Soulter/AstrBot)
|
||||
|
||||
<a href="https://github.com/Soulter/AstrBot/blob/master/README_en.md">English</a> |
|
||||
<a href="https://github.com/Soulter/AstrBot/blob/master/README_ja.md">日本語</a> |
|
||||
<a href="https://astrbot.app/">查看文档</a> |
|
||||
<a href="https://github.com/Soulter/AstrBot/issues">问题提交</a>
|
||||
</div>
|
||||
@@ -78,23 +80,42 @@ AstrBot 是一个松耦合、异步、支持多消息平台部署、具有易用
|
||||
| WhatsApp | 🚧 | 计划内 | - |
|
||||
| 小爱音响 | 🚧 | 计划内 | - |
|
||||
|
||||
# 🦌 接下来的路线图
|
||||
|
||||
> [!TIP]
|
||||
> 欢迎在 Issue 提出更多建议 <3
|
||||
|
||||
- [ ] 完善并保证目前所有平台适配器的功能一致性
|
||||
- [ ] 优化插件接口
|
||||
- [ ] 默认支持更多 TTS 服务,如 GPT-Sovits
|
||||
- [ ] 完善“聊天增强”部分,支持持久化记忆
|
||||
- [ ] 规划 i18n
|
||||
## ⚡ 提供商支持情况
|
||||
|
||||
| 名称 | 支持性 | 类型 | 备注 |
|
||||
| -------- | ------- | ------- | ------- |
|
||||
| OpenAI API | ✔ | 文本生成 | 同时也支持 DeepSeek、Google Gemini、GLM(智谱)、Moonshot(月之暗面)、阿里云百炼、硅基流动、xAI 等所有兼容 OpenAI API 的服务 |
|
||||
| Claude API | ✔ | 文本生成 | |
|
||||
| Google Gemini API | ✔ | 文本生成 | |
|
||||
| Dify | ✔ | LLMOps | |
|
||||
| DashScope(阿里云百炼应用) | ✔ | LLMOps | |
|
||||
| Ollama | ✔ | 模型加载器 | 本地部署 DeepSeek、Llama 等开源语言模型 |
|
||||
| LM Studio | ✔ | 模型加载器 | 本地部署 DeepSeek、Llama 等开源语言模型 |
|
||||
| LLMTuner | ✔ | 模型加载器 | 本地加载 lora 等微调模型 |
|
||||
| OneAPI | ✔ | LLM 分发系统 | |
|
||||
| Whisper | ✔ | 语音转文本 | 支持 API、本地部署 |
|
||||
| SenseVoice | ✔ | 语音转文本 | 本地部署 |
|
||||
| OpenAI TTS API | ✔ | 文本转语音 | |
|
||||
| Fishaudio | ✔ | 文本转语音 | GPT-Sovits 作者参与的项目 |
|
||||
| Edge-TTS | ✔ | 文本转语音 | Edge 浏览器的免费 TTS |
|
||||
|
||||
## ❤️ 贡献
|
||||
|
||||
欢迎任何 Issues/Pull Requests!只需要将你的更改提交到此项目 :)
|
||||
|
||||
对于新功能的添加,请先通过 Issue 讨论。
|
||||
### 如何贡献
|
||||
|
||||
你可以通过查看问题或帮助审核 PR(拉取请求)来贡献。任何问题或 PR 都欢迎参与,以促进社区贡献。当然,这些只是建议,你可以以任何方式进行贡献。对于新功能的添加,请先通过 Issue 讨论。
|
||||
|
||||
### 开发环境
|
||||
|
||||
AstrBot 使用 `ruff` 进行代码格式化和检查。
|
||||
|
||||
```bash
|
||||
git clone https://github.com/Soulter/AstrBot
|
||||
pip install pre-commit
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
## 🌟 支持
|
||||
|
||||
@@ -147,10 +168,6 @@ _✨ 内置 Web Chat,在线与机器人交互 ✨_
|
||||
|
||||
</div>
|
||||
|
||||
## Sponsors
|
||||
|
||||
[<img src="https://api.gitsponsors.com/api/badge/img?id=575865240" height="20">](https://api.gitsponsors.com/api/badge/link?p=XEpbdGxlitw/RbcwiTX93UMzNK/jgDYC8NiSzamIPMoKvG2lBFmyXhSS/b0hFoWlBBMX2L5X5CxTDsUdyvcIEHTOfnkXz47UNOZvMwyt5CzbYpq0SEzsSV1OJF1cCo90qC/ZyYKYOWedal3MhZ3ikw==)
|
||||
|
||||
## Disclaimer
|
||||
|
||||
1. The project is protected under the `AGPL-v3` opensource license.
|
||||
|
||||
182
README_en.md
Normal file
182
README_en.md
Normal file
@@ -0,0 +1,182 @@
|
||||
<p align="center">
|
||||
|
||||

|
||||
|
||||
</p>
|
||||
|
||||
<div align="center">
|
||||
|
||||
_✨ Easy-to-use Multi-platform LLM Chatbot & Development Framework ✨_
|
||||
|
||||
<a href="https://trendshift.io/repositories/12875" target="_blank"><img src="https://trendshift.io/api/badge/repositories/12875" alt="Soulter%2FAstrBot | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
|
||||
|
||||
[](https://github.com/Soulter/AstrBot/releases/latest)
|
||||
<img src="https://img.shields.io/badge/python-3.10+-blue.svg" alt="python">
|
||||
<a href="https://hub.docker.com/r/soulter/astrbot"><img alt="Docker pull" src="https://img.shields.io/docker/pulls/soulter/astrbot.svg"/></a>
|
||||
<a href="https://qm.qq.com/cgi-bin/qm/qr?k=wtbaNx7EioxeaqS9z7RQWVXPIxg2zYr7&jump_from=webapi&authKey=vlqnv/AV2DbJEvGIcxdlNSpfxVy+8vVqijgreRdnVKOaydpc+YSw4MctmEbr0k5"><img alt="Static Badge" src="https://img.shields.io/badge/QQ群-630166526-purple"></a>
|
||||
[](https://wakatime.com/badge/user/915e5316-99c6-4563-a483-ef186cf000c9/project/018e705a-a1a7-409a-a849-3013485e6c8e)
|
||||

|
||||
[](https://codecov.io/gh/Soulter/AstrBot)
|
||||
|
||||
<a href="https://astrbot.app/">Documentation</a> |
|
||||
<a href="https://github.com/Soulter/AstrBot/issues">Issue Tracking</a>
|
||||
</div>
|
||||
|
||||
AstrBot is a loosely coupled, asynchronous chatbot and development framework that supports multi-platform deployment, featuring an easy-to-use plugin system and comprehensive Large Language Model (LLM) integration capabilities.
|
||||
|
||||
## ✨ Key Features
|
||||
|
||||
1. **LLM Conversations** - Supports various LLMs including OpenAI API, Google Gemini, Llama, Deepseek, ChatGLM, etc. Enables local model deployment via Ollama/LLMTuner. Features multi-turn dialogues, personality contexts, multimodal capabilities (image understanding), and speech-to-text (Whisper).
|
||||
2. **Multi-platform Integration** - Supports QQ (OneBot), QQ Channels, WeChat (Gewechat), Feishu, and Telegram. Planned support for DingTalk, Discord, WhatsApp, and Xiaomi Smart Speakers. Includes rate limiting, whitelisting, keyword filtering, and Baidu content moderation.
|
||||
3. **Agent Capabilities** - Native support for code execution, natural language TODO lists, web search. Integrates with [Dify Platform](https://astrbot.app/others/dify.html) for easy access to Dify assistants/knowledge bases/workflows.
|
||||
4. **Plugin System** - Optimized plugin mechanism with minimal development effort. Supports multiple installed plugins.
|
||||
5. **Web Dashboard** - Visual configuration management, plugin controls, logging, and WebChat interface for direct LLM interaction.
|
||||
6. **High Stability & Modularity** - Event bus and pipeline architecture ensures high modularization and loose coupling.
|
||||
|
||||
> [!TIP]
|
||||
> Dashboard Demo: [https://demo.astrbot.app/](https://demo.astrbot.app/)
|
||||
> Username: `astrbot`, Password: `astrbot` (LLM not configured for chat page)
|
||||
|
||||
## ✨ Deployment
|
||||
|
||||
#### Docker Deployment
|
||||
|
||||
See docs: [Deploy with Docker](https://astrbot.app/deploy/astrbot/docker.html#docker-deployment)
|
||||
|
||||
#### Windows Installer
|
||||
|
||||
Requires Python (>3.10). See docs: [Windows Installer Guide](https://astrbot.app/deploy/astrbot/windows.html)
|
||||
|
||||
#### Replit Deployment
|
||||
|
||||
[](https://repl.it/github/Soulter/AstrBot)
|
||||
|
||||
#### CasaOS Deployment
|
||||
|
||||
Community-contributed method.
|
||||
See docs: [CasaOS Deployment](https://astrbot.app/deploy/astrbot/casaos.html)
|
||||
|
||||
#### Manual Deployment
|
||||
|
||||
See docs: [Source Code Deployment](https://astrbot.app/deploy/astrbot/cli.html)
|
||||
|
||||
## ⚡ Platform Support
|
||||
|
||||
| Platform | Status | Details | Message Types |
|
||||
| -------------------------------------------------------------- | ------ | ------------------- | ------------------- |
|
||||
| QQ (Official Bot) | ✔ | Private/Group chats | Text, Images |
|
||||
| QQ (OneBot) | ✔ | Private/Group chats | Text, Images, Voice |
|
||||
| WeChat (Personal) | ✔ | Private/Group chats | Text, Images, Voice |
|
||||
| [Telegram](https://github.com/Soulter/astrbot_plugin_telegram) | ✔ | Private/Group chats | Text, Images |
|
||||
| [WeChat Work](https://github.com/Soulter/astrbot_plugin_wecom) | ✔ | Private chats | Text, Images, Voice |
|
||||
| Feishu | ✔ | Group chats | Text, Images |
|
||||
| WeChat Open Platform | 🚧 | Planned | - |
|
||||
| Discord | 🚧 | Planned | - |
|
||||
| WhatsApp | 🚧 | Planned | - |
|
||||
| Xiaomi Speakers | 🚧 | Planned | - |
|
||||
|
||||
## Provider Support Status
|
||||
|
||||
| Name | Support | Type | Notes |
|
||||
|---------------------------|---------|------------------------|-----------------------------------------------------------------------|
|
||||
| OpenAI API | ✔ | Text Generation | Supports all OpenAI API-compatible services including DeepSeek, Google Gemini, GLM, Moonshot, Alibaba Cloud Bailian, Silicon Flow, xAI, etc. |
|
||||
| Claude API | ✔ | Text Generation | |
|
||||
| Google Gemini API | ✔ | Text Generation | |
|
||||
| Dify | ✔ | LLMOps | |
|
||||
| DashScope (Alibaba Cloud) | ✔ | LLMOps | |
|
||||
| Ollama | ✔ | Model Loader | Local deployment for open-source LLMs (DeepSeek, Llama, etc.) |
|
||||
| LM Studio | ✔ | Model Loader | Local deployment for open-source LLMs (DeepSeek, Llama, etc.) |
|
||||
| LLMTuner | ✔ | Model Loader | Local loading of fine-tuned models (e.g. LoRA) |
|
||||
| OneAPI | ✔ | LLM Distribution | |
|
||||
| Whisper | ✔ | Speech-to-Text | Supports API and local deployment |
|
||||
| SenseVoice | ✔ | Speech-to-Text | Local deployment |
|
||||
| OpenAI TTS API | ✔ | Text-to-Speech | |
|
||||
| Fishaudio | ✔ | Text-to-Speech | Project involving GPT-Sovits author |
|
||||
|
||||
# 🦌 Roadmap
|
||||
|
||||
> [!TIP]
|
||||
> Suggestions welcome via Issues <3
|
||||
|
||||
- [ ] Ensure feature parity across all platform adapters
|
||||
- [ ] Optimize plugin APIs
|
||||
- [ ] Add default TTS services (e.g., GPT-Sovits)
|
||||
- [ ] Enhance chat features with persistent memory
|
||||
- [ ] i18n Planning
|
||||
|
||||
## ❤️ Contributions
|
||||
|
||||
All Issues/PRs welcome! Simply submit your changes to this project :)
|
||||
|
||||
For major features, please discuss via Issues first.
|
||||
|
||||
## 🌟 Support
|
||||
|
||||
- Star this project!
|
||||
- Support via [Afdian](https://afdian.com/a/soulter)
|
||||
- WeChat support: [QR Code](https://drive.soulter.top/f/pYfA/d903f4fa49a496fda3f16d2be9e023b5.png)
|
||||
|
||||
## ✨ Demos
|
||||
|
||||
> [!NOTE]
|
||||
> Code executor file I/O currently tested with Napcat(QQ)/Lagrange(QQ)
|
||||
|
||||
<div align='center'>
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/4ee688d9-467d-45c8-99d6-368f9a8a92d8" width="600">
|
||||
|
||||
_✨ Docker-based Sandboxed Code Executor (Beta) ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/0378f407-6079-4f64-ae4c-e97ab20611d2" height=500>
|
||||
|
||||
_✨ Multimodal Input, Web Search, Text-to-Image ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/8ec12797-e70f-460a-959e-48eca39ca2bb" height=100>
|
||||
|
||||
_✨ Natural Language TODO Lists ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/e137a9e1-340a-4bf2-bb2b-771132780735" height=150>
|
||||
<img src="https://github.com/user-attachments/assets/480f5e82-cf6a-4955-a869-0d73137aa6e1" height=150>
|
||||
|
||||
_✨ Plugin System Showcase ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/592a8630-14c7-4e06-b496-9c0386e4f36c" width=600>
|
||||
|
||||
_✨ Web Dashboard ✨_
|
||||
|
||||
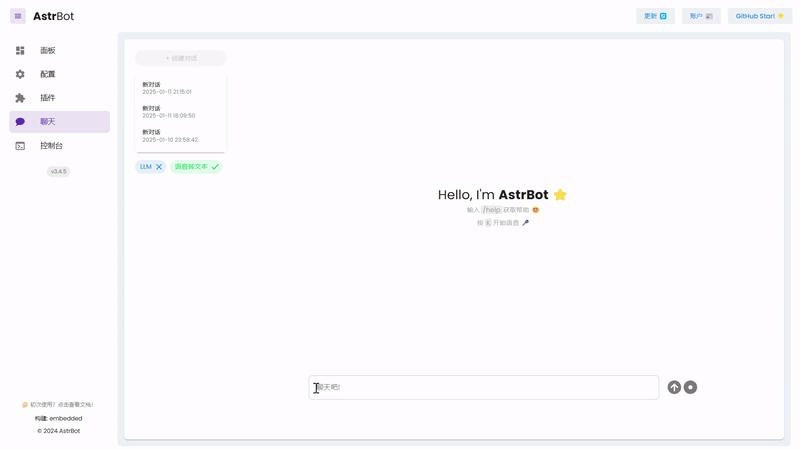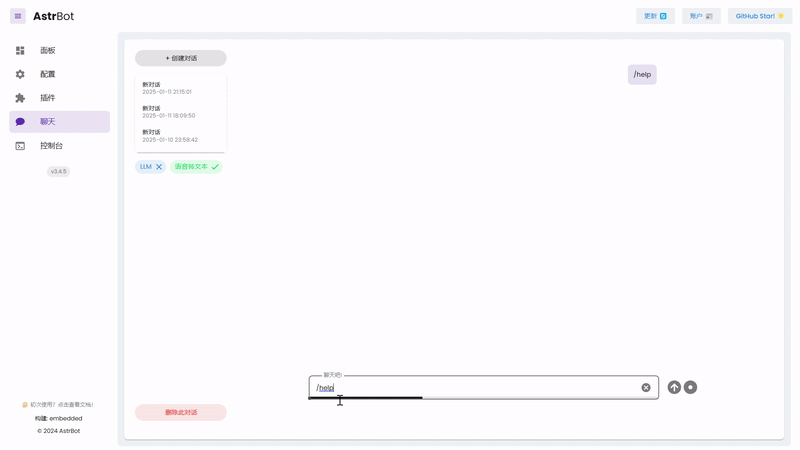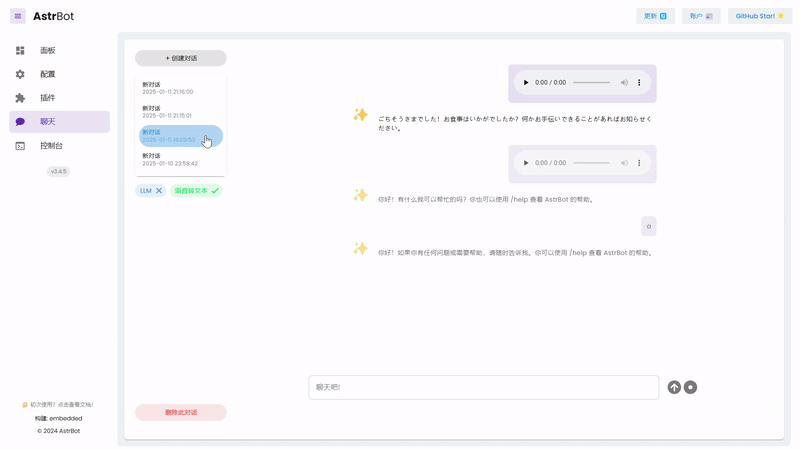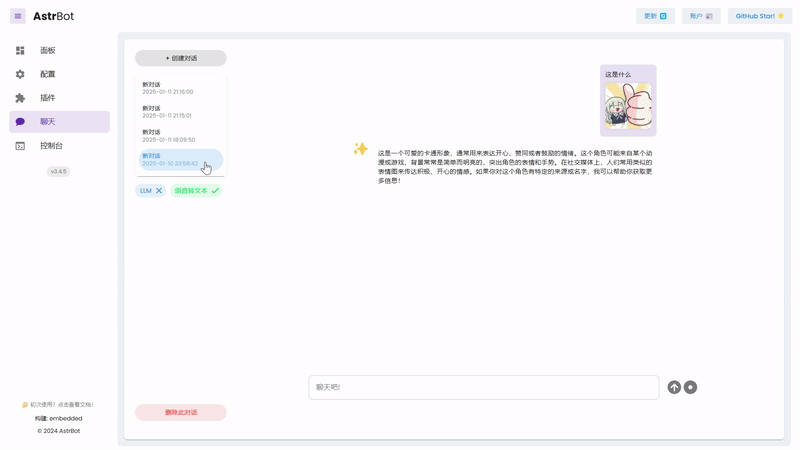
|
||||
|
||||
_✨ Built-in Web Chat Interface ✨_
|
||||
|
||||
</div>
|
||||
|
||||
## ⭐ Star History
|
||||
|
||||
> [!TIP]
|
||||
> If this project helps you, please give it a star <3
|
||||
|
||||
<div align="center">
|
||||
|
||||
[](https://star-history.com/#soulter/astrbot&Date)
|
||||
|
||||
</div>
|
||||
|
||||
## Disclaimer
|
||||
|
||||
1. Licensed under `AGPL-v3`.
|
||||
2. WeChat integration uses [Gewechat](https://github.com/Devo919/Gewechat). Use at your own risk with non-critical accounts.
|
||||
3. Users must comply with local laws and regulations.
|
||||
|
||||
<!-- ## ✨ ATRI [Beta]
|
||||
|
||||
Available as plugin: [astrbot_plugin_atri](https://github.com/Soulter/astrbot_plugin_atri)
|
||||
|
||||
1. Qwen1.5-7B-Chat Lora model fine-tuned with ATRI character data
|
||||
2. Long-term memory
|
||||
3. Meme understanding & responses
|
||||
4. TTS integration
|
||||
-->
|
||||
|
||||
|
||||
_私は、高性能ですから!_
|
||||
|
||||
170
README_ja.md
Normal file
170
README_ja.md
Normal file
@@ -0,0 +1,170 @@
|
||||
<p align="center">
|
||||
|
||||

|
||||
|
||||
</p>
|
||||
|
||||
<div align="center">
|
||||
|
||||
_✨ 簡単に使えるマルチプラットフォーム LLM チャットボットおよび開発フレームワーク ✨_
|
||||
|
||||
<a href="https://trendshift.io/repositories/12875" target="_blank"><img src="https://trendshift.io/api/badge/repositories/12875" alt="Soulter%2FAstrBot | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
|
||||
|
||||
[](https://github.com/Soulter/AstrBot/releases/latest)
|
||||
<img src="https://img.shields.io/badge/python-3.10+-blue.svg" alt="python">
|
||||
<a href="https://hub.docker.com/r/soulter/astrbot"><img alt="Docker pull" src="https://img.shields.io/docker/pulls/soulter/astrbot.svg"/></a>
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/QQ群-630166526-purple">
|
||||
[](https://wakatime.com/badge/user/915e5316-99c6-4563-a483-ef186cf000c9/project/018e705a-a1a7-409a-a849-3013485e6c8e)
|
||||

|
||||
[](https://codecov.io/gh/Soulter/AstrBot)
|
||||
|
||||
<a href="https://astrbot.app/">ドキュメントを見る</a> |
|
||||
<a href="https://github.com/Soulter/AstrBot/issues">問題を報告する</a>
|
||||
</div>
|
||||
|
||||
AstrBot は、疎結合、非同期、複数のメッセージプラットフォームに対応したデプロイ、使いやすいプラグインシステム、および包括的な大規模言語モデル(LLM)接続機能を備えたチャットボットおよび開発フレームワークです。
|
||||
|
||||
## ✨ 主な機能
|
||||
|
||||
1. **大規模言語モデルの対話**。OpenAI API、Google Gemini、Llama、Deepseek、ChatGLM など、さまざまな大規模言語モデルをサポートし、Ollama、LLMTuner を介してローカルにデプロイされた大規模モデルをサポートします。多輪対話、人格シナリオ、多モーダル機能を備え、画像理解、音声からテキストへの変換(Whisper)をサポートします。
|
||||
2. **複数のメッセージプラットフォームの接続**。QQ(OneBot)、QQ チャンネル、WeChat(Gewechat)、Feishu、Telegram への接続をサポートします。今後、DingTalk、Discord、WhatsApp、Xiaoai 音響をサポートする予定です。レート制限、ホワイトリスト、キーワードフィルタリング、Baidu コンテンツ監査をサポートします。
|
||||
3. **エージェント**。一部のエージェント機能をネイティブにサポートし、コードエグゼキューター、自然言語タスク、ウェブ検索などを提供します。[Dify プラットフォーム](https://astrbot.app/others/dify.html)と連携し、Dify スマートアシスタント、ナレッジベース、Dify ワークフローを簡単に接続できます。
|
||||
4. **プラグインの拡張**。深く最適化されたプラグインメカニズムを備え、[プラグインの開発](https://astrbot.app/dev/plugin.html)をサポートし、機能を拡張できます。複数のプラグインのインストールをサポートします。
|
||||
5. **ビジュアル管理パネル**。設定の視覚的な変更、プラグイン管理、ログの表示などをサポートし、設定の難易度を低減します。WebChat を統合し、パネル上で大規模モデルと対話できます。
|
||||
6. **高い安定性と高いモジュール性**。イベントバスとパイプラインに基づくアーキテクチャ設計により、高度にモジュール化され、低結合です。
|
||||
|
||||
> [!TIP]
|
||||
> 管理パネルのオンラインデモを体験する: [https://demo.astrbot.app/](https://demo.astrbot.app/)
|
||||
>
|
||||
> ユーザー名: `astrbot`, パスワード: `astrbot`。LLM が設定されていないため、チャットページで大規模モデルを使用することはできません。(デモのログインパスワードを変更しないでください 😭)
|
||||
|
||||
## ✨ 使用方法
|
||||
|
||||
#### Docker デプロイ
|
||||
|
||||
公式ドキュメント [Docker を使用して AstrBot をデプロイする](https://astrbot.app/deploy/astrbot/docker.html#%E4%BD%BF%E7%94%A8-docker-%E9%83%A8%E7%BD%B2-astrbot) を参照してください。
|
||||
|
||||
#### Windows ワンクリックインストーラーのデプロイ
|
||||
|
||||
コンピュータに Python(>3.10)がインストールされている必要があります。公式ドキュメント [Windows ワンクリックインストーラーを使用して AstrBot をデプロイする](https://astrbot.app/deploy/astrbot/windows.html) を参照してください。
|
||||
|
||||
#### Replit デプロイ
|
||||
|
||||
[](https://repl.it/github/Soulter/AstrBot)
|
||||
|
||||
#### CasaOS デプロイ
|
||||
|
||||
コミュニティが提供するデプロイ方法です。
|
||||
|
||||
公式ドキュメント [ソースコードを使用して AstrBot をデプロイする](https://astrbot.app/deploy/astrbot/casaos.html) を参照してください。
|
||||
|
||||
#### 手動デプロイ
|
||||
|
||||
公式ドキュメント [ソースコードを使用して AstrBot をデプロイする](https://astrbot.app/deploy/astrbot/cli.html) を参照してください。
|
||||
|
||||
## ⚡ メッセージプラットフォームのサポート状況
|
||||
|
||||
| プラットフォーム | サポート状況 | 詳細 | メッセージタイプ |
|
||||
| -------- | ------- | ------- | ------ |
|
||||
| QQ(公式ロボットインターフェース) | ✔ | プライベートチャット、グループチャット、QQ チャンネルプライベートチャット、グループチャット | テキスト、画像 |
|
||||
| QQ(OneBot) | ✔ | プライベートチャット、グループチャット | テキスト、画像、音声 |
|
||||
| WeChat(個人アカウント) | ✔ | WeChat 個人アカウントのプライベートチャット、グループチャット | テキスト、画像、音声 |
|
||||
| [Telegram](https://github.com/Soulter/astrbot_plugin_telegram) | ✔ | プライベートチャット、グループチャット | テキスト、画像 |
|
||||
| [WeChat(企業 WeChat)](https://github.com/Soulter/astrbot_plugin_wecom) | ✔ | プライベートチャット | テキスト、画像、音声 |
|
||||
| Feishu | ✔ | グループチャット | テキスト、画像 |
|
||||
| WeChat 対話オープンプラットフォーム | 🚧 | 計画中 | - |
|
||||
| Discord | 🚧 | 計画中 | - |
|
||||
| WhatsApp | 🚧 | 計画中 | - |
|
||||
| Xiaoai 音響 | 🚧 | 計画中 | - |
|
||||
|
||||
# 🦌 今後のロードマップ
|
||||
|
||||
> [!TIP]
|
||||
> Issue でさらに多くの提案を歓迎します <3
|
||||
|
||||
- [ ] 現在のすべてのプラットフォームアダプターの機能の一貫性を確保し、改善する
|
||||
- [ ] プラグインインターフェースの最適化
|
||||
- [ ] GPT-Sovits などの TTS サービスをデフォルトでサポート
|
||||
- [ ] "チャット強化" 部分を完成させ、永続的な記憶をサポート
|
||||
- [ ] i18n の計画
|
||||
|
||||
## ❤️ 貢献
|
||||
|
||||
Issue や Pull Request を歓迎します!このプロジェクトに変更を加えるだけです :)
|
||||
|
||||
新機能の追加については、まず Issue で議論してください。
|
||||
|
||||
## 🌟 サポート
|
||||
|
||||
- このプロジェクトに Star を付けてください!
|
||||
- [愛発電](https://afdian.com/a/soulter)で私をサポートしてください!
|
||||
- [WeChat](https://drive.soulter.top/f/pYfA/d903f4fa49a496fda3f16d2be9e023b5.png)で私をサポートしてください~
|
||||
|
||||
## ✨ デモ
|
||||
|
||||
> [!NOTE]
|
||||
> コードエグゼキューターのファイル入力/出力は現在 Napcat(QQ)、Lagrange(QQ) でのみテストされています
|
||||
|
||||
<div align='center'>
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/4ee688d9-467d-45c8-99d6-368f9a8a92d8" width="600">
|
||||
|
||||
_✨ Docker ベースのサンドボックス化されたコードエグゼキューター(ベータテスト中)✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/0378f407-6079-4f64-ae4c-e97ab20611d2" height=500>
|
||||
|
||||
_✨ 多モーダル、ウェブ検索、長文の画像変換(設定可能)✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/8ec12797-e70f-460a-959e-48eca39ca2bb" height=100>
|
||||
|
||||
_✨ 自然言語タスク ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/e137a9e1-340a-4bf2-bb2b-771132780735" height=150>
|
||||
<img src="https://github.com/user-attachments/assets/480f5e82-cf6a-4955-a869-0d73137aa6e1" height=150>
|
||||
|
||||
_✨ プラグインシステム - 一部のプラグインの展示 ✨_
|
||||
|
||||
<img src="https://github.com/user-attachments/assets/592a8630-14c7-4e06-b496-9c0386e4f36c" width="600">
|
||||
|
||||
_✨ 管理パネル ✨_
|
||||
|
||||

|
||||
|
||||
_✨ 内蔵 Web Chat、オンラインでボットと対話 ✨_
|
||||
|
||||
</div>
|
||||
|
||||
## ⭐ Star History
|
||||
|
||||
> [!TIP]
|
||||
> このプロジェクトがあなたの生活や仕事に役立った場合、またはこのプロジェクトの将来の発展に関心がある場合は、プロジェクトに Star を付けてください。これはこのオープンソースプロジェクトを維持するためのモチベーションです <3
|
||||
|
||||
<div align="center">
|
||||
|
||||
[](https://star-history.com/#soulter/astrbot&Date)
|
||||
|
||||
</div>
|
||||
|
||||
## スポンサー
|
||||
|
||||
[<img src="https://api.gitsponsors.com/api/badge/img?id=575865240" height="20">](https://api.gitsponsors.com/api/badge/link?p=XEpbdGxlitw/RbcwiTX93UMzNK/jgDYC8NiSzamIPMoKvG2lBFmyXhSS/b0hFoWlBBMX2L5X5CxTDsUdyvcIEHTOfnkXz47UNOZvMwyt5CzbYpq0SEzsSV1OJF1cCo90qC/ZyYKYOWedal3MhZ3ikw==)
|
||||
|
||||
## 免責事項
|
||||
|
||||
1. このプロジェクトは `AGPL-v3` オープンソースライセンスの下で保護されています。
|
||||
2. WeChat(個人アカウント)のデプロイメントには [Gewechat](https://github.com/Devo919/Gewechat) サービスを利用しています。AstrBot は Gewechat との接続を保証するだけであり、アカウントのリスク管理に関しては、このプロジェクトの著者は一切の責任を負いません。
|
||||
3. このプロジェクトを使用する際は、現地の法律および規制を遵守してください。
|
||||
|
||||
<!-- ## ✨ ATRI [ベータテスト]
|
||||
|
||||
この機能はプラグインとしてロードされます。プラグインリポジトリのアドレス:[astrbot_plugin_atri](https://github.com/Soulter/astrbot_plugin_atri)
|
||||
|
||||
1. 《ATRI ~ My Dear Moments》の主人公 ATRI のキャラクターセリフを微調整データセットとして使用した `Qwen1.5-7B-Chat Lora` 微調整モデル。
|
||||
2. 長期記憶
|
||||
3. ミームの理解と返信
|
||||
4. TTS
|
||||
-->
|
||||
|
||||
|
||||
_私は、高性能ですから!_
|
||||
|
||||
@@ -1,2 +1,3 @@
|
||||
from .core.log import LogManager
|
||||
logger = LogManager.GetLogger(log_name='astrbot')
|
||||
|
||||
logger = LogManager.GetLogger(log_name="astrbot")
|
||||
|
||||
@@ -4,10 +4,4 @@ from astrbot.core import html_renderer
|
||||
from astrbot.core import sp
|
||||
from astrbot.core.star.register import register_llm_tool as llm_tool
|
||||
|
||||
__all__ = [
|
||||
"AstrBotConfig",
|
||||
"logger",
|
||||
"html_renderer",
|
||||
"llm_tool",
|
||||
"sp"
|
||||
]
|
||||
__all__ = ["AstrBotConfig", "logger", "html_renderer", "llm_tool", "sp"]
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from astrbot import logger
|
||||
from astrbot.core import html_renderer
|
||||
@@ -6,8 +5,11 @@ from astrbot.core.star.register import register_llm_tool as llm_tool
|
||||
|
||||
# event
|
||||
from astrbot.core.message.message_event_result import (
|
||||
MessageEventResult, MessageChain, CommandResult, EventResultType
|
||||
)
|
||||
MessageEventResult,
|
||||
MessageChain,
|
||||
CommandResult,
|
||||
EventResultType,
|
||||
)
|
||||
from astrbot.core.platform import AstrMessageEvent
|
||||
|
||||
# star register
|
||||
@@ -18,10 +20,16 @@ from astrbot.core.star.register import (
|
||||
register_regex as regex,
|
||||
register_platform_adapter_type as platform_adapter_type,
|
||||
)
|
||||
from astrbot.core.star.filter.event_message_type import EventMessageTypeFilter, EventMessageType
|
||||
from astrbot.core.star.filter.platform_adapter_type import PlatformAdapterTypeFilter, PlatformAdapterType
|
||||
from astrbot.core.star.filter.event_message_type import (
|
||||
EventMessageTypeFilter,
|
||||
EventMessageType,
|
||||
)
|
||||
from astrbot.core.star.filter.platform_adapter_type import (
|
||||
PlatformAdapterTypeFilter,
|
||||
PlatformAdapterType,
|
||||
)
|
||||
from astrbot.core.star.register import (
|
||||
register_star as register # 注册插件(Star)
|
||||
register_star as register, # 注册插件(Star)
|
||||
)
|
||||
from astrbot.core.star import Context, Star
|
||||
from astrbot.core.star.config import *
|
||||
@@ -32,9 +40,14 @@ from astrbot.core.provider import Provider, Personality, ProviderMetaData
|
||||
|
||||
# platform
|
||||
from astrbot.core.platform import (
|
||||
AstrMessageEvent, Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
AstrMessageEvent,
|
||||
Platform,
|
||||
AstrBotMessage,
|
||||
MessageMember,
|
||||
MessageType,
|
||||
PlatformMetadata,
|
||||
)
|
||||
|
||||
from astrbot.core.platform.register import register_platform_adapter
|
||||
|
||||
from .message_components import *
|
||||
from .message_components import *
|
||||
@@ -5,33 +5,45 @@ from astrbot.core.star.register import (
|
||||
register_regex as regex,
|
||||
register_platform_adapter_type as platform_adapter_type,
|
||||
register_permission_type as permission_type,
|
||||
register_custom_filter as custom_filter,
|
||||
register_on_astrbot_loaded as on_astrbot_loaded,
|
||||
register_on_llm_request as on_llm_request,
|
||||
register_on_llm_response as on_llm_response,
|
||||
register_llm_tool as llm_tool,
|
||||
register_on_decorating_result as on_decorating_result,
|
||||
register_after_message_sent as after_message_sent
|
||||
register_after_message_sent as after_message_sent,
|
||||
)
|
||||
|
||||
from astrbot.core.star.filter.event_message_type import EventMessageTypeFilter, EventMessageType
|
||||
from astrbot.core.star.filter.platform_adapter_type import PlatformAdapterTypeFilter, PlatformAdapterType
|
||||
from astrbot.core.star.filter.event_message_type import (
|
||||
EventMessageTypeFilter,
|
||||
EventMessageType,
|
||||
)
|
||||
from astrbot.core.star.filter.platform_adapter_type import (
|
||||
PlatformAdapterTypeFilter,
|
||||
PlatformAdapterType,
|
||||
)
|
||||
from astrbot.core.star.filter.permission import PermissionTypeFilter, PermissionType
|
||||
from astrbot.core.star.filter.custom_filter import CustomFilter
|
||||
|
||||
__all__ = [
|
||||
'command',
|
||||
'command_group',
|
||||
'event_message_type',
|
||||
'regex',
|
||||
'platform_adapter_type',
|
||||
'permission_type',
|
||||
'EventMessageTypeFilter',
|
||||
'EventMessageType',
|
||||
'PlatformAdapterTypeFilter',
|
||||
'PlatformAdapterType',
|
||||
'PermissionTypeFilter',
|
||||
'PermissionType',
|
||||
'on_llm_request',
|
||||
'llm_tool',
|
||||
'on_decorating_result',
|
||||
'after_message_sent',
|
||||
'on_llm_response'
|
||||
]
|
||||
"command",
|
||||
"command_group",
|
||||
"event_message_type",
|
||||
"regex",
|
||||
"platform_adapter_type",
|
||||
"permission_type",
|
||||
"EventMessageTypeFilter",
|
||||
"EventMessageType",
|
||||
"PlatformAdapterTypeFilter",
|
||||
"PlatformAdapterType",
|
||||
"PermissionTypeFilter",
|
||||
"CustomFilter",
|
||||
"custom_filter",
|
||||
"PermissionType",
|
||||
"on_astrbot_loaded",
|
||||
"on_llm_request",
|
||||
"llm_tool",
|
||||
"on_decorating_result",
|
||||
"after_message_sent",
|
||||
"on_llm_response",
|
||||
]
|
||||
|
||||
@@ -1 +1 @@
|
||||
from astrbot.core.message.components import *
|
||||
from astrbot.core.message.components import *
|
||||
|
||||
@@ -1,6 +1,21 @@
|
||||
from astrbot.core.platform import (
|
||||
AstrMessageEvent, Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
AstrMessageEvent,
|
||||
Platform,
|
||||
AstrBotMessage,
|
||||
MessageMember,
|
||||
MessageType,
|
||||
PlatformMetadata,
|
||||
)
|
||||
|
||||
from astrbot.core.platform.register import register_platform_adapter
|
||||
from astrbot.core.message.components import *
|
||||
from astrbot.core.message.components import *
|
||||
|
||||
__all__ = [
|
||||
"AstrMessageEvent",
|
||||
"Platform",
|
||||
"AstrBotMessage",
|
||||
"MessageMember",
|
||||
"MessageType",
|
||||
"PlatformMetadata",
|
||||
"register_platform_adapter",
|
||||
]
|
||||
|
||||
@@ -1,2 +1,17 @@
|
||||
from astrbot.core.provider import Provider, STTProvider, Personality
|
||||
from astrbot.core.provider.entites import ProviderRequest, ProviderType, ProviderMetaData, LLMResponse
|
||||
from astrbot.core.provider.entites import (
|
||||
ProviderRequest,
|
||||
ProviderType,
|
||||
ProviderMetaData,
|
||||
LLMResponse,
|
||||
)
|
||||
|
||||
__all__ = [
|
||||
"Provider",
|
||||
"STTProvider",
|
||||
"Personality",
|
||||
"ProviderRequest",
|
||||
"ProviderType",
|
||||
"ProviderMetaData",
|
||||
"LLMResponse",
|
||||
]
|
||||
|
||||
@@ -1,6 +1,12 @@
|
||||
from astrbot.core.star.register import (
|
||||
register_star as register # 注册插件(Star)
|
||||
register_star as register, # 注册插件(Star)
|
||||
)
|
||||
|
||||
from astrbot.core.star import Context, Star
|
||||
from astrbot.core.star.config import *
|
||||
|
||||
__all__ = [
|
||||
"register",
|
||||
"Context",
|
||||
"Star",
|
||||
]
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import os
|
||||
import asyncio
|
||||
from .log import LogManager, LogBroker
|
||||
from .log import LogManager, LogBroker # noqa
|
||||
from astrbot.core.utils.t2i.renderer import HtmlRenderer
|
||||
from astrbot.core.utils.shared_preferences import SharedPreferences
|
||||
from astrbot.core.utils.pip_installer import PipInstaller
|
||||
@@ -11,16 +11,16 @@ from astrbot.core.config import AstrBotConfig
|
||||
os.makedirs("data", exist_ok=True)
|
||||
|
||||
astrbot_config = AstrBotConfig()
|
||||
t2i_base_url = astrbot_config.get('t2i_endpoint', 'https://t2i.soulter.top/text2img')
|
||||
t2i_base_url = astrbot_config.get("t2i_endpoint", "https://t2i.soulter.top/text2img")
|
||||
html_renderer = HtmlRenderer(t2i_base_url)
|
||||
logger = LogManager.GetLogger(log_name='astrbot')
|
||||
logger = LogManager.GetLogger(log_name="astrbot")
|
||||
|
||||
if os.environ.get("TESTING", ""):
|
||||
logger.setLevel("DEBUG")
|
||||
|
||||
if os.environ.get('TESTING', ""):
|
||||
logger.setLevel('DEBUG')
|
||||
|
||||
db_helper = SQLiteDatabase(DB_PATH)
|
||||
sp = SharedPreferences() # 简单的偏好设置存储
|
||||
pip_installer = PipInstaller(astrbot_config.get('pip_install_arg', ''))
|
||||
sp = SharedPreferences() # 简单的偏好设置存储
|
||||
pip_installer = PipInstaller(astrbot_config.get("pip_install_arg", ""))
|
||||
web_chat_queue = asyncio.Queue(maxsize=32)
|
||||
web_chat_back_queue = asyncio.Queue(maxsize=32)
|
||||
WEBUI_SK = "Advanced_System_for_Text_Response_and_Bot_Operations_Tool"
|
||||
|
||||
@@ -1,2 +1,9 @@
|
||||
from .default import DEFAULT_CONFIG, VERSION, DB_PATH
|
||||
from .astrbot_config import *
|
||||
from .astrbot_config import *
|
||||
|
||||
__all__ = [
|
||||
"DEFAULT_CONFIG",
|
||||
"VERSION",
|
||||
"DB_PATH",
|
||||
"AstrBotConfig",
|
||||
]
|
||||
|
||||
@@ -8,79 +8,82 @@ from typing import Dict
|
||||
ASTRBOT_CONFIG_PATH = "data/cmd_config.json"
|
||||
logger = logging.getLogger("astrbot")
|
||||
|
||||
|
||||
class RateLimitStrategy(enum.Enum):
|
||||
STALL = "stall"
|
||||
DISCARD = "discard"
|
||||
|
||||
|
||||
class AstrBotConfig(dict):
|
||||
'''从配置文件中加载的配置,支持直接通过点号操作符访问根配置项。
|
||||
|
||||
"""从配置文件中加载的配置,支持直接通过点号操作符访问根配置项。
|
||||
|
||||
- 初始化时会将传入的 default_config 与配置文件进行比对,如果配置文件中缺少配置项则会自动插入默认值并进行一次写入操作。会递归检查配置项。
|
||||
- 如果配置文件路径对应的文件不存在,则会自动创建并写入默认配置。
|
||||
- 如果传入了 schema,将会通过 schema 解析出 default_config,此时传入的 default_config 会被忽略。
|
||||
'''
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
config_path: str = ASTRBOT_CONFIG_PATH,
|
||||
self,
|
||||
config_path: str = ASTRBOT_CONFIG_PATH,
|
||||
default_config: dict = DEFAULT_CONFIG,
|
||||
schema: dict = None
|
||||
schema: dict = None,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
|
||||
# 调用父类的 __setattr__ 方法,防止保存配置时将此属性写入配置文件
|
||||
object.__setattr__(self, 'config_path', config_path)
|
||||
object.__setattr__(self, 'default_config', default_config)
|
||||
object.__setattr__(self, 'schema', schema)
|
||||
|
||||
object.__setattr__(self, "config_path", config_path)
|
||||
object.__setattr__(self, "default_config", default_config)
|
||||
object.__setattr__(self, "schema", schema)
|
||||
|
||||
if schema:
|
||||
default_config = self._config_schema_to_default_config(schema)
|
||||
|
||||
|
||||
if not self.check_exist():
|
||||
'''不存在时载入默认配置'''
|
||||
"""不存在时载入默认配置"""
|
||||
with open(config_path, "w", encoding="utf-8-sig") as f:
|
||||
json.dump(default_config, f, indent=4, ensure_ascii=False)
|
||||
|
||||
with open(config_path, "r", encoding="utf-8-sig") as f:
|
||||
conf_str = f.read()
|
||||
if conf_str.startswith(u'/ufeff'): # remove BOM
|
||||
conf_str = conf_str.encode('utf8')[3:].decode('utf8')
|
||||
if conf_str.startswith("/ufeff"): # remove BOM
|
||||
conf_str = conf_str.encode("utf8")[3:].decode("utf8")
|
||||
conf = json.loads(conf_str)
|
||||
|
||||
|
||||
# 检查配置完整性,并插入
|
||||
has_new = self.check_config_integrity(default_config, conf)
|
||||
self.update(conf)
|
||||
if has_new:
|
||||
self.save_config()
|
||||
|
||||
|
||||
self.update(conf)
|
||||
|
||||
def _config_schema_to_default_config(self, schema: dict) -> dict:
|
||||
'''将 Schema 转换成 Config'''
|
||||
"""将 Schema 转换成 Config"""
|
||||
conf = {}
|
||||
|
||||
|
||||
def _parse_schema(schema: dict, conf: dict):
|
||||
for k, v in schema.items():
|
||||
if v['type'] not in DEFAULT_VALUE_MAP:
|
||||
raise TypeError(f"不受支持的配置类型 {v['type']}。支持的类型有:{DEFAULT_VALUE_MAP.keys()}")
|
||||
if 'default' in v:
|
||||
default = v['default']
|
||||
if v["type"] not in DEFAULT_VALUE_MAP:
|
||||
raise TypeError(
|
||||
f"不受支持的配置类型 {v['type']}。支持的类型有:{DEFAULT_VALUE_MAP.keys()}"
|
||||
)
|
||||
if "default" in v:
|
||||
default = v["default"]
|
||||
else:
|
||||
default = DEFAULT_VALUE_MAP[v['type']]
|
||||
|
||||
if v['type'] == 'object':
|
||||
default = DEFAULT_VALUE_MAP[v["type"]]
|
||||
|
||||
if v["type"] == "object":
|
||||
conf[k] = {}
|
||||
_parse_schema(v['items'], conf[k])
|
||||
_parse_schema(v["items"], conf[k])
|
||||
else:
|
||||
conf[k] = default
|
||||
|
||||
|
||||
_parse_schema(schema, conf)
|
||||
|
||||
return conf
|
||||
|
||||
|
||||
def check_config_integrity(self, refer_conf: Dict, conf: Dict, path=""):
|
||||
'''检查配置完整性,如果有新的配置项则返回 True'''
|
||||
"""检查配置完整性,如果有新的配置项则返回 True"""
|
||||
has_new = False
|
||||
for key, value in refer_conf.items():
|
||||
if key not in conf:
|
||||
@@ -94,25 +97,27 @@ class AstrBotConfig(dict):
|
||||
conf[key] = value
|
||||
has_new = True
|
||||
elif isinstance(value, dict):
|
||||
has_new |= self.check_config_integrity(value, conf[key], path + "." + key if path else key)
|
||||
has_new |= self.check_config_integrity(
|
||||
value, conf[key], path + "." + key if path else key
|
||||
)
|
||||
return has_new
|
||||
|
||||
|
||||
def save_config(self, replace_config: Dict = None):
|
||||
'''将配置写入文件
|
||||
|
||||
"""将配置写入文件
|
||||
|
||||
如果传入 replace_config,则将配置替换为 replace_config
|
||||
'''
|
||||
"""
|
||||
if replace_config:
|
||||
self.update(replace_config)
|
||||
with open(self.config_path, "w", encoding="utf-8-sig") as f:
|
||||
json.dump(self, f, indent=2, ensure_ascii=False)
|
||||
|
||||
|
||||
def __getattr__(self, item):
|
||||
try:
|
||||
return self[item]
|
||||
except KeyError:
|
||||
return None
|
||||
|
||||
|
||||
def __delattr__(self, key):
|
||||
try:
|
||||
del self[key]
|
||||
@@ -124,4 +129,4 @@ class AstrBotConfig(dict):
|
||||
self[key] = value
|
||||
|
||||
def check_exist(self) -> bool:
|
||||
return os.path.exists(self.config_path)
|
||||
return os.path.exists(self.config_path)
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
如需修改配置,请在 `data/cmd_config.json` 中修改或者在管理面板中可视化修改。
|
||||
"""
|
||||
|
||||
VERSION = "3.4.26"
|
||||
VERSION = "3.4.35"
|
||||
DB_PATH = "data/data_v3.db"
|
||||
|
||||
# 默认配置
|
||||
@@ -16,7 +16,7 @@ DEFAULT_CONFIG = {
|
||||
"strategy": "stall", # stall, discard
|
||||
},
|
||||
"reply_prefix": "",
|
||||
"forward_threshold": 200,
|
||||
"forward_threshold": 1500,
|
||||
"enable_id_white_list": True,
|
||||
"id_whitelist": [],
|
||||
"id_whitelist_log": True,
|
||||
@@ -32,7 +32,8 @@ DEFAULT_CONFIG = {
|
||||
"interval": "1.5,3.5",
|
||||
"log_base": 2.6,
|
||||
"words_count_threshold": 150,
|
||||
"regex": ".*?[。?!~…]+|.+$"
|
||||
"regex": ".*?[。?!~…]+|.+$",
|
||||
"content_cleanup_rule": "",
|
||||
},
|
||||
"no_permission_reply": True,
|
||||
},
|
||||
@@ -66,16 +67,15 @@ DEFAULT_CONFIG = {
|
||||
"method": "possibility_reply",
|
||||
"possibility_reply": 0.1,
|
||||
"prompt": "",
|
||||
}
|
||||
"whitelist": [],
|
||||
},
|
||||
},
|
||||
"content_safety": {
|
||||
"also_use_in_response": False,
|
||||
"internal_keywords": {"enable": True, "extra_keywords": []},
|
||||
"baidu_aip": {"enable": False, "app_id": "", "api_key": "", "secret_key": ""},
|
||||
},
|
||||
"admins_id": [
|
||||
"astrbot"
|
||||
],
|
||||
"admins_id": ["astrbot"],
|
||||
"t2i": False,
|
||||
"t2i_word_threshold": 150,
|
||||
"http_proxy": "",
|
||||
@@ -83,7 +83,7 @@ DEFAULT_CONFIG = {
|
||||
"enable": True,
|
||||
"username": "astrbot",
|
||||
"password": "77b90590a8945a7d36c963981a307dc9",
|
||||
"port": 6185
|
||||
"port": 6185,
|
||||
},
|
||||
"platform": [],
|
||||
"wake_prefix": ["/"],
|
||||
@@ -120,9 +120,9 @@ CONFIG_METADATA_2 = {
|
||||
"enable": False,
|
||||
"appid": "",
|
||||
"secret": "",
|
||||
"port": 6196
|
||||
"port": 6196,
|
||||
},
|
||||
"aiocqhtp(QQ)": {
|
||||
"aiocqhttp(OneBotv11)": {
|
||||
"id": "default",
|
||||
"type": "aiocqhttp",
|
||||
"enable": False,
|
||||
@@ -138,6 +138,17 @@ CONFIG_METADATA_2 = {
|
||||
"host": "这里填写你的局域网IP或者公网服务器IP",
|
||||
"port": 11451,
|
||||
},
|
||||
"wecom(企业微信)": {
|
||||
"id": "wecom",
|
||||
"type": "wecom",
|
||||
"enable": False,
|
||||
"corpid": "",
|
||||
"secret": "",
|
||||
"port": 6195,
|
||||
"token": "",
|
||||
"encoding_aes_key": "",
|
||||
"api_base_url": "https://qyapi.weixin.qq.com/cgi-bin/",
|
||||
},
|
||||
"lark(飞书)": {
|
||||
"id": "lark",
|
||||
"type": "lark",
|
||||
@@ -145,14 +156,28 @@ CONFIG_METADATA_2 = {
|
||||
"lark_bot_name": "",
|
||||
"app_id": "",
|
||||
"app_secret": "",
|
||||
"domain": "https://open.feishu.cn"
|
||||
"domain": "https://open.feishu.cn",
|
||||
},
|
||||
"telegram": {
|
||||
"id": "telegram",
|
||||
"type": "telegram",
|
||||
"enable": False,
|
||||
"telegram_token": "your_bot_token",
|
||||
"start_message": "Hello, I'm AstrBot!",
|
||||
"telegram_api_base_url": "https://api.telegram.org/bot",
|
||||
},
|
||||
},
|
||||
"items": {
|
||||
"telegram_token": {
|
||||
"description": "Bot Token",
|
||||
"type": "string",
|
||||
"hint": "如果你的网络环境为中国大陆,请在 `其他配置` 处设置代理或更改 api_base。",
|
||||
},
|
||||
"id": {
|
||||
"description": "ID",
|
||||
"type": "string",
|
||||
"hint": "用于在多实例下方便管理和识别。自定义,ID 不能重复。",
|
||||
"obvious_hint": True,
|
||||
"hint": "ID 不能和其它的平台适配器重复,否则将发生严重冲突。",
|
||||
},
|
||||
"type": {
|
||||
"description": "适配器类型",
|
||||
@@ -198,8 +223,8 @@ CONFIG_METADATA_2 = {
|
||||
"description": "飞书机器人的名字",
|
||||
"type": "string",
|
||||
"hint": "请务必填对,否则 @ 机器人将无法唤醒,只能通过前缀唤醒。",
|
||||
"obvious_hint": True
|
||||
}
|
||||
"obvious_hint": True,
|
||||
},
|
||||
},
|
||||
},
|
||||
"platform_settings": {
|
||||
@@ -247,7 +272,7 @@ CONFIG_METADATA_2 = {
|
||||
"description": "间隔时间计算方法",
|
||||
"type": "string",
|
||||
"options": ["random", "log"],
|
||||
"hint": "分段回复的间隔时间计算方法。random 为随机时间,log 为根据消息长度计算,$y=log_{log\_base}(x)$,x为字数,y的单位为秒。",
|
||||
"hint": "分段回复的间隔时间计算方法。random 为随机时间,log 为根据消息长度计算,$y=log_<log_base>(x)$,x为字数,y的单位为秒。",
|
||||
},
|
||||
"interval": {
|
||||
"description": "随机间隔时间(秒)",
|
||||
@@ -270,6 +295,12 @@ CONFIG_METADATA_2 = {
|
||||
"obvious_hint": True,
|
||||
"hint": "用于分隔一段消息。默认情况下会根据句号、问号等标点符号分隔。re.findall(r'<regex>', text)",
|
||||
},
|
||||
"content_cleanup_rule": {
|
||||
"description": "过滤分段后的内容",
|
||||
"type": "string",
|
||||
"obvious_hint": True,
|
||||
"hint": "移除分段后的内容中的指定的内容。支持正则表达式。如填写 `[。?!]` 将移除所有的句号、问号、感叹号。re.sub(r'<regex>', '', text)",
|
||||
},
|
||||
},
|
||||
},
|
||||
"reply_prefix": {
|
||||
@@ -378,7 +409,7 @@ CONFIG_METADATA_2 = {
|
||||
"description": "服务提供商配置",
|
||||
"type": "list",
|
||||
"config_template": {
|
||||
"openai": {
|
||||
"OpenAI": {
|
||||
"id": "openai",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
@@ -389,7 +420,7 @@ CONFIG_METADATA_2 = {
|
||||
"model": "gpt-4o-mini",
|
||||
},
|
||||
},
|
||||
"azure_openai": {
|
||||
"Azure_OpenAI": {
|
||||
"id": "azure",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
@@ -401,7 +432,30 @@ CONFIG_METADATA_2 = {
|
||||
"model": "gpt-4o-mini",
|
||||
},
|
||||
},
|
||||
"ollama": {
|
||||
"xAI(grok)": {
|
||||
"id": "xai",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "https://api.x.ai/v1",
|
||||
"timeout": 120,
|
||||
"model_config": {
|
||||
"model": "grok-2-latest",
|
||||
},
|
||||
},
|
||||
"Anthropic(claude)": {
|
||||
"id": "claude",
|
||||
"type": "anthropic_chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "https://api.anthropic.com/v1",
|
||||
"timeout": 120,
|
||||
"model_config": {
|
||||
"model": "claude-3-5-sonnet-latest",
|
||||
"max_tokens": 4096,
|
||||
},
|
||||
},
|
||||
"Ollama": {
|
||||
"id": "ollama_default",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
@@ -411,7 +465,7 @@ CONFIG_METADATA_2 = {
|
||||
"model": "llama3.1-8b",
|
||||
},
|
||||
},
|
||||
"gemini(OpenAI兼容)": {
|
||||
"Gemini(OpenAI兼容)": {
|
||||
"id": "gemini_default",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
@@ -422,7 +476,7 @@ CONFIG_METADATA_2 = {
|
||||
"model": "gemini-1.5-flash",
|
||||
},
|
||||
},
|
||||
"gemini(googlegenai原生)": {
|
||||
"Gemini(googlegenai原生)": {
|
||||
"id": "gemini_default",
|
||||
"type": "googlegenai_chat_completion",
|
||||
"enable": True,
|
||||
@@ -433,7 +487,7 @@ CONFIG_METADATA_2 = {
|
||||
"model": "gemini-1.5-flash",
|
||||
},
|
||||
},
|
||||
"deepseek": {
|
||||
"DeepSeek": {
|
||||
"id": "deepseek_default",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
@@ -444,7 +498,7 @@ CONFIG_METADATA_2 = {
|
||||
"model": "deepseek-chat",
|
||||
},
|
||||
},
|
||||
"zhipu": {
|
||||
"Zhipu(智谱)": {
|
||||
"id": "zhipu_default",
|
||||
"type": "zhipu_chat_completion",
|
||||
"enable": True,
|
||||
@@ -455,7 +509,7 @@ CONFIG_METADATA_2 = {
|
||||
"model": "glm-4-flash",
|
||||
},
|
||||
},
|
||||
"siliconflow": {
|
||||
"SiliconFlow(硅基流动)": {
|
||||
"id": "siliconflow",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
@@ -466,7 +520,7 @@ CONFIG_METADATA_2 = {
|
||||
"model": "deepseek-ai/DeepSeek-V3",
|
||||
},
|
||||
},
|
||||
"moonshot(kimi)": {
|
||||
"MoonShot(Kimi)": {
|
||||
"id": "moonshot",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
@@ -477,7 +531,7 @@ CONFIG_METADATA_2 = {
|
||||
"model": "moonshot-v1-8k",
|
||||
},
|
||||
},
|
||||
"llmtuner": {
|
||||
"LLMTuner": {
|
||||
"id": "llmtuner_default",
|
||||
"type": "llm_tuner",
|
||||
"enable": True,
|
||||
@@ -487,7 +541,7 @@ CONFIG_METADATA_2 = {
|
||||
"finetuning_type": "lora",
|
||||
"quantization_bit": 4,
|
||||
},
|
||||
"dify": {
|
||||
"Dify": {
|
||||
"id": "dify_app_default",
|
||||
"type": "dify",
|
||||
"enable": True,
|
||||
@@ -495,9 +549,29 @@ CONFIG_METADATA_2 = {
|
||||
"dify_api_key": "",
|
||||
"dify_api_base": "https://api.dify.ai/v1",
|
||||
"dify_workflow_output_key": "",
|
||||
"dify_query_input_key": "astrbot_text_query",
|
||||
"variables": {},
|
||||
"timeout": 60,
|
||||
},
|
||||
"whisper(API)": {
|
||||
"Dashscope(阿里云百炼应用)": {
|
||||
"id": "dashscope",
|
||||
"type": "dashscope",
|
||||
"enable": True,
|
||||
"dashscope_app_type": "agent",
|
||||
"dashscope_api_key": "",
|
||||
"dashscope_app_id": "",
|
||||
"variables": {},
|
||||
"timeout": 60,
|
||||
},
|
||||
"FastGPT": {
|
||||
"id": "fastgpt",
|
||||
"type": "openai_chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "https://api.fastgpt.in/api/v1",
|
||||
"timeout": 60,
|
||||
},
|
||||
"Whisper(API)": {
|
||||
"id": "whisper",
|
||||
"type": "openai_whisper_api",
|
||||
"enable": False,
|
||||
@@ -505,14 +579,22 @@ CONFIG_METADATA_2 = {
|
||||
"api_base": "",
|
||||
"model": "whisper-1",
|
||||
},
|
||||
"whisper(本地加载)": {
|
||||
"Whisper(本地加载)": {
|
||||
"whisper_hint": "(不用修改我)",
|
||||
"enable": False,
|
||||
"id": "whisper",
|
||||
"type": "openai_whisper_selfhost",
|
||||
"model": "tiny",
|
||||
},
|
||||
"openai_tts(API)": {
|
||||
"sensevoice(本地加载)": {
|
||||
"sensevoice_hint": "(不用修改我)",
|
||||
"enable": False,
|
||||
"id": "sensevoice",
|
||||
"type": "sensevoice_stt_selfhost",
|
||||
"stt_model": "iic/SenseVoiceSmall",
|
||||
"is_emotion": False,
|
||||
},
|
||||
"OpenAI_TTS(API)": {
|
||||
"id": "openai_tts",
|
||||
"type": "openai_tts_api",
|
||||
"enable": False,
|
||||
@@ -522,7 +604,24 @@ CONFIG_METADATA_2 = {
|
||||
"openai-tts-voice": "alloy",
|
||||
"timeout": "20",
|
||||
},
|
||||
"fishaudio_tts(API)": {
|
||||
"Edge_TTS": {
|
||||
"edgetts_hint": "提示:使用这个服务前需要安装有 ffmpeg,并且可以直接在终端调用 ffmpeg 指令。",
|
||||
"id": "edge_tts",
|
||||
"type": "edge_tts",
|
||||
"enable": False,
|
||||
"edge-tts-voice": "zh-CN-XiaoxiaoNeural",
|
||||
"timeout": 20,
|
||||
},
|
||||
"GSVI_TTS(API)": {
|
||||
"id": "gsvi_tts",
|
||||
"type": "gsvi_tts_api",
|
||||
"api_base": "http://127.0.0.1:5000",
|
||||
"character": "",
|
||||
"emotion": "default",
|
||||
"enable": False,
|
||||
"timeout": 20,
|
||||
},
|
||||
"FishAudio_TTS(API)": {
|
||||
"id": "fishaudio_tts",
|
||||
"type": "fishaudio_tts_api",
|
||||
"enable": False,
|
||||
@@ -533,6 +632,47 @@ CONFIG_METADATA_2 = {
|
||||
},
|
||||
},
|
||||
"items": {
|
||||
"sensevoice_hint": {
|
||||
"description": "部署SenseVoice",
|
||||
"type": "string",
|
||||
"hint": "启用前请 pip 安装 funasr、funasr_onnx、torchaudio、torch、modelscope、jieba 库(默认使用CPU,大约下载 1 GB),并且安装 ffmpeg。否则将无法正常转文字。",
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"is_emotion": {
|
||||
"description": "情绪识别",
|
||||
"type": "bool",
|
||||
"hint": "是否开启情绪识别。happy|sad|angry|neutral|fearful|disgusted|surprised|unknown",
|
||||
},
|
||||
"stt_model": {
|
||||
"description": "模型名称",
|
||||
"type": "string",
|
||||
"hint": "modelscope 上的模型名称。默认:iic/SenseVoiceSmall。",
|
||||
},
|
||||
# "variables": {
|
||||
# "description": "工作流固定输入变量",
|
||||
# "type": "object",
|
||||
# "obvious_hint": True,
|
||||
# "hint": "可选。工作流固定输入变量,将会作为工作流的输入。也可以在对话时使用 /set 指令动态设置变量。如果变量名冲突,优先使用动态设置的变量。",
|
||||
# },
|
||||
# "fastgpt_app_type": {
|
||||
# "description": "应用类型",
|
||||
# "type": "string",
|
||||
# "hint": "FastGPT 应用的应用类型。",
|
||||
# "options": ["agent", "workflow", "plugin"],
|
||||
# "obvious_hint": True,
|
||||
# },
|
||||
"dashscope_app_type": {
|
||||
"description": "应用类型",
|
||||
"type": "string",
|
||||
"hint": "阿里云百炼应用的应用类型。",
|
||||
"options": [
|
||||
"agent",
|
||||
"agent-arrange",
|
||||
"dialog-workflow",
|
||||
"task-workflow",
|
||||
],
|
||||
"obvious_hint": True,
|
||||
},
|
||||
"timeout": {
|
||||
"description": "超时时间",
|
||||
"type": "int",
|
||||
@@ -559,7 +699,8 @@ CONFIG_METADATA_2 = {
|
||||
"id": {
|
||||
"description": "ID",
|
||||
"type": "string",
|
||||
"hint": "提供商 ID 名,用于在多实例下方便管理和识别。自定义,ID 不能重复。",
|
||||
"obvious_hint": True,
|
||||
"hint": "ID 不能和其它的服务提供商重复,否则将发生严重冲突。",
|
||||
},
|
||||
"type": {
|
||||
"description": "模型提供商类型",
|
||||
@@ -646,6 +787,12 @@ CONFIG_METADATA_2 = {
|
||||
"type": "string",
|
||||
"hint": "Dify Workflow 输出变量名。当应用类型为 workflow 时才使用。默认为 astrbot_wf_output。",
|
||||
},
|
||||
"dify_query_input_key": {
|
||||
"description": "Prompt 输入变量名",
|
||||
"type": "string",
|
||||
"hint": "发送的消息文本内容对应的输入变量名。默认为 astrbot_text_query。",
|
||||
"obvious": True,
|
||||
},
|
||||
},
|
||||
},
|
||||
"provider_settings": {
|
||||
@@ -815,6 +962,13 @@ CONFIG_METADATA_2 = {
|
||||
"obvious_hint": True,
|
||||
"hint": "启用后,会根据触发概率主动回复群聊内的对话。QQ官方API(qq_official)不可用",
|
||||
},
|
||||
"whitelist": {
|
||||
"description": "主动回复白名单",
|
||||
"type": "list",
|
||||
"items": {"type": "string"},
|
||||
"obvious_hint": True,
|
||||
"hint": "启用后,只有在白名单内的群聊会被主动回复。为空时不启用白名单过滤。需要通过 /sid 获取 SID 添加到这里。",
|
||||
},
|
||||
"method": {
|
||||
"description": "回复方法",
|
||||
"type": "string",
|
||||
|
||||
@@ -6,14 +6,16 @@ from typing import Dict, List
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot.core.db.po import Conversation
|
||||
|
||||
class ConversationManager():
|
||||
'''负责管理会话与 LLM 的对话,某个会话当前正在用哪个对话。'''
|
||||
|
||||
class ConversationManager:
|
||||
"""负责管理会话与 LLM 的对话,某个会话当前正在用哪个对话。"""
|
||||
|
||||
def __init__(self, db_helper: BaseDatabase):
|
||||
self.session_conversations: Dict[str, str] = sp.get("session_conversation", {})
|
||||
self.db = db_helper
|
||||
self.save_interval = 60 # 每 60 秒保存一次
|
||||
self._start_periodic_save()
|
||||
|
||||
|
||||
def _start_periodic_save(self):
|
||||
asyncio.create_task(self._periodic_save())
|
||||
|
||||
@@ -26,82 +28,83 @@ class ConversationManager():
|
||||
sp.put("session_conversation", self.session_conversations)
|
||||
|
||||
async def new_conversation(self, unified_msg_origin: str) -> str:
|
||||
'''新建对话,并将当前会话的对话转移到新对话'''
|
||||
"""新建对话,并将当前会话的对话转移到新对话"""
|
||||
conversation_id = str(uuid.uuid4())
|
||||
self.db.new_conversation(
|
||||
user_id=unified_msg_origin,
|
||||
cid=conversation_id
|
||||
)
|
||||
self.db.new_conversation(user_id=unified_msg_origin, cid=conversation_id)
|
||||
self.session_conversations[unified_msg_origin] = conversation_id
|
||||
sp.put("session_conversation", self.session_conversations)
|
||||
return conversation_id
|
||||
|
||||
|
||||
async def switch_conversation(self, unified_msg_origin: str, conversation_id: str):
|
||||
'''切换会话的对话'''
|
||||
"""切换会话的对话"""
|
||||
self.session_conversations[unified_msg_origin] = conversation_id
|
||||
sp.put("session_conversation", self.session_conversations)
|
||||
|
||||
async def delete_conversation(self, unified_msg_origin: str, conversation_id: str=None):
|
||||
'''删除会话的对话,当 conversation_id 为 None 时删除会话当前的对话'''
|
||||
|
||||
async def delete_conversation(
|
||||
self, unified_msg_origin: str, conversation_id: str = None
|
||||
):
|
||||
"""删除会话的对话,当 conversation_id 为 None 时删除会话当前的对话"""
|
||||
conversation_id = self.session_conversations.get(unified_msg_origin)
|
||||
if conversation_id:
|
||||
self.db.delete_conversation(
|
||||
user_id=unified_msg_origin,
|
||||
cid=conversation_id
|
||||
)
|
||||
self.db.delete_conversation(user_id=unified_msg_origin, cid=conversation_id)
|
||||
del self.session_conversations[unified_msg_origin]
|
||||
|
||||
sp.put("session_conversation", self.session_conversations)
|
||||
|
||||
async def get_curr_conversation_id(self, unified_msg_origin: str) -> str:
|
||||
'''获取会话当前的对话 ID'''
|
||||
"""获取会话当前的对话 ID"""
|
||||
return self.session_conversations.get(unified_msg_origin, None)
|
||||
|
||||
async def get_conversation(self, unified_msg_origin: str, conversation_id: str) -> Conversation:
|
||||
'''获取会话的对话'''
|
||||
|
||||
async def get_conversation(
|
||||
self, unified_msg_origin: str, conversation_id: str
|
||||
) -> Conversation:
|
||||
"""获取会话的对话"""
|
||||
return self.db.get_conversation_by_user_id(unified_msg_origin, conversation_id)
|
||||
|
||||
|
||||
async def get_conversations(self, unified_msg_origin: str) -> List[Conversation]:
|
||||
'''获取会话的所有对话'''
|
||||
"""获取会话的所有对话"""
|
||||
return self.db.get_conversations(unified_msg_origin)
|
||||
|
||||
async def update_conversation(self, unified_msg_origin: str, conversation_id: str, history: List[Dict]):
|
||||
'''更新会话的对话'''
|
||||
|
||||
async def update_conversation(
|
||||
self, unified_msg_origin: str, conversation_id: str, history: List[Dict]
|
||||
):
|
||||
"""更新会话的对话"""
|
||||
if conversation_id:
|
||||
self.db.update_conversation(
|
||||
user_id=unified_msg_origin,
|
||||
cid=conversation_id,
|
||||
history=json.dumps(history)
|
||||
history=json.dumps(history),
|
||||
)
|
||||
|
||||
|
||||
async def update_conversation_title(self, unified_msg_origin: str, title: str):
|
||||
'''更新会话的对话标题'''
|
||||
"""更新会话的对话标题"""
|
||||
conversation_id = self.session_conversations.get(unified_msg_origin)
|
||||
if conversation_id:
|
||||
self.db.update_conversation_title(
|
||||
user_id=unified_msg_origin,
|
||||
cid=conversation_id,
|
||||
title=title
|
||||
user_id=unified_msg_origin, cid=conversation_id, title=title
|
||||
)
|
||||
|
||||
async def update_conversation_persona_id(self, unified_msg_origin: str, persona_id: str):
|
||||
'''更新会话的对话 Persona ID'''
|
||||
|
||||
async def update_conversation_persona_id(
|
||||
self, unified_msg_origin: str, persona_id: str
|
||||
):
|
||||
"""更新会话的对话 Persona ID"""
|
||||
conversation_id = self.session_conversations.get(unified_msg_origin)
|
||||
if conversation_id:
|
||||
self.db.update_conversation_persona_id(
|
||||
user_id=unified_msg_origin,
|
||||
cid=conversation_id,
|
||||
persona_id=persona_id
|
||||
user_id=unified_msg_origin, cid=conversation_id, persona_id=persona_id
|
||||
)
|
||||
|
||||
async def get_human_readable_context(self, unified_msg_origin, conversation_id, page=1, page_size=10):
|
||||
|
||||
async def get_human_readable_context(
|
||||
self, unified_msg_origin, conversation_id, page=1, page_size=10
|
||||
):
|
||||
conversation = await self.get_conversation(unified_msg_origin, conversation_id)
|
||||
history = json.loads(conversation.history)
|
||||
|
||||
contexts = []
|
||||
temp_contexts = []
|
||||
for record in history:
|
||||
if record['role'] == "user":
|
||||
if record["role"] == "user":
|
||||
temp_contexts.append(f"User: {record['content']}")
|
||||
elif record['role'] == "assistant":
|
||||
elif record["role"] == "assistant":
|
||||
temp_contexts.append(f"Assistant: {record['content']}")
|
||||
contexts.insert(0, temp_contexts)
|
||||
temp_contexts = []
|
||||
@@ -110,9 +113,9 @@ class ConversationManager():
|
||||
contexts = [item for sublist in contexts for item in sublist]
|
||||
|
||||
# 计算分页
|
||||
paged_contexts = contexts[(page-1)*page_size:page*page_size]
|
||||
paged_contexts = contexts[(page - 1) * page_size : page * page_size]
|
||||
total_pages = len(contexts) // page_size
|
||||
if len(contexts) % page_size != 0:
|
||||
total_pages += 1
|
||||
|
||||
return paged_contexts, total_pages
|
||||
|
||||
return paged_contexts, total_pages
|
||||
|
||||
@@ -19,103 +19,122 @@ from astrbot.core import logger
|
||||
from astrbot.core.config.default import VERSION
|
||||
from astrbot.core.rag.knowledge_db_mgr import KnowledgeDBManager
|
||||
from astrbot.core.conversation_mgr import ConversationManager
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
from astrbot.core.star.star_handler import star_map
|
||||
|
||||
|
||||
class AstrBotCoreLifecycle:
|
||||
def __init__(self, log_broker: LogBroker, db: BaseDatabase):
|
||||
self.log_broker = log_broker
|
||||
self.astrbot_config = astrbot_config
|
||||
self.db = db
|
||||
|
||||
os.environ['https_proxy'] = self.astrbot_config['http_proxy']
|
||||
os.environ['http_proxy'] = self.astrbot_config['http_proxy']
|
||||
|
||||
|
||||
os.environ["https_proxy"] = self.astrbot_config["http_proxy"]
|
||||
os.environ["http_proxy"] = self.astrbot_config["http_proxy"]
|
||||
os.environ["no_proxy"] = "localhost"
|
||||
|
||||
async def initialize(self):
|
||||
logger.info("AstrBot v"+ VERSION)
|
||||
logger.info("AstrBot v" + VERSION)
|
||||
if os.environ.get("TESTING", ""):
|
||||
logger.setLevel("DEBUG")
|
||||
else:
|
||||
logger.setLevel(self.astrbot_config['log_level'])
|
||||
logger.setLevel(self.astrbot_config["log_level"])
|
||||
self.event_queue = Queue()
|
||||
self.event_queue.closed = False
|
||||
|
||||
|
||||
self.provider_manager = ProviderManager(self.astrbot_config, self.db)
|
||||
|
||||
|
||||
self.platform_manager = PlatformManager(self.astrbot_config, self.event_queue)
|
||||
|
||||
|
||||
self.knowledge_db_manager = KnowledgeDBManager(self.astrbot_config)
|
||||
|
||||
|
||||
self.conversation_manager = ConversationManager(self.db)
|
||||
|
||||
|
||||
self.star_context = Context(
|
||||
self.event_queue,
|
||||
self.astrbot_config,
|
||||
self.event_queue,
|
||||
self.astrbot_config,
|
||||
self.db,
|
||||
self.provider_manager,
|
||||
self.platform_manager,
|
||||
self.conversation_manager,
|
||||
self.knowledge_db_manager
|
||||
self.knowledge_db_manager,
|
||||
)
|
||||
self.plugin_manager = PluginManager(self.star_context, self.astrbot_config)
|
||||
|
||||
await self.plugin_manager.reload()
|
||||
'''扫描、注册插件、实例化插件类'''
|
||||
|
||||
await self.provider_manager.initialize()
|
||||
'''根据配置实例化各个 Provider'''
|
||||
|
||||
await self.platform_manager.initialize()
|
||||
'''根据配置实例化各个平台适配器'''
|
||||
|
||||
self.pipeline_scheduler = PipelineScheduler(PipelineContext(self.astrbot_config, self.plugin_manager))
|
||||
await self.plugin_manager.reload()
|
||||
"""扫描、注册插件、实例化插件类"""
|
||||
|
||||
await self.provider_manager.initialize()
|
||||
"""根据配置实例化各个 Provider"""
|
||||
|
||||
self.pipeline_scheduler = PipelineScheduler(
|
||||
PipelineContext(self.astrbot_config, self.plugin_manager)
|
||||
)
|
||||
await self.pipeline_scheduler.initialize()
|
||||
'''初始化消息事件流水线调度器'''
|
||||
|
||||
self.astrbot_updator = AstrBotUpdator(self.astrbot_config['plugin_repo_mirror'])
|
||||
"""初始化消息事件流水线调度器"""
|
||||
|
||||
self.astrbot_updator = AstrBotUpdator(self.astrbot_config["plugin_repo_mirror"])
|
||||
self.event_bus = EventBus(self.event_queue, self.pipeline_scheduler)
|
||||
self.start_time = int(time.time())
|
||||
self.curr_tasks: List[asyncio.Task] = []
|
||||
|
||||
def _load(self):
|
||||
await self.platform_manager.initialize()
|
||||
"""根据配置实例化各个平台适配器"""
|
||||
|
||||
def _load(self):
|
||||
event_bus_task = asyncio.create_task(
|
||||
self.event_bus.dispatch(), name="event_bus"
|
||||
)
|
||||
|
||||
platform_tasks = self.load_platform()
|
||||
event_bus_task = asyncio.create_task(self.event_bus.dispatch(), name="event_bus")
|
||||
|
||||
extra_tasks = []
|
||||
for task in self.star_context._register_tasks:
|
||||
extra_tasks.append(asyncio.create_task(task, name=task.__name__))
|
||||
|
||||
# self.curr_tasks = [event_bus_task, *platform_tasks, *extra_tasks]
|
||||
|
||||
tasks_ = [event_bus_task, *platform_tasks, *extra_tasks]
|
||||
|
||||
tasks_ = [event_bus_task, *extra_tasks]
|
||||
for task in tasks_:
|
||||
self.curr_tasks.append(asyncio.create_task(self._task_wrapper(task), name=task.get_name()))
|
||||
|
||||
self.curr_tasks.append(
|
||||
asyncio.create_task(self._task_wrapper(task), name=task.get_name())
|
||||
)
|
||||
|
||||
self.start_time = int(time.time())
|
||||
|
||||
|
||||
async def _task_wrapper(self, task: asyncio.Task):
|
||||
try:
|
||||
await task
|
||||
except asyncio.CancelledError:
|
||||
pass
|
||||
except Exception as e:
|
||||
|
||||
logger.error(f"------- 任务 {task.get_name()} 发生错误: {e}")
|
||||
for line in traceback.format_exc().split("\n"):
|
||||
logger.error(f"| {line}")
|
||||
logger.error("-------")
|
||||
|
||||
|
||||
async def start(self):
|
||||
self._load()
|
||||
logger.info("AstrBot 启动完成。")
|
||||
|
||||
|
||||
# 执行启动完成事件钩子
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(
|
||||
EventType.OnAstrBotLoadedEvent
|
||||
)
|
||||
for handler in handlers:
|
||||
try:
|
||||
logger.info(
|
||||
f"hook(on_astrbot_loaded) -> {star_map[handler.handler_module_path].name} - {handler.handler_name}"
|
||||
)
|
||||
await handler.handler()
|
||||
except BaseException:
|
||||
logger.error(traceback.format_exc())
|
||||
|
||||
await asyncio.gather(*self.curr_tasks, return_exceptions=True)
|
||||
|
||||
|
||||
async def stop(self):
|
||||
self.event_queue.closed = True
|
||||
for task in self.curr_tasks:
|
||||
task.cancel()
|
||||
|
||||
|
||||
await self.provider_manager.terminate()
|
||||
|
||||
|
||||
for task in self.curr_tasks:
|
||||
try:
|
||||
await task
|
||||
@@ -123,14 +142,18 @@ class AstrBotCoreLifecycle:
|
||||
pass
|
||||
except Exception as e:
|
||||
logger.error(f"任务 {task.get_name()} 发生错误: {e}")
|
||||
|
||||
|
||||
def restart(self):
|
||||
self.event_queue.closed = True
|
||||
threading.Thread(target=self.astrbot_updator._reboot, name="restart", daemon=True).start()
|
||||
|
||||
threading.Thread(
|
||||
target=self.astrbot_updator._reboot, name="restart", daemon=True
|
||||
).start()
|
||||
|
||||
def load_platform(self) -> List[asyncio.Task]:
|
||||
tasks = []
|
||||
platform_insts = self.platform_manager.get_insts()
|
||||
for platform_inst in platform_insts:
|
||||
tasks.append(asyncio.create_task(platform_inst.run(), name=platform_inst.meta().name))
|
||||
return tasks
|
||||
tasks.append(
|
||||
asyncio.create_task(platform_inst.run(), name=platform_inst.meta().name)
|
||||
)
|
||||
return tasks
|
||||
|
||||
@@ -3,111 +3,117 @@ from dataclasses import dataclass
|
||||
from typing import List
|
||||
from astrbot.core.db.po import Stats, LLMHistory, ATRIVision, Conversation
|
||||
|
||||
|
||||
@dataclass
|
||||
class BaseDatabase(abc.ABC):
|
||||
'''
|
||||
"""
|
||||
数据库基类
|
||||
'''
|
||||
"""
|
||||
|
||||
def __init__(self) -> None:
|
||||
pass
|
||||
|
||||
|
||||
def insert_base_metrics(self, metrics: dict):
|
||||
'''插入基础指标数据'''
|
||||
self.insert_platform_metrics(metrics['platform_stats'])
|
||||
self.insert_plugin_metrics(metrics['plugin_stats'])
|
||||
self.insert_command_metrics(metrics['command_stats'])
|
||||
self.insert_llm_metrics(metrics['llm_stats'])
|
||||
|
||||
"""插入基础指标数据"""
|
||||
self.insert_platform_metrics(metrics["platform_stats"])
|
||||
self.insert_plugin_metrics(metrics["plugin_stats"])
|
||||
self.insert_command_metrics(metrics["command_stats"])
|
||||
self.insert_llm_metrics(metrics["llm_stats"])
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_platform_metrics(self, metrics: dict):
|
||||
'''插入平台指标数据'''
|
||||
"""插入平台指标数据"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_plugin_metrics(self, metrics: dict):
|
||||
'''插入插件指标数据'''
|
||||
"""插入插件指标数据"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_command_metrics(self, metrics: dict):
|
||||
'''插入指令指标数据'''
|
||||
"""插入指令指标数据"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_llm_metrics(self, metrics: dict):
|
||||
'''插入 LLM 指标数据'''
|
||||
"""插入 LLM 指标数据"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def update_llm_history(self, session_id: str, content: str, provider_type: str):
|
||||
'''更新 LLM 历史记录。当不存在 session_id 时插入'''
|
||||
"""更新 LLM 历史记录。当不存在 session_id 时插入"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_llm_history(self, session_id: str = None, provider_type: str = None) -> List[LLMHistory]:
|
||||
'''获取 LLM 历史记录, 如果 session_id 为 None, 返回所有'''
|
||||
def get_llm_history(
|
||||
self, session_id: str = None, provider_type: str = None
|
||||
) -> List[LLMHistory]:
|
||||
"""获取 LLM 历史记录, 如果 session_id 为 None, 返回所有"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_base_stats(self, offset_sec: int = 86400) -> Stats:
|
||||
'''获取基础统计数据'''
|
||||
"""获取基础统计数据"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_total_message_count(self) -> int:
|
||||
'''获取总消息数'''
|
||||
"""获取总消息数"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_grouped_base_stats(self, offset_sec: int = 86400) -> Stats:
|
||||
'''获取基础统计数据(合并)'''
|
||||
"""获取基础统计数据(合并)"""
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def insert_atri_vision_data(self, vision_data: ATRIVision):
|
||||
'''插入 ATRI 视觉数据'''
|
||||
"""插入 ATRI 视觉数据"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_atri_vision_data(self) -> List[ATRIVision]:
|
||||
'''获取 ATRI 视觉数据'''
|
||||
"""获取 ATRI 视觉数据"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_atri_vision_data_by_path_or_id(self, url_or_path: str, id: str) -> ATRIVision:
|
||||
'''通过 url 或 path 获取 ATRI 视觉数据'''
|
||||
def get_atri_vision_data_by_path_or_id(
|
||||
self, url_or_path: str, id: str
|
||||
) -> ATRIVision:
|
||||
"""通过 url 或 path 获取 ATRI 视觉数据"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_conversation_by_user_id(self, user_id: str, cid: str) -> Conversation:
|
||||
'''通过 user_id 和 cid 获取 Conversation'''
|
||||
"""通过 user_id 和 cid 获取 Conversation"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def new_conversation(self, user_id: str, cid: str):
|
||||
'''新建 Conversation'''
|
||||
"""新建 Conversation"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_conversations(self, user_id: str) -> List[Conversation]:
|
||||
raise NotImplementedError
|
||||
|
||||
@abc.abstractmethod
|
||||
def update_conversation(self, user_id: str, cid: str, history: str):
|
||||
'''更新 Conversation'''
|
||||
"""更新 Conversation"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def delete_conversation(self, user_id: str, cid: str):
|
||||
'''删除 Conversation'''
|
||||
"""删除 Conversation"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def update_conversation_title(self, user_id: str, cid: str, title: str):
|
||||
'''更新 Conversation 标题'''
|
||||
"""更新 Conversation 标题"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def update_conversation_persona_id(self, user_id: str, cid: str, persona_id: str):
|
||||
'''更新 Conversation Persona ID'''
|
||||
raise NotImplementedError
|
||||
"""更新 Conversation Persona ID"""
|
||||
raise NotImplementedError
|
||||
|
||||
@@ -1,48 +1,57 @@
|
||||
'''指标数据'''
|
||||
"""指标数据"""
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import List
|
||||
|
||||
|
||||
@dataclass
|
||||
class Platform():
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
@dataclass
|
||||
class Provider():
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
@dataclass
|
||||
class Plugin():
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
@dataclass
|
||||
class Command():
|
||||
class Platform:
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
|
||||
@dataclass
|
||||
class Stats():
|
||||
class Provider:
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
|
||||
@dataclass
|
||||
class Plugin:
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
|
||||
@dataclass
|
||||
class Command:
|
||||
name: str
|
||||
count: int
|
||||
timestamp: int
|
||||
|
||||
|
||||
@dataclass
|
||||
class Stats:
|
||||
platform: List[Platform] = field(default_factory=list)
|
||||
command: List[Command] = field(default_factory=list)
|
||||
llm: List[Provider] = field(default_factory=list)
|
||||
|
||||
|
||||
|
||||
@dataclass
|
||||
class LLMHistory():
|
||||
'''LLM 聊天时持久化的信息'''
|
||||
class LLMHistory:
|
||||
"""LLM 聊天时持久化的信息"""
|
||||
|
||||
provider_type: str
|
||||
session_id: str
|
||||
content: str
|
||||
|
||||
|
||||
|
||||
@dataclass
|
||||
class ATRIVision():
|
||||
'''Deprecated'''
|
||||
class ATRIVision:
|
||||
"""Deprecated"""
|
||||
|
||||
id: str
|
||||
url_or_path: str
|
||||
caption: str
|
||||
@@ -52,19 +61,21 @@ class ATRIVision():
|
||||
session_id: str
|
||||
sender_nickname: str
|
||||
timestamp: int = -1
|
||||
|
||||
|
||||
|
||||
@dataclass
|
||||
class Conversation():
|
||||
'''LLM 对话存储
|
||||
|
||||
class Conversation:
|
||||
"""LLM 对话存储
|
||||
|
||||
对于网页聊天,history 存储了包括指令、回复、图片等在内的所有消息。
|
||||
对于其他平台的聊天,不存储非 LLM 的回复(因为考虑到已经存储在各自的平台上)。
|
||||
'''
|
||||
"""
|
||||
|
||||
user_id: str
|
||||
cid: str
|
||||
history: str = ""
|
||||
'''字符串格式的列表。'''
|
||||
"""字符串格式的列表。"""
|
||||
created_at: int = 0
|
||||
updated_at: int = 0
|
||||
title: str = ""
|
||||
persona_id: str = ""
|
||||
persona_id: str = ""
|
||||
|
||||
@@ -1,13 +1,7 @@
|
||||
import sqlite3
|
||||
import os
|
||||
import time
|
||||
from astrbot.core.db.po import (
|
||||
Platform,
|
||||
Stats,
|
||||
LLMHistory,
|
||||
ATRIVision,
|
||||
Conversation
|
||||
)
|
||||
from astrbot.core.db.po import Platform, Stats, LLMHistory, ATRIVision, Conversation
|
||||
from . import BaseDatabase
|
||||
from typing import Tuple
|
||||
|
||||
@@ -16,21 +10,21 @@ class SQLiteDatabase(BaseDatabase):
|
||||
def __init__(self, db_path: str) -> None:
|
||||
super().__init__()
|
||||
self.db_path = db_path
|
||||
|
||||
|
||||
with open(os.path.dirname(__file__) + "/sqlite_init.sql", "r") as f:
|
||||
sql = f.read()
|
||||
|
||||
|
||||
# 初始化数据库
|
||||
self.conn = self._get_conn(self.db_path)
|
||||
c = self.conn.cursor()
|
||||
c.executescript(sql)
|
||||
self.conn.commit()
|
||||
|
||||
|
||||
# 检查 webchat_conversation 的 title 字段是否存在
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
PRAGMA table_info(webchat_conversation)
|
||||
'''
|
||||
"""
|
||||
)
|
||||
res = c.fetchall()
|
||||
has_title = False
|
||||
@@ -42,26 +36,26 @@ class SQLiteDatabase(BaseDatabase):
|
||||
has_persona_id = True
|
||||
if not has_title:
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
ALTER TABLE webchat_conversation ADD COLUMN title TEXT;
|
||||
'''
|
||||
"""
|
||||
)
|
||||
self.conn.commit()
|
||||
if not has_persona_id:
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
ALTER TABLE webchat_conversation ADD COLUMN persona_id TEXT;
|
||||
'''
|
||||
"""
|
||||
)
|
||||
self.conn.commit()
|
||||
|
||||
|
||||
c.close()
|
||||
|
||||
|
||||
def _get_conn(self, db_path: str) -> sqlite3.Connection:
|
||||
conn = sqlite3.connect(self.db_path)
|
||||
conn.text_factory = str
|
||||
return conn
|
||||
|
||||
|
||||
def _exec_sql(self, sql: str, params: Tuple = None):
|
||||
conn = self.conn
|
||||
try:
|
||||
@@ -69,22 +63,23 @@ class SQLiteDatabase(BaseDatabase):
|
||||
except sqlite3.ProgrammingError:
|
||||
conn = self._get_conn(self.db_path)
|
||||
c = conn.cursor()
|
||||
|
||||
|
||||
if params:
|
||||
c.execute(sql, params)
|
||||
c.close()
|
||||
else:
|
||||
c.execute(sql)
|
||||
c.close()
|
||||
|
||||
|
||||
conn.commit()
|
||||
|
||||
|
||||
def insert_platform_metrics(self, metrics: dict):
|
||||
for k, v in metrics.items():
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
INSERT INTO platform(name, count, timestamp) VALUES (?, ?, ?)
|
||||
''', (k, v, int(time.time()))
|
||||
""",
|
||||
(k, v, int(time.time())),
|
||||
)
|
||||
|
||||
def insert_plugin_metrics(self, metrics: dict):
|
||||
@@ -93,40 +88,46 @@ class SQLiteDatabase(BaseDatabase):
|
||||
def insert_command_metrics(self, metrics: dict):
|
||||
for k, v in metrics.items():
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
INSERT INTO command(name, count, timestamp) VALUES (?, ?, ?)
|
||||
''', (k, v, int(time.time()))
|
||||
""",
|
||||
(k, v, int(time.time())),
|
||||
)
|
||||
|
||||
def insert_llm_metrics(self, metrics: dict):
|
||||
for k, v in metrics.items():
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
INSERT INTO llm(name, count, timestamp) VALUES (?, ?, ?)
|
||||
''', (k, v, int(time.time()))
|
||||
""",
|
||||
(k, v, int(time.time())),
|
||||
)
|
||||
|
||||
def update_llm_history(self, session_id: str, content: str, provider_type: str):
|
||||
res = self.get_llm_history(session_id, provider_type)
|
||||
if res:
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
UPDATE llm_history SET content = ? WHERE session_id = ? AND provider_type = ?
|
||||
''', (content, session_id, provider_type)
|
||||
""",
|
||||
(content, session_id, provider_type),
|
||||
)
|
||||
else:
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
INSERT INTO llm_history(provider_type, session_id, content) VALUES (?, ?, ?)
|
||||
''', (provider_type, session_id, content)
|
||||
""",
|
||||
(provider_type, session_id, content),
|
||||
)
|
||||
|
||||
def get_llm_history(self, session_id: str = None, provider_type: str = None) -> Tuple:
|
||||
def get_llm_history(
|
||||
self, session_id: str = None, provider_type: str = None
|
||||
) -> Tuple:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
|
||||
where_clause = ""
|
||||
if session_id or provider_type:
|
||||
where_clause += " WHERE "
|
||||
@@ -138,11 +139,12 @@ class SQLiteDatabase(BaseDatabase):
|
||||
if has:
|
||||
where_clause += " AND "
|
||||
where_clause += f"provider_type = '{provider_type}'"
|
||||
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
SELECT * FROM llm_history
|
||||
''' + where_clause
|
||||
"""
|
||||
+ where_clause
|
||||
)
|
||||
res = c.fetchall()
|
||||
histories = []
|
||||
@@ -152,125 +154,134 @@ class SQLiteDatabase(BaseDatabase):
|
||||
return histories
|
||||
|
||||
def get_base_stats(self, offset_sec: int = 86400) -> Stats:
|
||||
'''获取 offset_sec 秒前到现在的基础统计数据'''
|
||||
"""获取 offset_sec 秒前到现在的基础统计数据"""
|
||||
where_clause = f" WHERE timestamp >= {int(time.time()) - offset_sec}"
|
||||
|
||||
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
SELECT * FROM platform
|
||||
''' + where_clause
|
||||
"""
|
||||
+ where_clause
|
||||
)
|
||||
|
||||
|
||||
platform = []
|
||||
for row in c.fetchall():
|
||||
platform.append(Platform(*row))
|
||||
|
||||
|
||||
# c.execute(
|
||||
# '''
|
||||
# SELECT * FROM command
|
||||
# ''' + where_clause
|
||||
# )
|
||||
|
||||
|
||||
# command = []
|
||||
# for row in c.fetchall():
|
||||
# command.append(Command(*row))
|
||||
|
||||
|
||||
# c.execute(
|
||||
# '''
|
||||
# SELECT * FROM llm
|
||||
# ''' + where_clause
|
||||
# )
|
||||
|
||||
|
||||
# llm = []
|
||||
# for row in c.fetchall():
|
||||
# llm.append(Provider(*row))
|
||||
|
||||
|
||||
c.close()
|
||||
|
||||
|
||||
return Stats(platform, [], [])
|
||||
|
||||
|
||||
def get_total_message_count(self) -> int:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
SELECT SUM(count) FROM platform
|
||||
'''
|
||||
"""
|
||||
)
|
||||
res = c.fetchone()
|
||||
c.close()
|
||||
return res[0]
|
||||
|
||||
|
||||
def get_grouped_base_stats(self, offset_sec: int = 86400) -> Stats:
|
||||
'''获取 offset_sec 秒前到现在的基础统计数据(合并)'''
|
||||
"""获取 offset_sec 秒前到现在的基础统计数据(合并)"""
|
||||
where_clause = f" WHERE timestamp >= {int(time.time()) - offset_sec}"
|
||||
|
||||
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
SELECT name, SUM(count), timestamp FROM platform
|
||||
''' + where_clause + " GROUP BY name"
|
||||
"""
|
||||
+ where_clause
|
||||
+ " GROUP BY name"
|
||||
)
|
||||
|
||||
|
||||
platform = []
|
||||
for row in c.fetchall():
|
||||
platform.append(Platform(*row))
|
||||
|
||||
|
||||
c.close()
|
||||
|
||||
|
||||
return Stats(platform, [], [])
|
||||
|
||||
|
||||
|
||||
def get_conversation_by_user_id(self, user_id: str, cid: str) -> Conversation:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
SELECT * FROM webchat_conversation WHERE user_id = ? AND cid = ?
|
||||
''', (user_id, cid)
|
||||
""",
|
||||
(user_id, cid),
|
||||
)
|
||||
|
||||
|
||||
res = c.fetchone()
|
||||
c.close()
|
||||
|
||||
if not res:
|
||||
return
|
||||
|
||||
return Conversation(*res)
|
||||
|
||||
|
||||
def new_conversation(self, user_id: str, cid: str):
|
||||
history = "[]"
|
||||
updated_at = int(time.time())
|
||||
created_at = updated_at
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
INSERT INTO webchat_conversation(user_id, cid, history, updated_at, created_at) VALUES (?, ?, ?, ?, ?)
|
||||
''', (user_id, cid, history, updated_at, created_at)
|
||||
""",
|
||||
(user_id, cid, history, updated_at, created_at),
|
||||
)
|
||||
|
||||
|
||||
def get_conversations(self, user_id: str) -> Tuple:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
SELECT cid, created_at, updated_at, title, persona_id FROM webchat_conversation WHERE user_id = ? ORDER BY updated_at DESC
|
||||
''', (user_id,)
|
||||
""",
|
||||
(user_id,),
|
||||
)
|
||||
|
||||
|
||||
res = c.fetchall()
|
||||
c.close()
|
||||
conversations = []
|
||||
@@ -280,82 +291,101 @@ class SQLiteDatabase(BaseDatabase):
|
||||
updated_at = row[2]
|
||||
title = row[3]
|
||||
persona_id = row[4]
|
||||
conversations.append(Conversation("", cid, '[]', created_at, updated_at, title, persona_id))
|
||||
conversations.append(
|
||||
Conversation("", cid, "[]", created_at, updated_at, title, persona_id)
|
||||
)
|
||||
return conversations
|
||||
|
||||
|
||||
def update_conversation(self, user_id: str, cid: str, history: str):
|
||||
'''更新对话,并且同时更新时间'''
|
||||
"""更新对话,并且同时更新时间"""
|
||||
updated_at = int(time.time())
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
UPDATE webchat_conversation SET history = ?, updated_at = ? WHERE user_id = ? AND cid = ?
|
||||
''', (history, updated_at, user_id, cid)
|
||||
""",
|
||||
(history, updated_at, user_id, cid),
|
||||
)
|
||||
|
||||
|
||||
|
||||
def update_conversation_title(self, user_id: str, cid: str, title: str):
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
UPDATE webchat_conversation SET title = ? WHERE user_id = ? AND cid = ?
|
||||
''', (title, user_id, cid)
|
||||
""",
|
||||
(title, user_id, cid),
|
||||
)
|
||||
|
||||
|
||||
def update_conversation_persona_id(self, user_id: str, cid: str, persona_id: str):
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
UPDATE webchat_conversation SET persona_id = ? WHERE user_id = ? AND cid = ?
|
||||
''', (persona_id, user_id, cid)
|
||||
""",
|
||||
(persona_id, user_id, cid),
|
||||
)
|
||||
|
||||
|
||||
def delete_conversation(self, user_id: str, cid: str):
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
DELETE FROM webchat_conversation WHERE user_id = ? AND cid = ?
|
||||
''', (user_id, cid)
|
||||
""",
|
||||
(user_id, cid),
|
||||
)
|
||||
|
||||
def insert_atri_vision_data(self, vision: ATRIVision):
|
||||
ts = int(time.time())
|
||||
keywords = ",".join(vision.keywords)
|
||||
self._exec_sql(
|
||||
'''
|
||||
"""
|
||||
INSERT INTO atri_vision(id, url_or_path, caption, is_meme, keywords, platform_name, session_id, sender_nickname, timestamp) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
|
||||
''', (vision.id, vision.url_or_path, vision.caption, vision.is_meme, keywords, vision.platform_name, vision.session_id, vision.sender_nickname, ts)
|
||||
""",
|
||||
(
|
||||
vision.id,
|
||||
vision.url_or_path,
|
||||
vision.caption,
|
||||
vision.is_meme,
|
||||
keywords,
|
||||
vision.platform_name,
|
||||
vision.session_id,
|
||||
vision.sender_nickname,
|
||||
ts,
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
def get_atri_vision_data(self) -> Tuple:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
SELECT * FROM atri_vision
|
||||
'''
|
||||
"""
|
||||
)
|
||||
|
||||
|
||||
res = c.fetchall()
|
||||
visions = []
|
||||
for row in res:
|
||||
visions.append(ATRIVision(*row))
|
||||
c.close()
|
||||
return visions
|
||||
|
||||
def get_atri_vision_data_by_path_or_id(self, url_or_path: str, id: str) -> ATRIVision:
|
||||
|
||||
def get_atri_vision_data_by_path_or_id(
|
||||
self, url_or_path: str, id: str
|
||||
) -> ATRIVision:
|
||||
try:
|
||||
c = self.conn.cursor()
|
||||
except sqlite3.ProgrammingError:
|
||||
c = self._get_conn(self.db_path).cursor()
|
||||
|
||||
|
||||
c.execute(
|
||||
'''
|
||||
"""
|
||||
SELECT * FROM atri_vision WHERE url_or_path = ? OR id = ?
|
||||
''', (url_or_path, id)
|
||||
""",
|
||||
(url_or_path, id),
|
||||
)
|
||||
|
||||
|
||||
res = c.fetchone()
|
||||
c.close()
|
||||
if res:
|
||||
return ATRIVision(*res)
|
||||
return None
|
||||
return None
|
||||
|
||||
@@ -4,20 +4,24 @@ from astrbot.core.pipeline.scheduler import PipelineScheduler
|
||||
from astrbot.core import logger
|
||||
from .platform import AstrMessageEvent
|
||||
|
||||
|
||||
class EventBus:
|
||||
def __init__(self, event_queue: Queue, pipeline_scheduler: PipelineScheduler):
|
||||
self.event_queue = event_queue
|
||||
self.pipeline_scheduler = pipeline_scheduler
|
||||
|
||||
async def dispatch(self):
|
||||
logger.info("事件总线已打开。")
|
||||
while True:
|
||||
event: AstrMessageEvent = await self.event_queue.get()
|
||||
self._print_event(event)
|
||||
asyncio.create_task(self.pipeline_scheduler.execute(event))
|
||||
|
||||
def _print_event(self, event: AstrMessageEvent):
|
||||
|
||||
def _print_event(self, event: AstrMessageEvent):
|
||||
if event.get_sender_name():
|
||||
logger.info(f"[{event.get_platform_name()}] {event.get_sender_name()}/{event.get_sender_id()}: {event.get_message_outline()}")
|
||||
logger.info(
|
||||
f"[{event.get_platform_name()}] {event.get_sender_name()}/{event.get_sender_id()}: {event.get_message_outline()}"
|
||||
)
|
||||
else:
|
||||
logger.info(f"[{event.get_platform_name()}] {event.get_sender_id()}: {event.get_message_outline()}")
|
||||
logger.info(
|
||||
f"[{event.get_platform_name()}] {event.get_sender_id()}: {event.get_message_outline()}"
|
||||
)
|
||||
|
||||
@@ -7,31 +7,35 @@ from typing import List
|
||||
|
||||
CACHED_SIZE = 200
|
||||
log_color_config = {
|
||||
'DEBUG': 'bold_blue', 'INFO': 'bold_cyan',
|
||||
'WARNING': 'bold_yellow', 'ERROR': 'red',
|
||||
'CRITICAL': 'bold_red', 'RESET': 'reset',
|
||||
'asctime': 'green'
|
||||
"DEBUG": "green",
|
||||
"INFO": "bold_cyan",
|
||||
"WARNING": "bold_yellow",
|
||||
"ERROR": "red",
|
||||
"CRITICAL": "bold_red",
|
||||
"RESET": "reset",
|
||||
"asctime": "green",
|
||||
}
|
||||
|
||||
|
||||
class LogBroker:
|
||||
def __init__(self):
|
||||
self.log_cache = deque(maxlen=CACHED_SIZE)
|
||||
self.subscribers: List[Queue] = []
|
||||
|
||||
|
||||
def register(self) -> Queue:
|
||||
'''给每个订阅者返回一个带有日志缓存的队列'''
|
||||
"""给每个订阅者返回一个带有日志缓存的队列"""
|
||||
q = Queue(maxsize=CACHED_SIZE + 10)
|
||||
for log in self.log_cache:
|
||||
q.put_nowait(log)
|
||||
self.subscribers.append(q)
|
||||
return q
|
||||
|
||||
|
||||
def unregister(self, q: Queue):
|
||||
'''取消订阅'''
|
||||
"""取消订阅"""
|
||||
self.subscribers.remove(q)
|
||||
|
||||
|
||||
def publish(self, log_entry: str):
|
||||
'''发布消息'''
|
||||
"""发布消息"""
|
||||
self.log_cache.append(log_entry)
|
||||
for q in self.subscribers:
|
||||
try:
|
||||
@@ -39,6 +43,7 @@ class LogBroker:
|
||||
except asyncio.QueueFull:
|
||||
pass
|
||||
|
||||
|
||||
class LogQueueHandler(logging.Handler):
|
||||
def __init__(self, log_broker: LogBroker):
|
||||
super().__init__()
|
||||
@@ -48,26 +53,26 @@ class LogQueueHandler(logging.Handler):
|
||||
log_entry = self.format(record)
|
||||
self.log_broker.publish(log_entry)
|
||||
|
||||
class LogManager:
|
||||
|
||||
class LogManager:
|
||||
@classmethod
|
||||
def GetLogger(cls, log_name: str = 'default'):
|
||||
def GetLogger(cls, log_name: str = "default"):
|
||||
logger = logging.getLogger(log_name)
|
||||
if logger.hasHandlers():
|
||||
return logger
|
||||
console_handler = logging.StreamHandler()
|
||||
console_handler.setLevel(logging.DEBUG)
|
||||
console_formatter = colorlog.ColoredFormatter(
|
||||
fmt='%(log_color)s [%(asctime)s| %(levelname)s] [%(filename)s:%(lineno)d]: %(message)s %(reset)s',
|
||||
datefmt='%H:%M:%S',
|
||||
log_colors=log_color_config
|
||||
fmt="%(log_color)s [%(asctime)s] [%(levelname)-5s] [%(filename)s:%(lineno)d]: %(message)s %(reset)s",
|
||||
datefmt="%H:%M:%S",
|
||||
log_colors=log_color_config,
|
||||
)
|
||||
console_handler.setFormatter(console_formatter)
|
||||
logger.setLevel(logging.DEBUG)
|
||||
logger.addHandler(console_handler)
|
||||
|
||||
|
||||
return logger
|
||||
|
||||
|
||||
@classmethod
|
||||
def set_queue_handler(cls, logger: logging.Logger, log_broker: LogBroker):
|
||||
handler = LogQueueHandler(log_broker)
|
||||
@@ -75,5 +80,9 @@ class LogManager:
|
||||
if logger.handlers:
|
||||
handler.setFormatter(logger.handlers[0].formatter)
|
||||
else:
|
||||
handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
|
||||
logger.addHandler(handler)
|
||||
handler.setFormatter(
|
||||
logging.Formatter(
|
||||
"%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||
)
|
||||
)
|
||||
logger.addHandler(handler)
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
'''
|
||||
"""
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2021 Lxns-Network
|
||||
@@ -20,7 +20,7 @@ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
'''
|
||||
"""
|
||||
|
||||
import base64
|
||||
import json
|
||||
@@ -29,12 +29,21 @@ import typing as T
|
||||
from enum import Enum
|
||||
from pydantic.v1 import BaseModel
|
||||
|
||||
|
||||
class ComponentType(Enum):
|
||||
Plain = "Plain"
|
||||
Face = "Face"
|
||||
Record = "Record"
|
||||
Video = "Video"
|
||||
At = "At"
|
||||
Plain = "Plain" # 纯文本消息
|
||||
Face = "Face" # QQ表情
|
||||
Record = "Record" # 语音
|
||||
Video = "Video" # 视频
|
||||
At = "At" # At
|
||||
Node = "Node" # 转发消息的一个节点
|
||||
Nodes = "Nodes" # 转发消息的多个节点
|
||||
Poke = "Poke" # QQ 戳一戳
|
||||
Image = "Image" # 图片
|
||||
Reply = "Reply" # 回复
|
||||
Forward = "Forward" # 转发消息
|
||||
File = "File" # 文件
|
||||
|
||||
RPS = "RPS" # TODO
|
||||
Dice = "Dice" # TODO
|
||||
Shake = "Shake" # TODO
|
||||
@@ -43,18 +52,12 @@ class ComponentType(Enum):
|
||||
Contact = "Contact" # TODO
|
||||
Location = "Location" # TODO
|
||||
Music = "Music"
|
||||
Image = "Image"
|
||||
Reply = "Reply"
|
||||
RedBag = "RedBag"
|
||||
Poke = "Poke"
|
||||
Forward = "Forward"
|
||||
Node = "Node"
|
||||
Xml = "Xml"
|
||||
Json = "Json"
|
||||
CardImage = "CardImage"
|
||||
TTS = "TTS"
|
||||
Unknown = "Unknown"
|
||||
File = "File"
|
||||
|
||||
|
||||
class BaseMessageComponent(BaseModel):
|
||||
@@ -69,25 +72,26 @@ class BaseMessageComponent(BaseModel):
|
||||
k = "type"
|
||||
if isinstance(v, bool):
|
||||
v = 1 if v else 0
|
||||
output += ",%s=%s" % (k, str(v).replace("&", "&") \
|
||||
.replace(",", ",") \
|
||||
.replace("[", "[") \
|
||||
.replace("]", "]"))
|
||||
output += ",%s=%s" % (
|
||||
k,
|
||||
str(v)
|
||||
.replace("&", "&")
|
||||
.replace(",", ",")
|
||||
.replace("[", "[")
|
||||
.replace("]", "]"),
|
||||
)
|
||||
output += "]"
|
||||
return output
|
||||
|
||||
def toDict(self):
|
||||
data = dict()
|
||||
data = {}
|
||||
for k, v in self.__dict__.items():
|
||||
if k == "type" or v is None:
|
||||
continue
|
||||
if k == "_type":
|
||||
k = "type"
|
||||
data[k] = v
|
||||
return {
|
||||
"type": self.type.lower(),
|
||||
"data": data
|
||||
}
|
||||
return {"type": self.type.lower(), "data": data}
|
||||
|
||||
|
||||
class Plain(BaseMessageComponent):
|
||||
@@ -101,9 +105,9 @@ class Plain(BaseMessageComponent):
|
||||
def toString(self): # 没有 [CQ:plain] 这种东西,所以直接导出纯文本
|
||||
if not self.convert:
|
||||
return self.text
|
||||
return self.text.replace("&", "&") \
|
||||
.replace("[", "[") \
|
||||
.replace("]", "]")
|
||||
return (
|
||||
self.text.replace("&", "&").replace("[", "[").replace("]", "]")
|
||||
)
|
||||
|
||||
|
||||
class Face(BaseMessageComponent):
|
||||
@@ -272,7 +276,7 @@ class Image(BaseMessageComponent):
|
||||
c: T.Optional[int] = 2
|
||||
# 额外
|
||||
path: T.Optional[str] = ""
|
||||
file_unique: T.Optional[str] = "" # 某些平台可能有图片缓存的唯一标识
|
||||
file_unique: T.Optional[str] = "" # 某些平台可能有图片缓存的唯一标识
|
||||
|
||||
def __init__(self, file: T.Optional[str], **_):
|
||||
# for k in _.keys():
|
||||
@@ -341,14 +345,16 @@ class Forward(BaseMessageComponent):
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
|
||||
class Node(BaseMessageComponent):
|
||||
'''群合并转发消息'''
|
||||
"""群合并转发消息"""
|
||||
|
||||
type: ComponentType = "Node"
|
||||
id: T.Optional[int] = 0 # 忽略
|
||||
name: T.Optional[str] = "" # qq昵称
|
||||
uin: T.Optional[int] = 0 # qq号
|
||||
content: T.Optional[T.Union[str, list]] = "" # 子消息段列表
|
||||
seq: T.Optional[T.Union[str, list]] = "" # 忽略
|
||||
id: T.Optional[int] = 0 # 忽略
|
||||
name: T.Optional[str] = "" # qq昵称
|
||||
uin: T.Optional[int] = 0 # qq号
|
||||
content: T.Optional[T.Union[str, list]] = "" # 子消息段列表
|
||||
seq: T.Optional[T.Union[str, list]] = "" # 忽略
|
||||
time: T.Optional[int] = 0
|
||||
|
||||
def __init__(self, content: T.Union[str, list], **_):
|
||||
@@ -364,11 +370,22 @@ class Node(BaseMessageComponent):
|
||||
return ""
|
||||
|
||||
|
||||
class Nodes(BaseMessageComponent):
|
||||
type: ComponentType = "Nodes"
|
||||
nodes: T.List[Node]
|
||||
|
||||
def __init__(self, nodes: T.List[Node], **_):
|
||||
super().__init__(nodes=nodes, **_)
|
||||
|
||||
def toDict(self):
|
||||
return {"messages": [node.toDict() for node in self.nodes]}
|
||||
|
||||
|
||||
class Xml(BaseMessageComponent):
|
||||
type: ComponentType = "Xml"
|
||||
data: str
|
||||
resid: T.Optional[int] = 0
|
||||
|
||||
|
||||
def __init__(self, **_):
|
||||
super().__init__(**_)
|
||||
|
||||
@@ -418,14 +435,16 @@ class Unknown(BaseMessageComponent):
|
||||
def toString(self):
|
||||
return ""
|
||||
|
||||
|
||||
class File(BaseMessageComponent):
|
||||
'''
|
||||
"""
|
||||
目前此消息段只适配了 Napcat。
|
||||
'''
|
||||
"""
|
||||
|
||||
type: ComponentType = "File"
|
||||
name: T.Optional[str] = "" # 名字
|
||||
file: T.Optional[str] = "" # url(本地路径)
|
||||
|
||||
name: T.Optional[str] = "" # 名字
|
||||
file: T.Optional[str] = "" # url(本地路径)
|
||||
|
||||
def __init__(self, name: str, file: str):
|
||||
super().__init__(name=name, file=file)
|
||||
|
||||
@@ -451,10 +470,11 @@ ComponentTypes = {
|
||||
"poke": Poke,
|
||||
"forward": Forward,
|
||||
"node": Node,
|
||||
"nodes": Nodes,
|
||||
"xml": Xml,
|
||||
"json": Json,
|
||||
"cardimage": CardImage,
|
||||
"tts": TTS,
|
||||
"unknown": Unknown,
|
||||
'file': File,
|
||||
"file": File,
|
||||
}
|
||||
|
||||
@@ -5,145 +5,151 @@ from dataclasses import dataclass, field
|
||||
from astrbot.core.message.components import BaseMessageComponent, Plain, Image
|
||||
from typing_extensions import deprecated
|
||||
|
||||
|
||||
@dataclass
|
||||
class MessageChain():
|
||||
'''MessageChain 描述了一整条消息中带有的所有组件。
|
||||
class MessageChain:
|
||||
"""MessageChain 描述了一整条消息中带有的所有组件。
|
||||
现代消息平台的一条富文本消息中可能由多个组件构成,如文本、图片、At 等,并且保留了顺序。
|
||||
|
||||
|
||||
Attributes:
|
||||
`chain` (list): 用于顺序存储各个组件。
|
||||
`use_t2i_` (bool): 用于标记是否使用文本转图片服务。默认为 None,即跟随用户的设置。当设置为 True 时,将会使用文本转图片服务。
|
||||
'''
|
||||
|
||||
"""
|
||||
|
||||
chain: List[BaseMessageComponent] = field(default_factory=list)
|
||||
use_t2i_: Optional[bool] = None # None 为跟随用户设置
|
||||
|
||||
use_t2i_: Optional[bool] = None # None 为跟随用户设置
|
||||
|
||||
def message(self, message: str):
|
||||
'''添加一条文本消息到消息链 `chain` 中。
|
||||
|
||||
"""添加一条文本消息到消息链 `chain` 中。
|
||||
|
||||
Example:
|
||||
|
||||
CommandResult().message("Hello ").message("world!")
|
||||
# 输出 Hello world!
|
||||
|
||||
'''
|
||||
"""
|
||||
self.chain.append(Plain(message))
|
||||
return self
|
||||
|
||||
|
||||
@deprecated("请使用 message 方法代替。")
|
||||
def error(self, message: str):
|
||||
'''添加一条错误消息到消息链 `chain` 中
|
||||
|
||||
"""添加一条错误消息到消息链 `chain` 中
|
||||
|
||||
Example:
|
||||
|
||||
|
||||
CommandResult().error("解析失败")
|
||||
|
||||
'''
|
||||
|
||||
"""
|
||||
self.chain.append(Plain(message))
|
||||
return self
|
||||
|
||||
|
||||
def url_image(self, url: str):
|
||||
'''添加一条图片消息(https 链接)到消息链 `chain` 中。
|
||||
|
||||
"""添加一条图片消息(https 链接)到消息链 `chain` 中。
|
||||
|
||||
Note:
|
||||
如果需要发送本地图片,请使用 `file_image` 方法。
|
||||
|
||||
|
||||
Example:
|
||||
|
||||
|
||||
CommandResult().image("https://example.com/image.jpg")
|
||||
|
||||
'''
|
||||
|
||||
"""
|
||||
self.chain.append(Image.fromURL(url))
|
||||
return self
|
||||
|
||||
|
||||
def file_image(self, path: str):
|
||||
'''添加一条图片消息(本地文件路径)到消息链 `chain` 中。
|
||||
|
||||
"""添加一条图片消息(本地文件路径)到消息链 `chain` 中。
|
||||
|
||||
Note:
|
||||
如果需要发送网络图片,请使用 `url_image` 方法。
|
||||
|
||||
|
||||
CommandResult().image("image.jpg")
|
||||
'''
|
||||
"""
|
||||
self.chain.append(Image.fromFileSystem(path))
|
||||
return self
|
||||
|
||||
|
||||
def use_t2i(self, use_t2i: bool):
|
||||
'''设置是否使用文本转图片服务。
|
||||
|
||||
"""设置是否使用文本转图片服务。
|
||||
|
||||
Args:
|
||||
use_t2i (bool): 是否使用文本转图片服务。默认为 None,即跟随用户的设置。当设置为 True 时,将会使用文本转图片服务。
|
||||
'''
|
||||
"""
|
||||
self.use_t2i_ = use_t2i
|
||||
return self
|
||||
|
||||
|
||||
class EventResultType(enum.Enum):
|
||||
'''用于描述事件处理的结果类型。
|
||||
|
||||
"""用于描述事件处理的结果类型。
|
||||
|
||||
Attributes:
|
||||
CONTINUE: 事件将会继续传播
|
||||
STOP: 事件将会终止传播
|
||||
'''
|
||||
"""
|
||||
|
||||
CONTINUE = enum.auto()
|
||||
STOP = enum.auto()
|
||||
|
||||
|
||||
|
||||
class ResultContentType(enum.Enum):
|
||||
'''用于描述事件结果的内容的类型。
|
||||
'''
|
||||
"""用于描述事件结果的内容的类型。"""
|
||||
|
||||
LLM_RESULT = enum.auto()
|
||||
'''调用 LLM 产生的结果'''
|
||||
"""调用 LLM 产生的结果"""
|
||||
GENERAL_RESULT = enum.auto()
|
||||
'''普通的消息结果'''
|
||||
"""普通的消息结果"""
|
||||
|
||||
|
||||
@dataclass
|
||||
class MessageEventResult(MessageChain):
|
||||
'''MessageEventResult 描述了一整条消息中带有的所有组件以及事件处理的结果。
|
||||
"""MessageEventResult 描述了一整条消息中带有的所有组件以及事件处理的结果。
|
||||
现代消息平台的一条富文本消息中可能由多个组件构成,如文本、图片、At 等,并且保留了顺序。
|
||||
|
||||
|
||||
Attributes:
|
||||
`chain` (list): 用于顺序存储各个组件。
|
||||
`use_t2i_` (bool): 用于标记是否使用文本转图片服务。默认为 None,即跟随用户的设置。当设置为 True 时,将会使用文本转图片服务。
|
||||
`result_type` (EventResultType): 事件处理的结果类型。
|
||||
'''
|
||||
|
||||
result_type: Optional[EventResultType] = field(default_factory=lambda: EventResultType.CONTINUE)
|
||||
|
||||
result_content_type: Optional[ResultContentType] = field(default_factory=lambda: ResultContentType.GENERAL_RESULT)
|
||||
|
||||
def stop_event(self) -> 'MessageEventResult':
|
||||
'''终止事件传播。
|
||||
'''
|
||||
"""
|
||||
|
||||
result_type: Optional[EventResultType] = field(
|
||||
default_factory=lambda: EventResultType.CONTINUE
|
||||
)
|
||||
|
||||
result_content_type: Optional[ResultContentType] = field(
|
||||
default_factory=lambda: ResultContentType.GENERAL_RESULT
|
||||
)
|
||||
|
||||
def stop_event(self) -> "MessageEventResult":
|
||||
"""终止事件传播。"""
|
||||
self.result_type = EventResultType.STOP
|
||||
return self
|
||||
|
||||
def continue_event(self) -> 'MessageEventResult':
|
||||
'''继续事件传播。
|
||||
'''
|
||||
|
||||
def continue_event(self) -> "MessageEventResult":
|
||||
"""继续事件传播。"""
|
||||
self.result_type = EventResultType.CONTINUE
|
||||
return self
|
||||
|
||||
|
||||
def is_stopped(self) -> bool:
|
||||
'''
|
||||
"""
|
||||
是否终止事件传播。
|
||||
'''
|
||||
"""
|
||||
return self.result_type == EventResultType.STOP
|
||||
|
||||
def set_result_content_type(self, typ: ResultContentType) -> 'MessageEventResult':
|
||||
'''设置事件处理的结果类型。
|
||||
|
||||
|
||||
def set_result_content_type(self, typ: ResultContentType) -> "MessageEventResult":
|
||||
"""设置事件处理的结果类型。
|
||||
|
||||
Args:
|
||||
result_type (EventResultType): 事件处理的结果类型。
|
||||
'''
|
||||
"""
|
||||
self.result_content_type = typ
|
||||
return self
|
||||
|
||||
|
||||
def is_llm_result(self) -> bool:
|
||||
'''是否为 LLM 结果。
|
||||
'''
|
||||
"""是否为 LLM 结果。"""
|
||||
return self.result_content_type == ResultContentType.LLM_RESULT
|
||||
|
||||
|
||||
def get_plain_text(self) -> str:
|
||||
'''获取纯文本消息。这个方法将获取所有 Plain 组件的文本并拼接成一条消息。空格分隔。
|
||||
'''
|
||||
"""获取纯文本消息。这个方法将获取所有 Plain 组件的文本并拼接成一条消息。空格分隔。"""
|
||||
return " ".join([comp.text for comp in self.chain if isinstance(comp, Plain)])
|
||||
|
||||
|
||||
CommandResult = MessageEventResult
|
||||
|
||||
|
||||
CommandResult = MessageEventResult
|
||||
|
||||
@@ -1,4 +1,7 @@
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, EventResultType
|
||||
from astrbot.core.message.message_event_result import (
|
||||
MessageEventResult,
|
||||
EventResultType,
|
||||
)
|
||||
|
||||
from .waking_check.stage import WakingCheckStage
|
||||
from .whitelist_check.stage import WhitelistCheckStage
|
||||
@@ -10,14 +13,14 @@ from .result_decorate.stage import ResultDecorateStage
|
||||
from .respond.stage import RespondStage
|
||||
|
||||
STAGES_ORDER = [
|
||||
"WakingCheckStage", # 检查是否需要唤醒
|
||||
"WhitelistCheckStage", # 检查是否在群聊/私聊白名单
|
||||
"RateLimitStage", # 检查会话是否超过频率限制
|
||||
"ContentSafetyCheckStage", # 检查内容安全
|
||||
"PreProcessStage", # 预处理
|
||||
"ProcessStage", # 交由 Stars 处理(a.k.a 插件),或者 LLM 调用
|
||||
"ResultDecorateStage", # 处理结果,比如添加回复前缀、t2i、转换为语音 等
|
||||
"RespondStage" # 发送消息
|
||||
"WakingCheckStage", # 检查是否需要唤醒
|
||||
"WhitelistCheckStage", # 检查是否在群聊/私聊白名单
|
||||
"RateLimitStage", # 检查会话是否超过频率限制
|
||||
"ContentSafetyCheckStage", # 检查内容安全
|
||||
"PreProcessStage", # 预处理
|
||||
"ProcessStage", # 交由 Stars 处理(a.k.a 插件),或者 LLM 调用
|
||||
"ResultDecorateStage", # 处理结果,比如添加回复前缀、t2i、转换为语音 等
|
||||
"RespondStage", # 发送消息
|
||||
]
|
||||
|
||||
__all__ = [
|
||||
@@ -30,5 +33,5 @@ __all__ = [
|
||||
"ResultDecorateStage",
|
||||
"RespondStage",
|
||||
"MessageEventResult",
|
||||
"EventResultType"
|
||||
]
|
||||
"EventResultType",
|
||||
]
|
||||
|
||||
@@ -6,25 +6,32 @@ from astrbot.core.message.message_event_result import MessageEventResult
|
||||
from astrbot.core import logger
|
||||
from .strategies.strategy import StrategySelector
|
||||
|
||||
|
||||
@register_stage
|
||||
class ContentSafetyCheckStage(Stage):
|
||||
'''检查内容安全
|
||||
|
||||
"""检查内容安全
|
||||
|
||||
当前只会检查文本的。
|
||||
'''
|
||||
"""
|
||||
|
||||
async def initialize(self, ctx: PipelineContext):
|
||||
config = ctx.astrbot_config['content_safety']
|
||||
config = ctx.astrbot_config["content_safety"]
|
||||
self.strategy_selector = StrategySelector(config)
|
||||
|
||||
async def process(self, event: AstrMessageEvent, check_text: str = None) -> Union[None, AsyncGenerator[None, None]]:
|
||||
'''检查内容安全'''
|
||||
async def process(
|
||||
self, event: AstrMessageEvent, check_text: str = None
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
"""检查内容安全"""
|
||||
text = check_text if check_text else event.get_message_str()
|
||||
ok, info = self.strategy_selector.check(text)
|
||||
if not ok:
|
||||
event.set_result(MessageEventResult().message("你的消息或者大模型的响应中包含不适当的内容,已被屏蔽。"))
|
||||
yield
|
||||
if event.is_at_or_wake_command:
|
||||
event.set_result(
|
||||
MessageEventResult().message(
|
||||
"你的消息或者大模型的响应中包含不适当的内容,已被屏蔽。"
|
||||
)
|
||||
)
|
||||
yield
|
||||
event.stop_event()
|
||||
logger.info(f"内容安全检查不通过,原因:{info}")
|
||||
return
|
||||
event.continue_event()
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
import abc
|
||||
from typing import Tuple
|
||||
|
||||
|
||||
class ContentSafetyStrategy(abc.ABC):
|
||||
|
||||
@abc.abstractmethod
|
||||
def check(self, content: str) -> Tuple[bool, str]:
|
||||
raise NotImplementedError
|
||||
raise NotImplementedError
|
||||
|
||||
@@ -1,30 +1,30 @@
|
||||
'''
|
||||
"""
|
||||
使用此功能应该先 pip install baidu-aip
|
||||
'''
|
||||
"""
|
||||
|
||||
from . import ContentSafetyStrategy
|
||||
from aip import AipContentCensor
|
||||
|
||||
|
||||
class BaiduAipStrategy(ContentSafetyStrategy):
|
||||
def __init__(self, appid: str, ak: str, sk: str) -> None:
|
||||
self.app_id = appid
|
||||
self.api_key = ak
|
||||
self.secret_key = sk
|
||||
self.client = AipContentCensor(self.app_id,
|
||||
self.api_key,
|
||||
self.secret_key)
|
||||
self.client = AipContentCensor(self.app_id, self.api_key, self.secret_key)
|
||||
|
||||
def check(self, content: str):
|
||||
res = self.client.textCensorUserDefined(content)
|
||||
if 'conclusionType' not in res:
|
||||
if "conclusionType" not in res:
|
||||
return False, ""
|
||||
if res['conclusionType'] == 1:
|
||||
if res["conclusionType"] == 1:
|
||||
return True, ""
|
||||
else:
|
||||
if 'data' not in res:
|
||||
if "data" not in res:
|
||||
return False, ""
|
||||
count = len(res['data'])
|
||||
count = len(res["data"])
|
||||
info = f"百度审核服务发现 {count} 处违规:\n"
|
||||
for i in res['data']:
|
||||
for i in res["data"]:
|
||||
info += f"{i['msg']};\n"
|
||||
info += "\n判断结果:"+res['conclusion']
|
||||
return False, info
|
||||
info += "\n判断结果:" + res["conclusion"]
|
||||
return False, info
|
||||
|
||||
@@ -4,20 +4,23 @@ import json
|
||||
import base64
|
||||
from . import ContentSafetyStrategy
|
||||
|
||||
|
||||
class KeywordsStrategy(ContentSafetyStrategy):
|
||||
def __init__(self, extra_keywords: list) -> None:
|
||||
self.keywords = []
|
||||
if extra_keywords is None:
|
||||
extra_keywords = []
|
||||
self.keywords.extend(extra_keywords)
|
||||
keywords_path = os.path.join(os.path.dirname(__file__), 'unfit_words')
|
||||
keywords_path = os.path.join(os.path.dirname(__file__), "unfit_words")
|
||||
# internal keywords
|
||||
if os.path.exists(keywords_path):
|
||||
with open(keywords_path, "r", encoding="utf-8") as f:
|
||||
self.keywords.extend(json.loads(base64.b64decode(f.read()).decode("utf-8"))['keywords'])
|
||||
self.keywords.extend(
|
||||
json.loads(base64.b64decode(f.read()).decode("utf-8"))["keywords"]
|
||||
)
|
||||
|
||||
def check(self, content: str) -> bool:
|
||||
for keyword in self.keywords:
|
||||
if re.search(keyword, content):
|
||||
return False, "内容安全检查不通过,匹配到敏感词。"
|
||||
return True, ""
|
||||
return True, ""
|
||||
|
||||
@@ -2,6 +2,7 @@ from . import ContentSafetyStrategy
|
||||
from typing import List, Tuple
|
||||
from astrbot import logger
|
||||
|
||||
|
||||
class StrategySelector:
|
||||
def __init__(self, config: dict) -> None:
|
||||
self.enabled_strategies: List[ContentSafetyStrategy] = []
|
||||
|
||||
@@ -2,7 +2,8 @@ from dataclasses import dataclass
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from astrbot.core.star import PluginManager
|
||||
|
||||
|
||||
@dataclass
|
||||
class PipelineContext:
|
||||
astrbot_config: AstrBotConfig
|
||||
plugin_manager: PluginManager
|
||||
plugin_manager: PluginManager
|
||||
|
||||
@@ -7,42 +7,45 @@ from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.message.components import Plain, Record, Image
|
||||
|
||||
|
||||
@register_stage
|
||||
class PreProcessStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
self.config = ctx.astrbot_config
|
||||
self.plugin_manager = ctx.plugin_manager
|
||||
|
||||
self.stt_settings: dict = self.config.get('provider_stt_settings', {})
|
||||
self.platform_settings: dict = self.config.get('platform_settings', {})
|
||||
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
'''在处理事件之前的预处理'''
|
||||
self.stt_settings: dict = self.config.get("provider_stt_settings", {})
|
||||
self.platform_settings: dict = self.config.get("platform_settings", {})
|
||||
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
"""在处理事件之前的预处理"""
|
||||
# 路径映射
|
||||
if mappings := self.platform_settings.get('path_mapping', []):
|
||||
if mappings := self.platform_settings.get("path_mapping", []):
|
||||
# 支持 Record,Image 消息段的路径映射。
|
||||
message_chain = event.get_messages()
|
||||
|
||||
|
||||
for idx, component in enumerate(message_chain):
|
||||
if isinstance(component, (Record, Image)) and component.url:
|
||||
for mapping in mappings:
|
||||
from_, to_ = mapping.split(":")
|
||||
from_ = from_.removesuffix("/")
|
||||
to_ = to_.removesuffix("/")
|
||||
|
||||
|
||||
url = component.url.removeprefix("file://")
|
||||
if url.startswith(from_):
|
||||
component.url = url.replace(from_, to_, 1)
|
||||
logger.debug(f"路径映射: {url} -> {component.url}")
|
||||
message_chain[idx] = component
|
||||
|
||||
|
||||
# STT
|
||||
if self.stt_settings.get('enable', False):
|
||||
if self.stt_settings.get("enable", False):
|
||||
# TODO: 独立
|
||||
stt_provider = self.plugin_manager.context.provider_manager.curr_stt_provider_inst
|
||||
stt_provider = (
|
||||
self.plugin_manager.context.provider_manager.curr_stt_provider_inst
|
||||
)
|
||||
if stt_provider:
|
||||
message_chain = event.get_messages()
|
||||
for idx, component in enumerate(message_chain):
|
||||
|
||||
@@ -1,66 +0,0 @@
|
||||
'''
|
||||
Dify 调用 Stage
|
||||
'''
|
||||
import traceback
|
||||
from typing import Union, AsyncGenerator
|
||||
from ...context import PipelineContext
|
||||
from ..stage import Stage
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, ResultContentType
|
||||
from astrbot.core.message.components import Image
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
from astrbot.core.provider.entites import ProviderRequest
|
||||
|
||||
class DifyRequestSubStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
req: ProviderRequest = None
|
||||
|
||||
provider = self.ctx.plugin_manager.context.get_using_provider()
|
||||
|
||||
if not provider:
|
||||
return
|
||||
|
||||
if provider.meta().type != "dify":
|
||||
return
|
||||
|
||||
if event.get_extra("provider_request"):
|
||||
req = event.get_extra("provider_request")
|
||||
assert isinstance(req, ProviderRequest), "provider_request 必须是 ProviderRequest 类型。"
|
||||
else:
|
||||
req = ProviderRequest(prompt="", image_urls=[])
|
||||
if self.ctx.astrbot_config['provider_settings']['wake_prefix']:
|
||||
if not event.message_str.startswith(self.ctx.astrbot_config['provider_settings']['wake_prefix']):
|
||||
return
|
||||
req.prompt = event.message_str[len(self.ctx.astrbot_config['provider_settings']['wake_prefix']):]
|
||||
for comp in event.message_obj.message:
|
||||
if isinstance(comp, Image):
|
||||
image_url = comp.url if comp.url else comp.file
|
||||
req.image_urls.append(image_url)
|
||||
req.session_id = event.session_id
|
||||
event.set_extra("provider_request", req)
|
||||
|
||||
if not req.prompt:
|
||||
return
|
||||
|
||||
req.session_id = event.unified_msg_origin
|
||||
|
||||
try:
|
||||
logger.debug(f"Dify 请求 Payload: {req.__dict__}")
|
||||
llm_response = await provider.text_chat(**req.__dict__) # 请求 LLM
|
||||
await Metric.upload(llm_tick=1, model_name=provider.get_model(), provider_type=provider.meta().type)
|
||||
|
||||
if llm_response.role == 'assistant':
|
||||
# text completion
|
||||
event.set_result(MessageEventResult().message(llm_response.completion_text)
|
||||
.set_result_content_type(ResultContentType.LLM_RESULT))
|
||||
yield # rick roll
|
||||
|
||||
except BaseException as e:
|
||||
logger.error(traceback.format_exc())
|
||||
event.set_result(MessageEventResult().message("AstrBot 请求 Dify 失败:" + str(e)))
|
||||
return
|
||||
@@ -1,159 +1,234 @@
|
||||
'''
|
||||
"""
|
||||
本地 Agent 模式的 LLM 调用 Stage
|
||||
'''
|
||||
"""
|
||||
|
||||
import traceback
|
||||
import json
|
||||
from typing import Union, AsyncGenerator
|
||||
from ...context import PipelineContext
|
||||
from ..stage import Stage
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, ResultContentType
|
||||
from astrbot.core.message.message_event_result import (
|
||||
MessageEventResult,
|
||||
ResultContentType,
|
||||
)
|
||||
from astrbot.core.message.components import Image
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
from astrbot.core.provider.entites import ProviderRequest, LLMResponse
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
from astrbot.core.star.star import star_map
|
||||
|
||||
|
||||
class LLMRequestSubStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
self.bot_wake_prefixs = ctx.astrbot_config['wake_prefix'] # list
|
||||
self.provider_wake_prefix = ctx.astrbot_config['provider_settings']['wake_prefix'] # str
|
||||
|
||||
self.bot_wake_prefixs = ctx.astrbot_config["wake_prefix"] # list
|
||||
self.provider_wake_prefix = ctx.astrbot_config["provider_settings"][
|
||||
"wake_prefix"
|
||||
] # str
|
||||
|
||||
for bwp in self.bot_wake_prefixs:
|
||||
if self.provider_wake_prefix.startswith(bwp):
|
||||
logger.info(f"识别 LLM 聊天额外唤醒前缀 {self.provider_wake_prefix} 以机器人唤醒前缀 {bwp} 开头,已自动去除。")
|
||||
self.provider_wake_prefix = self.provider_wake_prefix[len(bwp):]
|
||||
|
||||
logger.info(
|
||||
f"识别 LLM 聊天额外唤醒前缀 {self.provider_wake_prefix} 以机器人唤醒前缀 {bwp} 开头,已自动去除。"
|
||||
)
|
||||
self.provider_wake_prefix = self.provider_wake_prefix[len(bwp) :]
|
||||
|
||||
self.conv_manager = ctx.plugin_manager.context.conversation_manager
|
||||
|
||||
async def process(self, event: AstrMessageEvent, _nested: bool = False) -> Union[None, AsyncGenerator[None, None]]:
|
||||
|
||||
async def process(
|
||||
self, event: AstrMessageEvent, _nested: bool = False
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
req: ProviderRequest = None
|
||||
|
||||
|
||||
provider = self.ctx.plugin_manager.context.get_using_provider()
|
||||
if provider is None:
|
||||
return
|
||||
|
||||
|
||||
if event.get_extra("provider_request"):
|
||||
req = event.get_extra("provider_request")
|
||||
assert isinstance(req, ProviderRequest), "provider_request 必须是 ProviderRequest 类型。"
|
||||
assert isinstance(req, ProviderRequest), (
|
||||
"provider_request 必须是 ProviderRequest 类型。"
|
||||
)
|
||||
|
||||
if req.conversation:
|
||||
req.contexts = json.loads(req.conversation.history)
|
||||
else:
|
||||
req = ProviderRequest(prompt="", image_urls=[])
|
||||
if self.provider_wake_prefix:
|
||||
if not event.message_str.startswith(self.provider_wake_prefix):
|
||||
return
|
||||
req.prompt = event.message_str[len(self.provider_wake_prefix):]
|
||||
req.prompt = event.message_str[len(self.provider_wake_prefix) :]
|
||||
req.func_tool = self.ctx.plugin_manager.context.get_llm_tool_manager()
|
||||
for comp in event.message_obj.message:
|
||||
if isinstance(comp, Image):
|
||||
image_url = comp.url if comp.url else comp.file
|
||||
req.image_urls.append(image_url)
|
||||
|
||||
|
||||
# 获取对话上下文
|
||||
conversation_id = await self.conv_manager.get_curr_conversation_id(event.unified_msg_origin)
|
||||
conversation_id = await self.conv_manager.get_curr_conversation_id(
|
||||
event.unified_msg_origin
|
||||
)
|
||||
if not conversation_id:
|
||||
conversation_id = await self.conv_manager.new_conversation(event.unified_msg_origin)
|
||||
req.session_id = conversation_id
|
||||
conversation = await self.conv_manager.get_conversation(event.unified_msg_origin, conversation_id)
|
||||
conversation_id = await self.conv_manager.new_conversation(
|
||||
event.unified_msg_origin
|
||||
)
|
||||
req.session_id = event.unified_msg_origin
|
||||
conversation = await self.conv_manager.get_conversation(
|
||||
event.unified_msg_origin, conversation_id
|
||||
)
|
||||
req.conversation = conversation
|
||||
req.contexts = json.loads(conversation.history)
|
||||
|
||||
event.set_extra("provider_request", req)
|
||||
|
||||
|
||||
if not req.prompt and not req.image_urls:
|
||||
return
|
||||
|
||||
# 执行请求 LLM 前事件。
|
||||
|
||||
# 执行请求 LLM 前事件钩子。
|
||||
# 装饰 system_prompt 等功能
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(EventType.OnLLMRequestEvent)
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(
|
||||
EventType.OnLLMRequestEvent
|
||||
)
|
||||
for handler in handlers:
|
||||
try:
|
||||
logger.debug(
|
||||
f"hook(on_llm_request) -> {star_map[handler.handler_module_path].name} - {handler.handler_name}"
|
||||
)
|
||||
await handler.handler(event, req)
|
||||
except BaseException:
|
||||
logger.error(traceback.format_exc())
|
||||
|
||||
|
||||
if event.is_stopped():
|
||||
logger.info(
|
||||
f"{star_map[handler.handler_module_path].name} - {handler.handler_name} 终止了事件传播。"
|
||||
)
|
||||
return
|
||||
|
||||
if isinstance(req.contexts, str):
|
||||
req.contexts = json.loads(req.contexts)
|
||||
|
||||
|
||||
try:
|
||||
logger.debug(f"提供商请求 Payload: {req}")
|
||||
if _nested:
|
||||
req.func_tool = None # 暂时不支持递归工具调用
|
||||
llm_response = await provider.text_chat(**req.__dict__) # 请求 LLM
|
||||
|
||||
# 执行 LLM 响应后的事件。
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(EventType.OnLLMResponseEvent)
|
||||
req.func_tool = None # 暂时不支持递归工具调用
|
||||
llm_response = await provider.text_chat(**req.__dict__) # 请求 LLM
|
||||
|
||||
# 执行 LLM 响应后的事件钩子。
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(
|
||||
EventType.OnLLMResponseEvent
|
||||
)
|
||||
for handler in handlers:
|
||||
try:
|
||||
logger.debug(
|
||||
f"hook(on_llm_response) -> {star_map[handler.handler_module_path].name} - {handler.handler_name}"
|
||||
)
|
||||
await handler.handler(event, llm_response)
|
||||
except BaseException:
|
||||
logger.error(traceback.format_exc())
|
||||
|
||||
|
||||
if event.is_stopped():
|
||||
logger.info(
|
||||
f"{star_map[handler.handler_module_path].name} - {handler.handler_name} 终止了事件传播。"
|
||||
)
|
||||
return
|
||||
|
||||
# 保存到历史记录
|
||||
await self._save_to_history(event, req, llm_response)
|
||||
|
||||
await Metric.upload(llm_tick=1, model_name=provider.get_model(), provider_type=provider.meta().type)
|
||||
|
||||
if llm_response.role == 'assistant':
|
||||
await Metric.upload(
|
||||
llm_tick=1,
|
||||
model_name=provider.get_model(),
|
||||
provider_type=provider.meta().type,
|
||||
)
|
||||
|
||||
if llm_response.role == "assistant":
|
||||
# text completion
|
||||
event.set_result(MessageEventResult().message(llm_response.completion_text)
|
||||
.set_result_content_type(ResultContentType.LLM_RESULT))
|
||||
elif llm_response.role == 'err':
|
||||
event.set_result(MessageEventResult().message(f"AstrBot 请求失败。\n错误信息: {llm_response.completion_text}"))
|
||||
elif llm_response.role == 'tool':
|
||||
event.set_result(
|
||||
MessageEventResult()
|
||||
.message(llm_response.completion_text)
|
||||
.set_result_content_type(ResultContentType.LLM_RESULT)
|
||||
)
|
||||
elif llm_response.role == "err":
|
||||
event.set_result(
|
||||
MessageEventResult().message(
|
||||
f"AstrBot 请求失败。\n错误信息: {llm_response.completion_text}"
|
||||
)
|
||||
)
|
||||
elif llm_response.role == "tool":
|
||||
# function calling
|
||||
function_calling_result = {}
|
||||
for func_tool_name, func_tool_args in zip(llm_response.tools_call_name, llm_response.tools_call_args):
|
||||
logger.info(
|
||||
f"触发 {len(llm_response.tools_call_name)} 个函数调用: {llm_response.tools_call_name}"
|
||||
)
|
||||
for func_tool_name, func_tool_args in zip(
|
||||
llm_response.tools_call_name, llm_response.tools_call_args
|
||||
):
|
||||
func_tool = req.func_tool.get_func(func_tool_name)
|
||||
logger.info(f"调用工具函数:{func_tool_name},参数:{func_tool_args}")
|
||||
logger.info(
|
||||
f"调用工具函数:{func_tool_name},参数:{func_tool_args}"
|
||||
)
|
||||
try:
|
||||
# 尝试调用工具函数
|
||||
wrapper = self._call_handler(self.ctx, event, func_tool.handler, **func_tool_args)
|
||||
wrapper = self._call_handler(
|
||||
self.ctx, event, func_tool.handler, **func_tool_args
|
||||
)
|
||||
async for resp in wrapper:
|
||||
if resp is not None: # 有 return 返回
|
||||
if resp is not None: # 有 return 返回
|
||||
function_calling_result[func_tool_name] = resp
|
||||
else:
|
||||
yield # 有生成器返回
|
||||
event.clear_result() # 清除上一个 handler 的结果
|
||||
yield # 有生成器返回
|
||||
event.clear_result() # 清除上一个 handler 的结果
|
||||
except BaseException as e:
|
||||
logger.warning(traceback.format_exc())
|
||||
function_calling_result[func_tool_name] = "When calling the function, an error occurred: " + str(e)
|
||||
function_calling_result[func_tool_name] = (
|
||||
"When calling the function, an error occurred: " + str(e)
|
||||
)
|
||||
if function_calling_result:
|
||||
# 工具返回 LLM 资源。比如 RAG、网页 得到的相关结果等。
|
||||
# 我们重新执行一遍这个 stage
|
||||
req.func_tool = None # 暂时不支持递归工具调用
|
||||
req.func_tool = None # 暂时不支持递归工具调用
|
||||
extra_prompt = "\n\nSystem executed some external tools for this task and here are the results:\n"
|
||||
for tool_name, tool_result in function_calling_result.items():
|
||||
extra_prompt += f"Tool: {tool_name}\nTool Result: {tool_result}\n"
|
||||
extra_prompt += (
|
||||
f"Tool: {tool_name}\nTool Result: {tool_result}\n"
|
||||
)
|
||||
req.prompt += extra_prompt
|
||||
async for _ in self.process(event, _nested=True):
|
||||
yield
|
||||
else:
|
||||
if llm_response.completion_text:
|
||||
event.set_result(MessageEventResult().message(llm_response.completion_text))
|
||||
event.set_result(
|
||||
MessageEventResult().message(llm_response.completion_text)
|
||||
)
|
||||
|
||||
except BaseException as e:
|
||||
logger.error(traceback.format_exc())
|
||||
event.set_result(MessageEventResult().message(f"AstrBot 请求失败。\n错误类型: {type(e).__name__}\n错误信息: {str(e)}"))
|
||||
event.set_result(
|
||||
MessageEventResult().message(
|
||||
f"AstrBot 请求失败。\n错误类型: {type(e).__name__}\n错误信息: {str(e)}"
|
||||
)
|
||||
)
|
||||
return
|
||||
|
||||
async def _save_to_history(self, event: AstrMessageEvent, req: ProviderRequest, llm_response: LLMResponse):
|
||||
|
||||
async def _save_to_history(
|
||||
self, event: AstrMessageEvent, req: ProviderRequest, llm_response: LLMResponse
|
||||
):
|
||||
if not req or not req.conversation or not llm_response:
|
||||
return
|
||||
|
||||
if llm_response.role == "assistant":
|
||||
# 文本回复
|
||||
contexts = req.contexts
|
||||
new_record = {
|
||||
"role": "user",
|
||||
"content": req.prompt
|
||||
}
|
||||
new_record = {"role": "user", "content": req.prompt}
|
||||
contexts.append(new_record)
|
||||
contexts.append({
|
||||
"role": "assistant",
|
||||
"content": llm_response.completion_text
|
||||
})
|
||||
contexts_to_save = list(filter(lambda item: '_no_save' not in item, contexts))
|
||||
contexts.append(
|
||||
{"role": "assistant", "content": llm_response.completion_text}
|
||||
)
|
||||
contexts_to_save = list(
|
||||
filter(lambda item: "_no_save" not in item, contexts)
|
||||
)
|
||||
await self.conv_manager.update_conversation(
|
||||
event.unified_msg_origin,
|
||||
req.session_id,
|
||||
history=contexts_to_save
|
||||
)
|
||||
event.unified_msg_origin, req.conversation.cid, history=contexts_to_save
|
||||
)
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
'''
|
||||
"""
|
||||
本地 Agent 模式的 AstrBot 插件调用 Stage
|
||||
'''
|
||||
"""
|
||||
|
||||
from ...context import PipelineContext
|
||||
from ..stage import Stage
|
||||
from typing import Dict, Any, List, AsyncGenerator, Union
|
||||
@@ -11,39 +12,45 @@ from astrbot.core.star.star_handler import StarHandlerMetadata
|
||||
from astrbot.core.star.star import star_map
|
||||
import traceback
|
||||
|
||||
|
||||
class StarRequestSubStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.curr_provider = ctx.plugin_manager.context.get_using_provider()
|
||||
self.prompt_prefix = ctx.astrbot_config['provider_settings']['prompt_prefix']
|
||||
self.identifier = ctx.astrbot_config['provider_settings']['identifier']
|
||||
self.prompt_prefix = ctx.astrbot_config["provider_settings"]["prompt_prefix"]
|
||||
self.identifier = ctx.astrbot_config["provider_settings"]["identifier"]
|
||||
self.ctx = ctx
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
activated_handlers: List[StarHandlerMetadata] = event.get_extra("activated_handlers")
|
||||
handlers_parsed_params: Dict[str, Dict[str, Any]] = event.get_extra("handlers_parsed_params")
|
||||
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
activated_handlers: List[StarHandlerMetadata] = event.get_extra(
|
||||
"activated_handlers"
|
||||
)
|
||||
handlers_parsed_params: Dict[str, Dict[str, Any]] = event.get_extra(
|
||||
"handlers_parsed_params"
|
||||
)
|
||||
if not handlers_parsed_params:
|
||||
handlers_parsed_params = {}
|
||||
for handler in activated_handlers:
|
||||
params = handlers_parsed_params.get(handler.handler_full_name, {})
|
||||
try:
|
||||
if handler.handler_module_path not in star_map:
|
||||
# 孤立无援的 star handler
|
||||
continue
|
||||
|
||||
logger.debug(f"执行插件 handler {handler.handler_full_name}")
|
||||
logger.debug(
|
||||
f"plugin -> {star_map.get(handler.handler_module_path).name} - {handler.handler_name}"
|
||||
)
|
||||
wrapper = self._call_handler(self.ctx, event, handler.handler, **params)
|
||||
async for ret in wrapper:
|
||||
yield ret
|
||||
event.clear_result() # 清除上一个 handler 的结果
|
||||
event.clear_result() # 清除上一个 handler 的结果
|
||||
except Exception as e:
|
||||
logger.error(traceback.format_exc())
|
||||
logger.error(f"Star {handler.handler_full_name} handle error: {e}")
|
||||
|
||||
|
||||
if event.is_at_or_wake_command:
|
||||
ret = f":(\n\n在调用插件 {star_map.get(handler.handler_module_path).name} 的处理函数 {handler.handler_name} 时出现异常:{e}"
|
||||
event.set_result(MessageEventResult().message(ret))
|
||||
yield
|
||||
event.clear_result()
|
||||
|
||||
event.stop_event()
|
||||
|
||||
event.stop_event()
|
||||
|
||||
@@ -3,39 +3,37 @@ from ..stage import Stage, register_stage
|
||||
from ..context import PipelineContext
|
||||
from .method.llm_request import LLMRequestSubStage
|
||||
from .method.star_request import StarRequestSubStage
|
||||
from .method.dify_request import DifyRequestSubStage
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.star.star_handler import StarHandlerMetadata
|
||||
from astrbot.core.provider.entites import ProviderRequest
|
||||
from astrbot.core import logger
|
||||
|
||||
|
||||
@register_stage
|
||||
class ProcessStage(Stage):
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.ctx = ctx
|
||||
self.config = ctx.astrbot_config
|
||||
self.plugin_manager = ctx.plugin_manager
|
||||
self.llm_request_sub_stage = LLMRequestSubStage()
|
||||
await self.llm_request_sub_stage.initialize(ctx)
|
||||
|
||||
|
||||
self.star_request_sub_stage = StarRequestSubStage()
|
||||
await self.star_request_sub_stage.initialize(ctx)
|
||||
|
||||
self.dify_request_sub_stage = DifyRequestSubStage()
|
||||
await self.dify_request_sub_stage.initialize(ctx)
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
'''处理事件
|
||||
'''
|
||||
activated_handlers: List[StarHandlerMetadata] = event.get_extra("activated_handlers")
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
"""处理事件"""
|
||||
activated_handlers: List[StarHandlerMetadata] = event.get_extra(
|
||||
"activated_handlers"
|
||||
)
|
||||
# 有插件 Handler 被激活
|
||||
if activated_handlers:
|
||||
async for resp in self.star_request_sub_stage.process(event):
|
||||
# 生成器返回值处理
|
||||
if isinstance(resp, ProviderRequest):
|
||||
# Handler 的 LLM 请求
|
||||
logger.debug(f"llm request -> {resp.prompt}")
|
||||
event.set_extra("provider_request", resp)
|
||||
_t = False
|
||||
async for _ in self.llm_request_sub_stage.process(event):
|
||||
@@ -45,23 +43,26 @@ class ProcessStage(Stage):
|
||||
yield
|
||||
else:
|
||||
yield
|
||||
|
||||
# 调用提供商相关请求
|
||||
if not self.ctx.astrbot_config['provider_settings'].get('enable', True):
|
||||
|
||||
# 调用 LLM 相关请求
|
||||
if not self.ctx.astrbot_config["provider_settings"].get("enable", True):
|
||||
return
|
||||
|
||||
if not event._has_send_oper and event.is_at_or_wake_command:
|
||||
if (event.get_result() and not event.get_result().is_stopped()) or not event.get_result():
|
||||
|
||||
if (
|
||||
not event._has_send_oper
|
||||
and event.is_at_or_wake_command
|
||||
and not event.call_llm
|
||||
):
|
||||
# 是否有过发送操作 and 是否是被 @ 或者通过唤醒前缀
|
||||
if (
|
||||
event.get_result() and not event.get_result().is_stopped()
|
||||
) or not event.get_result():
|
||||
# 事件没有终止传播
|
||||
provider = self.ctx.plugin_manager.context.get_using_provider()
|
||||
|
||||
|
||||
if not provider:
|
||||
logger.info("未找到可用的 LLM 提供商,请先前往配置服务提供商。")
|
||||
return
|
||||
|
||||
match provider.meta().type:
|
||||
case "dify":
|
||||
async for _ in self.dify_request_sub_stage.process(event):
|
||||
yield
|
||||
case _:
|
||||
async for _ in self.llm_request_sub_stage.process(event):
|
||||
yield
|
||||
|
||||
async for _ in self.llm_request_sub_stage.process(event):
|
||||
yield
|
||||
|
||||
@@ -5,7 +5,6 @@ from typing import DefaultDict, Deque, Union, AsyncGenerator
|
||||
from ..stage import Stage, register_stage
|
||||
from ..context import PipelineContext
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.config.astrbot_config import RateLimitStrategy
|
||||
|
||||
@@ -32,11 +31,19 @@ class RateLimitStage(Stage):
|
||||
"""
|
||||
初始化限流器,根据配置设置限流参数。
|
||||
"""
|
||||
self.rate_limit_count = ctx.astrbot_config['platform_settings']['rate_limit']['count']
|
||||
self.rate_limit_time = timedelta(seconds=ctx.astrbot_config['platform_settings']['rate_limit']['time'])
|
||||
self.rl_strategy = ctx.astrbot_config['platform_settings']['rate_limit']['strategy'] # stall or discard
|
||||
self.rate_limit_count = ctx.astrbot_config["platform_settings"]["rate_limit"][
|
||||
"count"
|
||||
]
|
||||
self.rate_limit_time = timedelta(
|
||||
seconds=ctx.astrbot_config["platform_settings"]["rate_limit"]["time"]
|
||||
)
|
||||
self.rl_strategy = ctx.astrbot_config["platform_settings"]["rate_limit"][
|
||||
"strategy"
|
||||
] # stall or discard
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
"""
|
||||
检查并处理限流逻辑。如果触发限流,流水线会 stall 并在窗口期后自动恢复。
|
||||
|
||||
@@ -59,23 +66,29 @@ class RateLimitStage(Stage):
|
||||
# 达到限流阈值,计算下一个窗口的时间
|
||||
next_window_time = timestamps[0] + self.rate_limit_time
|
||||
stall_duration = (next_window_time - now).total_seconds()
|
||||
|
||||
|
||||
match self.rl_strategy:
|
||||
case RateLimitStrategy.STALL.value:
|
||||
logger.info(f"会话 {session_id} 被限流。根据限流策略,此会话处理将被暂停 {stall_duration:.2f} 秒。")
|
||||
logger.info(
|
||||
f"会话 {session_id} 被限流。根据限流策略,此会话处理将被暂停 {stall_duration:.2f} 秒。"
|
||||
)
|
||||
await asyncio.sleep(stall_duration)
|
||||
case RateLimitStrategy.DISCARD.value:
|
||||
# event.set_result(MessageEventResult().message(f"会话 {session_id} 被限流。根据限流策略,此请求已被丢弃,直到您的限额于 {stall_duration:.2f} 秒后重置。"))
|
||||
logger.info(f"会话 {session_id} 被限流。根据限流策略,此请求已被丢弃,直到限额于 {stall_duration:.2f} 秒后重置。")
|
||||
logger.info(
|
||||
f"会话 {session_id} 被限流。根据限流策略,此请求已被丢弃,直到限额于 {stall_duration:.2f} 秒后重置。"
|
||||
)
|
||||
return event.stop_event()
|
||||
|
||||
self._remove_expired_timestamps(timestamps, now + timedelta(seconds=stall_duration))
|
||||
|
||||
self._remove_expired_timestamps(
|
||||
timestamps, now + timedelta(seconds=stall_duration)
|
||||
)
|
||||
|
||||
timestamps.append(now)
|
||||
|
||||
return event.continue_event()
|
||||
|
||||
def _remove_expired_timestamps(self, timestamps: Deque[datetime], now: datetime) -> None:
|
||||
def _remove_expired_timestamps(
|
||||
self, timestamps: Deque[datetime], now: datetime
|
||||
) -> None:
|
||||
"""
|
||||
移除时间窗口外的时间戳。
|
||||
|
||||
@@ -85,4 +98,4 @@ class RateLimitStage(Stage):
|
||||
"""
|
||||
expiry_threshold: datetime = now - self.rate_limit_time
|
||||
while timestamps and timestamps[0] < expiry_threshold:
|
||||
timestamps.popleft()
|
||||
timestamps.popleft()
|
||||
|
||||
@@ -1,46 +1,67 @@
|
||||
import random
|
||||
import asyncio
|
||||
import math
|
||||
import traceback
|
||||
from typing import Union, AsyncGenerator
|
||||
from ..stage import register_stage, Stage
|
||||
from ..context import PipelineContext
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageChain
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.message.message_event_result import BaseMessageComponent, Plain
|
||||
from astrbot.core.message.message_event_result import BaseMessageComponent
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
from astrbot.core.star.star import star_map
|
||||
from astrbot.core.message.components import Plain, Reply, At
|
||||
|
||||
|
||||
@register_stage
|
||||
class RespondStage(Stage):
|
||||
async def initialize(self, ctx: PipelineContext):
|
||||
self.ctx = ctx
|
||||
|
||||
|
||||
self.reply_with_mention = ctx.astrbot_config["platform_settings"][
|
||||
"reply_with_mention"
|
||||
]
|
||||
self.reply_with_quote = ctx.astrbot_config["platform_settings"][
|
||||
"reply_with_quote"
|
||||
]
|
||||
|
||||
# 分段回复
|
||||
self.enable_seg: bool = ctx.astrbot_config['platform_settings']['segmented_reply']['enable']
|
||||
self.only_llm_result = ctx.astrbot_config['platform_settings']['segmented_reply']['only_llm_result']
|
||||
|
||||
self.interval_method = ctx.astrbot_config['platform_settings']['segmented_reply']['interval_method']
|
||||
self.log_base = float(ctx.astrbot_config['platform_settings']['segmented_reply']['log_base'])
|
||||
interval_str: str = ctx.astrbot_config['platform_settings']['segmented_reply']['interval']
|
||||
self.enable_seg: bool = ctx.astrbot_config["platform_settings"][
|
||||
"segmented_reply"
|
||||
]["enable"]
|
||||
self.only_llm_result = ctx.astrbot_config["platform_settings"][
|
||||
"segmented_reply"
|
||||
]["only_llm_result"]
|
||||
|
||||
self.interval_method = ctx.astrbot_config["platform_settings"][
|
||||
"segmented_reply"
|
||||
]["interval_method"]
|
||||
self.log_base = float(
|
||||
ctx.astrbot_config["platform_settings"]["segmented_reply"]["log_base"]
|
||||
)
|
||||
interval_str: str = ctx.astrbot_config["platform_settings"]["segmented_reply"][
|
||||
"interval"
|
||||
]
|
||||
interval_str_ls = interval_str.replace(" ", "").split(",")
|
||||
try:
|
||||
self.interval = [float(t) for t in interval_str_ls]
|
||||
except BaseException as e:
|
||||
logger.error(f'解析分段回复的间隔时间失败。{e}')
|
||||
logger.error(f"解析分段回复的间隔时间失败。{e}")
|
||||
self.interval = [1.5, 3.5]
|
||||
logger.info(f"分段回复间隔时间:{self.interval}")
|
||||
|
||||
|
||||
async def _word_cnt(self, text: str) -> int:
|
||||
'''分段回复 统计字数'''
|
||||
"""分段回复 统计字数"""
|
||||
if all(ord(c) < 128 for c in text):
|
||||
word_count = len(text.split())
|
||||
else:
|
||||
word_count = len([c for c in text if c.isalnum()])
|
||||
return word_count
|
||||
|
||||
|
||||
async def _calc_comp_interval(self, comp: BaseMessageComponent) -> float:
|
||||
'''分段回复 计算间隔时间'''
|
||||
if self.interval_method == 'log':
|
||||
"""分段回复 计算间隔时间"""
|
||||
if self.interval_method == "log":
|
||||
if isinstance(comp, Plain):
|
||||
wc = await self._word_cnt(comp.text)
|
||||
i = math.log(wc + 1, self.log_base)
|
||||
@@ -51,28 +72,61 @@ class RespondStage(Stage):
|
||||
# random
|
||||
return random.uniform(self.interval[0], self.interval[1])
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
result = event.get_result()
|
||||
if result is None:
|
||||
return
|
||||
|
||||
if len(result.chain) > 0:
|
||||
await event._pre_send()
|
||||
|
||||
if self.enable_seg and ((self.only_llm_result and result.is_llm_result()) or not self.only_llm_result):
|
||||
|
||||
if self.enable_seg and (
|
||||
(self.only_llm_result and result.is_llm_result())
|
||||
or not self.only_llm_result
|
||||
):
|
||||
decorated_comps = []
|
||||
if self.reply_with_mention:
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, At):
|
||||
decorated_comps.append(comp)
|
||||
result.chain.remove(comp)
|
||||
break
|
||||
if self.reply_with_quote:
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Reply):
|
||||
decorated_comps.append(comp)
|
||||
result.chain.remove(comp)
|
||||
break
|
||||
# 分段回复
|
||||
for comp in result.chain:
|
||||
i = await self._calc_comp_interval(comp)
|
||||
await asyncio.sleep(i)
|
||||
await event.send(MessageChain([comp]))
|
||||
await event.send(MessageChain([*decorated_comps, comp]))
|
||||
else:
|
||||
await event.send(result)
|
||||
await event._post_send()
|
||||
logger.info(f"AstrBot -> {event.get_sender_name()}/{event.get_sender_id()}: {event._outline_chain(result.chain)}")
|
||||
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(EventType.OnAfterMessageSentEvent)
|
||||
logger.info(
|
||||
f"AstrBot -> {event.get_sender_name()}/{event.get_sender_id()}: {event._outline_chain(result.chain)}"
|
||||
)
|
||||
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(
|
||||
EventType.OnAfterMessageSentEvent
|
||||
)
|
||||
for handler in handlers:
|
||||
# TODO: 如何让这里的 handler 也能使用 LLM 能力。也许需要将 LLMRequestSubStage 提取出来。
|
||||
await handler.handler(event)
|
||||
|
||||
event.clear_result()
|
||||
try:
|
||||
logger.debug(
|
||||
f"hook(on_after_message_sent) -> {star_map[handler.handler_module_path].name} - {handler.handler_name}"
|
||||
)
|
||||
await handler.handler(event)
|
||||
except BaseException:
|
||||
logger.error(traceback.format_exc())
|
||||
|
||||
if event.is_stopped():
|
||||
logger.info(
|
||||
f"{star_map[handler.handler_module_path].name} - {handler.handler_name} 终止了事件传播。"
|
||||
)
|
||||
return
|
||||
|
||||
event.clear_result()
|
||||
|
||||
@@ -7,63 +7,112 @@ from ..context import PipelineContext
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.platform.message_type import MessageType
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.message.components import Plain, Image, At, Reply, Record
|
||||
from astrbot.core.message.components import Plain, Image, At, Reply, Record, File, Node
|
||||
from astrbot.core import html_renderer
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
from astrbot.core.star.star import star_map
|
||||
|
||||
|
||||
@register_stage
|
||||
class ResultDecorateStage(Stage):
|
||||
async def initialize(self, ctx: PipelineContext):
|
||||
self.ctx = ctx
|
||||
self.reply_prefix = ctx.astrbot_config['platform_settings']['reply_prefix']
|
||||
self.reply_with_mention = ctx.astrbot_config['platform_settings']['reply_with_mention']
|
||||
self.reply_with_quote = ctx.astrbot_config['platform_settings']['reply_with_quote']
|
||||
self.t2i_word_threshold = ctx.astrbot_config['t2i_word_threshold']
|
||||
self.reply_prefix = ctx.astrbot_config["platform_settings"]["reply_prefix"]
|
||||
self.reply_with_mention = ctx.astrbot_config["platform_settings"][
|
||||
"reply_with_mention"
|
||||
]
|
||||
self.reply_with_quote = ctx.astrbot_config["platform_settings"][
|
||||
"reply_with_quote"
|
||||
]
|
||||
self.t2i_word_threshold = ctx.astrbot_config["t2i_word_threshold"]
|
||||
try:
|
||||
self.t2i_word_threshold = int(self.t2i_word_threshold)
|
||||
if self.t2i_word_threshold < 50:
|
||||
self.t2i_word_threshold = 50
|
||||
except BaseException:
|
||||
self.t2i_word_threshold = 150
|
||||
|
||||
|
||||
self.forward_threshold = ctx.astrbot_config["platform_settings"][
|
||||
"forward_threshold"
|
||||
]
|
||||
|
||||
# 分段回复
|
||||
self.words_count_threshold = int(ctx.astrbot_config['platform_settings']['segmented_reply']['words_count_threshold'])
|
||||
self.enable_segmented_reply = ctx.astrbot_config['platform_settings']['segmented_reply']['enable']
|
||||
self.only_llm_result = ctx.astrbot_config['platform_settings']['segmented_reply']['only_llm_result']
|
||||
self.regex = ctx.astrbot_config['platform_settings']['segmented_reply']['regex']
|
||||
|
||||
self.words_count_threshold = int(
|
||||
ctx.astrbot_config["platform_settings"]["segmented_reply"][
|
||||
"words_count_threshold"
|
||||
]
|
||||
)
|
||||
self.enable_segmented_reply = ctx.astrbot_config["platform_settings"][
|
||||
"segmented_reply"
|
||||
]["enable"]
|
||||
self.only_llm_result = ctx.astrbot_config["platform_settings"][
|
||||
"segmented_reply"
|
||||
]["only_llm_result"]
|
||||
self.regex = ctx.astrbot_config["platform_settings"]["segmented_reply"]["regex"]
|
||||
self.content_cleanup_rule = ctx.astrbot_config["platform_settings"][
|
||||
"segmented_reply"
|
||||
]["content_cleanup_rule"]
|
||||
|
||||
# exception
|
||||
self.content_safe_check_reply = ctx.astrbot_config['content_safety']['also_use_in_response']
|
||||
self.content_safe_check_reply = ctx.astrbot_config["content_safety"][
|
||||
"also_use_in_response"
|
||||
]
|
||||
self.content_safe_check_stage = None
|
||||
if self.content_safe_check_reply:
|
||||
for stage in registered_stages:
|
||||
if stage.__class__.__name__ == "ContentSafetyCheckStage":
|
||||
self.content_safe_check_stage = stage
|
||||
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
result = event.get_result()
|
||||
if result is None:
|
||||
if result is None or not result.chain:
|
||||
return
|
||||
|
||||
|
||||
# 回复时检查内容安全
|
||||
if self.content_safe_check_reply and self.content_safe_check_stage and result.is_llm_result():
|
||||
if (
|
||||
self.content_safe_check_reply
|
||||
and self.content_safe_check_stage
|
||||
and result.is_llm_result()
|
||||
):
|
||||
text = ""
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Plain):
|
||||
text += comp.text
|
||||
async for _ in self.content_safe_check_stage.process(event, check_text=text):
|
||||
async for _ in self.content_safe_check_stage.process(
|
||||
event, check_text=text
|
||||
):
|
||||
yield
|
||||
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(EventType.OnDecoratingResultEvent)
|
||||
|
||||
# 发送消息前事件钩子
|
||||
handlers = star_handlers_registry.get_handlers_by_event_type(
|
||||
EventType.OnDecoratingResultEvent
|
||||
)
|
||||
for handler in handlers:
|
||||
await handler.handler(event)
|
||||
|
||||
try:
|
||||
logger.debug(
|
||||
f"hook(on_decorating_result) -> {star_map[handler.handler_module_path].name} - {handler.handler_name}"
|
||||
)
|
||||
await handler.handler(event)
|
||||
if event.get_result() is None or not event.get_result().chain:
|
||||
logger.debug(
|
||||
f"hook(on_decorating_result) -> {star_map[handler.handler_module_path].name} - {handler.handler_name} 将消息结果清空。"
|
||||
)
|
||||
except BaseException:
|
||||
logger.error(traceback.format_exc())
|
||||
|
||||
if event.is_stopped():
|
||||
logger.info(
|
||||
f"{star_map[handler.handler_module_path].name} - {handler.handler_name} 终止了事件传播。"
|
||||
)
|
||||
return
|
||||
|
||||
# 需要再获取一次。插件可能直接对 chain 进行了替换。
|
||||
result = event.get_result()
|
||||
if result is None:
|
||||
return
|
||||
|
||||
|
||||
if len(result.chain) > 0:
|
||||
# 回复前缀
|
||||
if self.reply_prefix:
|
||||
@@ -71,10 +120,12 @@ class ResultDecorateStage(Stage):
|
||||
if isinstance(comp, Plain):
|
||||
comp.text = self.reply_prefix + comp.text
|
||||
break
|
||||
|
||||
# 分段回复
|
||||
|
||||
# 分段回复
|
||||
if self.enable_segmented_reply:
|
||||
if (self.only_llm_result and result.is_llm_result()) or not self.only_llm_result:
|
||||
if (
|
||||
self.only_llm_result and result.is_llm_result()
|
||||
) or not self.only_llm_result:
|
||||
new_chain = []
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Plain):
|
||||
@@ -82,20 +133,27 @@ class ResultDecorateStage(Stage):
|
||||
# 不分段回复
|
||||
new_chain.append(comp)
|
||||
continue
|
||||
split_response = re.findall(self.regex, comp.text)
|
||||
split_response = []
|
||||
for line in comp.text.split("\n"):
|
||||
split_response.extend(re.findall(self.regex, line))
|
||||
if not split_response:
|
||||
new_chain.append(comp)
|
||||
continue
|
||||
for seg in split_response:
|
||||
if seg:
|
||||
if self.content_cleanup_rule:
|
||||
seg = re.sub(self.content_cleanup_rule, "", seg)
|
||||
if seg.strip():
|
||||
new_chain.append(Plain(seg))
|
||||
else:
|
||||
# 非 Plain 类型的消息段不分段
|
||||
new_chain.append(comp)
|
||||
result.chain = new_chain
|
||||
|
||||
|
||||
# TTS
|
||||
if self.ctx.astrbot_config['provider_tts_settings']['enable'] and result.is_llm_result():
|
||||
if (
|
||||
self.ctx.astrbot_config["provider_tts_settings"]["enable"]
|
||||
and result.is_llm_result()
|
||||
):
|
||||
tts_provider = self.ctx.plugin_manager.context.provider_manager.curr_tts_provider_inst
|
||||
new_chain = []
|
||||
for comp in result.chain:
|
||||
@@ -105,9 +163,13 @@ class ResultDecorateStage(Stage):
|
||||
audio_path = await tts_provider.get_audio(comp.text)
|
||||
logger.info("TTS 结果: " + audio_path)
|
||||
if audio_path:
|
||||
new_chain.append(Record(file=audio_path, url=audio_path))
|
||||
new_chain.append(
|
||||
Record(file=audio_path, url=audio_path)
|
||||
)
|
||||
else:
|
||||
logger.error(f"由于 TTS 音频文件没找到,消息段转语音失败: {comp.text}")
|
||||
logger.error(
|
||||
f"由于 TTS 音频文件没找到,消息段转语音失败: {comp.text}"
|
||||
)
|
||||
new_chain.append(comp)
|
||||
except BaseException:
|
||||
logger.error(traceback.format_exc())
|
||||
@@ -116,9 +178,11 @@ class ResultDecorateStage(Stage):
|
||||
else:
|
||||
new_chain.append(comp)
|
||||
result.chain = new_chain
|
||||
|
||||
|
||||
# 文本转图片
|
||||
elif (result.use_t2i_ is None and self.ctx.astrbot_config['t2i']) or result.use_t2i_:
|
||||
elif (
|
||||
result.use_t2i_ is None and self.ctx.astrbot_config["t2i"]
|
||||
) or result.use_t2i_:
|
||||
plain_str = ""
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Plain):
|
||||
@@ -133,16 +197,39 @@ class ResultDecorateStage(Stage):
|
||||
logger.error("文本转图片失败,使用文本发送。")
|
||||
return
|
||||
if time.time() - render_start > 3:
|
||||
logger.warning("文本转图片耗时超过了 3 秒,如果觉得很慢可以使用 /t2i 关闭文本转图片模式。")
|
||||
logger.warning(
|
||||
"文本转图片耗时超过了 3 秒,如果觉得很慢可以使用 /t2i 关闭文本转图片模式。"
|
||||
)
|
||||
if url:
|
||||
result.chain = [Image.fromURL(url)]
|
||||
|
||||
# at 回复
|
||||
if self.reply_with_mention and event.get_message_type() != MessageType.FRIEND_MESSAGE:
|
||||
result.chain.insert(0, At(qq=event.get_sender_id(), name=event.get_sender_name()))
|
||||
if len(result.chain) > 1 and isinstance(result.chain[1], Plain):
|
||||
result.chain[1].text = "\n" + result.chain[1].text
|
||||
|
||||
# 引用回复
|
||||
if self.reply_with_quote:
|
||||
result.chain.insert(0, Reply(id=event.message_obj.message_id))
|
||||
|
||||
# 触发转发消息
|
||||
has_forwarded = False
|
||||
if event.get_platform_name() == "aiocqhttp":
|
||||
word_cnt = 0
|
||||
for comp in result.chain:
|
||||
if isinstance(comp, Plain):
|
||||
word_cnt += len(comp.text)
|
||||
if word_cnt > self.forward_threshold:
|
||||
node = Node(
|
||||
uin=event.get_self_id(), name="AstrBot", content=[*result.chain]
|
||||
)
|
||||
result.chain = [node]
|
||||
has_forwarded = True
|
||||
|
||||
if not has_forwarded:
|
||||
# at 回复
|
||||
if (
|
||||
self.reply_with_mention
|
||||
and event.get_message_type() != MessageType.FRIEND_MESSAGE
|
||||
):
|
||||
result.chain.insert(
|
||||
0, At(qq=event.get_sender_id(), name=event.get_sender_name())
|
||||
)
|
||||
if len(result.chain) > 1 and isinstance(result.chain[1], Plain):
|
||||
result.chain[1].text = "\n" + result.chain[1].text
|
||||
|
||||
# 引用回复
|
||||
if self.reply_with_quote:
|
||||
if not any(isinstance(item, File) for item in result.chain):
|
||||
result.chain.insert(0, Reply(id=event.message_obj.message_id))
|
||||
|
||||
@@ -5,44 +5,52 @@ from typing import AsyncGenerator
|
||||
from astrbot.core.platform import AstrMessageEvent
|
||||
from astrbot.core import logger
|
||||
|
||||
class PipelineScheduler():
|
||||
|
||||
class PipelineScheduler:
|
||||
def __init__(self, context: PipelineContext):
|
||||
registered_stages.sort(key=lambda x: STAGES_ORDER.index(x.__class__ .__name__))
|
||||
registered_stages.sort(key=lambda x: STAGES_ORDER.index(x.__class__.__name__))
|
||||
self.ctx = context
|
||||
|
||||
|
||||
async def initialize(self):
|
||||
for stage in registered_stages:
|
||||
logger.debug(f"初始化阶段 {stage.__class__ .__name__}")
|
||||
|
||||
# logger.debug(f"初始化阶段 {stage.__class__ .__name__}")
|
||||
|
||||
await stage.initialize(self.ctx)
|
||||
|
||||
|
||||
async def _process_stages(self, event: AstrMessageEvent, from_stage=0):
|
||||
for i in range(from_stage, len(registered_stages)):
|
||||
stage = registered_stages[i]
|
||||
logger.debug(f"执行阶段 {stage.__class__ .__name__}")
|
||||
# logger.debug(f"执行阶段 {stage.__class__ .__name__}")
|
||||
coro = stage.process(event)
|
||||
if isinstance(coro, AsyncGenerator):
|
||||
async for _ in coro:
|
||||
if event.is_stopped():
|
||||
logger.debug(f"阶段 {stage.__class__ .__name__} 已终止事件传播。")
|
||||
logger.debug(
|
||||
f"阶段 {stage.__class__.__name__} 已终止事件传播。"
|
||||
)
|
||||
break
|
||||
await self._process_stages(event, i + 1)
|
||||
if event.is_stopped():
|
||||
logger.debug(
|
||||
f"阶段 {stage.__class__.__name__} 已终止事件传播。"
|
||||
)
|
||||
break
|
||||
else:
|
||||
await coro
|
||||
|
||||
if event.is_stopped():
|
||||
logger.debug(f"阶段 {stage.__class__ .__name__} 已终止事件传播。")
|
||||
logger.debug(f"阶段 {stage.__class__.__name__} 已终止事件传播。")
|
||||
break
|
||||
|
||||
if event.is_stopped():
|
||||
logger.debug(f"阶段 {stage.__class__ .__name__} 已终止事件传播。")
|
||||
logger.debug(f"阶段 {stage.__class__.__name__} 已终止事件传播。")
|
||||
break
|
||||
|
||||
|
||||
async def execute(self, event: AstrMessageEvent):
|
||||
'''执行 pipeline'''
|
||||
"""执行 pipeline"""
|
||||
await self._process_stages(event)
|
||||
|
||||
|
||||
if not event._has_send_oper and event.get_platform_name() == "webchat":
|
||||
await event.send(None)
|
||||
|
||||
logger.debug("pipeline 执行完毕。")
|
||||
|
||||
logger.debug("pipeline 执行完毕。")
|
||||
|
||||
@@ -1,60 +1,67 @@
|
||||
from __future__ import annotations
|
||||
import abc
|
||||
import inspect
|
||||
from astrbot.api import logger
|
||||
from typing import List, AsyncGenerator, Union, Awaitable
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from .context import PipelineContext
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, CommandResult
|
||||
|
||||
registered_stages: List[Stage] = []
|
||||
'''维护了所有已注册的 Stage 实现类'''
|
||||
"""维护了所有已注册的 Stage 实现类"""
|
||||
|
||||
|
||||
def register_stage(cls):
|
||||
'''一个简单的装饰器,用于注册 pipeline 包下的 Stage 实现类
|
||||
'''
|
||||
"""一个简单的装饰器,用于注册 pipeline 包下的 Stage 实现类"""
|
||||
registered_stages.append(cls())
|
||||
return cls
|
||||
|
||||
|
||||
|
||||
class Stage(abc.ABC):
|
||||
'''描述一个 Pipeline 的某个阶段
|
||||
'''
|
||||
|
||||
"""描述一个 Pipeline 的某个阶段"""
|
||||
|
||||
@abc.abstractmethod
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
'''初始化阶段
|
||||
'''
|
||||
"""初始化阶段"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
'''处理事件
|
||||
'''
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
"""处理事件"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
async def _call_handler(
|
||||
self,
|
||||
self,
|
||||
ctx: PipelineContext,
|
||||
event: AstrMessageEvent,
|
||||
event: AstrMessageEvent,
|
||||
handler: Awaitable,
|
||||
**params
|
||||
*args,
|
||||
**kwargs,
|
||||
) -> AsyncGenerator[None, None]:
|
||||
'''调用 Handler。'''
|
||||
"""调用 Handler。"""
|
||||
# 判断 handler 是否是类方法(通过装饰器注册的没有 __self__ 属性)
|
||||
ready_to_call = None
|
||||
try:
|
||||
ready_to_call = handler(event, **params)
|
||||
ready_to_call = handler(event, *args, **kwargs)
|
||||
except TypeError as e:
|
||||
# 向下兼容
|
||||
ready_to_call = handler(event, ctx.plugin_manager.context, **params)
|
||||
|
||||
logger.debug(str(e))
|
||||
ready_to_call = handler(event, ctx.plugin_manager.context, *args, **kwargs)
|
||||
|
||||
if isinstance(ready_to_call, AsyncGenerator):
|
||||
_has_yielded = False
|
||||
async for ret in ready_to_call:
|
||||
# 如果处理函数是生成器,返回值只能是 MessageEventResult 或者 None(无返回值)
|
||||
_has_yielded = True
|
||||
if isinstance(ret, (MessageEventResult, CommandResult)):
|
||||
event.set_result(ret)
|
||||
yield
|
||||
else:
|
||||
yield ret
|
||||
if not _has_yielded:
|
||||
yield
|
||||
elif inspect.iscoroutine(ready_to_call):
|
||||
# 如果只是一个 coroutine
|
||||
ret = await ready_to_call
|
||||
@@ -62,4 +69,4 @@ class Stage(abc.ABC):
|
||||
event.set_result(ret)
|
||||
yield
|
||||
else:
|
||||
yield ret
|
||||
yield ret
|
||||
|
||||
@@ -3,11 +3,12 @@ from ..context import PipelineContext
|
||||
from typing import Union, AsyncGenerator
|
||||
from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, MessageChain
|
||||
from astrbot.core.message.components import At, Reply
|
||||
from astrbot.core.message.components import At
|
||||
from astrbot.core.star.star_handler import star_handlers_registry, EventType
|
||||
from astrbot.core.star.filter.command_group import CommandGroupFilter
|
||||
from astrbot.core.star.star import star_map
|
||||
from astrbot.core.star.filter.permission import PermissionTypeFilter
|
||||
|
||||
|
||||
@register_stage
|
||||
class WakingCheckStage(Stage):
|
||||
"""检查是否需要唤醒。唤醒机器人有如下几点条件:
|
||||
@@ -76,34 +77,19 @@ class WakingCheckStage(Stage):
|
||||
# 检查插件的 handler filter
|
||||
activated_handlers = []
|
||||
handlers_parsed_params = {} # 注册了指令的 handler
|
||||
for handler in star_handlers_registry.get_handlers_by_event_type(EventType.AdapterMessageEvent):
|
||||
# filter 需要满足 AND 的逻辑关系
|
||||
|
||||
for handler in star_handlers_registry.get_handlers_by_event_type(
|
||||
EventType.AdapterMessageEvent
|
||||
):
|
||||
# filter 需满足 AND 逻辑关系
|
||||
passed = True
|
||||
child_command_handler_md = None
|
||||
|
||||
permission_not_pass = False
|
||||
|
||||
if len(handler.event_filters) == 0:
|
||||
# 不可能有这种情况, 也不允许有这种情况
|
||||
continue
|
||||
|
||||
if 'sub_command' in handler.extras_configs:
|
||||
# 如果是子指令
|
||||
continue
|
||||
|
||||
for filter in handler.event_filters:
|
||||
try:
|
||||
if isinstance(filter, CommandGroupFilter):
|
||||
"""如果指令组过滤成功, 会返回叶子指令的 StarHandlerMetadata"""
|
||||
ok, child_command_handler_md = filter.filter(
|
||||
event, self.ctx.astrbot_config
|
||||
)
|
||||
if not ok:
|
||||
passed = False
|
||||
else:
|
||||
handler = child_command_handler_md # handler 覆盖
|
||||
break
|
||||
elif isinstance(filter, PermissionTypeFilter):
|
||||
if isinstance(filter, PermissionTypeFilter):
|
||||
if not filter.filter(event, self.ctx.astrbot_config):
|
||||
permission_not_pass = True
|
||||
else:
|
||||
@@ -111,25 +97,25 @@ class WakingCheckStage(Stage):
|
||||
passed = False
|
||||
break
|
||||
except Exception as e:
|
||||
# event.set_result(MessageEventResult().message(f"插件 {handler.handler_full_name} 报错:{e}"))
|
||||
# yield
|
||||
await event.send(
|
||||
MessageEventResult().message(
|
||||
f"插件 {handler.handler_full_name} 报错:{e}"
|
||||
f"插件 {star_map[handler.handler_module_path].name}: {e}"
|
||||
)
|
||||
)
|
||||
event.stop_event()
|
||||
passed = False
|
||||
break
|
||||
|
||||
if passed:
|
||||
|
||||
if permission_not_pass:
|
||||
if self.no_permission_reply:
|
||||
await event.send(MessageChain().message(f"ID {event.get_sender_id()} 权限不足。通过 /sid 获取 ID 并请管理员添加。"))
|
||||
await event.send(
|
||||
MessageChain().message(
|
||||
f"ID {event.get_sender_id()} 权限不足。通过 /sid 获取 ID 并请管理员添加。"
|
||||
)
|
||||
)
|
||||
event.stop_event()
|
||||
return
|
||||
|
||||
|
||||
is_wake = True
|
||||
event.is_wake = True
|
||||
|
||||
@@ -138,6 +124,7 @@ class WakingCheckStage(Stage):
|
||||
handlers_parsed_params[handler.handler_full_name] = event.get_extra(
|
||||
"parsed_params"
|
||||
)
|
||||
|
||||
event.clear_extra()
|
||||
|
||||
event.set_extra("activated_handlers", activated_handlers)
|
||||
|
||||
@@ -5,38 +5,55 @@ from astrbot.core.platform.astr_message_event import AstrMessageEvent
|
||||
from astrbot.core.platform.message_type import MessageType
|
||||
from astrbot.core import logger
|
||||
|
||||
|
||||
@register_stage
|
||||
class WhitelistCheckStage(Stage):
|
||||
'''检查是否在群聊/私聊白名单
|
||||
'''
|
||||
"""检查是否在群聊/私聊白名单"""
|
||||
|
||||
async def initialize(self, ctx: PipelineContext) -> None:
|
||||
self.enable_whitelist_check = ctx.astrbot_config['platform_settings']['enable_id_white_list']
|
||||
self.whitelist = ctx.astrbot_config['platform_settings']['id_whitelist']
|
||||
self.wl_ignore_admin_on_group = ctx.astrbot_config['platform_settings']['wl_ignore_admin_on_group']
|
||||
self.wl_ignore_admin_on_friend = ctx.astrbot_config['platform_settings']['wl_ignore_admin_on_friend']
|
||||
self.wl_log = ctx.astrbot_config['platform_settings']['id_whitelist_log']
|
||||
|
||||
async def process(self, event: AstrMessageEvent) -> Union[None, AsyncGenerator[None, None]]:
|
||||
self.enable_whitelist_check = ctx.astrbot_config["platform_settings"][
|
||||
"enable_id_white_list"
|
||||
]
|
||||
self.whitelist = ctx.astrbot_config["platform_settings"]["id_whitelist"]
|
||||
self.wl_ignore_admin_on_group = ctx.astrbot_config["platform_settings"][
|
||||
"wl_ignore_admin_on_group"
|
||||
]
|
||||
self.wl_ignore_admin_on_friend = ctx.astrbot_config["platform_settings"][
|
||||
"wl_ignore_admin_on_friend"
|
||||
]
|
||||
self.wl_log = ctx.astrbot_config["platform_settings"]["id_whitelist_log"]
|
||||
|
||||
async def process(
|
||||
self, event: AstrMessageEvent
|
||||
) -> Union[None, AsyncGenerator[None, None]]:
|
||||
if not self.enable_whitelist_check:
|
||||
# 白名单检查未启用
|
||||
return
|
||||
|
||||
|
||||
if len(self.whitelist) == 0:
|
||||
# 白名单为空,不检查
|
||||
return
|
||||
|
||||
if event.get_platform_name() == 'webchat':
|
||||
|
||||
if event.get_platform_name() == "webchat":
|
||||
# WebChat 豁免
|
||||
return
|
||||
|
||||
|
||||
# 检查是否在白名单
|
||||
if self.wl_ignore_admin_on_group:
|
||||
if event.role == 'admin' and event.get_message_type() == MessageType.GROUP_MESSAGE:
|
||||
if (
|
||||
event.role == "admin"
|
||||
and event.get_message_type() == MessageType.GROUP_MESSAGE
|
||||
):
|
||||
return
|
||||
if self.wl_ignore_admin_on_friend:
|
||||
if event.role == 'admin' and event.get_message_type() == MessageType.FRIEND_MESSAGE:
|
||||
if (
|
||||
event.role == "admin"
|
||||
and event.get_message_type() == MessageType.FRIEND_MESSAGE
|
||||
):
|
||||
return
|
||||
if event.unified_msg_origin not in self.whitelist:
|
||||
if self.wl_log:
|
||||
logger.info(f"会话 ID {event.unified_msg_origin} 不在会话白名单中,已终止事件传播。请在配置文件中添加该会话 ID 到白名单。")
|
||||
event.stop_event()
|
||||
logger.info(
|
||||
f"会话 ID {event.unified_msg_origin} 不在会话白名单中,已终止事件传播。请在配置文件中添加该会话 ID 到白名单。"
|
||||
)
|
||||
event.stop_event()
|
||||
|
||||
@@ -1,4 +1,13 @@
|
||||
from .platform import Platform
|
||||
from .astr_message_event import AstrMessageEvent
|
||||
from .platform_metadata import PlatformMetadata
|
||||
from .astrbot_message import AstrBotMessage, MessageMember, MessageType
|
||||
from .astrbot_message import AstrBotMessage, MessageMember, MessageType
|
||||
|
||||
__all__ = [
|
||||
"Platform",
|
||||
"AstrMessageEvent",
|
||||
"PlatformMetadata",
|
||||
"AstrBotMessage",
|
||||
"MessageMember",
|
||||
"MessageType",
|
||||
]
|
||||
|
||||
@@ -5,72 +5,85 @@ from .platform_metadata import PlatformMetadata
|
||||
from astrbot.core.message.message_event_result import MessageEventResult, MessageChain
|
||||
from astrbot.core.platform.message_type import MessageType
|
||||
from typing import List, Union
|
||||
from astrbot.core.message.components import Plain, Image, BaseMessageComponent, Face, At, AtAll, Forward
|
||||
from astrbot.core.message.components import (
|
||||
Plain,
|
||||
Image,
|
||||
BaseMessageComponent,
|
||||
Face,
|
||||
At,
|
||||
AtAll,
|
||||
Forward,
|
||||
)
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
from astrbot.core.provider.entites import ProviderRequest
|
||||
from astrbot.core.db.po import Conversation
|
||||
|
||||
|
||||
@dataclass
|
||||
class MessageSesion:
|
||||
platform_name: str
|
||||
message_type: MessageType
|
||||
session_id: str
|
||||
|
||||
|
||||
def __str__(self):
|
||||
return f"{self.platform_name}:{self.message_type.value}:{self.session_id}"
|
||||
|
||||
|
||||
@staticmethod
|
||||
def from_str(session_str: str):
|
||||
platform_name, message_type, session_id = session_str.split(":")
|
||||
return MessageSesion(platform_name, MessageType(message_type), session_id)
|
||||
|
||||
|
||||
class AstrMessageEvent(abc.ABC):
|
||||
def __init__(self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,):
|
||||
def __init__(
|
||||
self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,
|
||||
):
|
||||
self.message_str = message_str
|
||||
'''纯文本的消息'''
|
||||
"""纯文本的消息"""
|
||||
self.message_obj = message_obj
|
||||
'''消息对象,AstrBotMessage。带有完整的消息结构。'''
|
||||
"""消息对象, AstrBotMessage。带有完整的消息结构。"""
|
||||
self.platform_meta = platform_meta
|
||||
'''消息平台的信息, 其中 name 是平台的类型,如 aiocqhttp'''
|
||||
"""消息平台的信息, 其中 name 是平台的类型,如 aiocqhttp"""
|
||||
self.session_id = session_id
|
||||
'''用户的会话 ID。可以直接使用下面的 unified_msg_origin'''
|
||||
"""用户的会话 ID。可以直接使用下面的 unified_msg_origin"""
|
||||
self.role = "member"
|
||||
'''用户是否是管理员。如果是管理员,这里是 admin'''
|
||||
self.is_wake = False # 是否通过 WakingStage
|
||||
'''是否唤醒'''
|
||||
"""用户是否是管理员。如果是管理员,这里是 admin"""
|
||||
self.is_wake = False
|
||||
"""是否唤醒(是否通过 WakingStage)"""
|
||||
self.is_at_or_wake_command = False
|
||||
'''是否是 At 机器人或者带有唤醒词或者是私聊(事件监听器会让 is_wake 设为 True,但是不会让这个属性置为 True)'''
|
||||
"""是否是 At 机器人或者带有唤醒词或者是私聊(插件注册的事件监听器会让 is_wake 设为 True, 但是不会让这个属性置为 True)"""
|
||||
self._extras = {}
|
||||
self.session = MessageSesion(
|
||||
platform_name=platform_meta.name,
|
||||
message_type=message_obj.type,
|
||||
session_id=session_id
|
||||
session_id=session_id,
|
||||
)
|
||||
self.unified_msg_origin = str(self.session)
|
||||
'''统一的消息来源字符串。格式为 platform_name:message_type:session_id'''
|
||||
"""统一的消息来源字符串。格式为 platform_name:message_type:session_id"""
|
||||
self._result: MessageEventResult = None
|
||||
'''消息事件的结果'''
|
||||
|
||||
self._has_send_oper = False
|
||||
'''是否有过至少一次发送操作'''
|
||||
|
||||
|
||||
"""消息事件的结果"""
|
||||
|
||||
self._has_send_oper = False
|
||||
"""在此次事件中是否有过至少一次发送消息的操作"""
|
||||
self.call_llm = False
|
||||
"""是否在此消息事件中禁止默认的 LLM 请求"""
|
||||
|
||||
# back_compability
|
||||
self.platform = platform_meta
|
||||
|
||||
|
||||
def get_platform_name(self):
|
||||
return self.platform_meta.name
|
||||
|
||||
|
||||
def get_message_str(self) -> str:
|
||||
'''
|
||||
"""
|
||||
获取消息字符串。
|
||||
'''
|
||||
"""
|
||||
return self.message_str
|
||||
|
||||
|
||||
def _outline_chain(self, chain: List[BaseMessageComponent]) -> str:
|
||||
outline = ""
|
||||
for i in chain:
|
||||
@@ -90,180 +103,183 @@ class AstrMessageEvent(abc.ABC):
|
||||
else:
|
||||
outline += f"[{i.type}]"
|
||||
return outline
|
||||
|
||||
|
||||
def get_message_outline(self) -> str:
|
||||
'''
|
||||
"""
|
||||
获取消息概要。
|
||||
|
||||
|
||||
除了文本消息外,其他消息类型会被转换为对应的占位符。如图片消息会被转换为 [图片]。
|
||||
'''
|
||||
"""
|
||||
return self._outline_chain(self.message_obj.message)
|
||||
|
||||
|
||||
def get_messages(self) -> List[BaseMessageComponent]:
|
||||
'''
|
||||
"""
|
||||
获取消息链。
|
||||
'''
|
||||
"""
|
||||
return self.message_obj.message
|
||||
|
||||
|
||||
def get_message_type(self) -> MessageType:
|
||||
'''
|
||||
"""
|
||||
获取消息类型。
|
||||
'''
|
||||
"""
|
||||
return self.message_obj.type
|
||||
|
||||
|
||||
def get_session_id(self) -> str:
|
||||
'''
|
||||
"""
|
||||
获取会话id。
|
||||
'''
|
||||
"""
|
||||
return self.session_id
|
||||
|
||||
|
||||
def get_group_id(self) -> str:
|
||||
'''
|
||||
"""
|
||||
获取群组id。如果不是群组消息,返回空字符串。
|
||||
'''
|
||||
"""
|
||||
return self.message_obj.group_id
|
||||
|
||||
|
||||
def get_self_id(self) -> str:
|
||||
'''
|
||||
"""
|
||||
获取机器人自身的id。
|
||||
'''
|
||||
"""
|
||||
return self.message_obj.self_id
|
||||
|
||||
|
||||
def get_sender_id(self) -> str:
|
||||
'''
|
||||
"""
|
||||
获取消息发送者的id。
|
||||
'''
|
||||
"""
|
||||
return self.message_obj.sender.user_id
|
||||
|
||||
|
||||
def get_sender_name(self) -> str:
|
||||
'''
|
||||
"""
|
||||
获取消息发送者的名称。(可能会返回空字符串)
|
||||
'''
|
||||
"""
|
||||
return self.message_obj.sender.nickname
|
||||
|
||||
|
||||
def set_extra(self, key, value):
|
||||
'''
|
||||
"""
|
||||
设置额外的信息。
|
||||
'''
|
||||
"""
|
||||
self._extras[key] = value
|
||||
|
||||
def get_extra(self, key = None):
|
||||
'''
|
||||
|
||||
def get_extra(self, key=None):
|
||||
"""
|
||||
获取额外的信息。
|
||||
'''
|
||||
"""
|
||||
if key is None:
|
||||
return self._extras
|
||||
return self._extras.get(key, None)
|
||||
|
||||
|
||||
def clear_extra(self):
|
||||
'''
|
||||
"""
|
||||
清除额外的信息。
|
||||
'''
|
||||
"""
|
||||
self._extras.clear()
|
||||
|
||||
|
||||
def is_private_chat(self) -> bool:
|
||||
'''
|
||||
"""
|
||||
是否是私聊。
|
||||
'''
|
||||
"""
|
||||
return self.message_obj.type.value == (MessageType.FRIEND_MESSAGE).value
|
||||
|
||||
|
||||
def is_wake_up(self) -> bool:
|
||||
'''
|
||||
"""
|
||||
是否是唤醒机器人的事件。
|
||||
'''
|
||||
"""
|
||||
return self.is_wake
|
||||
|
||||
|
||||
def is_admin(self) -> bool:
|
||||
'''
|
||||
"""
|
||||
是否是管理员。
|
||||
'''
|
||||
"""
|
||||
return self.role == "admin"
|
||||
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
'''
|
||||
"""
|
||||
发送消息到消息平台。
|
||||
'''
|
||||
await Metric.upload(msg_event_tick = 1, adapter_name = self.platform_meta.name)
|
||||
"""
|
||||
await Metric.upload(msg_event_tick=1, adapter_name=self.platform_meta.name)
|
||||
self._has_send_oper = True
|
||||
|
||||
|
||||
async def _pre_send(self):
|
||||
'''调度器会在执行 send() 前调用该方法'''
|
||||
pass
|
||||
|
||||
"""调度器会在执行 send() 前调用该方法"""
|
||||
|
||||
async def _post_send(self):
|
||||
'''调度器会在执行 send() 后调用该方法'''
|
||||
pass
|
||||
|
||||
|
||||
"""调度器会在执行 send() 后调用该方法"""
|
||||
|
||||
def set_result(self, result: Union[MessageEventResult, str]):
|
||||
'''设置消息事件的结果。
|
||||
|
||||
"""设置消息事件的结果。
|
||||
|
||||
Note:
|
||||
事件处理器可以通过设置结果来控制事件是否继续传播,并向消息适配器发送消息。
|
||||
|
||||
|
||||
如果没有设置 `MessageEventResult` 中的 result_type,默认为 CONTINUE。即事件将会继续向后面的 listener 或者 command 传播。
|
||||
|
||||
|
||||
Example:
|
||||
```
|
||||
async def ban_handler(self, event: AstrMessageEvent):
|
||||
if event.get_sender_id() in self.blacklist:
|
||||
event.set_result(MessageEventResult().set_console_log("由于用户在黑名单,因此消息事件中断处理。")).set_result_type(EventResultType.STOP)
|
||||
return
|
||||
|
||||
|
||||
async def check_count(self, event: AstrMessageEvent):
|
||||
self.count += 1
|
||||
event.set_result(MessageEventResult().set_console_log("数量已增加", logging.DEBUG).set_result_type(EventResultType.CONTINUE))
|
||||
return
|
||||
```
|
||||
'''
|
||||
"""
|
||||
if isinstance(result, str):
|
||||
result = MessageEventResult().message(result)
|
||||
self._result = result
|
||||
|
||||
|
||||
def stop_event(self):
|
||||
'''终止事件传播。
|
||||
'''
|
||||
"""终止事件传播。"""
|
||||
if self._result is None:
|
||||
self.set_result(MessageEventResult().stop_event())
|
||||
else:
|
||||
self._result.stop_event()
|
||||
|
||||
|
||||
def continue_event(self):
|
||||
'''继续事件传播。
|
||||
'''
|
||||
"""继续事件传播。"""
|
||||
if self._result is None:
|
||||
self.set_result(MessageEventResult().continue_event())
|
||||
else:
|
||||
self._result.continue_event()
|
||||
|
||||
|
||||
def is_stopped(self) -> bool:
|
||||
'''
|
||||
"""
|
||||
是否终止事件传播。
|
||||
'''
|
||||
"""
|
||||
if self._result is None:
|
||||
return False # 默认是继续传播
|
||||
return self._result.is_stopped()
|
||||
|
||||
return False # 默认是继续传播
|
||||
return self._result.is_stopped()
|
||||
|
||||
def should_call_llm(self, call_llm: bool):
|
||||
"""
|
||||
是否在此消息事件中禁止默认的 LLM 请求。
|
||||
|
||||
只会阻止 AstrBot 默认的 LLM 请求链路,不会阻止插件中的 LLM 请求。
|
||||
"""
|
||||
self.call_llm = call_llm
|
||||
|
||||
def get_result(self) -> MessageEventResult:
|
||||
'''
|
||||
"""
|
||||
获取消息事件的结果。
|
||||
'''
|
||||
"""
|
||||
return self._result
|
||||
|
||||
|
||||
def clear_result(self):
|
||||
'''
|
||||
"""
|
||||
清除消息事件的结果。
|
||||
'''
|
||||
"""
|
||||
self._result = None
|
||||
|
||||
'''消息链相关'''
|
||||
|
||||
|
||||
"""消息链相关"""
|
||||
|
||||
def make_result(self) -> MessageEventResult:
|
||||
'''
|
||||
"""
|
||||
创建一个空的消息事件结果。
|
||||
|
||||
|
||||
Example:
|
||||
|
||||
|
||||
```python
|
||||
# 纯文本回复
|
||||
yield event.make_result().message("Hi")
|
||||
@@ -271,65 +287,76 @@ class AstrMessageEvent(abc.ABC):
|
||||
yield event.make_result().url_image("https://example.com/image.jpg")
|
||||
yield event.make_result().file_image("image.jpg")
|
||||
```
|
||||
'''
|
||||
"""
|
||||
return MessageEventResult()
|
||||
|
||||
|
||||
def plain_result(self, text: str) -> MessageEventResult:
|
||||
'''
|
||||
"""
|
||||
创建一个空的消息事件结果,只包含一条文本消息。
|
||||
'''
|
||||
"""
|
||||
return MessageEventResult().message(text)
|
||||
|
||||
|
||||
def image_result(self, url_or_path: str) -> MessageEventResult:
|
||||
'''
|
||||
"""
|
||||
创建一个空的消息事件结果,只包含一条图片消息。
|
||||
|
||||
|
||||
根据开头是否包含 http 来判断是网络图片还是本地图片。
|
||||
'''
|
||||
"""
|
||||
if url_or_path.startswith("http"):
|
||||
return MessageEventResult().url_image(url_or_path)
|
||||
return MessageEventResult().file_image(url_or_path)
|
||||
|
||||
|
||||
def chain_result(self, chain: List[BaseMessageComponent]) -> MessageEventResult:
|
||||
'''
|
||||
"""
|
||||
创建一个空的消息事件结果,包含指定的消息链。
|
||||
'''
|
||||
"""
|
||||
mer = MessageEventResult()
|
||||
mer.chain = chain
|
||||
return mer
|
||||
|
||||
'''LLM 请求相关'''
|
||||
|
||||
|
||||
"""LLM 请求相关"""
|
||||
|
||||
def request_llm(
|
||||
self,
|
||||
prompt: str,
|
||||
func_tool_manager = None,
|
||||
func_tool_manager=None,
|
||||
session_id: str = None,
|
||||
image_urls: List[str] = [],
|
||||
contexts: List = [],
|
||||
system_prompt: str = "",
|
||||
conversation: Conversation = None
|
||||
conversation: Conversation = None,
|
||||
) -> ProviderRequest:
|
||||
'''
|
||||
"""
|
||||
创建一个 LLM 请求。
|
||||
|
||||
|
||||
Examples:
|
||||
```py
|
||||
yield event.request_llm(prompt="hi")
|
||||
```
|
||||
prompt: 提示词
|
||||
|
||||
system_prompt: 系统提示词
|
||||
|
||||
session_id: 已经过时,留空即可
|
||||
|
||||
image_urls: 可以是 base64:// 或者 http:// 开头的图片链接,也可以是本地图片路径。
|
||||
contexts: 当指定 contexts 时,将会使用 contexts 作为上下文。
|
||||
|
||||
contexts: 当指定 contexts 时,将会使用 contexts 作为上下文。如果同时传入了 conversation,将会忽略 conversation。
|
||||
|
||||
func_tool_manager: 函数工具管理器,用于调用函数工具。用 self.context.get_llm_tool_manager() 获取。
|
||||
|
||||
conversation: 可选。如果指定,将在指定的对话中进行 LLM 请求。对话的人格会被用于 LLM 请求,并且结果将会被记录到对话中。
|
||||
'''
|
||||
"""
|
||||
|
||||
if len(contexts) > 0 and conversation:
|
||||
conversation = None
|
||||
|
||||
return ProviderRequest(
|
||||
prompt = prompt,
|
||||
session_id = session_id,
|
||||
image_urls = image_urls,
|
||||
func_tool = func_tool_manager,
|
||||
contexts = contexts,
|
||||
system_prompt = system_prompt,
|
||||
conversation=conversation
|
||||
)
|
||||
prompt=prompt,
|
||||
session_id=session_id,
|
||||
image_urls=image_urls,
|
||||
func_tool=func_tool_manager,
|
||||
contexts=contexts,
|
||||
system_prompt=system_prompt,
|
||||
conversation=conversation,
|
||||
)
|
||||
|
||||
@@ -4,26 +4,29 @@ from dataclasses import dataclass
|
||||
from astrbot.core.message.components import BaseMessageComponent
|
||||
from .message_type import MessageType
|
||||
|
||||
|
||||
@dataclass
|
||||
class MessageMember():
|
||||
class MessageMember:
|
||||
user_id: str # 发送者id
|
||||
nickname: str = None
|
||||
|
||||
|
||||
class AstrBotMessage:
|
||||
'''
|
||||
"""
|
||||
AstrBot 的消息对象
|
||||
'''
|
||||
"""
|
||||
|
||||
type: MessageType # 消息类型
|
||||
self_id: str # 机器人的识别id
|
||||
session_id: str # 会话id。取决于 unique_session 的设置。
|
||||
message_id: str # 消息id
|
||||
group_id: str = "" # 群组id,如果为私聊,则为空
|
||||
group_id: str = "" # 群组id,如果为私聊,则为空
|
||||
sender: MessageMember # 发送者
|
||||
message: List[BaseMessageComponent] # 消息链使用 Nakuru 的消息链格式
|
||||
message_str: str # 最直观的纯文本消息字符串
|
||||
raw_message: object
|
||||
timestamp: int # 消息时间戳
|
||||
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.timestamp = int(time.time())
|
||||
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
import traceback
|
||||
import asyncio
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from .platform import Platform
|
||||
from typing import List
|
||||
@@ -6,48 +8,135 @@ from .register import platform_cls_map
|
||||
from astrbot.core import logger
|
||||
from .sources.webchat.webchat_adapter import WebChatAdapter
|
||||
|
||||
class PlatformManager():
|
||||
|
||||
class PlatformManager:
|
||||
def __init__(self, config: AstrBotConfig, event_queue: Queue):
|
||||
self.platform_insts: List[Platform] = []
|
||||
'''加载的 Platform 的实例'''
|
||||
|
||||
self.platforms_config = config['platform']
|
||||
self.settings = config['platform_settings']
|
||||
"""加载的 Platform 的实例"""
|
||||
|
||||
self._inst_map = {}
|
||||
|
||||
self.platforms_config = config["platform"]
|
||||
self.settings = config["platform_settings"]
|
||||
self.event_queue = event_queue
|
||||
|
||||
try:
|
||||
for platform in self.platforms_config:
|
||||
if not platform['enable']:
|
||||
continue
|
||||
match platform['type']:
|
||||
case "aiocqhttp":
|
||||
from .sources.aiocqhttp.aiocqhttp_platform_adapter import AiocqhttpAdapter # noqa: F401
|
||||
case "qq_official":
|
||||
from .sources.qqofficial.qqofficial_platform_adapter import QQOfficialPlatformAdapter # noqa: F401
|
||||
case "qq_official_webhook":
|
||||
from .sources.qqofficial_webhook.qo_webhook_adapter import QQOfficialWebhookPlatformAdapter # noqa: F401
|
||||
case "gewechat":
|
||||
from .sources.gewechat.gewechat_platform_adapter import GewechatPlatformAdapter # noqa: F401
|
||||
case "lark":
|
||||
from .sources.lark.lark_adapter import LarkPlatformAdapter # noqa: F401
|
||||
except (ImportError, ModuleNotFoundError) as e:
|
||||
logger.error(f"加载平台适配器 {platform['type']} 失败,原因:{e}。请检查依赖库是否安装。提示:可以在 管理面板->控制台->安装Pip库 中安装依赖库。")
|
||||
except Exception as e:
|
||||
logger.error(f"加载平台适配器 {platform['type']} 失败,原因:{e}。")
|
||||
|
||||
async def initialize(self):
|
||||
"""初始化所有平台适配器"""
|
||||
for platform in self.platforms_config:
|
||||
if not platform['enable']:
|
||||
continue
|
||||
if platform['type'] not in platform_cls_map:
|
||||
logger.error(f"未找到适用于 {platform['type']}({platform['id']}) 平台适配器,请检查是否已经安装或者名称填写错误。已跳过。")
|
||||
continue
|
||||
cls_type = platform_cls_map[platform['type']]
|
||||
logger.debug(f"尝试实例化 {platform['type']}({platform['id']}) 平台适配器 ...")
|
||||
inst = cls_type(platform, self.settings, self.event_queue)
|
||||
self.platform_insts.append(inst)
|
||||
|
||||
self.platform_insts.append(WebChatAdapter({}, self.settings, self.event_queue))
|
||||
|
||||
try:
|
||||
await self.load_platform(platform)
|
||||
except Exception as e:
|
||||
logger.error(f"初始化 {platform} 平台适配器失败: {e}")
|
||||
|
||||
# 网页聊天
|
||||
webchat_inst = WebChatAdapter({}, self.settings, self.event_queue)
|
||||
self.platform_insts.append(webchat_inst)
|
||||
asyncio.create_task(
|
||||
self._task_wrapper(asyncio.create_task(webchat_inst.run(), name="webchat"))
|
||||
)
|
||||
|
||||
async def load_platform(self, platform_config: dict):
|
||||
"""实例化一个平台"""
|
||||
# 动态导入
|
||||
try:
|
||||
if not platform_config["enable"]:
|
||||
return
|
||||
|
||||
logger.info(
|
||||
f"载入 {platform_config['type']}({platform_config['id']}) 平台适配器 ..."
|
||||
)
|
||||
match platform_config["type"]:
|
||||
case "aiocqhttp":
|
||||
from .sources.aiocqhttp.aiocqhttp_platform_adapter import (
|
||||
AiocqhttpAdapter, # noqa: F401
|
||||
)
|
||||
case "qq_official":
|
||||
from .sources.qqofficial.qqofficial_platform_adapter import (
|
||||
QQOfficialPlatformAdapter, # noqa: F401
|
||||
)
|
||||
case "qq_official_webhook":
|
||||
from .sources.qqofficial_webhook.qo_webhook_adapter import (
|
||||
QQOfficialWebhookPlatformAdapter, # noqa: F401
|
||||
)
|
||||
case "gewechat":
|
||||
from .sources.gewechat.gewechat_platform_adapter import (
|
||||
GewechatPlatformAdapter, # noqa: F401
|
||||
)
|
||||
case "lark":
|
||||
from .sources.lark.lark_adapter import LarkPlatformAdapter # noqa: F401
|
||||
case "telegram":
|
||||
from .sources.telegram.tg_adapter import TelegramPlatformAdapter # noqa: F401
|
||||
case "wecom":
|
||||
from .sources.wecom.wecom_adapter import WecomPlatformAdapter # noqa: F401
|
||||
except (ImportError, ModuleNotFoundError) as e:
|
||||
logger.error(
|
||||
f"加载平台适配器 {platform_config['type']} 失败,原因:{e}。请检查依赖库是否安装。提示:可以在 管理面板->控制台->安装Pip库 中安装依赖库。"
|
||||
)
|
||||
except Exception as e:
|
||||
logger.error(f"加载平台适配器 {platform_config['type']} 失败,原因:{e}。")
|
||||
|
||||
if platform_config["type"] not in platform_cls_map:
|
||||
logger.error(
|
||||
f"未找到适用于 {platform_config['type']}({platform_config['id']}) 平台适配器,请检查是否已经安装或者名称填写错误"
|
||||
)
|
||||
return
|
||||
cls_type = platform_cls_map[platform_config["type"]]
|
||||
inst = cls_type(platform_config, self.settings, self.event_queue)
|
||||
self._inst_map[platform_config["id"]] = inst
|
||||
self.platform_insts.append(inst)
|
||||
|
||||
asyncio.create_task(
|
||||
self._task_wrapper(
|
||||
asyncio.create_task(
|
||||
inst.run(), name=platform_config["id"] + "_platform"
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
async def _task_wrapper(self, task: asyncio.Task):
|
||||
try:
|
||||
await task
|
||||
except asyncio.CancelledError:
|
||||
pass
|
||||
except Exception as e:
|
||||
logger.error(f"------- 任务 {task.get_name()} 发生错误: {e}")
|
||||
for line in traceback.format_exc().split("\n"):
|
||||
logger.error(f"| {line}")
|
||||
logger.error("-------")
|
||||
|
||||
async def reload(self, platform_config: dict):
|
||||
# 还未实现完成,不要调用此方法
|
||||
|
||||
if platform_config["id"] in self._inst_map:
|
||||
# 正在运行
|
||||
if getattr(self._inst_map[platform_config["id"]], "terminate", None):
|
||||
logger.info(f"正在尝试终止 {platform_config['id']} 平台适配器 ...")
|
||||
await self._inst_map[platform_config["id"]].terminate()
|
||||
logger.info(f"{platform_config['id']} 平台适配器已终止。")
|
||||
del self._inst_map[platform_config["id"]]
|
||||
self.platform_insts.remove(self._inst_map[platform_config["id"]])
|
||||
else:
|
||||
logger.warning(f"可能无法正常终止 {platform_config['id']} 平台适配器。")
|
||||
|
||||
# 再启动新的实例
|
||||
await self.load_platform(platform_config)
|
||||
|
||||
else:
|
||||
# 先将 _inst_map 中在 platform_config 中不存在的实例删除
|
||||
config_ids = [platform["id"] for platform in self.platforms_config]
|
||||
for key in list(self._inst_map.keys()):
|
||||
if key not in config_ids:
|
||||
if getattr(self._inst_map[key], "terminate", None):
|
||||
logger.info(f"正在尝试终止 {key} 平台适配器 ...")
|
||||
await self._inst_map[key].terminate()
|
||||
logger.info(f"{key} 平台适配器已终止。")
|
||||
del self._inst_map[key]
|
||||
self.platform_insts.remove(self._inst_map[key])
|
||||
else:
|
||||
logger.warning(f"可能无法正常终止 {key} 平台适配器。")
|
||||
|
||||
# 再启动新的实例
|
||||
await self.load_platform(platform_config)
|
||||
|
||||
def get_insts(self):
|
||||
return self.platform_insts
|
||||
return self.platform_insts
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
from enum import Enum
|
||||
|
||||
|
||||
class MessageType(Enum):
|
||||
GROUP_MESSAGE = 'GroupMessage' # 群组形式的消息
|
||||
FRIEND_MESSAGE = 'FriendMessage' # 私聊、好友等单聊消息
|
||||
OTHER_MESSAGE = 'OtherMessage' # 其他类型的消息,如系统消息等
|
||||
GROUP_MESSAGE = "GroupMessage" # 群组形式的消息
|
||||
FRIEND_MESSAGE = "FriendMessage" # 私聊、好友等单聊消息
|
||||
OTHER_MESSAGE = "OtherMessage" # 其他类型的消息,如系统消息等
|
||||
|
||||
@@ -7,36 +7,51 @@ from astrbot.core.message.message_event_result import MessageChain
|
||||
from .astr_message_event import MessageSesion
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
|
||||
|
||||
class Platform(abc.ABC):
|
||||
def __init__(self, event_queue: Queue):
|
||||
super().__init__()
|
||||
# 维护了消息平台的事件队列,EventBus 会从这里取出事件并处理。
|
||||
self._event_queue = event_queue
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def run(self) -> Awaitable[Any]:
|
||||
'''
|
||||
"""
|
||||
得到一个平台的运行实例,需要返回一个协程对象。
|
||||
'''
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
async def terminate(self):
|
||||
"""
|
||||
终止一个平台的运行实例。
|
||||
"""
|
||||
pass
|
||||
|
||||
@abc.abstractmethod
|
||||
def meta(self) -> PlatformMetadata:
|
||||
'''
|
||||
"""
|
||||
得到一个平台的元数据。
|
||||
'''
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain) -> Awaitable[Any]:
|
||||
'''
|
||||
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
) -> Awaitable[Any]:
|
||||
"""
|
||||
通过会话发送消息。该方法旨在让插件能够直接通过**可持久化的会话数据**发送消息,而不需要保存 event 对象。
|
||||
|
||||
|
||||
异步方法。
|
||||
'''
|
||||
await Metric.upload(msg_event_tick = 1, adapter_name = self.meta().name)
|
||||
|
||||
"""
|
||||
await Metric.upload(msg_event_tick=1, adapter_name=self.meta().name)
|
||||
|
||||
def commit_event(self, event: AstrMessageEvent):
|
||||
'''
|
||||
"""
|
||||
提交一个事件到事件队列。
|
||||
'''
|
||||
self._event_queue.put_nowait(event)
|
||||
"""
|
||||
self._event_queue.put_nowait(event)
|
||||
|
||||
def get_client(self):
|
||||
"""
|
||||
获取平台的客户端对象。
|
||||
"""
|
||||
pass
|
||||
|
||||
@@ -1,12 +1,14 @@
|
||||
from dataclasses import dataclass
|
||||
|
||||
|
||||
@dataclass
|
||||
class PlatformMetadata():
|
||||
class PlatformMetadata:
|
||||
name: str
|
||||
'''平台的名称'''
|
||||
"""平台的名称"""
|
||||
description: str
|
||||
'''平台的描述'''
|
||||
|
||||
"""平台的描述"""
|
||||
|
||||
default_config_tmpl: dict = None
|
||||
'''平台的默认配置模板'''
|
||||
"""平台的默认配置模板"""
|
||||
adapter_display_name: str = None
|
||||
'''显示在 WebUI 配置页中的平台名称,如空则是 name'''
|
||||
"""显示在 WebUI 配置页中的平台名称,如空则是 name"""
|
||||
|
||||
@@ -3,42 +3,46 @@ from .platform_metadata import PlatformMetadata
|
||||
from astrbot.core import logger
|
||||
|
||||
platform_registry: List[PlatformMetadata] = []
|
||||
'''维护了通过装饰器注册的平台适配器'''
|
||||
"""维护了通过装饰器注册的平台适配器"""
|
||||
platform_cls_map: Dict[str, Type] = {}
|
||||
'''维护了平台适配器名称和适配器类的映射'''
|
||||
"""维护了平台适配器名称和适配器类的映射"""
|
||||
|
||||
|
||||
def register_platform_adapter(
|
||||
adapter_name: str,
|
||||
desc: str,
|
||||
adapter_name: str,
|
||||
desc: str,
|
||||
default_config_tmpl: dict = None,
|
||||
adapter_display_name: str = None
|
||||
adapter_display_name: str = None,
|
||||
):
|
||||
'''用于注册平台适配器的带参装饰器。
|
||||
|
||||
default_config_tmpl 指定了平台适配器的默认配置模板。用户填写好后将会作为 platform_config 传入你的 Platform 类的实现类。
|
||||
'''
|
||||
"""用于注册平台适配器的带参装饰器。
|
||||
|
||||
default_config_tmpl 指定了平台适配器的默认配置模板。用户填写好后将会作为 platform_config 传入你的 Platform 类的实现类。
|
||||
"""
|
||||
|
||||
def decorator(cls):
|
||||
if adapter_name in platform_cls_map:
|
||||
raise ValueError(f"平台适配器 {adapter_name} 已经注册过了,可能发生了适配器命名冲突。")
|
||||
|
||||
raise ValueError(
|
||||
f"平台适配器 {adapter_name} 已经注册过了,可能发生了适配器命名冲突。"
|
||||
)
|
||||
|
||||
# 添加必备选项
|
||||
if default_config_tmpl:
|
||||
if 'type' not in default_config_tmpl:
|
||||
default_config_tmpl['type'] = adapter_name
|
||||
if 'enable' not in default_config_tmpl:
|
||||
default_config_tmpl['enable'] = False
|
||||
if 'id' not in default_config_tmpl:
|
||||
default_config_tmpl['id'] = adapter_name
|
||||
if "type" not in default_config_tmpl:
|
||||
default_config_tmpl["type"] = adapter_name
|
||||
if "enable" not in default_config_tmpl:
|
||||
default_config_tmpl["enable"] = False
|
||||
if "id" not in default_config_tmpl:
|
||||
default_config_tmpl["id"] = adapter_name
|
||||
|
||||
pm = PlatformMetadata(
|
||||
name=adapter_name,
|
||||
description=desc,
|
||||
default_config_tmpl=default_config_tmpl,
|
||||
adapter_display_name=adapter_display_name
|
||||
adapter_display_name=adapter_display_name,
|
||||
)
|
||||
platform_registry.append(pm)
|
||||
platform_cls_map[adapter_name] = cls
|
||||
logger.debug(f"平台适配器 {adapter_name} 已注册")
|
||||
return cls
|
||||
|
||||
|
||||
return decorator
|
||||
|
||||
@@ -1,23 +1,26 @@
|
||||
import asyncio
|
||||
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.message_components import Plain, Image, Record, At, Node, Music, Video
|
||||
from astrbot.api.message_components import Plain, Image, Record, At, Node, Nodes
|
||||
from aiocqhttp import CQHttp
|
||||
from astrbot.core.utils.io import file_to_base64, download_image_by_url
|
||||
|
||||
|
||||
class AiocqhttpMessageEvent(AstrMessageEvent):
|
||||
def __init__(self, message_str, message_obj, platform_meta, session_id, bot: CQHttp):
|
||||
def __init__(
|
||||
self, message_str, message_obj, platform_meta, session_id, bot: CQHttp
|
||||
):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.bot = bot
|
||||
|
||||
|
||||
@staticmethod
|
||||
async def _parse_onebot_json(message_chain: MessageChain):
|
||||
'''解析成 OneBot json 格式'''
|
||||
"""解析成 OneBot json 格式"""
|
||||
ret = []
|
||||
for segment in message_chain.chain:
|
||||
d = segment.toDict()
|
||||
if isinstance(segment, Plain):
|
||||
d['type'] = 'text'
|
||||
d["type"] = "text"
|
||||
elif isinstance(segment, (Image, Record)):
|
||||
# convert to base64
|
||||
if segment.file and segment.file.startswith("file:///"):
|
||||
@@ -30,31 +33,48 @@ class AiocqhttpMessageEvent(AstrMessageEvent):
|
||||
bs64_data = segment.file
|
||||
else:
|
||||
bs64_data = file_to_base64(segment.file)
|
||||
d['data'] = {
|
||||
'file': bs64_data,
|
||||
d["data"] = {
|
||||
"file": bs64_data,
|
||||
}
|
||||
elif isinstance(segment, At):
|
||||
d['data'] = {
|
||||
'qq': str(segment.qq) # 转换为字符串
|
||||
d["data"] = {
|
||||
"qq": str(segment.qq) # 转换为字符串
|
||||
}
|
||||
ret.append(d)
|
||||
return ret
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
ret = await AiocqhttpMessageEvent._parse_onebot_json(message)
|
||||
|
||||
|
||||
send_one_by_one = False
|
||||
for seg in message.chain:
|
||||
if isinstance(seg, (Node, Music)):
|
||||
if isinstance(seg, (Node, Nodes)):
|
||||
# 转发消息不能和普通消息混在一起发送
|
||||
send_one_by_one = True
|
||||
break
|
||||
|
||||
|
||||
if send_one_by_one:
|
||||
for seg in message.chain:
|
||||
await self.bot.send(self.message_obj.raw_message, await AiocqhttpMessageEvent._parse_onebot_json(MessageChain([seg])))
|
||||
await asyncio.sleep(0.5)
|
||||
if isinstance(seg, Nodes):
|
||||
# 带有多个节点的合并转发消息
|
||||
payload = seg.toDict()
|
||||
if self.get_group_id():
|
||||
payload["group_id"] = self.get_group_id()
|
||||
await self.bot.call_action("send_group_forward_msg", **payload)
|
||||
else:
|
||||
payload["user_id"] = self.get_sender_id()
|
||||
await self.bot.call_action(
|
||||
"send_private_forward_msg", **payload
|
||||
)
|
||||
else:
|
||||
await self.bot.send(
|
||||
self.message_obj.raw_message,
|
||||
await AiocqhttpMessageEvent._parse_onebot_json(
|
||||
MessageChain([seg])
|
||||
),
|
||||
)
|
||||
await asyncio.sleep(0.5)
|
||||
else:
|
||||
await self.bot.send(self.message_obj.raw_message, ret)
|
||||
|
||||
await super().send(message)
|
||||
|
||||
await super().send(message)
|
||||
|
||||
@@ -2,9 +2,16 @@ import os
|
||||
import time
|
||||
import asyncio
|
||||
import logging
|
||||
import uuid
|
||||
from typing import Awaitable, Any
|
||||
from aiocqhttp import CQHttp, Event
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
from astrbot.api.platform import (
|
||||
Platform,
|
||||
AstrBotMessage,
|
||||
MessageMember,
|
||||
MessageType,
|
||||
PlatformMetadata,
|
||||
)
|
||||
from astrbot.api.event import MessageChain
|
||||
from .aiocqhttp_message_event import * # noqa: F403
|
||||
from astrbot.api.message_components import * # noqa: F403
|
||||
@@ -15,23 +22,64 @@ from ...register import register_platform_adapter
|
||||
from aiocqhttp.exceptions import ActionFailed
|
||||
from astrbot.core.utils.io import download_file
|
||||
|
||||
@register_platform_adapter("aiocqhttp", "适用于 OneBot 标准的消息平台适配器,支持反向 WebSockets。")
|
||||
|
||||
@register_platform_adapter(
|
||||
"aiocqhttp", "适用于 OneBot V11 标准的消息平台适配器,支持反向 WebSockets。"
|
||||
)
|
||||
class AiocqhttpAdapter(Platform):
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
def __init__(
|
||||
self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue
|
||||
) -> None:
|
||||
super().__init__(event_queue)
|
||||
|
||||
|
||||
self.config = platform_config
|
||||
self.settings = platform_settings
|
||||
self.unique_session = platform_settings['unique_session']
|
||||
self.host = platform_config['ws_reverse_host']
|
||||
self.port = platform_config['ws_reverse_port']
|
||||
|
||||
self.unique_session = platform_settings["unique_session"]
|
||||
self.host = platform_config["ws_reverse_host"]
|
||||
self.port = platform_config["ws_reverse_port"]
|
||||
|
||||
self.metadata = PlatformMetadata(
|
||||
"aiocqhttp",
|
||||
"适用于 OneBot 标准的消息平台适配器,支持反向 WebSockets。",
|
||||
)
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
|
||||
self.stop = False
|
||||
|
||||
self.bot = CQHttp(
|
||||
use_ws_reverse=True, import_name="aiocqhttp", api_timeout_sec=180
|
||||
)
|
||||
|
||||
@self.bot.on_request()
|
||||
async def request(event: Event):
|
||||
abm = await self.convert_message(event)
|
||||
if abm:
|
||||
await self.handle_msg(abm)
|
||||
|
||||
@self.bot.on_notice()
|
||||
async def notice(event: Event):
|
||||
abm = await self.convert_message(event)
|
||||
if abm:
|
||||
await self.handle_msg(abm)
|
||||
|
||||
@self.bot.on_message("group")
|
||||
async def group(event: Event):
|
||||
abm = await self.convert_message(event)
|
||||
if abm:
|
||||
await self.handle_msg(abm)
|
||||
|
||||
@self.bot.on_message("private")
|
||||
async def private(event: Event):
|
||||
abm = await self.convert_message(event)
|
||||
if abm:
|
||||
await self.handle_msg(abm)
|
||||
|
||||
@self.bot.on_websocket_connection
|
||||
def on_websocket_connection(_):
|
||||
logger.info("aiocqhttp(OneBot v11) 适配器已连接。")
|
||||
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
):
|
||||
ret = await AiocqhttpMessageEvent._parse_onebot_json(message_chain)
|
||||
match session.message_type.value:
|
||||
case MessageType.GROUP_MESSAGE.value:
|
||||
@@ -40,32 +88,104 @@ class AiocqhttpAdapter(Platform):
|
||||
_, group_id = session.session_id.split("_")
|
||||
await self.bot.send_group_msg(group_id=group_id, message=ret)
|
||||
else:
|
||||
await self.bot.send_group_msg(group_id=session.session_id, message=ret)
|
||||
await self.bot.send_group_msg(
|
||||
group_id=session.session_id, message=ret
|
||||
)
|
||||
case MessageType.FRIEND_MESSAGE.value:
|
||||
await self.bot.send_private_msg(user_id=session.session_id, message=ret)
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
|
||||
async def convert_message(self, event: Event) -> AstrBotMessage:
|
||||
logger.debug(f"[aiocqhttp] RawMessage {event}")
|
||||
|
||||
if event["post_type"] == "message":
|
||||
abm = await self._convert_handle_message_event(event)
|
||||
elif event["post_type"] == "notice":
|
||||
abm = await self._convert_handle_notice_event(event)
|
||||
elif event["post_type"] == "request":
|
||||
abm = await self._convert_handle_request_event(event)
|
||||
|
||||
return abm
|
||||
|
||||
async def _convert_handle_request_event(self, event: Event) -> AstrBotMessage:
|
||||
"""OneBot V11 请求类事件"""
|
||||
abm = AstrBotMessage()
|
||||
abm.self_id = str(event.self_id)
|
||||
abm.tag = "aiocqhttp"
|
||||
|
||||
abm.sender = MessageMember(str(event.sender['user_id']), event.sender['nickname'])
|
||||
|
||||
if event['message_type'] == 'group':
|
||||
abm.sender = MessageMember(user_id=event.user_id, nickname=event.user_id)
|
||||
abm.type = MessageType.OTHER_MESSAGE
|
||||
if "group_id" in event and event["group_id"]:
|
||||
abm.type = MessageType.GROUP_MESSAGE
|
||||
abm.group_id = str(event.group_id)
|
||||
elif event['message_type'] == 'private':
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
|
||||
if self.unique_session:
|
||||
abm.session_id = abm.sender.user_id + "_" + str(event.group_id) # 也保留群组 id
|
||||
else:
|
||||
abm.session_id = str(event.group_id) if abm.type == MessageType.GROUP_MESSAGE else abm.sender.user_id
|
||||
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
if self.unique_session and abm.type == MessageType.GROUP_MESSAGE:
|
||||
abm.session_id = str(abm.sender.user_id) + "_" + str(event.group_id)
|
||||
abm.message_str = ""
|
||||
abm.message = []
|
||||
abm.timestamp = int(time.time())
|
||||
abm.message_id = uuid.uuid4().hex
|
||||
abm.raw_message = event
|
||||
return abm
|
||||
|
||||
async def _convert_handle_notice_event(self, event: Event) -> AstrBotMessage:
|
||||
"""OneBot V11 通知类事件"""
|
||||
abm = AstrBotMessage()
|
||||
abm.self_id = str(event.self_id)
|
||||
abm.sender = MessageMember(user_id=event.user_id, nickname=event.user_id)
|
||||
abm.type = MessageType.OTHER_MESSAGE
|
||||
if "group_id" in event and event["group_id"]:
|
||||
abm.group_id = str(event.group_id)
|
||||
abm.type = MessageType.GROUP_MESSAGE
|
||||
else:
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
if self.unique_session and abm.type == MessageType.GROUP_MESSAGE:
|
||||
abm.session_id = (
|
||||
abm.sender.user_id + "_" + str(event.group_id)
|
||||
) # 也保留群组 id
|
||||
else:
|
||||
abm.session_id = (
|
||||
str(event.group_id)
|
||||
if abm.type == MessageType.GROUP_MESSAGE
|
||||
else abm.sender.user_id
|
||||
)
|
||||
abm.message_str = ""
|
||||
abm.message = []
|
||||
abm.raw_message = event
|
||||
abm.timestamp = int(time.time())
|
||||
abm.message_id = uuid.uuid4().hex
|
||||
|
||||
if "sub_type" in event:
|
||||
if event["sub_type"] == "poke" and "target_id" in event:
|
||||
abm.message.append(Poke(qq=str(event["target_id"]), type="poke")) # noqa: F405
|
||||
|
||||
return abm
|
||||
|
||||
async def _convert_handle_message_event(self, event: Event) -> AstrBotMessage:
|
||||
"""OneBot V11 消息类事件"""
|
||||
abm = AstrBotMessage()
|
||||
abm.self_id = str(event.self_id)
|
||||
abm.sender = MessageMember(
|
||||
str(event.sender["user_id"]), event.sender["nickname"]
|
||||
)
|
||||
if event["message_type"] == "group":
|
||||
abm.type = MessageType.GROUP_MESSAGE
|
||||
abm.group_id = str(event.group_id)
|
||||
elif event["message_type"] == "private":
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
if self.unique_session and abm.type == MessageType.GROUP_MESSAGE:
|
||||
abm.session_id = (
|
||||
abm.sender.user_id + "_" + str(event.group_id)
|
||||
) # 也保留群组 id
|
||||
else:
|
||||
abm.session_id = (
|
||||
str(event.group_id)
|
||||
if abm.type == MessageType.GROUP_MESSAGE
|
||||
else abm.sender.user_id
|
||||
)
|
||||
|
||||
abm.message_id = str(event.message_id)
|
||||
abm.message = []
|
||||
|
||||
|
||||
message_str = ""
|
||||
if not isinstance(event.message, list):
|
||||
err = f"aiocqhttp: 无法识别的消息类型: {str(event.message)},此条消息将被忽略。如果您在使用 go-cqhttp,请将其配置文件中的 message.post-format 更改为 array。"
|
||||
@@ -75,98 +195,104 @@ class AiocqhttpAdapter(Platform):
|
||||
except BaseException as e:
|
||||
logger.error(f"回复消息失败: {e}")
|
||||
return
|
||||
logger.debug(f"aiocqhttp: 收到消息: {event.message}")
|
||||
|
||||
# 按消息段类型类型适配
|
||||
for m in event.message:
|
||||
t = m['type']
|
||||
t = m["type"]
|
||||
a = None
|
||||
if t == 'text':
|
||||
message_str += m['data']['text'].strip()
|
||||
elif t == 'file':
|
||||
if m['data']['url'] and m['data']['url'].startswith("http"):
|
||||
if t == "text":
|
||||
message_str += m["data"]["text"].strip()
|
||||
a = ComponentTypes[t](**m["data"]) # noqa: F405
|
||||
abm.message.append(a)
|
||||
|
||||
elif t == "file":
|
||||
if m["data"].get("url") and m["data"].get("url").startswith("http"):
|
||||
# Lagrange
|
||||
logger.info("guessing lagrange")
|
||||
|
||||
file_name = m['data'].get('file_name', "file")
|
||||
|
||||
file_name = m["data"].get("file_name", "file")
|
||||
path = os.path.join("data/temp", file_name)
|
||||
await download_file(m['data']['url'], path)
|
||||
|
||||
m['data'] = {
|
||||
"file": path,
|
||||
"name": file_name
|
||||
}
|
||||
|
||||
await download_file(m["data"]["url"], path)
|
||||
|
||||
m["data"] = {"file": path, "name": file_name}
|
||||
a = ComponentTypes[t](**m["data"]) # noqa: F405
|
||||
abm.message.append(a)
|
||||
|
||||
else:
|
||||
try:
|
||||
# Napcat, LLBot
|
||||
ret = await self.bot.call_action(action="get_file", file_id=event.message[0]['data']['file_id'])
|
||||
if not ret.get('file', None):
|
||||
ret = await self.bot.call_action(
|
||||
action="get_file",
|
||||
file_id=event.message[0]["data"]["file_id"],
|
||||
)
|
||||
if not ret.get("file", None):
|
||||
raise ValueError(f"无法解析文件响应: {ret}")
|
||||
if not os.path.exists(ret['file']):
|
||||
raise FileNotFoundError(f"文件不存在或者权限问题: {ret['file']}。如果您使用 Docker 部署了 AstrBot 或者消息协议端(Napcat等),请先映射路径。如果路径在 /root 目录下,请用 sudo 打开 AstrBot")
|
||||
|
||||
m['data'] = {
|
||||
"file": ret['file'],
|
||||
"name": ret['file_name']
|
||||
}
|
||||
if not os.path.exists(ret["file"]):
|
||||
raise FileNotFoundError(
|
||||
f"文件不存在或者权限问题: {ret['file']}。如果您使用 Docker 部署了 AstrBot 或者消息协议端(Napcat等),请先映射路径。如果路径在 /root 目录下,请用 sudo 打开 AstrBot"
|
||||
)
|
||||
|
||||
m["data"] = {"file": ret["file"], "name": ret["file_name"]}
|
||||
a = ComponentTypes[t](**m["data"]) # noqa: F405
|
||||
abm.message.append(a)
|
||||
except ActionFailed as e:
|
||||
logger.error(f"获取文件失败: {e},此消息段将被忽略。")
|
||||
except BaseException as e:
|
||||
logger.error(f"获取文件失败: {e},此消息段将被忽略。")
|
||||
|
||||
a = ComponentTypes[t](**m['data']) # noqa: F405
|
||||
abm.message.append(a)
|
||||
|
||||
else:
|
||||
a = ComponentTypes[t](**m["data"]) # noqa: F405
|
||||
abm.message.append(a)
|
||||
|
||||
abm.timestamp = int(time.time())
|
||||
abm.message_str = message_str
|
||||
abm.raw_message = event
|
||||
|
||||
return abm
|
||||
|
||||
|
||||
def run(self) -> Awaitable[Any]:
|
||||
if not self.host or not self.port:
|
||||
logger.warning("aiocqhttp: 未配置 ws_reverse_host 或 ws_reverse_port,将使用默认值:http://0.0.0.0:6199")
|
||||
logger.warning(
|
||||
"aiocqhttp: 未配置 ws_reverse_host 或 ws_reverse_port,将使用默认值:http://0.0.0.0:6199"
|
||||
)
|
||||
self.host = "0.0.0.0"
|
||||
self.port = 6199
|
||||
|
||||
self.bot = CQHttp(use_ws_reverse=True, import_name='aiocqhttp', api_timeout_sec=180)
|
||||
@self.bot.on_message('group')
|
||||
async def group(event: Event):
|
||||
abm = await self.convert_message(event)
|
||||
if abm:
|
||||
await self.handle_msg(abm)
|
||||
|
||||
@self.bot.on_message('private')
|
||||
async def private(event: Event):
|
||||
abm = await self.convert_message(event)
|
||||
if abm:
|
||||
await self.handle_msg(abm)
|
||||
|
||||
@self.bot.on_websocket_connection
|
||||
def on_websocket_connection(_):
|
||||
logger.info("aiocqhttp 适配器已连接。")
|
||||
|
||||
bot = self.bot.run_task(host=self.host, port=int(self.port), shutdown_trigger=self.shutdown_trigger_placeholder)
|
||||
|
||||
|
||||
coro = self.bot.run_task(
|
||||
host=self.host,
|
||||
port=int(self.port),
|
||||
shutdown_trigger=self.shutdown_trigger_placeholder,
|
||||
)
|
||||
|
||||
for handler in logging.root.handlers[:]:
|
||||
logging.root.removeHandler(handler)
|
||||
logging.getLogger('aiocqhttp').setLevel(logging.ERROR)
|
||||
|
||||
return bot
|
||||
|
||||
logging.getLogger("aiocqhttp").setLevel(logging.ERROR)
|
||||
|
||||
return coro
|
||||
|
||||
async def terminate(self):
|
||||
self.stop = True
|
||||
await asyncio.sleep(1)
|
||||
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return self.metadata
|
||||
|
||||
|
||||
async def shutdown_trigger_placeholder(self):
|
||||
while not self._event_queue.closed:
|
||||
# TODO: use asyncio.Event
|
||||
while not self._event_queue.closed and not self.stop: # noqa: ASYNC110
|
||||
await asyncio.sleep(1)
|
||||
logger.info("aiocqhttp 适配器已关闭。")
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
|
||||
message_event = AiocqhttpMessageEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id,
|
||||
bot=self.bot
|
||||
bot=self.bot,
|
||||
)
|
||||
|
||||
self.commit_event(message_event)
|
||||
|
||||
self.commit_event(message_event)
|
||||
|
||||
def get_client(self) -> CQHttp:
|
||||
return self.bot
|
||||
|
||||
@@ -4,7 +4,9 @@ import aiohttp
|
||||
import quart
|
||||
import base64
|
||||
import datetime
|
||||
|
||||
import re
|
||||
import os
|
||||
import anyio
|
||||
from astrbot.api.platform import AstrBotMessage, MessageMember, MessageType
|
||||
from astrbot.api.message_components import Plain, Image, At, Record
|
||||
from astrbot.api import logger, sp
|
||||
@@ -12,120 +14,172 @@ from .downloader import GeweDownloader
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
|
||||
|
||||
class SimpleGewechatClient():
|
||||
'''针对 Gewechat 的简单实现。
|
||||
|
||||
class SimpleGewechatClient:
|
||||
"""针对 Gewechat 的简单实现。
|
||||
|
||||
@author: Soulter
|
||||
@website: https://github.com/Soulter
|
||||
'''
|
||||
def __init__(self, base_url: str, nickname: str, host: str, port: int, event_queue: asyncio.Queue):
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
base_url: str,
|
||||
nickname: str,
|
||||
host: str,
|
||||
port: int,
|
||||
event_queue: asyncio.Queue,
|
||||
):
|
||||
self.base_url = base_url
|
||||
if self.base_url.endswith('/'):
|
||||
if self.base_url.endswith("/"):
|
||||
self.base_url = self.base_url[:-1]
|
||||
|
||||
self.download_base_url = self.base_url.split(':')[:-1] # 去掉端口
|
||||
self.download_base_url = ':'.join(self.download_base_url) + ":2532/download/"
|
||||
|
||||
|
||||
self.download_base_url = self.base_url.split(":")[:-1] # 去掉端口
|
||||
self.download_base_url = ":".join(self.download_base_url) + ":2532/download/"
|
||||
|
||||
self.base_url += "/v2/api"
|
||||
|
||||
|
||||
logger.info(f"Gewechat API: {self.base_url}")
|
||||
logger.info(f"Gewechat 下载 API: {self.download_base_url}")
|
||||
|
||||
|
||||
if isinstance(port, str):
|
||||
port = int(port)
|
||||
|
||||
|
||||
self.token = None
|
||||
self.headers = {}
|
||||
self.nickname = nickname
|
||||
self.appid = sp.get(f"gewechat-appid-{nickname}", "")
|
||||
|
||||
|
||||
self.server = quart.Quart(__name__)
|
||||
self.server.add_url_rule('/astrbot-gewechat/callback', view_func=self.callback, methods=['POST'])
|
||||
self.server.add_url_rule('/astrbot-gewechat/file/<file_id>', view_func=self.handle_file, methods=['GET'])
|
||||
|
||||
self.server.add_url_rule(
|
||||
"/astrbot-gewechat/callback", view_func=self.callback, methods=["POST"]
|
||||
)
|
||||
self.server.add_url_rule(
|
||||
"/astrbot-gewechat/file/<file_id>",
|
||||
view_func=self.handle_file,
|
||||
methods=["GET"],
|
||||
)
|
||||
|
||||
self.host = host
|
||||
self.port = port
|
||||
self.port = port
|
||||
self.callback_url = f"http://{self.host}:{self.port}/astrbot-gewechat/callback"
|
||||
self.file_server_url = f"http://{self.host}:{self.port}/astrbot-gewechat/file"
|
||||
|
||||
|
||||
self.event_queue = event_queue
|
||||
|
||||
|
||||
self.multimedia_downloader = None
|
||||
|
||||
|
||||
self.userrealnames = {}
|
||||
|
||||
self.stop = False
|
||||
|
||||
async def get_token_id(self):
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(f"{self.base_url}/tools/getTokenId") as resp:
|
||||
json_blob = await resp.json()
|
||||
self.token = json_blob['data']
|
||||
self.token = json_blob["data"]
|
||||
logger.info(f"获取到 Gewechat Token: {self.token}")
|
||||
self.headers = {
|
||||
"X-GEWE-TOKEN": self.token
|
||||
}
|
||||
|
||||
self.headers = {"X-GEWE-TOKEN": self.token}
|
||||
|
||||
async def _convert(self, data: dict) -> AstrBotMessage:
|
||||
type_name = data['TypeName']
|
||||
if "TypeName" in data:
|
||||
type_name = data["TypeName"]
|
||||
elif "type_name" in data:
|
||||
type_name = data["type_name"]
|
||||
else:
|
||||
raise Exception("无法识别的消息类型")
|
||||
if type_name == "Offline":
|
||||
logger.critical("收到 gewechat 下线通知。")
|
||||
return
|
||||
|
||||
if 'Data' in data and 'CreateTime' in data['Data']:
|
||||
|
||||
d = None
|
||||
if "Data" in data:
|
||||
d = data["Data"]
|
||||
elif "data" in data:
|
||||
d = data["data"]
|
||||
|
||||
if not d:
|
||||
logger.warning(f"消息不含 data 字段: {data}")
|
||||
return
|
||||
|
||||
if "CreateTime" in d:
|
||||
# 得到系统 UTF+8 的 ts
|
||||
tz_offset = datetime.timedelta(hours=8)
|
||||
tz = datetime.timezone(tz_offset)
|
||||
ts = datetime.datetime.now(tz).timestamp()
|
||||
create_time = data['Data']['CreateTime']
|
||||
create_time = d["CreateTime"]
|
||||
if create_time < ts - 30:
|
||||
logger.warning(f"消息时间戳过旧: {create_time},当前时间戳: {ts}")
|
||||
return
|
||||
|
||||
|
||||
abm = AstrBotMessage()
|
||||
d = data['Data']
|
||||
|
||||
from_user_name = d['FromUserName']['string'] # 消息来源
|
||||
d['to_wxid'] = from_user_name # 用于发信息
|
||||
|
||||
abm.message_id = str(d.get('MsgId'))
|
||||
|
||||
from_user_name = d["FromUserName"]["string"] # 消息来源
|
||||
d["to_wxid"] = from_user_name # 用于发信息
|
||||
|
||||
abm.message_id = str(d.get("MsgId"))
|
||||
abm.session_id = from_user_name
|
||||
abm.self_id = data['Wxid'] # 机器人的 wxid
|
||||
|
||||
user_id = "" # 发送人 wxid
|
||||
content = d['Content']['string'] # 消息内容
|
||||
|
||||
abm.self_id = data["Wxid"] # 机器人的 wxid
|
||||
|
||||
user_id = "" # 发送人 wxid
|
||||
content = d["Content"]["string"] # 消息内容
|
||||
|
||||
at_me = False
|
||||
if "@chatroom" in from_user_name:
|
||||
abm.type = MessageType.GROUP_MESSAGE
|
||||
_t = content.split(':\n')
|
||||
_t = content.split(":\n")
|
||||
user_id = _t[0]
|
||||
content = _t[1]
|
||||
if '\u2005' in content:
|
||||
if "\u2005" in content:
|
||||
# at
|
||||
content = content.split('\u2005')[1]
|
||||
# content = content.split('\u2005')[1]
|
||||
content = re.sub(r"@[^\u2005]*\u2005", "", content)
|
||||
abm.group_id = from_user_name
|
||||
# at
|
||||
msg_source = d['MsgSource']
|
||||
if f'<atuserlist><![CDATA[,{abm.self_id}]]>' in msg_source \
|
||||
or f'<atuserlist><![CDATA[{abm.self_id}]]>' in msg_source:
|
||||
msg_source = d["MsgSource"]
|
||||
if (
|
||||
f"<atuserlist><![CDATA[,{abm.self_id}]]>" in msg_source
|
||||
or f"<atuserlist><![CDATA[{abm.self_id}]]>" in msg_source
|
||||
):
|
||||
at_me = True
|
||||
if '在群聊中@了你' in d.get('PushContent', ''):
|
||||
if "在群聊中@了你" in d.get("PushContent", ""):
|
||||
at_me = True
|
||||
else:
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
user_id = from_user_name
|
||||
|
||||
|
||||
abm.message = []
|
||||
if at_me:
|
||||
abm.message.insert(0, At(qq=abm.self_id))
|
||||
|
||||
user_real_name = d.get('PushContent', 'unknown : ').split(' : ')[0] \
|
||||
.replace('在群聊中@了你', '') \
|
||||
.replace('在群聊中发了一段语音', '') \
|
||||
.replace('在群聊中发了一张图片', '') # 真实昵称
|
||||
|
||||
# 解析用户真实名字
|
||||
user_real_name = "unknown"
|
||||
if abm.group_id:
|
||||
if (
|
||||
abm.group_id not in self.userrealnames
|
||||
or user_id not in self.userrealnames[abm.group_id]
|
||||
):
|
||||
# 获取群成员列表,并且缓存
|
||||
if abm.group_id not in self.userrealnames:
|
||||
self.userrealnames[abm.group_id] = {}
|
||||
member_list = await self.get_chatroom_member_list(abm.group_id)
|
||||
logger.debug(f"获取到 {abm.group_id} 的群成员列表。")
|
||||
if member_list and "memberList" in member_list:
|
||||
for member in member_list["memberList"]:
|
||||
self.userrealnames[abm.group_id][member["wxid"]] = member[
|
||||
"nickName"
|
||||
]
|
||||
if user_id in self.userrealnames[abm.group_id]:
|
||||
user_real_name = self.userrealnames[abm.group_id][user_id]
|
||||
else:
|
||||
user_real_name = self.userrealnames[abm.group_id][user_id]
|
||||
else:
|
||||
user_real_name = d.get("PushContent", "unknown : ").split(" : ")[0]
|
||||
|
||||
abm.sender = MessageMember(user_id, user_real_name)
|
||||
abm.raw_message = d
|
||||
abm.message_str = ""
|
||||
# 不同消息类型
|
||||
match d['MsgType']:
|
||||
match d["MsgType"]:
|
||||
case 1:
|
||||
# 文本消息
|
||||
abm.message.append(Plain(content))
|
||||
@@ -133,58 +187,59 @@ class SimpleGewechatClient():
|
||||
case 3:
|
||||
# 图片消息
|
||||
file_url = await self.multimedia_downloader.download_image(
|
||||
self.appid,
|
||||
content
|
||||
self.appid, content
|
||||
)
|
||||
logger.debug(f"下载图片: {file_url}")
|
||||
file_path = await download_image_by_url(file_url)
|
||||
abm.message.append(Image(file=file_path, url=file_path))
|
||||
|
||||
|
||||
case 34:
|
||||
# 语音消息
|
||||
# data = await self.multimedia_downloader.download_voice(
|
||||
# self.appid,
|
||||
# content,
|
||||
# self.appid,
|
||||
# content,
|
||||
# abm.message_id
|
||||
# )
|
||||
# print(data)
|
||||
if 'ImgBuf' in d and 'buffer' in d['ImgBuf']:
|
||||
voice_data = base64.b64decode(d['ImgBuf']['buffer'])
|
||||
if "ImgBuf" in d and "buffer" in d["ImgBuf"]:
|
||||
voice_data = base64.b64decode(d["ImgBuf"]["buffer"])
|
||||
file_path = f"data/temp/gewe_voice_{abm.message_id}.silk"
|
||||
with open(file_path, "wb") as f:
|
||||
f.write(voice_data)
|
||||
async with await anyio.open_file(file_path, "wb") as f:
|
||||
await f.write(voice_data)
|
||||
abm.message.append(Record(file=file_path, url=file_path))
|
||||
case _:
|
||||
logger.info(f"未实现的消息类型: {d['MsgType']}")
|
||||
abm.raw_message = d
|
||||
|
||||
|
||||
logger.debug(f"abm: {abm}")
|
||||
return abm
|
||||
|
||||
async def callback(self):
|
||||
data = await quart.request.json
|
||||
logger.debug(f"收到 gewechat 回调: {data}")
|
||||
|
||||
if data.get('testMsg', None):
|
||||
|
||||
if data.get("testMsg", None):
|
||||
return quart.jsonify({"r": "AstrBot ACK"})
|
||||
|
||||
|
||||
abm = None
|
||||
try:
|
||||
abm = await self._convert(data)
|
||||
except BaseException as e:
|
||||
logger.warning(f"尝试解析 GeweChat 下发的消息时遇到问题: {e}。下发消息内容: {data}。")
|
||||
|
||||
logger.warning(
|
||||
f"尝试解析 GeweChat 下发的消息时遇到问题: {e}。下发消息内容: {data}。"
|
||||
)
|
||||
|
||||
if abm:
|
||||
coro = getattr(self, "on_event_received")
|
||||
if coro:
|
||||
await coro(abm)
|
||||
|
||||
|
||||
return quart.jsonify({"r": "AstrBot ACK"})
|
||||
|
||||
|
||||
async def handle_file(self, file_id):
|
||||
file_path = f"data/temp/{file_id}"
|
||||
return await quart.send_file(file_path)
|
||||
|
||||
|
||||
async def _set_callback_url(self):
|
||||
logger.info("设置回调,请等待...")
|
||||
await asyncio.sleep(3)
|
||||
@@ -192,43 +247,41 @@ class SimpleGewechatClient():
|
||||
async with session.post(
|
||||
f"{self.base_url}/tools/setCallback",
|
||||
headers=self.headers,
|
||||
json={
|
||||
"token": self.token,
|
||||
"callbackUrl": self.callback_url
|
||||
}
|
||||
json={"token": self.token, "callbackUrl": self.callback_url},
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.info(f"设置回调结果: {json_blob}")
|
||||
if json_blob['ret'] != 200:
|
||||
if json_blob["ret"] != 200:
|
||||
raise Exception(f"设置回调失败: {json_blob}")
|
||||
logger.info(f"将在 {self.callback_url} 上接收 gewechat 下发的消息。如果一直没收到消息请先尝试重启 AstrBot。如果仍没收到请到管理面板聊天页输入 /gewe_logout 重新登录。")
|
||||
|
||||
logger.info(
|
||||
f"将在 {self.callback_url} 上接收 gewechat 下发的消息。如果一直没收到消息请先尝试重启 AstrBot。如果仍没收到请到管理面板聊天页输入 /gewe_logout 重新登录。"
|
||||
)
|
||||
|
||||
async def start_polling(self):
|
||||
threading.Thread(target=asyncio.run, args=(self._set_callback_url(),)).start()
|
||||
await self.server.run_task(
|
||||
host='0.0.0.0',
|
||||
port=self.port,
|
||||
shutdown_trigger=self.shutdown_trigger_placeholder
|
||||
host="0.0.0.0",
|
||||
port=self.port,
|
||||
shutdown_trigger=self.shutdown_trigger_placeholder,
|
||||
)
|
||||
|
||||
|
||||
async def shutdown_trigger_placeholder(self):
|
||||
while not self.event_queue.closed:
|
||||
# TODO: use asyncio.Event
|
||||
while not self.event_queue.closed and not self.stop: # noqa: ASYNC110
|
||||
await asyncio.sleep(1)
|
||||
logger.info("gewechat 适配器已关闭。")
|
||||
|
||||
|
||||
async def check_online(self, appid: str):
|
||||
# /login/checkOnline
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/login/checkOnline",
|
||||
headers=self.headers,
|
||||
json={
|
||||
"appId": appid
|
||||
}
|
||||
json={"appId": appid},
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
return json_blob['data']
|
||||
|
||||
return json_blob["data"]
|
||||
|
||||
async def logout(self):
|
||||
if self.appid:
|
||||
online = await self.check_online(self.appid)
|
||||
@@ -237,81 +290,120 @@ class SimpleGewechatClient():
|
||||
async with session.post(
|
||||
f"{self.base_url}/login/logout",
|
||||
headers=self.headers,
|
||||
json={
|
||||
"appId": self.appid
|
||||
}
|
||||
json={"appId": self.appid},
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.info(f"登出结果: {json_blob}")
|
||||
|
||||
|
||||
async def login(self):
|
||||
if self.token is None:
|
||||
await self.get_token_id()
|
||||
|
||||
self.multimedia_downloader = GeweDownloader(self.base_url, self.download_base_url, self.token)
|
||||
|
||||
|
||||
self.multimedia_downloader = GeweDownloader(
|
||||
self.base_url, self.download_base_url, self.token
|
||||
)
|
||||
|
||||
if self.appid:
|
||||
online = await self.check_online(self.appid)
|
||||
if online:
|
||||
logger.info(f"APPID: {self.appid} 已在线")
|
||||
return
|
||||
|
||||
payload = {
|
||||
"appId": self.appid
|
||||
}
|
||||
|
||||
|
||||
payload = {"appId": self.appid}
|
||||
|
||||
if self.appid:
|
||||
logger.info(f"使用 APPID: {self.appid}, {self.nickname}")
|
||||
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/login/getLoginQrCode",
|
||||
f"{self.base_url}/login/getLoginQrCode",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
json=payload,
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
if json_blob['ret'] != 200:
|
||||
if json_blob["ret"] != 200:
|
||||
raise Exception(f"获取二维码失败: {json_blob}")
|
||||
qr_data = json_blob['data']['qrData']
|
||||
qr_uuid = json_blob['data']['uuid']
|
||||
appid = json_blob['data']['appId']
|
||||
qr_data = json_blob["data"]["qrData"]
|
||||
qr_uuid = json_blob["data"]["uuid"]
|
||||
appid = json_blob["data"]["appId"]
|
||||
logger.info(f"APPID: {appid}")
|
||||
logger.warning(f"请打开该网址,然后使用微信扫描二维码登录: https://api.cl2wm.cn/api/qrcode/code?text={qr_data}")
|
||||
|
||||
logger.warning(
|
||||
f"请打开该网址,然后使用微信扫描二维码登录: https://api.cl2wm.cn/api/qrcode/code?text={qr_data}"
|
||||
)
|
||||
|
||||
# 执行登录
|
||||
retry_cnt = 64
|
||||
payload.update({
|
||||
"uuid": qr_uuid,
|
||||
"appId": appid
|
||||
})
|
||||
payload.update({"uuid": qr_uuid, "appId": appid})
|
||||
while retry_cnt > 0:
|
||||
retry_cnt -= 1
|
||||
|
||||
# 需要验证码
|
||||
if os.path.exists("data/temp/gewe_code"):
|
||||
with open("data/temp/gewe_code", "r") as f:
|
||||
code = f.read().strip()
|
||||
if not code:
|
||||
logger.warning(
|
||||
"未找到验证码,请在管理面板聊天页输入 /gewe_code 验证码 来验证,如 /gewe_code 123456"
|
||||
)
|
||||
await asyncio.sleep(5)
|
||||
continue
|
||||
payload["captchCode"] = code
|
||||
logger.info(f"使用验证码: {code}")
|
||||
try:
|
||||
os.remove("data/temp/gewe_code")
|
||||
except Exception:
|
||||
logger.warning("删除验证码文件 data/temp/gewe_code 失败。")
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/login/checkLogin",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
json=payload,
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.info(f"检查登录状态: {json_blob}")
|
||||
status = json_blob['data']['status']
|
||||
nickname = json_blob['data'].get('nickName', '')
|
||||
if status == 1:
|
||||
logger.info(f"等待确认...{nickname}")
|
||||
elif status == 2:
|
||||
logger.info(f"绿泡泡平台登录成功: {nickname}")
|
||||
break
|
||||
elif status == 0:
|
||||
logger.info("等待扫码...")
|
||||
|
||||
ret = json_blob["ret"]
|
||||
msg = ""
|
||||
if json_blob["data"] and "msg" in json_blob["data"]:
|
||||
msg = json_blob["data"]["msg"]
|
||||
if ret == 500 and "安全验证码" in msg:
|
||||
logger.warning(
|
||||
"此次登录需要安全验证码,请在管理面板聊天页输入 /gewe_code 验证码 来验证,如 /gewe_code 123456"
|
||||
)
|
||||
else:
|
||||
logger.warning(f"未知状态: {status}")
|
||||
status = json_blob["data"]["status"]
|
||||
nickname = json_blob["data"].get("nickName", "")
|
||||
if status == 1:
|
||||
logger.info(f"等待确认...{nickname}")
|
||||
elif status == 2:
|
||||
logger.info(f"绿泡泡平台登录成功: {nickname}")
|
||||
break
|
||||
elif status == 0:
|
||||
logger.info("等待扫码...")
|
||||
else:
|
||||
logger.warning(f"未知状态: {status}")
|
||||
await asyncio.sleep(5)
|
||||
|
||||
|
||||
if appid:
|
||||
sp.put(f"gewechat-appid-{self.nickname}", appid)
|
||||
self.appid = appid
|
||||
logger.info(f"已保存 APPID: {appid}")
|
||||
|
||||
|
||||
"""API"""
|
||||
|
||||
async def get_chatroom_member_list(self, chatroom_wxid: str):
|
||||
payload = {"appId": self.appid, "chatroomId": chatroom_wxid}
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/group/getChatroomMemberList",
|
||||
headers=self.headers,
|
||||
json=payload,
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
return json_blob["data"]
|
||||
|
||||
async def post_text(self, to_wxid, content: str, ats: str = ""):
|
||||
payload = {
|
||||
"appId": self.appid,
|
||||
@@ -319,65 +411,57 @@ class SimpleGewechatClient():
|
||||
"content": content,
|
||||
}
|
||||
if ats:
|
||||
payload['ats'] = ats
|
||||
|
||||
payload["ats"] = ats
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/message/postText",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
f"{self.base_url}/message/postText", headers=self.headers, json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.debug(f"发送消息结果: {json_blob}")
|
||||
|
||||
|
||||
async def post_image(self, to_wxid, image_url: str):
|
||||
payload = {
|
||||
"appId": self.appid,
|
||||
"toWxid": to_wxid,
|
||||
"imgUrl": image_url,
|
||||
}
|
||||
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/message/postImage",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
f"{self.base_url}/message/postImage", headers=self.headers, json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.debug(f"发送图片结果: {json_blob}")
|
||||
|
||||
|
||||
async def post_voice(self, to_wxid, voice_url: str, voice_duration: int):
|
||||
payload = {
|
||||
"appId": self.appid,
|
||||
"toWxid": to_wxid,
|
||||
"voiceUrl": voice_url,
|
||||
"voiceDuration": voice_duration
|
||||
"voiceDuration": voice_duration,
|
||||
}
|
||||
|
||||
|
||||
logger.debug(f"发送语音: {payload}")
|
||||
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/message/postVoice",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
f"{self.base_url}/message/postVoice", headers=self.headers, json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.debug(f"发送语音结果: {json_blob}")
|
||||
|
||||
|
||||
async def post_file(self, to_wxid, file_url: str, file_name: str):
|
||||
payload = {
|
||||
"appId": self.appid,
|
||||
"toWxid": to_wxid,
|
||||
"fileUrl": file_url,
|
||||
"fileName": file_name
|
||||
"fileName": file_name,
|
||||
}
|
||||
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{self.base_url}/message/postFile",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
f"{self.base_url}/message/postFile", headers=self.headers, json=payload
|
||||
) as resp:
|
||||
json_blob = await resp.json()
|
||||
logger.debug(f"发送文件结果: {json_blob}")
|
||||
logger.debug(f"发送文件结果: {json_blob}")
|
||||
|
||||
@@ -2,50 +2,40 @@ from astrbot import logger
|
||||
import aiohttp
|
||||
import json
|
||||
|
||||
class GeweDownloader():
|
||||
|
||||
class GeweDownloader:
|
||||
def __init__(self, base_url: str, download_base_url: str, token: str):
|
||||
self.base_url = base_url
|
||||
self.download_base_url = download_base_url
|
||||
self.headers = {
|
||||
"Content-Type": "application/json",
|
||||
"X-GEWE-TOKEN": token
|
||||
}
|
||||
|
||||
self.headers = {"Content-Type": "application/json", "X-GEWE-TOKEN": token}
|
||||
|
||||
async def _post_json(self, baseurl: str, route: str, payload: dict):
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(
|
||||
f"{baseurl}{route}",
|
||||
headers=self.headers,
|
||||
json=payload
|
||||
f"{baseurl}{route}", headers=self.headers, json=payload
|
||||
) as resp:
|
||||
return await resp.read()
|
||||
|
||||
|
||||
async def download_voice(self, appid: str, xml: str, msg_id: str):
|
||||
payload = {
|
||||
"appId": appid,
|
||||
"xml": xml,
|
||||
"msgId": msg_id
|
||||
}
|
||||
payload = {"appId": appid, "xml": xml, "msgId": msg_id}
|
||||
return await self._post_json(self.base_url, "/message/downloadVoice", payload)
|
||||
|
||||
|
||||
async def download_image(self, appid: str, xml: str) -> str:
|
||||
'''返回一个可下载的 URL'''
|
||||
choices = [2, 3] # 2:常规图片 3:缩略图
|
||||
|
||||
"""返回一个可下载的 URL"""
|
||||
choices = [2, 3] # 2:常规图片 3:缩略图
|
||||
|
||||
for choice in choices:
|
||||
try:
|
||||
payload = {
|
||||
"appId": appid,
|
||||
"xml": xml,
|
||||
"type": choice
|
||||
}
|
||||
data = await self._post_json(self.base_url, "/message/downloadImage", payload)
|
||||
payload = {"appId": appid, "xml": xml, "type": choice}
|
||||
data = await self._post_json(
|
||||
self.base_url, "/message/downloadImage", payload
|
||||
)
|
||||
json_blob = json.loads(data)
|
||||
if 'fileUrl' in json_blob['data']:
|
||||
return self.download_base_url + json_blob['data']['fileUrl']
|
||||
if "fileUrl" in json_blob["data"]:
|
||||
return self.download_base_url + json_blob["data"]["fileUrl"]
|
||||
|
||||
except BaseException as e:
|
||||
logger.error(f"gewe download image: {e}")
|
||||
continue
|
||||
|
||||
raise Exception("无法下载图片")
|
||||
|
||||
raise Exception("无法下载图片")
|
||||
|
||||
@@ -10,8 +10,9 @@ from astrbot.api.platform import AstrBotMessage, PlatformMetadata
|
||||
from astrbot.api.message_components import Plain, Image, Record, At, File
|
||||
from .client import SimpleGewechatClient
|
||||
|
||||
|
||||
def get_wav_duration(file_path):
|
||||
with wave.open(file_path, 'rb') as wav_file:
|
||||
with wave.open(file_path, "rb") as wav_file:
|
||||
file_size = os.path.getsize(file_path)
|
||||
n_channels, sampwidth, framerate, n_frames = wav_file.getparams()[:4]
|
||||
if n_frames == 2147483647:
|
||||
@@ -22,30 +23,30 @@ def get_wav_duration(file_path):
|
||||
duration = n_frames / float(framerate)
|
||||
return duration
|
||||
|
||||
|
||||
class GewechatPlatformEvent(AstrMessageEvent):
|
||||
def __init__(
|
||||
self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,
|
||||
client: SimpleGewechatClient
|
||||
):
|
||||
self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,
|
||||
client: SimpleGewechatClient,
|
||||
):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.client = client
|
||||
|
||||
|
||||
@staticmethod
|
||||
async def send_with_client(message: MessageChain, user_name: str):
|
||||
pass
|
||||
|
||||
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
to_wxid = self.message_obj.raw_message.get('to_wxid', None)
|
||||
|
||||
to_wxid = self.message_obj.raw_message.get("to_wxid", None)
|
||||
|
||||
if not to_wxid:
|
||||
logger.error("无法获取到 to_wxid。")
|
||||
return
|
||||
|
||||
|
||||
# 检查@
|
||||
ats = []
|
||||
ats_names = []
|
||||
@@ -54,7 +55,7 @@ class GewechatPlatformEvent(AstrMessageEvent):
|
||||
ats.append(comp.qq)
|
||||
ats_names.append(comp.name)
|
||||
has_at = False
|
||||
|
||||
|
||||
for comp in message.chain:
|
||||
if isinstance(comp, Plain):
|
||||
text = comp.text
|
||||
@@ -70,7 +71,7 @@ class GewechatPlatformEvent(AstrMessageEvent):
|
||||
payload["ats"] = ats
|
||||
has_at = True
|
||||
await self.client.post_text(**payload)
|
||||
|
||||
|
||||
elif isinstance(comp, Image):
|
||||
img_url = comp.file
|
||||
img_path = ""
|
||||
@@ -80,9 +81,9 @@ class GewechatPlatformEvent(AstrMessageEvent):
|
||||
img_path = await download_image_by_url(comp.file)
|
||||
else:
|
||||
img_path = img_url
|
||||
|
||||
|
||||
# 检查 record_path 是否在 data/temp 目录中, record_path 可能是绝对路径
|
||||
temp_directory = os.path.abspath('data/temp')
|
||||
temp_directory = os.path.abspath("data/temp")
|
||||
img_path = os.path.abspath(img_path)
|
||||
if os.path.commonpath([temp_directory, img_path]) != temp_directory:
|
||||
with open(img_path, "rb") as f:
|
||||
@@ -96,27 +97,29 @@ class GewechatPlatformEvent(AstrMessageEvent):
|
||||
# 默认已经存在 data/temp 中
|
||||
record_url = comp.file
|
||||
record_path = ""
|
||||
|
||||
|
||||
if record_url.startswith("file:///"):
|
||||
record_path = record_url[8:]
|
||||
elif record_url.startswith("http"):
|
||||
await download_file(record_url, f"data/temp/{uuid.uuid4()}.wav")
|
||||
else:
|
||||
record_path = record_url
|
||||
|
||||
|
||||
silk_path = f"data/temp/{uuid.uuid4()}.silk"
|
||||
try:
|
||||
duration = await wav_to_tencent_silk(record_path, silk_path)
|
||||
except Exception as e:
|
||||
logger.error(traceback.format_exc())
|
||||
await self.send(MessageChain().message(f"语音文件转换失败。{str(e)}"))
|
||||
await self.send(
|
||||
MessageChain().message(f"语音文件转换失败。{str(e)}")
|
||||
)
|
||||
logger.info("Silk 语音文件格式转换至: " + record_path)
|
||||
if duration == 0:
|
||||
duration = get_wav_duration(record_path)
|
||||
file_id = os.path.basename(silk_path)
|
||||
record_url = f"{self.client.file_server_url}/{file_id}"
|
||||
logger.debug(f"gewe callback record url: {record_url}")
|
||||
await self.client.post_voice(to_wxid, record_url, duration*1000)
|
||||
await self.client.post_voice(to_wxid, record_url, duration * 1000)
|
||||
elif isinstance(comp, File):
|
||||
file_path = comp.file
|
||||
file_name = comp.name
|
||||
@@ -126,14 +129,14 @@ class GewechatPlatformEvent(AstrMessageEvent):
|
||||
await download_file(file_path, f"data/temp/{file_name}")
|
||||
else:
|
||||
file_path = file_path
|
||||
|
||||
|
||||
file_id = os.path.basename(file_path)
|
||||
file_url = f"{self.client.file_server_url}/{file_id}"
|
||||
logger.debug(f"gewe callback file url: {file_url}")
|
||||
await self.client.post_file(to_wxid, file_url, file_id)
|
||||
await self.client.post_file(to_wxid, file_url, file_id)
|
||||
elif isinstance(comp, At):
|
||||
pass
|
||||
else:
|
||||
logger.error(f"gewechat 暂不支持发送消息类型: {comp.type}")
|
||||
|
||||
await super().send(message)
|
||||
logger.debug(f"gewechat 忽略: {comp.type}")
|
||||
|
||||
await super().send(message)
|
||||
|
||||
@@ -15,31 +15,47 @@ if sys.version_info >= (3, 12):
|
||||
from typing import override
|
||||
else:
|
||||
from typing_extensions import override
|
||||
|
||||
|
||||
|
||||
@register_platform_adapter("gewechat", "基于 gewechat 的 Wechat 适配器")
|
||||
class GewechatPlatformAdapter(Platform):
|
||||
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
def __init__(
|
||||
self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue
|
||||
) -> None:
|
||||
super().__init__(event_queue)
|
||||
self.config = platform_config
|
||||
self.settingss = platform_settings
|
||||
self.test_mode = os.environ.get('TEST_MODE', 'off') == 'on'
|
||||
self.test_mode = os.environ.get("TEST_MODE", "off") == "on"
|
||||
self.client = None
|
||||
|
||||
|
||||
self.client = SimpleGewechatClient(
|
||||
self.config["base_url"],
|
||||
self.config["nickname"],
|
||||
self.config["host"],
|
||||
self.config["port"],
|
||||
self._event_queue,
|
||||
)
|
||||
|
||||
async def on_event_received(abm: AstrBotMessage):
|
||||
await self.handle_msg(abm)
|
||||
|
||||
self.client.on_event_received = on_event_received
|
||||
|
||||
@override
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
):
|
||||
to_wxid = session.session_id
|
||||
if not to_wxid:
|
||||
logger.error("无法获取到 to_wxid。")
|
||||
return
|
||||
|
||||
|
||||
for comp in message_chain.chain:
|
||||
if isinstance(comp, Plain):
|
||||
await self.client.post_text(to_wxid, comp.text)
|
||||
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
|
||||
@override
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
@@ -47,43 +63,35 @@ class GewechatPlatformAdapter(Platform):
|
||||
"基于 gewechat 的 Wechat 适配器",
|
||||
)
|
||||
|
||||
@override
|
||||
def run(self):
|
||||
self.client = SimpleGewechatClient(
|
||||
self.config['base_url'],
|
||||
self.config['nickname'],
|
||||
self.config['host'],
|
||||
self.config['port'],
|
||||
self._event_queue,
|
||||
)
|
||||
|
||||
async def on_event_received(abm: AstrBotMessage):
|
||||
await self.handle_msg(abm)
|
||||
|
||||
self.client.on_event_received = on_event_received
|
||||
|
||||
return self._run()
|
||||
|
||||
async def terminate(self):
|
||||
self.client.stop = True
|
||||
await asyncio.sleep(1)
|
||||
|
||||
async def logout(self):
|
||||
await self.client.logout()
|
||||
|
||||
|
||||
@override
|
||||
def run(self):
|
||||
return self._run()
|
||||
|
||||
async def _run(self):
|
||||
await self.client.login()
|
||||
|
||||
await self.client.start_polling()
|
||||
|
||||
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
if message.type == MessageType.GROUP_MESSAGE:
|
||||
if self.settingss['unique_session']:
|
||||
if self.settingss["unique_session"]:
|
||||
message.session_id = message.sender.user_id + "_" + message.group_id
|
||||
|
||||
|
||||
message_event = GewechatPlatformEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id,
|
||||
client=self.client
|
||||
client=self.client,
|
||||
)
|
||||
|
||||
self.commit_event(message_event)
|
||||
|
||||
self.commit_event(message_event)
|
||||
|
||||
def get_client(self) -> SimpleGewechatClient:
|
||||
return self.client
|
||||
|
||||
@@ -1,97 +1,107 @@
|
||||
import base64
|
||||
import time
|
||||
import asyncio
|
||||
import json
|
||||
import re
|
||||
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
from astrbot.api.platform import (
|
||||
Platform,
|
||||
AstrBotMessage,
|
||||
MessageMember,
|
||||
MessageType,
|
||||
PlatformMetadata,
|
||||
)
|
||||
from astrbot.api.event import MessageChain
|
||||
from typing import Union, List
|
||||
from astrbot.api.message_components import Image, Plain, At
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from .lark_event import LarkMessageEvent
|
||||
from ...register import register_platform_adapter
|
||||
from astrbot.core.message.components import BaseMessageComponent
|
||||
from astrbot import logger
|
||||
import lark_oapi as lark
|
||||
from lark_oapi.api.im.v1 import *
|
||||
|
||||
|
||||
@register_platform_adapter("lark", "飞书机器人官方 API 适配器")
|
||||
class LarkPlatformAdapter(Platform):
|
||||
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
def __init__(
|
||||
self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue
|
||||
) -> None:
|
||||
super().__init__(event_queue)
|
||||
|
||||
self.config = platform_config
|
||||
|
||||
self.unique_session = platform_settings['unique_session']
|
||||
|
||||
self.appid = platform_config['app_id']
|
||||
self.appsecret = platform_config['app_secret']
|
||||
self.domain = platform_config.get('domain', lark.FEISHU_DOMAIN)
|
||||
self.bot_name = platform_config.get('lark_bot_name', "astrbot")
|
||||
|
||||
self.config = platform_config
|
||||
|
||||
self.unique_session = platform_settings["unique_session"]
|
||||
|
||||
self.appid = platform_config["app_id"]
|
||||
self.appsecret = platform_config["app_secret"]
|
||||
self.domain = platform_config.get("domain", lark.FEISHU_DOMAIN)
|
||||
self.bot_name = platform_config.get("lark_bot_name", "astrbot")
|
||||
|
||||
if not self.bot_name:
|
||||
logger.warning("未设置飞书机器人名称,@ 机器人可能得不到回复。")
|
||||
|
||||
|
||||
async def on_msg_event_recv(event: lark.im.v1.P2ImMessageReceiveV1):
|
||||
await self.convert_msg(event)
|
||||
|
||||
|
||||
def do_v2_msg_event(event: lark.im.v1.P2ImMessageReceiveV1):
|
||||
asyncio.create_task(on_msg_event_recv(event))
|
||||
|
||||
self.event_handler = lark.EventDispatcherHandler.builder("", "") \
|
||||
.register_p2_im_message_receive_v1(do_v2_msg_event) \
|
||||
|
||||
self.event_handler = (
|
||||
lark.EventDispatcherHandler.builder("", "")
|
||||
.register_p2_im_message_receive_v1(do_v2_msg_event)
|
||||
.build()
|
||||
|
||||
)
|
||||
|
||||
self.client = lark.ws.Client(
|
||||
app_id=self.appid,
|
||||
app_secret=self.appsecret,
|
||||
log_level=lark.LogLevel.ERROR,
|
||||
domain=self.domain,
|
||||
event_handler=self.event_handler
|
||||
event_handler=self.event_handler,
|
||||
)
|
||||
|
||||
|
||||
self.lark_api = (
|
||||
lark.Client.builder()
|
||||
.app_id(self.appid)
|
||||
.app_secret(self.appsecret)
|
||||
.build()
|
||||
lark.Client.builder().app_id(self.appid).app_secret(self.appsecret).build()
|
||||
)
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
):
|
||||
raise NotImplementedError("QQ 机器人官方 API 适配器不支持 send_by_session")
|
||||
|
||||
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
"lark",
|
||||
"飞书机器人官方 API 适配器",
|
||||
)
|
||||
|
||||
|
||||
async def convert_msg(self, event: lark.im.v1.P2ImMessageReceiveV1):
|
||||
message = event.event.message
|
||||
abm = AstrBotMessage()
|
||||
abm.timestamp = int(message.create_time) / 1000
|
||||
abm.message = []
|
||||
abm.type = MessageType.GROUP_MESSAGE if message.chat_type == 'group' else MessageType.FRIEND_MESSAGE
|
||||
if message.chat_type == 'group':
|
||||
abm.type = (
|
||||
MessageType.GROUP_MESSAGE
|
||||
if message.chat_type == "group"
|
||||
else MessageType.FRIEND_MESSAGE
|
||||
)
|
||||
if message.chat_type == "group":
|
||||
abm.group_id = message.chat_id
|
||||
abm.self_id = self.bot_name
|
||||
abm.message_str = ""
|
||||
|
||||
|
||||
at_list = {}
|
||||
if message.mentions:
|
||||
for m in message.mentions:
|
||||
at_list[m.key] = At(qq=m.id.open_id, name=m.name)
|
||||
if m.name == self.bot_name:
|
||||
abm.self_id = m.id.open_id
|
||||
|
||||
|
||||
content_json_b = json.loads(message.content)
|
||||
|
||||
if message.message_type == 'text':
|
||||
message_str_raw = content_json_b['text'] # 带有 @ 的消息
|
||||
|
||||
if message.message_type == "text":
|
||||
message_str_raw = content_json_b["text"] # 带有 @ 的消息
|
||||
at_pattern = r"(@_user_\d+)" # 可以根据需求修改正则
|
||||
at_users = re.findall(at_pattern, message_str_raw)
|
||||
# at_users = re.findall(at_pattern, message_str_raw)
|
||||
# 拆分文本,去掉AT符号部分
|
||||
parts = re.split(at_pattern, message_str_raw)
|
||||
for i in range(len(parts)):
|
||||
@@ -102,41 +112,43 @@ class LarkPlatformAdapter(Platform):
|
||||
abm.message.append(at_list[s])
|
||||
else:
|
||||
abm.message.append(Plain(parts[i].strip()))
|
||||
elif message.message_type == 'post':
|
||||
elif message.message_type == "post":
|
||||
_ls = []
|
||||
|
||||
content_ls = content_json_b.get('content', [])
|
||||
|
||||
content_ls = content_json_b.get("content", [])
|
||||
for comp in content_ls:
|
||||
if isinstance(comp, list):
|
||||
_ls.extend(comp)
|
||||
elif isinstance(comp, dict):
|
||||
_ls.append(comp)
|
||||
content_json_b = _ls
|
||||
elif message.message_type == 'image':
|
||||
elif message.message_type == "image":
|
||||
content_json_b = [
|
||||
{"tag": "img", "image_key": content_json_b["image_key"], "style": []}
|
||||
]
|
||||
|
||||
if message.message_type in ('post', 'image'):
|
||||
|
||||
if message.message_type in ("post", "image"):
|
||||
for comp in content_json_b:
|
||||
if comp['tag'] == 'at':
|
||||
abm.message.append(at_list[comp['user_id']])
|
||||
elif comp['tag'] == 'text' and comp['text'].strip():
|
||||
abm.message.append(Plain(comp['text'].strip()))
|
||||
elif comp['tag'] == 'img':
|
||||
image_key = comp['image_key']
|
||||
request = GetMessageResourceRequest.builder() \
|
||||
.message_id(message.message_id) \
|
||||
.file_key(image_key) \
|
||||
.type("image") \
|
||||
if comp["tag"] == "at":
|
||||
abm.message.append(at_list[comp["user_id"]])
|
||||
elif comp["tag"] == "text" and comp["text"].strip():
|
||||
abm.message.append(Plain(comp["text"].strip()))
|
||||
elif comp["tag"] == "img":
|
||||
image_key = comp["image_key"]
|
||||
request = (
|
||||
GetMessageResourceRequest.builder()
|
||||
.message_id(message.message_id)
|
||||
.file_key(image_key)
|
||||
.type("image")
|
||||
.build()
|
||||
)
|
||||
response = await self.lark_api.im.v1.message_resource.aget(request)
|
||||
if not response.success():
|
||||
logger.error(f"无法下载飞书图片: {image_key}")
|
||||
image_bytes = response.file.read()
|
||||
image_base64 = base64.b64encode(image_bytes).decode()
|
||||
abm.message.append(Image.fromBase64(image_base64))
|
||||
|
||||
|
||||
for comp in abm.message:
|
||||
if isinstance(comp, Plain):
|
||||
abm.message_str += comp.text
|
||||
@@ -144,7 +156,7 @@ class LarkPlatformAdapter(Platform):
|
||||
abm.raw_message = message
|
||||
abm.sender = MessageMember(
|
||||
user_id=event.event.sender.sender_id.open_id,
|
||||
nickname=event.event.sender.sender_id.open_id[:8]
|
||||
nickname=event.event.sender.sender_id.open_id[:8],
|
||||
)
|
||||
# 独立会话
|
||||
if not self.unique_session:
|
||||
@@ -154,22 +166,24 @@ class LarkPlatformAdapter(Platform):
|
||||
abm.session_id = abm.sender.user_id
|
||||
else:
|
||||
abm.session_id = abm.sender.user_id
|
||||
|
||||
|
||||
logger.debug(abm)
|
||||
await self.handle_msg(abm)
|
||||
|
||||
|
||||
async def handle_msg(self, abm: AstrBotMessage):
|
||||
event = LarkMessageEvent(
|
||||
message_str=abm.message_str,
|
||||
message_obj=abm,
|
||||
platform_meta=self.meta(),
|
||||
session_id=abm.session_id,
|
||||
bot=self.lark_api
|
||||
bot=self.lark_api,
|
||||
)
|
||||
|
||||
|
||||
self._event_queue.put_nowait(event)
|
||||
|
||||
|
||||
async def run(self):
|
||||
# self.client.start()
|
||||
await self.client._connect()
|
||||
|
||||
|
||||
def get_client(self) -> lark.Client:
|
||||
return self.client
|
||||
|
||||
@@ -3,36 +3,32 @@ import uuid
|
||||
import lark_oapi as lark
|
||||
from typing import List
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.message_components import Plain, Image as AstrBotImage, Record, At, Node, Music, Video
|
||||
from astrbot.core.utils.io import file_to_base64, download_image_by_url
|
||||
from astrbot.api.message_components import Plain, Image as AstrBotImage, At
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
from lark_oapi.api.im.v1 import *
|
||||
from astrbot import logger
|
||||
|
||||
|
||||
class LarkMessageEvent(AstrMessageEvent):
|
||||
def __init__(self, message_str, message_obj, platform_meta, session_id, bot: lark.Client):
|
||||
def __init__(
|
||||
self, message_str, message_obj, platform_meta, session_id, bot: lark.Client
|
||||
):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.bot = bot
|
||||
|
||||
|
||||
@staticmethod
|
||||
async def _convert_to_lark(message: MessageChain, lark_client: lark.Client) -> List:
|
||||
ret = []
|
||||
_stage = []
|
||||
for comp in message.chain:
|
||||
if isinstance(comp, Plain):
|
||||
_stage.append({
|
||||
"tag": "md",
|
||||
"text": comp.text
|
||||
})
|
||||
_stage.append({"tag": "md", "text": comp.text})
|
||||
elif isinstance(comp, At):
|
||||
_stage.append({
|
||||
"tag": "at",
|
||||
"user_id": comp.qq,
|
||||
"style": []
|
||||
})
|
||||
_stage.append({"tag": "at", "user_id": comp.qq, "style": []})
|
||||
elif isinstance(comp, AstrBotImage):
|
||||
file_path = ""
|
||||
if comp.file and comp.file.startswith("file:///"):
|
||||
file_path = comp.file.replace('file:///', '')
|
||||
file_path = comp.file.replace("file:///", "")
|
||||
elif comp.file and comp.file.startswith("http"):
|
||||
image_file_path = await download_image_by_url(comp.file)
|
||||
file_path = image_file_path
|
||||
@@ -40,31 +36,30 @@ class LarkMessageEvent(AstrMessageEvent):
|
||||
pass
|
||||
else:
|
||||
file_path = comp.file
|
||||
|
||||
request = CreateImageRequest.builder() \
|
||||
.request_body( \
|
||||
CreateImageRequestBody.builder() \
|
||||
.image_type("message") \
|
||||
.image(open(file_path, 'rb')) \
|
||||
.build() \
|
||||
) \
|
||||
|
||||
request = (
|
||||
CreateImageRequest.builder()
|
||||
.request_body(
|
||||
CreateImageRequestBody.builder()
|
||||
.image_type("message")
|
||||
.image(open(file_path, "rb"))
|
||||
.build()
|
||||
)
|
||||
.build()
|
||||
)
|
||||
response = await lark_client.im.v1.image.acreate(request)
|
||||
if not response.success():
|
||||
logger.error(f"无法上传飞书图片({response.code}): {response.msg}")
|
||||
image_key = response.data.image_key
|
||||
print(image_key)
|
||||
ret.append(_stage)
|
||||
ret.append([{
|
||||
"tag": "img",
|
||||
"image_key": image_key
|
||||
}])
|
||||
ret.append([{"tag": "img", "image_key": image_key}])
|
||||
_stage.clear()
|
||||
else:
|
||||
logger.warning(f"飞书 暂时不支持消息段: {comp.type}")
|
||||
|
||||
if _stage:
|
||||
ret.append(_stage)
|
||||
ret.append(_stage)
|
||||
return ret
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
@@ -76,21 +71,23 @@ class LarkMessageEvent(AstrMessageEvent):
|
||||
}
|
||||
}
|
||||
|
||||
request = ReplyMessageRequest.builder() \
|
||||
.message_id(self.message_obj.message_id) \
|
||||
.request_body( \
|
||||
ReplyMessageRequestBody.builder() \
|
||||
.content(json.dumps(wrapped)) \
|
||||
.msg_type("post") \
|
||||
.uuid(str(uuid.uuid4())) \
|
||||
.reply_in_thread(False) \
|
||||
.build() \
|
||||
) \
|
||||
request = (
|
||||
ReplyMessageRequest.builder()
|
||||
.message_id(self.message_obj.message_id)
|
||||
.request_body(
|
||||
ReplyMessageRequestBody.builder()
|
||||
.content(json.dumps(wrapped))
|
||||
.msg_type("post")
|
||||
.uuid(str(uuid.uuid4()))
|
||||
.reply_in_thread(False)
|
||||
.build()
|
||||
)
|
||||
.build()
|
||||
)
|
||||
|
||||
response = await self.bot.im.v1.message.areply(request)
|
||||
|
||||
|
||||
if not response.success():
|
||||
logger.error(f"回复飞书消息失败({response.code}): {response.msg}")
|
||||
|
||||
await super().send(message)
|
||||
|
||||
await super().send(message)
|
||||
|
||||
@@ -5,18 +5,25 @@ import botpy.types.message
|
||||
from astrbot.core.utils.io import file_to_base64, download_image_by_url
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.platform import AstrBotMessage, PlatformMetadata
|
||||
from astrbot.api.message_components import Plain, Image, Reply
|
||||
from astrbot.api.message_components import Plain, Image
|
||||
from botpy import Client
|
||||
from botpy.http import Route
|
||||
from astrbot.api import logger
|
||||
|
||||
|
||||
class QQOfficialMessageEvent(AstrMessageEvent):
|
||||
def __init__(self, message_str: str, message_obj: AstrBotMessage, platform_meta: PlatformMetadata, session_id: str, bot: Client):
|
||||
def __init__(
|
||||
self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,
|
||||
bot: Client,
|
||||
):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.bot = bot
|
||||
self.send_buffer = None
|
||||
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
if not self.send_buffer:
|
||||
self.send_buffer = message
|
||||
@@ -24,82 +31,87 @@ class QQOfficialMessageEvent(AstrMessageEvent):
|
||||
self.send_buffer.chain.extend(message.chain)
|
||||
|
||||
async def _post_send(self):
|
||||
'''QQ 官方 API 仅支持回复一次'''
|
||||
"""QQ 官方 API 仅支持回复一次"""
|
||||
source = self.message_obj.raw_message
|
||||
assert isinstance(source, (botpy.message.Message, botpy.message.GroupMessage, botpy.message.DirectMessage, botpy.message.C2CMessage))
|
||||
|
||||
plain_text, image_base64, image_path = await QQOfficialMessageEvent._parse_to_qqofficial(self.send_buffer)
|
||||
|
||||
assert isinstance(
|
||||
source,
|
||||
(
|
||||
botpy.message.Message,
|
||||
botpy.message.GroupMessage,
|
||||
botpy.message.DirectMessage,
|
||||
botpy.message.C2CMessage,
|
||||
),
|
||||
)
|
||||
|
||||
(
|
||||
plain_text,
|
||||
image_base64,
|
||||
image_path,
|
||||
) = await QQOfficialMessageEvent._parse_to_qqofficial(self.send_buffer)
|
||||
|
||||
if not plain_text and not image_base64 and not image_path:
|
||||
return
|
||||
|
||||
ref = None
|
||||
for i in self.send_buffer.chain:
|
||||
if isinstance(i, Reply):
|
||||
try:
|
||||
ref = self.message_obj.raw_message.message_reference
|
||||
ref = botpy.types.message.Reference(
|
||||
message_id=ref.message_id,
|
||||
ignore_get_message_error=False
|
||||
)
|
||||
except BaseException as _:
|
||||
pass
|
||||
break
|
||||
|
||||
|
||||
payload = {
|
||||
'content': plain_text,
|
||||
'msg_id': self.message_obj.message_id,
|
||||
"content": plain_text,
|
||||
"msg_id": self.message_obj.message_id,
|
||||
}
|
||||
|
||||
|
||||
match type(source):
|
||||
case botpy.message.GroupMessage:
|
||||
if ref:
|
||||
payload['message_reference'] = ref
|
||||
if image_base64:
|
||||
media = await self.upload_group_and_c2c_image(image_base64, 1, group_openid=source.group_openid)
|
||||
payload['media'] = media
|
||||
payload['msg_type'] = 7
|
||||
await self.bot.api.post_group_message(group_openid=source.group_openid, **payload)
|
||||
media = await self.upload_group_and_c2c_image(
|
||||
image_base64, 1, group_openid=source.group_openid
|
||||
)
|
||||
payload["media"] = media
|
||||
payload["msg_type"] = 7
|
||||
await self.bot.api.post_group_message(
|
||||
group_openid=source.group_openid, **payload
|
||||
)
|
||||
case botpy.message.C2CMessage:
|
||||
if ref:
|
||||
payload['message_reference'] = ref
|
||||
if image_base64:
|
||||
media = await self.upload_group_and_c2c_image(image_base64, 1, openid=source.author.user_openid)
|
||||
payload['media'] = media
|
||||
payload['msg_type'] = 7
|
||||
await self.bot.api.post_c2c_message(openid=source.author.user_openid, **payload)
|
||||
media = await self.upload_group_and_c2c_image(
|
||||
image_base64, 1, openid=source.author.user_openid
|
||||
)
|
||||
payload["media"] = media
|
||||
payload["msg_type"] = 7
|
||||
await self.bot.api.post_c2c_message(
|
||||
openid=source.author.user_openid, **payload
|
||||
)
|
||||
case botpy.message.Message:
|
||||
if ref:
|
||||
payload['message_reference'] = ref
|
||||
if image_path:
|
||||
payload['file_image'] = image_path
|
||||
payload["file_image"] = image_path
|
||||
await self.bot.api.post_message(channel_id=source.channel_id, **payload)
|
||||
case botpy.message.DirectMessage:
|
||||
if ref:
|
||||
payload['message_reference'] = ref
|
||||
if image_path:
|
||||
payload['file_image'] = image_path
|
||||
payload["file_image"] = image_path
|
||||
await self.bot.api.post_dms(guild_id=source.guild_id, **payload)
|
||||
|
||||
await super().send(self.send_buffer)
|
||||
|
||||
|
||||
self.send_buffer = None
|
||||
|
||||
async def upload_group_and_c2c_image(self, image_base64: str, file_type: int, **kwargs) -> botpy.types.message.Media:
|
||||
|
||||
async def upload_group_and_c2c_image(
|
||||
self, image_base64: str, file_type: int, **kwargs
|
||||
) -> botpy.types.message.Media:
|
||||
payload = {
|
||||
'file_data': image_base64,
|
||||
'file_type': file_type,
|
||||
"srv_send_msg": False
|
||||
"file_data": image_base64,
|
||||
"file_type": file_type,
|
||||
"srv_send_msg": False,
|
||||
}
|
||||
if 'openid' in kwargs:
|
||||
payload['openid'] = kwargs['openid']
|
||||
route = Route("POST", "/v2/users/{openid}/files", openid=kwargs['openid'])
|
||||
if "openid" in kwargs:
|
||||
payload["openid"] = kwargs["openid"]
|
||||
route = Route("POST", "/v2/users/{openid}/files", openid=kwargs["openid"])
|
||||
return await self.bot.api._http.request(route, json=payload)
|
||||
elif 'group_openid' in kwargs:
|
||||
payload['group_openid'] = kwargs['group_openid']
|
||||
route = Route("POST", "/v2/groups/{group_openid}/files", group_openid=kwargs['group_openid'])
|
||||
elif "group_openid" in kwargs:
|
||||
payload["group_openid"] = kwargs["group_openid"]
|
||||
route = Route(
|
||||
"POST",
|
||||
"/v2/groups/{group_openid}/files",
|
||||
group_openid=kwargs["group_openid"],
|
||||
)
|
||||
return await self.bot.api._http.request(route, json=payload)
|
||||
|
||||
|
||||
@staticmethod
|
||||
async def _parse_to_qqofficial(message: MessageChain):
|
||||
plain_text = ""
|
||||
@@ -114,10 +126,12 @@ class QQOfficialMessageEvent(AstrMessageEvent):
|
||||
image_file_path = i.file[8:]
|
||||
elif i.file and i.file.startswith("http"):
|
||||
image_file_path = await download_image_by_url(i.file)
|
||||
image_base64 = file_to_base64(image_file_path).replace("base64://", "")
|
||||
image_base64 = file_to_base64(image_file_path).replace(
|
||||
"base64://", ""
|
||||
)
|
||||
else:
|
||||
image_base64 = file_to_base64(i.file).replace("base64://", "")
|
||||
image_file_path = i.file
|
||||
else:
|
||||
logger.error(f"qq_official 暂不支持发送消息类型 {i.type}")
|
||||
return plain_text, image_base64, image_file_path
|
||||
logger.debug(f"qq_official 忽略 {i.type}")
|
||||
return plain_text, image_base64, image_file_path
|
||||
|
||||
@@ -10,7 +10,13 @@ import botpy.types.message
|
||||
import os
|
||||
|
||||
from botpy import Client
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
from astrbot.api.platform import (
|
||||
Platform,
|
||||
AstrBotMessage,
|
||||
MessageMember,
|
||||
MessageType,
|
||||
PlatformMetadata,
|
||||
)
|
||||
from astrbot.api.event import MessageChain
|
||||
from typing import Union, List
|
||||
from astrbot.api.message_components import Image, Plain, At
|
||||
@@ -23,67 +29,84 @@ from astrbot.core.message.components import BaseMessageComponent
|
||||
for handler in logging.root.handlers[:]:
|
||||
logging.root.removeHandler(handler)
|
||||
|
||||
|
||||
# QQ 机器人官方框架
|
||||
class botClient(Client):
|
||||
def set_platform(self, platform: 'QQOfficialPlatformAdapter'):
|
||||
def set_platform(self, platform: "QQOfficialPlatformAdapter"):
|
||||
self.platform = platform
|
||||
|
||||
|
||||
# 收到群消息
|
||||
async def on_group_at_message_create(self, message: botpy.message.GroupMessage):
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(message, MessageType.GROUP_MESSAGE)
|
||||
abm.session_id = abm.sender.user_id if self.platform.unique_session else message.group_openid
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(
|
||||
message, MessageType.GROUP_MESSAGE
|
||||
)
|
||||
abm.session_id = (
|
||||
abm.sender.user_id if self.platform.unique_session else message.group_openid
|
||||
)
|
||||
self._commit(abm)
|
||||
|
||||
# 收到频道消息
|
||||
async def on_at_message_create(self, message: botpy.message.Message):
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(message, MessageType.GROUP_MESSAGE)
|
||||
abm.session_id = abm.sender.user_id if self.platform.unique_session else message.channel_id
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(
|
||||
message, MessageType.GROUP_MESSAGE
|
||||
)
|
||||
abm.session_id = (
|
||||
abm.sender.user_id if self.platform.unique_session else message.channel_id
|
||||
)
|
||||
self._commit(abm)
|
||||
|
||||
|
||||
# 收到私聊消息
|
||||
async def on_direct_message_create(self, message: botpy.message.DirectMessage):
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(message, MessageType.FRIEND_MESSAGE)
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(
|
||||
message, MessageType.FRIEND_MESSAGE
|
||||
)
|
||||
abm.session_id = abm.sender.user_id
|
||||
self._commit(abm)
|
||||
|
||||
|
||||
# 收到 C2C 消息
|
||||
async def on_c2c_message_create(self, message: botpy.message.C2CMessage):
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(message, MessageType.FRIEND_MESSAGE)
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(
|
||||
message, MessageType.FRIEND_MESSAGE
|
||||
)
|
||||
abm.session_id = abm.sender.user_id
|
||||
self._commit(abm)
|
||||
|
||||
|
||||
def _commit(self, abm: AstrBotMessage):
|
||||
self.platform.commit_event(QQOfficialMessageEvent(
|
||||
abm.message_str,
|
||||
abm,
|
||||
self.platform.meta(),
|
||||
abm.session_id,
|
||||
self.platform.client
|
||||
))
|
||||
self.platform.commit_event(
|
||||
QQOfficialMessageEvent(
|
||||
abm.message_str,
|
||||
abm,
|
||||
self.platform.meta(),
|
||||
abm.session_id,
|
||||
self.platform.client,
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@register_platform_adapter("qq_official", "QQ 机器人官方 API 适配器")
|
||||
class QQOfficialPlatformAdapter(Platform):
|
||||
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
def __init__(
|
||||
self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue
|
||||
) -> None:
|
||||
super().__init__(event_queue)
|
||||
|
||||
|
||||
self.config = platform_config
|
||||
|
||||
self.appid = platform_config['appid']
|
||||
self.secret = platform_config['secret']
|
||||
self.unique_session = platform_settings['unique_session']
|
||||
qq_group = platform_config['enable_group_c2c']
|
||||
guild_dm = platform_config['enable_guild_direct_message']
|
||||
|
||||
self.appid = platform_config["appid"]
|
||||
self.secret = platform_config["secret"]
|
||||
self.unique_session = platform_settings["unique_session"]
|
||||
qq_group = platform_config["enable_group_c2c"]
|
||||
guild_dm = platform_config["enable_guild_direct_message"]
|
||||
|
||||
if qq_group:
|
||||
self.intents = botpy.Intents(
|
||||
public_messages=True,
|
||||
public_guild_messages=True,
|
||||
direct_message=guild_dm
|
||||
direct_message=guild_dm,
|
||||
)
|
||||
else:
|
||||
self.intents = botpy.Intents(
|
||||
public_guild_messages=True,
|
||||
direct_message=guild_dm
|
||||
public_guild_messages=True, direct_message=guild_dm
|
||||
)
|
||||
self.client = botClient(
|
||||
intents=self.intents,
|
||||
@@ -92,12 +115,14 @@ class QQOfficialPlatformAdapter(Platform):
|
||||
)
|
||||
|
||||
self.client.set_platform(self)
|
||||
|
||||
self.test_mode = os.environ.get('TEST_MODE', 'off') == 'on'
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
|
||||
self.test_mode = os.environ.get("TEST_MODE", "off") == "on"
|
||||
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
):
|
||||
raise NotImplementedError("QQ 机器人官方 API 适配器不支持 send_by_session")
|
||||
|
||||
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
"qq_official",
|
||||
@@ -105,8 +130,10 @@ class QQOfficialPlatformAdapter(Platform):
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _parse_from_qqofficial(message: Union[botpy.message.Message, botpy.message.GroupMessage],
|
||||
message_type: MessageType):
|
||||
def _parse_from_qqofficial(
|
||||
message: Union[botpy.message.Message, botpy.message.GroupMessage],
|
||||
message_type: MessageType,
|
||||
):
|
||||
abm = AstrBotMessage()
|
||||
abm.type = message_type
|
||||
abm.timestamp = int(time.time())
|
||||
@@ -114,20 +141,15 @@ class QQOfficialPlatformAdapter(Platform):
|
||||
abm.message_id = message.id
|
||||
abm.tag = "qq_official"
|
||||
msg: List[BaseMessageComponent] = []
|
||||
|
||||
|
||||
if isinstance(message, botpy.message.GroupMessage) or isinstance(message, botpy.message.C2CMessage):
|
||||
if isinstance(message, botpy.message.GroupMessage) or isinstance(
|
||||
message, botpy.message.C2CMessage
|
||||
):
|
||||
if isinstance(message, botpy.message.GroupMessage):
|
||||
abm.sender = MessageMember(
|
||||
message.author.member_openid,
|
||||
""
|
||||
)
|
||||
abm.sender = MessageMember(message.author.member_openid, "")
|
||||
abm.group_id = message.group_openid
|
||||
else:
|
||||
abm.sender = MessageMember(
|
||||
message.author.user_openid,
|
||||
""
|
||||
)
|
||||
abm.sender = MessageMember(message.author.user_openid, "")
|
||||
abm.message_str = message.content.strip()
|
||||
abm.self_id = "unknown_selfid"
|
||||
msg.append(At(qq="qq_official"))
|
||||
@@ -137,37 +159,39 @@ class QQOfficialPlatformAdapter(Platform):
|
||||
if i.content_type.startswith("image"):
|
||||
url = i.url
|
||||
if not url.startswith("http"):
|
||||
url = "https://"+url
|
||||
url = "https://" + url
|
||||
img = Image.fromURL(url)
|
||||
msg.append(img)
|
||||
abm.message = msg
|
||||
|
||||
elif isinstance(message, botpy.message.Message) or isinstance(message, botpy.message.DirectMessage):
|
||||
elif isinstance(message, botpy.message.Message) or isinstance(
|
||||
message, botpy.message.DirectMessage
|
||||
):
|
||||
try:
|
||||
abm.self_id = str(message.mentions[0].id)
|
||||
except BaseException as _:
|
||||
abm.self_id = ""
|
||||
|
||||
plain_content = message.content.replace(
|
||||
"<@!"+str(abm.self_id)+">", "").strip()
|
||||
"<@!" + str(abm.self_id) + ">", ""
|
||||
).strip()
|
||||
|
||||
if message.attachments:
|
||||
for i in message.attachments:
|
||||
if i.content_type.startswith("image"):
|
||||
url = i.url
|
||||
if not url.startswith("http"):
|
||||
url = "https://"+url
|
||||
url = "https://" + url
|
||||
img = Image.fromURL(url)
|
||||
msg.append(img)
|
||||
abm.message = msg
|
||||
abm.message_str = plain_content
|
||||
abm.sender = MessageMember(
|
||||
str(message.author.id),
|
||||
str(message.author.username)
|
||||
str(message.author.id), str(message.author.username)
|
||||
)
|
||||
msg.append(At(qq="qq_official"))
|
||||
msg.append(Plain(plain_content))
|
||||
|
||||
|
||||
if isinstance(message, botpy.message.Message):
|
||||
abm.group_id = message.channel_id
|
||||
else:
|
||||
@@ -176,7 +200,7 @@ class QQOfficialPlatformAdapter(Platform):
|
||||
return abm
|
||||
|
||||
def run(self):
|
||||
return self.client.start(
|
||||
appid=self.appid,
|
||||
secret=self.secret
|
||||
)
|
||||
return self.client.start(appid=self.appid, secret=self.secret)
|
||||
|
||||
def get_client(self) -> botClient:
|
||||
return self.client
|
||||
|
||||
@@ -17,72 +17,85 @@ from ..qqofficial.qqofficial_platform_adapter import QQOfficialPlatformAdapter
|
||||
# remove logger handler
|
||||
for handler in logging.root.handlers[:]:
|
||||
logging.root.removeHandler(handler)
|
||||
|
||||
|
||||
|
||||
# QQ 机器人官方框架
|
||||
class botClient(Client):
|
||||
def set_platform(self, platform: 'QQOfficialWebhookPlatformAdapter'):
|
||||
def set_platform(self, platform: "QQOfficialWebhookPlatformAdapter"):
|
||||
self.platform = platform
|
||||
|
||||
|
||||
# 收到群消息
|
||||
async def on_group_at_message_create(self, message: botpy.message.GroupMessage):
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(message, MessageType.GROUP_MESSAGE)
|
||||
abm.session_id = abm.sender.user_id if self.platform.unique_session else message.group_openid
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(
|
||||
message, MessageType.GROUP_MESSAGE
|
||||
)
|
||||
abm.session_id = (
|
||||
abm.sender.user_id if self.platform.unique_session else message.group_openid
|
||||
)
|
||||
self._commit(abm)
|
||||
|
||||
# 收到频道消息
|
||||
async def on_at_message_create(self, message: botpy.message.Message):
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(message, MessageType.GROUP_MESSAGE)
|
||||
abm.session_id = abm.sender.user_id if self.platform.unique_session else message.channel_id
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(
|
||||
message, MessageType.GROUP_MESSAGE
|
||||
)
|
||||
abm.session_id = (
|
||||
abm.sender.user_id if self.platform.unique_session else message.channel_id
|
||||
)
|
||||
self._commit(abm)
|
||||
|
||||
|
||||
# 收到私聊消息
|
||||
async def on_direct_message_create(self, message: botpy.message.DirectMessage):
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(message, MessageType.FRIEND_MESSAGE)
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(
|
||||
message, MessageType.FRIEND_MESSAGE
|
||||
)
|
||||
abm.session_id = abm.sender.user_id
|
||||
self._commit(abm)
|
||||
|
||||
|
||||
# 收到 C2C 消息
|
||||
async def on_c2c_message_create(self, message: botpy.message.C2CMessage):
|
||||
abm = self.platform._parse_from_qqofficial(message, MessageType.FRIEND_MESSAGE)
|
||||
abm = QQOfficialPlatformAdapter._parse_from_qqofficial(
|
||||
message, MessageType.FRIEND_MESSAGE
|
||||
)
|
||||
abm.session_id = abm.sender.user_id
|
||||
self._commit(abm)
|
||||
|
||||
|
||||
def _commit(self, abm: AstrBotMessage):
|
||||
self.platform.commit_event(QQOfficialWebhookMessageEvent(
|
||||
abm.message_str,
|
||||
abm,
|
||||
self.platform.meta(),
|
||||
abm.session_id,
|
||||
self
|
||||
))
|
||||
|
||||
self.platform.commit_event(
|
||||
QQOfficialWebhookMessageEvent(
|
||||
abm.message_str, abm, self.platform.meta(), abm.session_id, self
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@register_platform_adapter("qq_official_webhook", "QQ 机器人官方 API 适配器(Webhook)")
|
||||
class QQOfficialWebhookPlatformAdapter(Platform):
|
||||
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
def __init__(
|
||||
self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue
|
||||
) -> None:
|
||||
super().__init__(event_queue)
|
||||
|
||||
|
||||
self.config = platform_config
|
||||
|
||||
self.appid = platform_config['appid']
|
||||
self.secret = platform_config['secret']
|
||||
self.unique_session = platform_settings['unique_session']
|
||||
|
||||
self.appid = platform_config["appid"]
|
||||
self.secret = platform_config["secret"]
|
||||
self.unique_session = platform_settings["unique_session"]
|
||||
|
||||
intents = botpy.Intents(
|
||||
public_messages=True,
|
||||
public_guild_messages=True,
|
||||
direct_message=True
|
||||
public_messages=True, public_guild_messages=True, direct_message=True
|
||||
)
|
||||
self.client = botClient(
|
||||
intents=intents, # 已经无用
|
||||
intents=intents, # 已经无用
|
||||
bot_log=False,
|
||||
timeout=20,
|
||||
)
|
||||
self.client.set_platform(self)
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
):
|
||||
raise NotImplementedError("QQ 机器人官方 API 适配器不支持 send_by_session")
|
||||
|
||||
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
"qq_official_webhook",
|
||||
@@ -91,9 +104,10 @@ class QQOfficialWebhookPlatformAdapter(Platform):
|
||||
|
||||
async def run(self):
|
||||
self.webhook_helper = QQOfficialWebhook(
|
||||
self.config,
|
||||
self._event_queue,
|
||||
self.client
|
||||
self.config, self._event_queue, self.client
|
||||
)
|
||||
await self.webhook_helper.initialize()
|
||||
await self.webhook_helper.start_polling()
|
||||
await self.webhook_helper.start_polling()
|
||||
|
||||
def get_client(self) -> botClient:
|
||||
return self.client
|
||||
|
||||
@@ -1,18 +1,15 @@
|
||||
import botpy
|
||||
import botpy.message
|
||||
import botpy.types
|
||||
import botpy.types.message
|
||||
from astrbot.core.utils.io import file_to_base64, download_image_by_url
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.platform import AstrBotMessage, PlatformMetadata
|
||||
from astrbot.api.message_components import Plain, Image, Reply
|
||||
from botpy import Client
|
||||
from botpy.http import Route
|
||||
from astrbot.api import logger
|
||||
from ..qqofficial.qqofficial_message_event import QQOfficialMessageEvent
|
||||
|
||||
|
||||
class QQOfficialWebhookMessageEvent(QQOfficialMessageEvent):
|
||||
def __init__(self, message_str: str, message_obj: AstrBotMessage, platform_meta: PlatformMetadata, session_id: str, bot: Client):
|
||||
def __init__(
|
||||
self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,
|
||||
bot: Client,
|
||||
):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id, bot)
|
||||
|
||||
@@ -1,47 +1,46 @@
|
||||
import aiohttp
|
||||
import quart
|
||||
import json
|
||||
import logging
|
||||
import asyncio
|
||||
import typing
|
||||
from botpy import BotAPI, BotHttp, Client, Token, BotWebSocket, ConnectionSession
|
||||
from astrbot.api import logger
|
||||
import traceback
|
||||
from cryptography.hazmat.primitives.asymmetric import ed25519
|
||||
|
||||
# remove logger handler
|
||||
for handler in logging.root.handlers[:]:
|
||||
logging.root.removeHandler(handler)
|
||||
|
||||
class QQOfficialWebhook():
|
||||
|
||||
class QQOfficialWebhook:
|
||||
def __init__(self, config: dict, event_queue: asyncio.Queue, botpy_client: Client):
|
||||
self.appid = config['appid']
|
||||
self.secret = config['secret']
|
||||
self.appid = config["appid"]
|
||||
self.secret = config["secret"]
|
||||
self.port = config.get("port", 6196)
|
||||
|
||||
|
||||
if isinstance(self.port, str):
|
||||
self.port = int(self.port)
|
||||
|
||||
|
||||
self.http: BotHttp = BotHttp(timeout=300)
|
||||
self.api: BotAPI = BotAPI(http=self.http)
|
||||
self.token = Token(self.appid, self.secret)
|
||||
|
||||
|
||||
self.server = quart.Quart(__name__)
|
||||
self.server.add_url_rule('/astrbot-qo-webhook/callback', view_func=self.callback, methods=['POST'])
|
||||
self.server.add_url_rule(
|
||||
"/astrbot-qo-webhook/callback", view_func=self.callback, methods=["POST"]
|
||||
)
|
||||
self.client = botpy_client
|
||||
self.event_queue = event_queue
|
||||
|
||||
|
||||
async def initialize(self):
|
||||
logger.info(f"正在登录到 QQ 官方机器人...")
|
||||
logger.info("正在登录到 QQ 官方机器人...")
|
||||
self.user = await self.http.login(self.token)
|
||||
logger.info(f"已登录 QQ 官方机器人账号: {self.user}")
|
||||
# 直接注入到 botpy 的 Client,移花接木!
|
||||
self.client.api = self.api
|
||||
self.client.http = self.http
|
||||
|
||||
|
||||
async def bot_connect():
|
||||
pass
|
||||
|
||||
|
||||
self._connection = ConnectionSession(
|
||||
max_async=1,
|
||||
connect=bot_connect,
|
||||
@@ -54,21 +53,22 @@ class QQOfficialWebhook():
|
||||
seed = bot_secret
|
||||
while len(seed) < target_size:
|
||||
seed *= 2
|
||||
return seed[:target_size].encode('utf-8')
|
||||
return seed[:target_size].encode("utf-8")
|
||||
|
||||
|
||||
async def webhook_validation(self, validation_payload: dict):
|
||||
seed = await self.repeat_seed(self.secret)
|
||||
private_key = ed25519.Ed25519PrivateKey.from_private_bytes(seed)
|
||||
msg = validation_payload.get("event_ts", "") + validation_payload.get("plain_token", "")
|
||||
msg = validation_payload.get("event_ts", "") + validation_payload.get(
|
||||
"plain_token", ""
|
||||
)
|
||||
# sign
|
||||
signature = private_key.sign(msg.encode()).hex()
|
||||
response = {
|
||||
"plain_token": validation_payload.get("plain_token"),
|
||||
"signature": signature
|
||||
"signature": signature,
|
||||
}
|
||||
return response
|
||||
|
||||
|
||||
async def callback(self):
|
||||
msg: dict = await quart.request.json
|
||||
logger.debug(f"收到 qq_official_webhook 回调: {msg}")
|
||||
@@ -76,7 +76,7 @@ class QQOfficialWebhook():
|
||||
event = msg.get("t")
|
||||
opcode = msg.get("op")
|
||||
data = msg.get("d")
|
||||
|
||||
|
||||
if opcode == 13:
|
||||
# validation
|
||||
signed = await self.webhook_validation(data)
|
||||
@@ -91,18 +91,17 @@ class QQOfficialWebhook():
|
||||
logger.error("_parser unknown event %s.", event)
|
||||
else:
|
||||
func(msg)
|
||||
|
||||
|
||||
return {"opcode": 12}
|
||||
|
||||
|
||||
async def start_polling(self):
|
||||
await self.server.run_task(
|
||||
host='0.0.0.0',
|
||||
port=self.port,
|
||||
shutdown_trigger=self.shutdown_trigger_placeholder
|
||||
host="0.0.0.0",
|
||||
port=self.port,
|
||||
shutdown_trigger=self.shutdown_trigger_placeholder,
|
||||
)
|
||||
|
||||
|
||||
async def shutdown_trigger_placeholder(self):
|
||||
while not self.event_queue.closed:
|
||||
while not self.event_queue.closed: # noqa: ASYNC110
|
||||
await asyncio.sleep(1)
|
||||
logger.info("qq_official_webhook 适配器已关闭。")
|
||||
|
||||
172
astrbot/core/platform/sources/telegram/tg_adapter.py
Normal file
172
astrbot/core/platform/sources/telegram/tg_adapter.py
Normal file
@@ -0,0 +1,172 @@
|
||||
import sys
|
||||
import uuid
|
||||
import asyncio
|
||||
|
||||
from astrbot.api.platform import (
|
||||
Platform,
|
||||
AstrBotMessage,
|
||||
MessageMember,
|
||||
PlatformMetadata,
|
||||
MessageType,
|
||||
)
|
||||
from astrbot.api.event import MessageChain
|
||||
from astrbot.api.message_components import (
|
||||
Plain,
|
||||
Image,
|
||||
Record,
|
||||
File as AstrBotFile,
|
||||
Video,
|
||||
At,
|
||||
)
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from astrbot.api.platform import register_platform_adapter
|
||||
|
||||
from telegram import Update
|
||||
from telegram.ext import ApplicationBuilder, ContextTypes, filters
|
||||
from telegram.constants import ChatType
|
||||
from telegram.ext import MessageHandler as TelegramMessageHandler
|
||||
from .tg_event import TelegramPlatformEvent
|
||||
from astrbot.api import logger
|
||||
from telegram.ext import ExtBot
|
||||
|
||||
if sys.version_info >= (3, 12):
|
||||
from typing import override
|
||||
else:
|
||||
from typing_extensions import override
|
||||
|
||||
|
||||
@register_platform_adapter("telegram", "telegram 适配器")
|
||||
class TelegramPlatformAdapter(Platform):
|
||||
def __init__(
|
||||
self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue
|
||||
) -> None:
|
||||
super().__init__(event_queue)
|
||||
self.config = platform_config
|
||||
self.settings = platform_settings
|
||||
self.client_self_id = uuid.uuid4().hex[:8]
|
||||
|
||||
base_url = self.config.get(
|
||||
"telegram_api_base_url", "https://api.telegram.org/bot"
|
||||
)
|
||||
if not base_url:
|
||||
base_url = "https://api.telegram.org/bot"
|
||||
self.application = (
|
||||
ApplicationBuilder()
|
||||
.token(self.config["telegram_token"])
|
||||
.base_url(base_url)
|
||||
.build()
|
||||
)
|
||||
message_handler = TelegramMessageHandler(
|
||||
filters=filters.ALL, # receive all messages
|
||||
callback=self.convert_message,
|
||||
)
|
||||
self.application.add_handler(message_handler)
|
||||
self.client = self.application.bot
|
||||
|
||||
@override
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
):
|
||||
from_username = session.session_id
|
||||
await TelegramPlatformEvent.send_with_client(
|
||||
self.client, message_chain, from_username
|
||||
)
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
@override
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
"telegram",
|
||||
"telegram 适配器",
|
||||
)
|
||||
|
||||
@override
|
||||
async def run(self):
|
||||
await self.application.initialize()
|
||||
await self.application.start()
|
||||
queue = self.application.updater.start_polling()
|
||||
logger.info("Telegram Platform Adapter is running.")
|
||||
await queue
|
||||
|
||||
async def start(self, update: Update, context: ContextTypes.DEFAULT_TYPE):
|
||||
await context.bot.send_message(
|
||||
chat_id=update.effective_chat.id, text=self.config["start_message"]
|
||||
)
|
||||
|
||||
async def convert_message(
|
||||
self, update: Update, context: ContextTypes.DEFAULT_TYPE
|
||||
) -> AstrBotMessage:
|
||||
message = AstrBotMessage()
|
||||
# 获得是群聊还是私聊
|
||||
if update.effective_chat.type == ChatType.PRIVATE:
|
||||
message.type = MessageType.FRIEND_MESSAGE
|
||||
else:
|
||||
message.type = MessageType.GROUP_MESSAGE
|
||||
message.group_id = update.effective_chat.id
|
||||
message.message_id = str(update.message.message_id)
|
||||
message.session_id = str(update.effective_chat.id)
|
||||
message.sender = MessageMember(
|
||||
str(update.effective_user.id), update.effective_user.username
|
||||
)
|
||||
message.self_id = str(context.bot.username)
|
||||
message.raw_message = update
|
||||
message.message_str = ""
|
||||
message.message = []
|
||||
|
||||
logger.debug(f"Telegram message: {update.message}")
|
||||
|
||||
if update.message.text:
|
||||
plain_text = update.message.text
|
||||
|
||||
if update.message.entities:
|
||||
for entity in update.message.entities:
|
||||
if entity.type == "mention":
|
||||
name = plain_text[entity.offset+1 : entity.offset + entity.length]
|
||||
message.message.append(At(qq=name, name=name))
|
||||
plain_text = (
|
||||
plain_text[: entity.offset]
|
||||
+ plain_text[entity.offset + entity.length :]
|
||||
)
|
||||
|
||||
message.message.append(Plain(plain_text))
|
||||
message.message_str = plain_text
|
||||
|
||||
elif update.message.voice:
|
||||
file = await update.message.voice.get_file()
|
||||
message.message = [
|
||||
Record(file=file.file_path, url=file.file_path),
|
||||
]
|
||||
|
||||
elif update.message.photo:
|
||||
photo = update.message.photo[-1] # get the largest photo
|
||||
file = await photo.get_file()
|
||||
message.message.append(Image(file=file.file_path, url=file.file_path))
|
||||
|
||||
elif update.message.document:
|
||||
file = await update.message.document.get_file()
|
||||
message.message = [
|
||||
AstrBotFile(
|
||||
file=file.file_path, name=update.message.document.file_name
|
||||
),
|
||||
]
|
||||
|
||||
elif update.message.video:
|
||||
file = await update.message.video.get_file()
|
||||
message.message = [
|
||||
Video(file=file.file_path, path=file.file_path),
|
||||
]
|
||||
|
||||
await self.handle_msg(message)
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
message_event = TelegramPlatformEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id,
|
||||
client=self.client,
|
||||
)
|
||||
self.commit_event(message_event)
|
||||
|
||||
def get_client(self) -> ExtBot:
|
||||
return self.client
|
||||
70
astrbot/core/platform/sources/telegram/tg_event.py
Normal file
70
astrbot/core/platform/sources/telegram/tg_event.py
Normal file
@@ -0,0 +1,70 @@
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.platform import AstrBotMessage, PlatformMetadata, MessageType
|
||||
from astrbot.api.message_components import Plain, Image, Reply, At, File, Record
|
||||
from telegram.ext import ExtBot
|
||||
|
||||
|
||||
class TelegramPlatformEvent(AstrMessageEvent):
|
||||
def __init__(
|
||||
self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,
|
||||
client: ExtBot,
|
||||
):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.client = client
|
||||
|
||||
@staticmethod
|
||||
async def send_with_client(client: ExtBot, message: MessageChain, user_name: str):
|
||||
image_path = None
|
||||
|
||||
has_reply = False
|
||||
reply_message_id = None
|
||||
at_user_id = None
|
||||
for i in message.chain:
|
||||
if isinstance(i, Reply):
|
||||
has_reply = True
|
||||
reply_message_id = i.id
|
||||
if isinstance(i, At):
|
||||
at_user_id = i.name
|
||||
|
||||
at_flag = False
|
||||
for i in message.chain:
|
||||
payload = {
|
||||
"chat_id": user_name,
|
||||
}
|
||||
if has_reply:
|
||||
payload["reply_to_message_id"] = reply_message_id
|
||||
|
||||
if isinstance(i, Plain):
|
||||
if at_user_id and not at_flag:
|
||||
i.text = f"@{at_user_id} " + i.text
|
||||
at_flag = True
|
||||
await client.send_message(text=i.text, **payload)
|
||||
elif isinstance(i, Image):
|
||||
if i.path:
|
||||
image_path = i.path
|
||||
else:
|
||||
image_path = i.file
|
||||
|
||||
if image_path.startswith("base64://"):
|
||||
import base64
|
||||
|
||||
base64_data = image_path[9:]
|
||||
image_bytes = base64.b64decode(base64_data)
|
||||
await client.send_photo(photo=image_bytes, **payload)
|
||||
else:
|
||||
await client.send_photo(photo=image_path, **payload)
|
||||
elif isinstance(i, File):
|
||||
await client.send_document(document=i.file, filename=i.name, **payload)
|
||||
elif isinstance(i, Record):
|
||||
await client.send_voice(voice=i.file, **payload)
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
if self.get_message_type() == MessageType.GROUP_MESSAGE:
|
||||
await self.send_with_client(self.client, message, self.message_obj.group_id)
|
||||
else:
|
||||
await self.send_with_client(self.client, message, self.get_sender_id())
|
||||
await super().send(message)
|
||||
@@ -3,41 +3,53 @@ import asyncio
|
||||
import uuid
|
||||
import os
|
||||
from typing import Awaitable, Any
|
||||
from astrbot.api.platform import Platform, AstrBotMessage, MessageMember, MessageType, PlatformMetadata
|
||||
from astrbot.api.event import MessageChain
|
||||
from astrbot.api.message_components import Plain, Image, Record # noqa: F403
|
||||
from astrbot.api import logger
|
||||
from astrbot.core.platform import (
|
||||
Platform,
|
||||
AstrBotMessage,
|
||||
MessageMember,
|
||||
MessageType,
|
||||
PlatformMetadata,
|
||||
)
|
||||
from astrbot.core.message.message_event_result import MessageChain
|
||||
from astrbot.core.message.components import Plain, Image, Record # noqa: F403
|
||||
from astrbot import logger
|
||||
from astrbot.core import web_chat_queue, web_chat_back_queue
|
||||
from .webchat_event import WebChatMessageEvent
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from ...register import register_platform_adapter
|
||||
|
||||
|
||||
class QueueListener:
|
||||
def __init__(self, queue: asyncio.Queue, callback: callable) -> None:
|
||||
self.queue = queue
|
||||
self.callback = callback
|
||||
|
||||
|
||||
async def run(self):
|
||||
while True:
|
||||
data = await self.queue.get()
|
||||
await self.callback(data)
|
||||
|
||||
|
||||
@register_platform_adapter("webchat", "webchat")
|
||||
class WebChatAdapter(Platform):
|
||||
def __init__(self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue) -> None:
|
||||
def __init__(
|
||||
self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue
|
||||
) -> None:
|
||||
super().__init__(event_queue)
|
||||
|
||||
|
||||
self.config = platform_config
|
||||
self.settings = platform_settings
|
||||
self.unique_session = platform_settings['unique_session']
|
||||
self.unique_session = platform_settings["unique_session"]
|
||||
self.imgs_dir = "data/webchat/imgs"
|
||||
|
||||
self.metadata = PlatformMetadata(
|
||||
"webchat",
|
||||
"webchat",
|
||||
)
|
||||
|
||||
async def send_by_session(self, session: MessageSesion, message_chain: MessageChain):
|
||||
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
):
|
||||
# abm.session_id = f"webchat!{username}!{cid}"
|
||||
plain = ""
|
||||
cid = session.session_id.split("!")[-1]
|
||||
@@ -45,68 +57,72 @@ class WebChatAdapter(Platform):
|
||||
if isinstance(comp, Plain):
|
||||
plain += comp.text
|
||||
web_chat_back_queue.put_nowait((plain, cid))
|
||||
|
||||
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
|
||||
async def convert_message(self, data: tuple) -> AstrBotMessage:
|
||||
username, cid, payload = data
|
||||
|
||||
|
||||
|
||||
abm = AstrBotMessage()
|
||||
abm.self_id = "webchat"
|
||||
abm.tag = "webchat"
|
||||
abm.sender = MessageMember(username, username)
|
||||
abm.sender = MessageMember(username, username)
|
||||
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
|
||||
|
||||
abm.session_id = f"webchat!{username}!{cid}"
|
||||
|
||||
|
||||
abm.message_id = str(uuid.uuid4())
|
||||
abm.message = []
|
||||
|
||||
if payload['message']:
|
||||
abm.message.append(Plain(payload['message']))
|
||||
if payload['image_url']:
|
||||
if isinstance(payload['image_url'], list):
|
||||
for img in payload['image_url']:
|
||||
abm.message.append(Image.fromFileSystem(os.path.join(self.imgs_dir, img)))
|
||||
|
||||
if payload["message"]:
|
||||
abm.message.append(Plain(payload["message"]))
|
||||
if payload["image_url"]:
|
||||
if isinstance(payload["image_url"], list):
|
||||
for img in payload["image_url"]:
|
||||
abm.message.append(
|
||||
Image.fromFileSystem(os.path.join(self.imgs_dir, img))
|
||||
)
|
||||
else:
|
||||
abm.message.append(Image.fromFileSystem(os.path.join(self.imgs_dir, payload['image_url'])))
|
||||
if payload['audio_url']:
|
||||
if isinstance(payload['audio_url'], list):
|
||||
for audio in payload['audio_url']:
|
||||
abm.message.append(
|
||||
Image.fromFileSystem(
|
||||
os.path.join(self.imgs_dir, payload["image_url"])
|
||||
)
|
||||
)
|
||||
if payload["audio_url"]:
|
||||
if isinstance(payload["audio_url"], list):
|
||||
for audio in payload["audio_url"]:
|
||||
path = os.path.join(self.imgs_dir, audio)
|
||||
abm.message.append(Record(file=path, path=path))
|
||||
else:
|
||||
path = os.path.join(self.imgs_dir, payload['audio_url'])
|
||||
path = os.path.join(self.imgs_dir, payload["audio_url"])
|
||||
abm.message.append(Record(file=path, path=path))
|
||||
|
||||
|
||||
logger.debug(f"WebChatAdapter: {abm.message}")
|
||||
|
||||
message_str = payload['message']
|
||||
|
||||
message_str = payload["message"]
|
||||
abm.timestamp = int(time.time())
|
||||
abm.message_str = message_str
|
||||
abm.raw_message = data
|
||||
return abm
|
||||
|
||||
|
||||
def run(self) -> Awaitable[Any]:
|
||||
async def callback(data: tuple):
|
||||
abm = await self.convert_message(data)
|
||||
await self.handle_msg(abm)
|
||||
|
||||
|
||||
bot = QueueListener(web_chat_queue, callback)
|
||||
return bot.run()
|
||||
|
||||
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return self.metadata
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
|
||||
message_event = WebChatMessageEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id
|
||||
session_id=message.session_id,
|
||||
)
|
||||
|
||||
self.commit_event(message_event)
|
||||
|
||||
self.commit_event(message_event)
|
||||
|
||||
@@ -1,24 +1,26 @@
|
||||
import os
|
||||
import uuid
|
||||
import base64
|
||||
from astrbot.api import logger
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.message_components import Plain, Image
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
from astrbot.core import web_chat_back_queue
|
||||
|
||||
|
||||
class WebChatMessageEvent(AstrMessageEvent):
|
||||
def __init__(self, message_str, message_obj, platform_meta, session_id):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.imgs_dir = "data/webchat/imgs"
|
||||
os.makedirs(self.imgs_dir, exist_ok=True)
|
||||
os.makedirs(self.imgs_dir, exist_ok=True)
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
if not message:
|
||||
web_chat_back_queue.put_nowait(None)
|
||||
return
|
||||
|
||||
|
||||
cid = self.session_id.split("!")[-1]
|
||||
|
||||
|
||||
for comp in message.chain:
|
||||
if isinstance(comp, Plain):
|
||||
web_chat_back_queue.put_nowait((comp.text, cid))
|
||||
@@ -31,6 +33,11 @@ class WebChatMessageEvent(AstrMessageEvent):
|
||||
with open(path, "wb") as f:
|
||||
with open(ph, "rb") as f2:
|
||||
f.write(f2.read())
|
||||
elif comp.file.startswith("base64://"):
|
||||
base64_str = comp.file[9:]
|
||||
image_data = base64.b64decode(base64_str)
|
||||
with open(path, "wb") as f:
|
||||
f.write(image_data)
|
||||
elif comp.file and comp.file.startswith("http"):
|
||||
await download_image_by_url(comp.file, path=path)
|
||||
else:
|
||||
@@ -39,6 +46,6 @@ class WebChatMessageEvent(AstrMessageEvent):
|
||||
f.write(f2.read())
|
||||
web_chat_back_queue.put_nowait((f"[IMAGE]{filename}", cid))
|
||||
else:
|
||||
logger.error(f"webchat 暂不支持发送消息类型: {comp.type}")
|
||||
logger.debug(f"webchat 忽略: {comp.type}")
|
||||
web_chat_back_queue.put_nowait(None)
|
||||
await super().send(message)
|
||||
await super().send(message)
|
||||
|
||||
234
astrbot/core/platform/sources/wecom/wecom_adapter.py
Normal file
234
astrbot/core/platform/sources/wecom/wecom_adapter.py
Normal file
@@ -0,0 +1,234 @@
|
||||
import sys
|
||||
import uuid
|
||||
import asyncio
|
||||
import quart
|
||||
|
||||
from astrbot.api.platform import (
|
||||
Platform,
|
||||
AstrBotMessage,
|
||||
MessageMember,
|
||||
PlatformMetadata,
|
||||
MessageType,
|
||||
)
|
||||
from astrbot.api.event import MessageChain
|
||||
from astrbot.api.message_components import Plain, Image, Record
|
||||
from astrbot.core.platform.astr_message_event import MessageSesion
|
||||
from astrbot.api.platform import register_platform_adapter
|
||||
from astrbot.core import logger
|
||||
from requests import Response
|
||||
|
||||
from wechatpy.enterprise.crypto import WeChatCrypto
|
||||
from wechatpy.enterprise import WeChatClient
|
||||
from wechatpy.enterprise.messages import TextMessage, ImageMessage, VoiceMessage
|
||||
from wechatpy.exceptions import InvalidSignatureException
|
||||
from wechatpy.enterprise import parse_message
|
||||
from .wecom_event import WecomPlatformEvent
|
||||
|
||||
if sys.version_info >= (3, 12):
|
||||
from typing import override
|
||||
else:
|
||||
from typing_extensions import override
|
||||
|
||||
|
||||
class WecomServer:
|
||||
def __init__(self, event_queue: asyncio.Queue, config: dict):
|
||||
self.server = quart.Quart(__name__)
|
||||
self.port = int(config.get("port"))
|
||||
self.server.add_url_rule(
|
||||
"/callback/command", view_func=self.verify, methods=["GET"]
|
||||
)
|
||||
self.server.add_url_rule(
|
||||
"/callback/command", view_func=self.callback_command, methods=["POST"]
|
||||
)
|
||||
self.event_queue = event_queue
|
||||
|
||||
self.crypto = WeChatCrypto(
|
||||
config["token"].strip(),
|
||||
config["encoding_aes_key"].strip(),
|
||||
config["corpid"].strip(),
|
||||
)
|
||||
|
||||
self.callback = None
|
||||
|
||||
async def verify(self):
|
||||
logger.info(f"验证请求有效性: {quart.request.args}")
|
||||
args = quart.request.args
|
||||
try:
|
||||
echo_str = self.crypto.check_signature(
|
||||
args.get("msg_signature"),
|
||||
args.get("timestamp"),
|
||||
args.get("nonce"),
|
||||
args.get("echostr"),
|
||||
)
|
||||
logger.info("验证请求有效性成功。")
|
||||
return echo_str
|
||||
except InvalidSignatureException:
|
||||
logger.error("验证请求有效性失败,签名异常,请检查配置。")
|
||||
raise
|
||||
|
||||
async def callback_command(self):
|
||||
data = await quart.request.get_data()
|
||||
msg_signature = quart.request.args.get("msg_signature")
|
||||
timestamp = quart.request.args.get("timestamp")
|
||||
nonce = quart.request.args.get("nonce")
|
||||
try:
|
||||
xml = self.crypto.decrypt_message(data, msg_signature, timestamp, nonce)
|
||||
except InvalidSignatureException:
|
||||
logger.error("解密失败,签名异常,请检查配置。")
|
||||
raise
|
||||
else:
|
||||
msg = parse_message(xml)
|
||||
logger.info(f"解析成功: {msg}")
|
||||
|
||||
if self.callback:
|
||||
await self.callback(msg)
|
||||
|
||||
return "success"
|
||||
|
||||
async def start_polling(self):
|
||||
logger.info(f"将在 0.0.0.0:{self.port} 端口启动 企业微信 适配器。")
|
||||
await self.server.run_task(
|
||||
host="0.0.0.0",
|
||||
port=self.port,
|
||||
shutdown_trigger=self.shutdown_trigger_placeholder,
|
||||
)
|
||||
|
||||
async def shutdown_trigger_placeholder(self):
|
||||
while not self.event_queue.closed: # noqa: ASYNC110
|
||||
await asyncio.sleep(1)
|
||||
logger.info("企业微信 适配器已关闭。")
|
||||
|
||||
|
||||
@register_platform_adapter("wecom", "wecom 适配器")
|
||||
class WecomPlatformAdapter(Platform):
|
||||
def __init__(
|
||||
self, platform_config: dict, platform_settings: dict, event_queue: asyncio.Queue
|
||||
) -> None:
|
||||
super().__init__(event_queue)
|
||||
self.config = platform_config
|
||||
self.settingss = platform_settings
|
||||
self.client_self_id = uuid.uuid4().hex[:8]
|
||||
self.api_base_url = platform_config.get(
|
||||
"api_base_url", "https://qyapi.weixin.qq.com/cgi-bin/"
|
||||
)
|
||||
|
||||
if not self.api_base_url:
|
||||
self.api_base_url = "https://qyapi.weixin.qq.com/cgi-bin/"
|
||||
|
||||
if self.api_base_url.endswith("/"):
|
||||
self.api_base_url = self.api_base_url[:-1]
|
||||
if not self.api_base_url.endswith("/cgi-bin"):
|
||||
self.api_base_url += "/cgi-bin"
|
||||
|
||||
if not self.api_base_url.endswith("/"):
|
||||
self.api_base_url += "/"
|
||||
|
||||
self.server = WecomServer(self._event_queue, self.config)
|
||||
|
||||
self.client = WeChatClient(
|
||||
self.config["corpid"].strip(),
|
||||
self.config["secret"].strip(),
|
||||
)
|
||||
self.client.API_BASE_URL = self.api_base_url
|
||||
|
||||
async def callback(msg):
|
||||
await self.convert_message(msg)
|
||||
|
||||
self.server.callback = callback
|
||||
|
||||
@override
|
||||
async def send_by_session(
|
||||
self, session: MessageSesion, message_chain: MessageChain
|
||||
):
|
||||
await super().send_by_session(session, message_chain)
|
||||
|
||||
@override
|
||||
def meta(self) -> PlatformMetadata:
|
||||
return PlatformMetadata(
|
||||
"wecom",
|
||||
"wecom 适配器",
|
||||
)
|
||||
|
||||
@override
|
||||
async def run(self):
|
||||
await self.server.start_polling()
|
||||
|
||||
async def convert_message(self, msg):
|
||||
abm = AstrBotMessage()
|
||||
if msg.type == "text":
|
||||
assert isinstance(msg, TextMessage)
|
||||
abm.message_str = msg.content
|
||||
abm.self_id = str(msg.agent)
|
||||
abm.message = [Plain(msg.content)]
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
abm.sender = MessageMember(
|
||||
msg.source,
|
||||
msg.source,
|
||||
)
|
||||
abm.message_id = msg.id
|
||||
abm.timestamp = msg.time
|
||||
abm.session_id = abm.sender.user_id
|
||||
abm.raw_message = msg
|
||||
elif msg.type == "image":
|
||||
assert isinstance(msg, ImageMessage)
|
||||
abm.message_str = "[图片]"
|
||||
abm.self_id = str(msg.agent)
|
||||
abm.message = [Image(file=msg.image, url=msg.image)]
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
abm.sender = MessageMember(
|
||||
msg.source,
|
||||
msg.source,
|
||||
)
|
||||
abm.message_id = msg.id
|
||||
abm.timestamp = msg.time
|
||||
abm.session_id = abm.sender.user_id
|
||||
abm.raw_message = msg
|
||||
elif msg.type == "voice":
|
||||
assert isinstance(msg, VoiceMessage)
|
||||
|
||||
resp: Response = await asyncio.get_event_loop().run_in_executor(
|
||||
None, self.client.media.download, msg.media_id
|
||||
)
|
||||
path = f"data/temp/wecom_{msg.media_id}.amr"
|
||||
with open(path, "wb") as f:
|
||||
f.write(resp.content)
|
||||
|
||||
try:
|
||||
from pydub import AudioSegment
|
||||
|
||||
path_wav = f"data/temp/wecom_{msg.media_id}.wav"
|
||||
audio = AudioSegment.from_file(path)
|
||||
audio.export(path_wav, format="wav")
|
||||
except Exception as e:
|
||||
logger.error(f"转换音频失败: {e}。如果没有安装 ffmpeg 请先安装。")
|
||||
path_wav = path
|
||||
return
|
||||
|
||||
abm.message_str = ""
|
||||
abm.self_id = str(msg.agent)
|
||||
abm.message = [Record(file=path_wav, url=path_wav)]
|
||||
abm.type = MessageType.FRIEND_MESSAGE
|
||||
abm.sender = MessageMember(
|
||||
msg.source,
|
||||
msg.source,
|
||||
)
|
||||
abm.message_id = msg.id
|
||||
abm.timestamp = msg.time
|
||||
abm.session_id = abm.sender.user_id
|
||||
abm.raw_message = msg
|
||||
|
||||
logger.info(f"abm: {abm}")
|
||||
await self.handle_msg(abm)
|
||||
|
||||
async def handle_msg(self, message: AstrBotMessage):
|
||||
message_event = WecomPlatformEvent(
|
||||
message_str=message.message_str,
|
||||
message_obj=message,
|
||||
platform_meta=self.meta(),
|
||||
session_id=message.session_id,
|
||||
client=self.client,
|
||||
)
|
||||
self.commit_event(message_event)
|
||||
|
||||
def get_client(self) -> WeChatClient:
|
||||
return self.client
|
||||
103
astrbot/core/platform/sources/wecom/wecom_event.py
Normal file
103
astrbot/core/platform/sources/wecom/wecom_event.py
Normal file
@@ -0,0 +1,103 @@
|
||||
import uuid
|
||||
from astrbot.api.event import AstrMessageEvent, MessageChain
|
||||
from astrbot.api.platform import AstrBotMessage, PlatformMetadata
|
||||
from astrbot.api.message_components import Plain, Image, Record
|
||||
from wechatpy.enterprise import WeChatClient
|
||||
from astrbot.core.utils.io import download_image_by_url, download_file
|
||||
|
||||
from astrbot.api import logger
|
||||
|
||||
try:
|
||||
import pydub
|
||||
except Exception:
|
||||
logger.warning(
|
||||
"检测到 pydub 库未安装,企业微信将无法语音收发。如需使用语音,请前往管理面板 -> 控制台 -> 安装 Pip 库安装 pydub。"
|
||||
)
|
||||
pass
|
||||
|
||||
|
||||
class WecomPlatformEvent(AstrMessageEvent):
|
||||
def __init__(
|
||||
self,
|
||||
message_str: str,
|
||||
message_obj: AstrBotMessage,
|
||||
platform_meta: PlatformMetadata,
|
||||
session_id: str,
|
||||
client: WeChatClient,
|
||||
):
|
||||
super().__init__(message_str, message_obj, platform_meta, session_id)
|
||||
self.client = client
|
||||
|
||||
@staticmethod
|
||||
async def send_with_client(
|
||||
client: WeChatClient, message: MessageChain, user_name: str
|
||||
):
|
||||
pass
|
||||
|
||||
async def send(self, message: MessageChain):
|
||||
message_obj = self.message_obj
|
||||
|
||||
for comp in message.chain:
|
||||
if isinstance(comp, Plain):
|
||||
self.client.message.send_text(
|
||||
message_obj.self_id, message_obj.session_id, comp.text
|
||||
)
|
||||
elif isinstance(comp, Image):
|
||||
img_url = comp.file
|
||||
img_path = ""
|
||||
if img_url.startswith("file:///"):
|
||||
img_path = img_url[8:]
|
||||
elif comp.file and comp.file.startswith("http"):
|
||||
img_path = await download_image_by_url(comp.file)
|
||||
else:
|
||||
img_path = img_url
|
||||
|
||||
with open(img_path, "rb") as f:
|
||||
try:
|
||||
response = self.client.media.upload("image", f)
|
||||
except Exception as e:
|
||||
logger.error(f"企业微信上传图片失败: {e}")
|
||||
await self.send(
|
||||
MessageChain().message(f"企业微信上传图片失败: {e}")
|
||||
)
|
||||
return
|
||||
logger.info(f"企业微信上传图片返回: {response}")
|
||||
self.client.message.send_image(
|
||||
message_obj.self_id,
|
||||
message_obj.session_id,
|
||||
response["media_id"],
|
||||
)
|
||||
elif isinstance(comp, Record):
|
||||
record_url = comp.file
|
||||
record_path = ""
|
||||
|
||||
if record_url.startswith("file:///"):
|
||||
record_path = record_url[8:]
|
||||
elif record_url.startswith("http"):
|
||||
await download_file(record_url, f"data/temp/{uuid.uuid4()}.wav")
|
||||
else:
|
||||
record_path = record_url
|
||||
|
||||
# 转成amr
|
||||
record_path_amr = f"data/temp/{uuid.uuid4()}.amr"
|
||||
pydub.AudioSegment.from_wav(record_path).export(
|
||||
record_path_amr, format="amr"
|
||||
)
|
||||
|
||||
with open(record_path_amr, "rb") as f:
|
||||
try:
|
||||
response = self.client.media.upload("voice", f)
|
||||
except Exception as e:
|
||||
logger.error(f"企业微信上传语音失败: {e}")
|
||||
await self.send(
|
||||
MessageChain().message(f"企业微信上传语音失败: {e}")
|
||||
)
|
||||
return
|
||||
logger.info(f"企业微信上传语音返回: {response}")
|
||||
self.client.message.send_voice(
|
||||
message_obj.self_id,
|
||||
message_obj.session_id,
|
||||
response["media_id"],
|
||||
)
|
||||
|
||||
await super().send(message)
|
||||
@@ -2,9 +2,4 @@ from .provider import Provider, Personality, STTProvider
|
||||
|
||||
from .entites import ProviderMetaData
|
||||
|
||||
__all__ = [
|
||||
"Provider",
|
||||
"Personality",
|
||||
"ProviderMetaData",
|
||||
"STTProvider"
|
||||
]
|
||||
__all__ = ["Provider", "Personality", "ProviderMetaData", "STTProvider"]
|
||||
|
||||
@@ -10,55 +10,58 @@ class ProviderType(enum.Enum):
|
||||
CHAT_COMPLETION = "chat_completion"
|
||||
SPEECH_TO_TEXT = "speech_to_text"
|
||||
TEXT_TO_SPEECH = "text_to_speech"
|
||||
|
||||
@dataclass
|
||||
class ProviderMetaData():
|
||||
type: str
|
||||
'''提供商适配器名称,如 openai, ollama'''
|
||||
desc: str = ""
|
||||
'''提供商适配器描述.'''
|
||||
provider_type: ProviderType = ProviderType.CHAT_COMPLETION
|
||||
cls_type: Type = None
|
||||
|
||||
default_config_tmpl: dict = None
|
||||
'''平台的默认配置模板'''
|
||||
provider_display_name: str = None
|
||||
'''显示在 WebUI 配置页中的提供商名称,如空则是 type'''
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProviderRequest():
|
||||
class ProviderMetaData:
|
||||
type: str
|
||||
"""提供商适配器名称,如 openai, ollama"""
|
||||
desc: str = ""
|
||||
"""提供商适配器描述."""
|
||||
provider_type: ProviderType = ProviderType.CHAT_COMPLETION
|
||||
cls_type: Type = None
|
||||
|
||||
default_config_tmpl: dict = None
|
||||
"""平台的默认配置模板"""
|
||||
provider_display_name: str = None
|
||||
"""显示在 WebUI 配置页中的提供商名称,如空则是 type"""
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProviderRequest:
|
||||
prompt: str
|
||||
'''提示词'''
|
||||
"""提示词"""
|
||||
session_id: str = ""
|
||||
'''会话 ID'''
|
||||
"""会话 ID"""
|
||||
image_urls: List[str] = None
|
||||
'''图片 URL 列表'''
|
||||
"""图片 URL 列表"""
|
||||
func_tool: FuncCall = None
|
||||
'''工具'''
|
||||
"""工具"""
|
||||
contexts: List = None
|
||||
'''上下文。格式与 openai 的上下文格式一致:
|
||||
"""上下文。格式与 openai 的上下文格式一致:
|
||||
参考 https://platform.openai.com/docs/api-reference/chat/create#chat-create-messages
|
||||
'''
|
||||
"""
|
||||
system_prompt: str = ""
|
||||
'''系统提示词'''
|
||||
"""系统提示词"""
|
||||
conversation: Conversation = None
|
||||
|
||||
|
||||
def __repr__(self):
|
||||
return f"ProviderRequest(prompt={self.prompt}, session_id={self.session_id}, image_urls={self.image_urls}, func_tool={self.func_tool}, contexts={self.contexts}, system_prompt={self.system_prompt})"
|
||||
|
||||
|
||||
def __str__(self):
|
||||
return self.__repr__()
|
||||
|
||||
|
||||
|
||||
@dataclass
|
||||
class LLMResponse:
|
||||
role: str
|
||||
'''角色, assistant, tool, err'''
|
||||
"""角色, assistant, tool, err"""
|
||||
completion_text: str = ""
|
||||
'''LLM 返回的文本'''
|
||||
"""LLM 返回的文本"""
|
||||
tools_call_args: List[Dict[str, any]] = field(default_factory=list)
|
||||
'''工具调用参数'''
|
||||
"""工具调用参数"""
|
||||
tools_call_name: List[str] = field(default_factory=list)
|
||||
'''工具调用名称'''
|
||||
|
||||
"""工具调用名称"""
|
||||
|
||||
raw_completion: ChatCompletion = None
|
||||
_new_record: Dict[str, any] = None
|
||||
_new_record: Dict[str, any] = None
|
||||
|
||||
@@ -14,10 +14,11 @@ class FuncTool:
|
||||
parameters: Dict
|
||||
description: str
|
||||
handler: Awaitable
|
||||
handler_module_path: str = None # 必须要保留这个,handler 在初始化会被 functools.partial 包装,导致 handler 的 __module__ 为 functools
|
||||
handler_module_path: str = None # 必须要保留这个,handler 在初始化会被 functools.partial 包装,导致 handler 的 __module__ 为 functools
|
||||
|
||||
active: bool = True
|
||||
'''是否激活'''
|
||||
"""是否激活"""
|
||||
|
||||
|
||||
SUPPORTED_TYPES = [
|
||||
"string",
|
||||
@@ -101,7 +102,30 @@ class FuncCall:
|
||||
}
|
||||
)
|
||||
return _l
|
||||
|
||||
|
||||
def get_func_desc_anthropic_style(self) -> list:
|
||||
"""
|
||||
获得 Anthropic API 风格的**已经激活**的工具描述
|
||||
"""
|
||||
tools = []
|
||||
for f in self.func_list:
|
||||
if not f.active:
|
||||
continue
|
||||
|
||||
# Convert internal format to Anthropic style
|
||||
tool = {
|
||||
"name": f.name,
|
||||
"description": f.description,
|
||||
"input_schema": {
|
||||
"type": "object",
|
||||
"properties": f.parameters.get("properties", {}),
|
||||
# Keep the required field from the original parameters if it exists
|
||||
"required": f.parameters.get("required", []),
|
||||
},
|
||||
}
|
||||
tools.append(tool)
|
||||
return tools
|
||||
|
||||
def get_func_desc_google_genai_style(self) -> Dict:
|
||||
declarations = {}
|
||||
tools = []
|
||||
@@ -109,10 +133,7 @@ class FuncCall:
|
||||
if not f.active:
|
||||
continue
|
||||
|
||||
func_declaration = {
|
||||
"name": f.name,
|
||||
"description": f.description
|
||||
}
|
||||
func_declaration = {"name": f.name, "description": f.description}
|
||||
|
||||
# 检查并添加非空的properties参数
|
||||
params = f.parameters if isinstance(f.parameters, dict) else {}
|
||||
@@ -124,7 +145,6 @@ class FuncCall:
|
||||
if tools:
|
||||
declarations["function_declarations"] = tools
|
||||
return declarations
|
||||
|
||||
|
||||
async def func_call(self, question: str, session_id: str, provider) -> tuple:
|
||||
_l = []
|
||||
@@ -197,9 +217,8 @@ class FuncCall:
|
||||
tool_call_result.append(str(ret))
|
||||
return tool_call_result, True
|
||||
|
||||
|
||||
def __str__(self):
|
||||
return str(self.func_list)
|
||||
|
||||
|
||||
def __repr__(self):
|
||||
return str(self.func_list)
|
||||
return str(self.func_list)
|
||||
|
||||
@@ -1,25 +1,34 @@
|
||||
import traceback
|
||||
import uuid
|
||||
from astrbot.core.config.astrbot_config import AstrBotConfig
|
||||
from .provider import Provider, STTProvider, TTSProvider, Personality
|
||||
from .entites import ProviderType
|
||||
from typing import List
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from collections import defaultdict
|
||||
from .register import provider_cls_map, llm_tools
|
||||
from astrbot.core import logger, sp
|
||||
|
||||
class ProviderManager():
|
||||
|
||||
class ProviderManager:
|
||||
def __init__(self, config: AstrBotConfig, db_helper: BaseDatabase):
|
||||
self.providers_config: List = config['provider']
|
||||
self.provider_settings: dict = config['provider_settings']
|
||||
self.provider_stt_settings: dict = config.get('provider_stt_settings', {})
|
||||
self.provider_tts_settings: dict = config.get('provider_tts_settings', {})
|
||||
self.persona_configs: list = config.get('persona', [])
|
||||
|
||||
self.providers_config: List = config["provider"]
|
||||
self.provider_settings: dict = config["provider_settings"]
|
||||
self.provider_stt_settings: dict = config.get("provider_stt_settings", {})
|
||||
self.provider_tts_settings: dict = config.get("provider_tts_settings", {})
|
||||
self.persona_configs: list = config.get("persona", [])
|
||||
self.astrbot_config = config
|
||||
|
||||
self.selected_provider_id = sp.get("curr_provider")
|
||||
self.selected_stt_provider_id = self.provider_stt_settings.get("provider_id")
|
||||
self.selected_tts_provider_id = self.provider_settings.get("provider_id")
|
||||
self.provider_enabled = self.provider_settings.get("enable", False)
|
||||
self.stt_enabled = self.provider_stt_settings.get("enable", False)
|
||||
self.tts_enabled = self.provider_tts_settings.get("enable", False)
|
||||
|
||||
# 人格情景管理
|
||||
# 目前没有拆成独立的模块
|
||||
self.default_persona_name = self.provider_settings.get('default_personality', 'default')
|
||||
self.default_persona_name = self.provider_settings.get(
|
||||
"default_personality", "default"
|
||||
)
|
||||
self.personas: List[Personality] = []
|
||||
self.selected_default_persona = None
|
||||
for persona in self.persona_configs:
|
||||
@@ -29,212 +38,305 @@ class ProviderManager():
|
||||
mid_processed = ""
|
||||
if begin_dialogs:
|
||||
if len(begin_dialogs) % 2 != 0:
|
||||
logger.error(f"{persona['name']} 人格情景预设对话格式不对,条数应该为偶数。")
|
||||
logger.error(
|
||||
f"{persona['name']} 人格情景预设对话格式不对,条数应该为偶数。"
|
||||
)
|
||||
begin_dialogs = []
|
||||
user_turn = True
|
||||
for dialog in begin_dialogs:
|
||||
bd_processed.append({
|
||||
"role": "user" if user_turn else "assistant",
|
||||
"content": dialog,
|
||||
"_no_save": None # 不持久化到 db
|
||||
})
|
||||
bd_processed.append(
|
||||
{
|
||||
"role": "user" if user_turn else "assistant",
|
||||
"content": dialog,
|
||||
"_no_save": None, # 不持久化到 db
|
||||
}
|
||||
)
|
||||
user_turn = not user_turn
|
||||
if mood_imitation_dialogs:
|
||||
if len(mood_imitation_dialogs) % 2 != 0:
|
||||
logger.error(f"{persona['name']} 对话风格对话格式不对,条数应该为偶数。")
|
||||
logger.error(
|
||||
f"{persona['name']} 对话风格对话格式不对,条数应该为偶数。"
|
||||
)
|
||||
mood_imitation_dialogs = []
|
||||
user_turn = True
|
||||
for dialog in mood_imitation_dialogs:
|
||||
role = "A" if user_turn else "B"
|
||||
mid_processed += f"{role}: {dialog}\n"
|
||||
if not user_turn:
|
||||
mid_processed += '\n'
|
||||
mid_processed += "\n"
|
||||
user_turn = not user_turn
|
||||
|
||||
|
||||
try:
|
||||
persona = Personality(
|
||||
**persona,
|
||||
**persona,
|
||||
_begin_dialogs_processed=bd_processed,
|
||||
_mood_imitation_dialogs_processed=mid_processed
|
||||
_mood_imitation_dialogs_processed=mid_processed,
|
||||
)
|
||||
if persona['name'] == self.default_persona_name:
|
||||
if persona["name"] == self.default_persona_name:
|
||||
self.selected_default_persona = persona
|
||||
self.personas.append(persona)
|
||||
except Exception as e:
|
||||
logger.error(f"解析 Persona 配置失败:{e}")
|
||||
|
||||
|
||||
if not self.selected_default_persona and len(self.personas) > 0:
|
||||
# 默认选择第一个
|
||||
self.selected_default_persona = self.personas[0]
|
||||
|
||||
|
||||
if not self.selected_default_persona:
|
||||
self.selected_default_persona = Personality(
|
||||
prompt="You are a helpful and friendly assistant.",
|
||||
name="default",
|
||||
_begin_dialogs_processed=[],
|
||||
_mood_imitation_dialogs_processed=""
|
||||
_mood_imitation_dialogs_processed="",
|
||||
)
|
||||
self.personas.append(self.selected_default_persona)
|
||||
|
||||
|
||||
|
||||
self.provider_insts: List[Provider] = []
|
||||
'''加载的 Provider 的实例'''
|
||||
"""加载的 Provider 的实例"""
|
||||
self.stt_provider_insts: List[STTProvider] = []
|
||||
'''加载的 Speech To Text Provider 的实例'''
|
||||
"""加载的 Speech To Text Provider 的实例"""
|
||||
self.tts_provider_insts: List[TTSProvider] = []
|
||||
'''加载的 Text To Speech Provider 的实例'''
|
||||
"""加载的 Text To Speech Provider 的实例"""
|
||||
self.inst_map = {}
|
||||
"""Provider 实例映射. key: provider_id, value: Provider 实例"""
|
||||
self.llm_tools = llm_tools
|
||||
self.curr_provider_inst: Provider = None
|
||||
'''当前使用的 Provider 实例'''
|
||||
"""当前使用的 Provider 实例"""
|
||||
self.curr_stt_provider_inst: STTProvider = None
|
||||
'''当前使用的 Speech To Text Provider 实例'''
|
||||
"""当前使用的 Speech To Text Provider 实例"""
|
||||
self.curr_tts_provider_inst: TTSProvider = None
|
||||
'''当前使用的 Text To Speech Provider 实例'''
|
||||
self.loaded_ids = defaultdict(bool)
|
||||
"""当前使用的 Text To Speech Provider 实例"""
|
||||
self.db_helper = db_helper
|
||||
|
||||
|
||||
# kdb(experimental)
|
||||
self.curr_kdb_name = ""
|
||||
kdb_cfg = config.get("knowledge_db", {})
|
||||
if kdb_cfg and len(kdb_cfg):
|
||||
self.curr_kdb_name = list(kdb_cfg.keys())[0]
|
||||
|
||||
changed = False
|
||||
for provider_cfg in self.providers_config:
|
||||
if not provider_cfg['enable']:
|
||||
continue
|
||||
|
||||
if provider_cfg['id'] in self.loaded_ids:
|
||||
new_id = f"{provider_cfg['id']}_{str(uuid.uuid4())[:8]}"
|
||||
logger.info(f"Provider ID 重复:{provider_cfg['id']}。已自动更改为 {new_id}。")
|
||||
provider_cfg['id'] = new_id
|
||||
changed = True
|
||||
self.loaded_ids[provider_cfg['id']] = True
|
||||
|
||||
try:
|
||||
match provider_cfg['type']:
|
||||
case "openai_chat_completion":
|
||||
from .sources.openai_source import ProviderOpenAIOfficial as ProviderOpenAIOfficial
|
||||
case "zhipu_chat_completion":
|
||||
from .sources.zhipu_source import ProviderZhipu as ProviderZhipu
|
||||
case "llm_tuner":
|
||||
logger.info("加载 LLM Tuner 工具 ...")
|
||||
from .sources.llmtuner_source import LLMTunerModelLoader as LLMTunerModelLoader
|
||||
case "dify":
|
||||
from .sources.dify_source import ProviderDify as ProviderDify
|
||||
case "googlegenai_chat_completion":
|
||||
from .sources.gemini_source import ProviderGoogleGenAI as ProviderGoogleGenAI
|
||||
case "openai_whisper_api":
|
||||
from .sources.whisper_api_source import ProviderOpenAIWhisperAPI as ProviderOpenAIWhisperAPI
|
||||
case "openai_whisper_selfhost":
|
||||
from .sources.whisper_selfhosted_source import ProviderOpenAIWhisperSelfHost as ProviderOpenAIWhisperSelfHost
|
||||
case "openai_tts_api":
|
||||
from .sources.openai_tts_api_source import ProviderOpenAITTSAPI as ProviderOpenAITTSAPI
|
||||
case "fishaudio_tts_api":
|
||||
from .sources.fishaudio_tts_api_source import ProviderFishAudioTTSAPI as ProviderFishAudioTTSAPI
|
||||
except (ImportError, ModuleNotFoundError) as e:
|
||||
logger.critical(f"加载 {provider_cfg['type']}({provider_cfg['id']}) 提供商适配器失败:{e}。可能是因为有未安装的依赖。")
|
||||
continue
|
||||
except Exception as e:
|
||||
logger.critical(f"加载 {provider_cfg['type']}({provider_cfg['id']}) 提供商适配器失败:{e}。未知原因")
|
||||
continue
|
||||
|
||||
if changed:
|
||||
try:
|
||||
config.save_config()
|
||||
except Exception as e:
|
||||
logger.warning(f"保存配置文件失败:{e}")
|
||||
|
||||
async def initialize(self):
|
||||
|
||||
selected_provider_id = sp.get("curr_provider")
|
||||
selected_stt_provider_id = self.provider_stt_settings.get("provider_id")
|
||||
selected_tts_provider_id = self.provider_settings.get("provider_id")
|
||||
provider_enabled = self.provider_settings.get("enable", False)
|
||||
stt_enabled = self.provider_stt_settings.get("enable", False)
|
||||
tts_enabled = self.provider_tts_settings.get("enable", False)
|
||||
|
||||
for provider_config in self.providers_config:
|
||||
if not provider_config['enable']:
|
||||
continue
|
||||
if provider_config['type'] not in provider_cls_map:
|
||||
logger.error(f"未找到适用于 {provider_config['type']}({provider_config['id']}) 的提供商适配器,请检查是否已经安装或者名称填写错误。已跳过。")
|
||||
continue
|
||||
await self.load_provider(provider_config)
|
||||
|
||||
provider_metadata = provider_cls_map[provider_config['type']]
|
||||
logger.debug(f"尝试实例化 {provider_config['type']}({provider_config['id']}) 提供商适配器 ...")
|
||||
try:
|
||||
# 按任务实例化提供商
|
||||
|
||||
if provider_metadata.provider_type == ProviderType.SPEECH_TO_TEXT:
|
||||
# STT 任务
|
||||
inst = provider_metadata.cls_type(provider_config, self.provider_settings)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.stt_provider_insts.append(inst)
|
||||
if selected_stt_provider_id == provider_config['id'] and stt_enabled:
|
||||
self.curr_stt_provider_inst = inst
|
||||
logger.info(f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前语音转文本提供商适配器。")
|
||||
|
||||
elif provider_metadata.provider_type == ProviderType.TEXT_TO_SPEECH:
|
||||
# TTS 任务
|
||||
inst = provider_metadata.cls_type(provider_config, self.provider_settings)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.tts_provider_insts.append(inst)
|
||||
if selected_tts_provider_id == provider_config['id'] and tts_enabled:
|
||||
self.curr_tts_provider_inst = inst
|
||||
logger.info(f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前文本转语音提供商适配器。")
|
||||
|
||||
elif provider_metadata.provider_type == ProviderType.CHAT_COMPLETION:
|
||||
# 文本生成任务
|
||||
inst = provider_metadata.cls_type(
|
||||
provider_config,
|
||||
self.provider_settings,
|
||||
self.db_helper,
|
||||
self.provider_settings.get('persistant_history', True),
|
||||
self.selected_default_persona
|
||||
)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.provider_insts.append(inst)
|
||||
if selected_provider_id == provider_config['id'] and provider_enabled:
|
||||
self.curr_provider_inst = inst
|
||||
logger.info(f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前提供商适配器。")
|
||||
|
||||
except Exception as e:
|
||||
traceback.print_exc()
|
||||
logger.error(f"实例化 {provider_config['type']}({provider_config['id']}) 提供商适配器失败:{e}")
|
||||
|
||||
if len(self.provider_insts) > 0 and not self.curr_provider_inst and provider_enabled:
|
||||
self.curr_provider_inst = self.provider_insts[0]
|
||||
|
||||
if len(self.stt_provider_insts) > 0 and not self.curr_stt_provider_inst and stt_enabled:
|
||||
self.curr_stt_provider_inst = self.stt_provider_insts[0]
|
||||
|
||||
if len(self.tts_provider_insts) > 0 and not self.curr_tts_provider_inst and tts_enabled:
|
||||
self.curr_tts_provider_inst = self.tts_provider_insts[0]
|
||||
|
||||
if not self.curr_provider_inst:
|
||||
logger.warning("未启用任何用于 文本生成 的提供商适配器。")
|
||||
|
||||
if stt_enabled and not self.curr_stt_provider_inst:
|
||||
logger.warning("未启用任何用于 语音转文本 的提供商适配器。")
|
||||
|
||||
if tts_enabled and not self.curr_tts_provider_inst:
|
||||
logger.warning("未启用任何用于 文本转语音 的提供商适配器。")
|
||||
|
||||
|
||||
if self.stt_enabled and not self.curr_stt_provider_inst:
|
||||
logger.warning("未启用任何用于 语音转文本 的提供商适配器。")
|
||||
|
||||
if self.tts_enabled and not self.curr_tts_provider_inst:
|
||||
logger.warning("未启用任何用于 文本转语音 的提供商适配器。")
|
||||
|
||||
async def load_provider(self, provider_config: dict):
|
||||
if not provider_config["enable"]:
|
||||
return
|
||||
|
||||
logger.info(
|
||||
f"载入 {provider_config['type']}({provider_config['id']}) 服务提供商适配器 ..."
|
||||
)
|
||||
logger.debug(f"Provider Config: {provider_config}")
|
||||
|
||||
# 动态导入
|
||||
try:
|
||||
match provider_config["type"]:
|
||||
case "openai_chat_completion":
|
||||
from .sources.openai_source import (
|
||||
ProviderOpenAIOfficial as ProviderOpenAIOfficial,
|
||||
)
|
||||
case "zhipu_chat_completion":
|
||||
from .sources.zhipu_source import ProviderZhipu as ProviderZhipu
|
||||
case "anthropic_chat_completion":
|
||||
from .sources.anthropic_source import (
|
||||
ProviderAnthropic as ProviderAnthropic,
|
||||
)
|
||||
case "llm_tuner":
|
||||
logger.info("加载 LLM Tuner 工具 ...")
|
||||
from .sources.llmtuner_source import (
|
||||
LLMTunerModelLoader as LLMTunerModelLoader,
|
||||
)
|
||||
case "dify":
|
||||
from .sources.dify_source import ProviderDify as ProviderDify
|
||||
case "dashscope":
|
||||
from .sources.dashscope_source import (
|
||||
ProviderDashscope as ProviderDashscope,
|
||||
)
|
||||
case "googlegenai_chat_completion":
|
||||
from .sources.gemini_source import (
|
||||
ProviderGoogleGenAI as ProviderGoogleGenAI,
|
||||
)
|
||||
case "sensevoice_stt_selfhost":
|
||||
from .sources.sensevoice_selfhosted_source import (
|
||||
ProviderSenseVoiceSTTSelfHost as ProviderSenseVoiceSTTSelfHost,
|
||||
)
|
||||
case "openai_whisper_api":
|
||||
from .sources.whisper_api_source import (
|
||||
ProviderOpenAIWhisperAPI as ProviderOpenAIWhisperAPI,
|
||||
)
|
||||
case "openai_whisper_selfhost":
|
||||
from .sources.whisper_selfhosted_source import (
|
||||
ProviderOpenAIWhisperSelfHost as ProviderOpenAIWhisperSelfHost,
|
||||
)
|
||||
case "openai_tts_api":
|
||||
from .sources.openai_tts_api_source import (
|
||||
ProviderOpenAITTSAPI as ProviderOpenAITTSAPI,
|
||||
)
|
||||
case "edge_tts":
|
||||
from .sources.edge_tts_source import (
|
||||
ProviderEdgeTTS as ProviderEdgeTTS,
|
||||
)
|
||||
case "gsvi_tts_api":
|
||||
from .sources.gsvi_tts_source import (
|
||||
ProviderGSVITTS as ProviderGSVITTS,
|
||||
)
|
||||
case "fishaudio_tts_api":
|
||||
from .sources.fishaudio_tts_api_source import (
|
||||
ProviderFishAudioTTSAPI as ProviderFishAudioTTSAPI,
|
||||
)
|
||||
except (ImportError, ModuleNotFoundError) as e:
|
||||
logger.critical(
|
||||
f"加载 {provider_config['type']}({provider_config['id']}) 提供商适配器失败:{e}。可能是因为有未安装的依赖。"
|
||||
)
|
||||
return
|
||||
except Exception as e:
|
||||
logger.critical(
|
||||
f"加载 {provider_config['type']}({provider_config['id']}) 提供商适配器失败:{e}。未知原因"
|
||||
)
|
||||
return
|
||||
|
||||
if provider_config["type"] not in provider_cls_map:
|
||||
logger.error(
|
||||
f"未找到适用于 {provider_config['type']}({provider_config['id']}) 的提供商适配器,请检查是否已经安装或者名称填写错误。已跳过。"
|
||||
)
|
||||
return
|
||||
|
||||
provider_metadata = provider_cls_map[provider_config["type"]]
|
||||
try:
|
||||
# 按任务实例化提供商
|
||||
|
||||
if provider_metadata.provider_type == ProviderType.SPEECH_TO_TEXT:
|
||||
# STT 任务
|
||||
inst = provider_metadata.cls_type(
|
||||
provider_config, self.provider_settings
|
||||
)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.stt_provider_insts.append(inst)
|
||||
if (
|
||||
self.selected_stt_provider_id == provider_config["id"]
|
||||
and self.stt_enabled
|
||||
):
|
||||
self.curr_stt_provider_inst = inst
|
||||
logger.info(
|
||||
f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前语音转文本提供商适配器。"
|
||||
)
|
||||
if not self.curr_stt_provider_inst and self.stt_enabled:
|
||||
self.curr_stt_provider_inst = inst
|
||||
|
||||
elif provider_metadata.provider_type == ProviderType.TEXT_TO_SPEECH:
|
||||
# TTS 任务
|
||||
inst = provider_metadata.cls_type(
|
||||
provider_config, self.provider_settings
|
||||
)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.tts_provider_insts.append(inst)
|
||||
if (
|
||||
self.selected_tts_provider_id == provider_config["id"]
|
||||
and self.tts_enabled
|
||||
):
|
||||
self.curr_tts_provider_inst = inst
|
||||
logger.info(
|
||||
f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前文本转语音提供商适配器。"
|
||||
)
|
||||
if not self.curr_tts_provider_inst and self.tts_enabled:
|
||||
self.curr_tts_provider_inst = inst
|
||||
|
||||
elif provider_metadata.provider_type == ProviderType.CHAT_COMPLETION:
|
||||
# 文本生成任务
|
||||
inst = provider_metadata.cls_type(
|
||||
provider_config,
|
||||
self.provider_settings,
|
||||
self.db_helper,
|
||||
self.provider_settings.get("persistant_history", True),
|
||||
self.selected_default_persona,
|
||||
)
|
||||
|
||||
if getattr(inst, "initialize", None):
|
||||
await inst.initialize()
|
||||
|
||||
self.provider_insts.append(inst)
|
||||
if (
|
||||
self.selected_provider_id == provider_config["id"]
|
||||
and self.provider_enabled
|
||||
):
|
||||
self.curr_provider_inst = inst
|
||||
logger.info(
|
||||
f"已选择 {provider_config['type']}({provider_config['id']}) 作为当前提供商适配器。"
|
||||
)
|
||||
if not self.curr_provider_inst and self.provider_enabled:
|
||||
self.curr_provider_inst = inst
|
||||
|
||||
self.inst_map[provider_config["id"]] = inst
|
||||
except Exception as e:
|
||||
logger.error(traceback.format_exc())
|
||||
logger.error(
|
||||
f"实例化 {provider_config['type']}({provider_config['id']}) 提供商适配器失败:{e}"
|
||||
)
|
||||
|
||||
async def reload(self, provider_config: dict):
|
||||
await self.terminate_provider(provider_config["id"])
|
||||
if provider_config["enable"]:
|
||||
await self.load_provider(provider_config)
|
||||
|
||||
# 和配置文件保持同步
|
||||
config_ids = [provider["id"] for provider in self.providers_config]
|
||||
for key in list(self.inst_map.keys()):
|
||||
if key not in config_ids:
|
||||
await self.terminate_provider(key)
|
||||
|
||||
if len(self.provider_insts) == 0:
|
||||
self.curr_provider_inst = None
|
||||
if len(self.stt_provider_insts) == 0:
|
||||
self.curr_stt_provider_inst = None
|
||||
if len(self.tts_provider_insts) == 0:
|
||||
self.curr_tts_provider_inst = None
|
||||
|
||||
def get_insts(self):
|
||||
return self.provider_insts
|
||||
|
||||
|
||||
async def terminate_provider(self, provider_id: str):
|
||||
if provider_id in self.inst_map:
|
||||
logger.info(
|
||||
f"终止 {provider_id} 提供商适配器({len(self.provider_insts)}, {len(self.stt_provider_insts)}, {len(self.tts_provider_insts)}) ..."
|
||||
)
|
||||
|
||||
if self.inst_map[provider_id] in self.provider_insts:
|
||||
self.provider_insts.remove(self.inst_map[provider_id])
|
||||
if self.inst_map[provider_id] in self.stt_provider_insts:
|
||||
self.stt_provider_insts.remove(self.inst_map[provider_id])
|
||||
if self.inst_map[provider_id] in self.tts_provider_insts:
|
||||
self.tts_provider_insts.remove(self.inst_map[provider_id])
|
||||
|
||||
if self.inst_map[provider_id] == self.curr_provider_inst:
|
||||
self.curr_provider_inst = None
|
||||
if self.inst_map[provider_id] == self.curr_stt_provider_inst:
|
||||
self.curr_stt_provider_inst = None
|
||||
if self.inst_map[provider_id] == self.curr_tts_provider_inst:
|
||||
self.curr_tts_provider_inst = None
|
||||
|
||||
if getattr(self.inst_map[provider_id], "terminate", None):
|
||||
await self.inst_map[provider_id].terminate()
|
||||
|
||||
logger.info(
|
||||
f"{provider_id} 提供商适配器已终止({len(self.provider_insts)}, {len(self.stt_provider_insts)}, {len(self.tts_provider_insts)})"
|
||||
)
|
||||
del self.inst_map[provider_id]
|
||||
|
||||
async def terminate(self):
|
||||
for provider_inst in self.provider_insts:
|
||||
if hasattr(provider_inst, "terminate"):
|
||||
await provider_inst.terminate()
|
||||
await provider_inst.terminate()
|
||||
|
||||
@@ -1,9 +1,6 @@
|
||||
import abc
|
||||
import json
|
||||
from collections import defaultdict
|
||||
from typing import List
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot.core import logger
|
||||
from typing import TypedDict
|
||||
from astrbot.core.provider.func_tool_manager import FuncCall
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
@@ -15,19 +12,19 @@ class Personality(TypedDict):
|
||||
name: str = ""
|
||||
begin_dialogs: List[str] = []
|
||||
mood_imitation_dialogs: List[str] = []
|
||||
|
||||
|
||||
# cache
|
||||
_begin_dialogs_processed: List[dict] = []
|
||||
_mood_imitation_dialogs_processed: str = ""
|
||||
|
||||
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProviderMeta():
|
||||
class ProviderMeta:
|
||||
id: str
|
||||
model: str
|
||||
type: str
|
||||
|
||||
|
||||
|
||||
|
||||
class AbstractProvider(abc.ABC):
|
||||
def __init__(self, provider_config: dict) -> None:
|
||||
super().__init__()
|
||||
@@ -35,66 +32,68 @@ class AbstractProvider(abc.ABC):
|
||||
self.provider_config = provider_config
|
||||
|
||||
def set_model(self, model_name: str):
|
||||
'''设置当前使用的模型名称'''
|
||||
"""设置当前使用的模型名称"""
|
||||
self.model_name = model_name
|
||||
|
||||
|
||||
def get_model(self) -> str:
|
||||
'''获得当前使用的模型名称'''
|
||||
"""获得当前使用的模型名称"""
|
||||
return self.model_name
|
||||
|
||||
|
||||
def meta(self) -> ProviderMeta:
|
||||
'''获取 Provider 的元数据'''
|
||||
"""获取 Provider 的元数据"""
|
||||
return ProviderMeta(
|
||||
id=self.provider_config['id'],
|
||||
id=self.provider_config["id"],
|
||||
model=self.get_model(),
|
||||
type=self.provider_config['type']
|
||||
type=self.provider_config["type"],
|
||||
)
|
||||
|
||||
|
||||
class Provider(AbstractProvider):
|
||||
def __init__(
|
||||
self,
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
provider_settings: dict,
|
||||
persistant_history: bool = True,
|
||||
db_helper: BaseDatabase = None,
|
||||
default_persona: Personality = None
|
||||
default_persona: Personality = None,
|
||||
) -> None:
|
||||
super().__init__(provider_config)
|
||||
|
||||
|
||||
self.provider_settings = provider_settings
|
||||
|
||||
|
||||
self.curr_personality: Personality = default_persona
|
||||
'''维护了当前的使用的 persona,即人格。可能为 None'''
|
||||
"""维护了当前的使用的 persona,即人格。可能为 None"""
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_current_key(self) -> str:
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
def get_keys(self) -> List[str]:
|
||||
'''获得提供商 Key'''
|
||||
"""获得提供商 Key"""
|
||||
return self.provider_config.get("key", [])
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def set_key(self, key: str):
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_models(self) -> List[str]:
|
||||
'''获得支持的模型列表'''
|
||||
"""获得支持的模型列表"""
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
async def text_chat(self,
|
||||
prompt: str,
|
||||
session_id: str=None,
|
||||
image_urls: List[str]=None,
|
||||
func_tool: FuncCall=None,
|
||||
contexts: List=None,
|
||||
system_prompt: str=None,
|
||||
**kwargs) -> LLMResponse:
|
||||
'''获得 LLM 的文本对话结果。会使用当前的模型进行对话。
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str = None,
|
||||
image_urls: List[str] = None,
|
||||
func_tool: FuncCall = None,
|
||||
contexts: List = None,
|
||||
system_prompt: str = None,
|
||||
**kwargs,
|
||||
) -> LLMResponse:
|
||||
"""获得 LLM 的文本对话结果。会使用当前的模型进行对话。
|
||||
|
||||
Args:
|
||||
prompt: 提示词
|
||||
session_id: 会话 ID(此属性已经被废弃)
|
||||
@@ -102,17 +101,17 @@ class Provider(AbstractProvider):
|
||||
tools: Function-calling 工具
|
||||
contexts: 上下文
|
||||
kwargs: 其他参数
|
||||
|
||||
|
||||
Notes:
|
||||
- 如果传入了 image_urls,将会在对话时附上图片。如果模型不支持图片输入,将会抛出错误。
|
||||
- 如果传入了 tools,将会使用 tools 进行 Function-calling。如果模型不支持 Function-calling,将会抛出错误。
|
||||
'''
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
async def pop_record(self, context: List):
|
||||
'''
|
||||
"""
|
||||
弹出 context 第一条非系统提示词对话记录
|
||||
'''
|
||||
"""
|
||||
poped = 0
|
||||
indexs_to_pop = []
|
||||
for idx, record in enumerate(context):
|
||||
@@ -123,20 +122,20 @@ class Provider(AbstractProvider):
|
||||
poped += 1
|
||||
if poped == 2:
|
||||
break
|
||||
|
||||
|
||||
for idx in reversed(indexs_to_pop):
|
||||
context.pop(idx)
|
||||
|
||||
|
||||
|
||||
class STTProvider(AbstractProvider):
|
||||
def __init__(self, provider_config: dict, provider_settings: dict) -> None:
|
||||
super().__init__(provider_config)
|
||||
self.provider_config = provider_config
|
||||
self.provider_settings = provider_settings
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
async def get_text(self, audio_url: str) -> str:
|
||||
'''获取音频的文本'''
|
||||
"""获取音频的文本"""
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
@@ -145,8 +144,8 @@ class TTSProvider(AbstractProvider):
|
||||
super().__init__(provider_config)
|
||||
self.provider_config = provider_config
|
||||
self.provider_settings = provider_settings
|
||||
|
||||
|
||||
@abc.abstractmethod
|
||||
async def get_audio(self, text: str) -> str:
|
||||
'''获取文本的音频,返回音频文件路径'''
|
||||
raise NotImplementedError()
|
||||
"""获取文本的音频,返回音频文件路径"""
|
||||
raise NotImplementedError()
|
||||
|
||||
@@ -1,35 +1,39 @@
|
||||
from typing import List, Dict, Type
|
||||
from typing import List, Dict
|
||||
from .entites import ProviderMetaData, ProviderType
|
||||
from astrbot.core import logger
|
||||
from .func_tool_manager import FuncCall
|
||||
|
||||
provider_registry: List[ProviderMetaData] = []
|
||||
'''维护了通过装饰器注册的 Provider'''
|
||||
"""维护了通过装饰器注册的 Provider"""
|
||||
provider_cls_map: Dict[str, ProviderMetaData] = {}
|
||||
'''维护了 Provider 类型名称和 ProviderMetadata 的映射'''
|
||||
"""维护了 Provider 类型名称和 ProviderMetadata 的映射"""
|
||||
|
||||
llm_tools = FuncCall()
|
||||
|
||||
|
||||
def register_provider_adapter(
|
||||
provider_type_name: str,
|
||||
desc: str,
|
||||
provider_type_name: str,
|
||||
desc: str,
|
||||
provider_type: ProviderType = ProviderType.CHAT_COMPLETION,
|
||||
default_config_tmpl: dict = None,
|
||||
provider_display_name: str = None
|
||||
provider_display_name: str = None,
|
||||
):
|
||||
'''用于注册平台适配器的带参装饰器'''
|
||||
"""用于注册平台适配器的带参装饰器"""
|
||||
|
||||
def decorator(cls):
|
||||
if provider_type_name in provider_cls_map:
|
||||
raise ValueError(f"检测到大模型提供商适配器 {provider_type_name} 已经注册,可能发生了大模型提供商适配器类型命名冲突。")
|
||||
|
||||
raise ValueError(
|
||||
f"检测到大模型提供商适配器 {provider_type_name} 已经注册,可能发生了大模型提供商适配器类型命名冲突。"
|
||||
)
|
||||
|
||||
# 添加必备选项
|
||||
if default_config_tmpl:
|
||||
if 'type' not in default_config_tmpl:
|
||||
default_config_tmpl['type'] = provider_type_name
|
||||
if 'enable' not in default_config_tmpl:
|
||||
default_config_tmpl['enable'] = False
|
||||
if 'id' not in default_config_tmpl:
|
||||
default_config_tmpl['id'] = provider_type_name
|
||||
if "type" not in default_config_tmpl:
|
||||
default_config_tmpl["type"] = provider_type_name
|
||||
if "enable" not in default_config_tmpl:
|
||||
default_config_tmpl["enable"] = False
|
||||
if "id" not in default_config_tmpl:
|
||||
default_config_tmpl["id"] = provider_type_name
|
||||
|
||||
pm = ProviderMetaData(
|
||||
type=provider_type_name,
|
||||
@@ -37,11 +41,11 @@ def register_provider_adapter(
|
||||
provider_type=provider_type,
|
||||
cls_type=cls,
|
||||
default_config_tmpl=default_config_tmpl,
|
||||
provider_display_name=provider_display_name
|
||||
provider_display_name=provider_display_name,
|
||||
)
|
||||
provider_registry.append(pm)
|
||||
provider_cls_map[provider_type_name] = pm
|
||||
logger.debug(f"服务提供商 Provider {provider_type_name} 已注册")
|
||||
return cls
|
||||
|
||||
|
||||
return decorator
|
||||
|
||||
195
astrbot/core/provider/sources/anthropic_source.py
Normal file
195
astrbot/core/provider/sources/anthropic_source.py
Normal file
@@ -0,0 +1,195 @@
|
||||
from typing import List
|
||||
from mimetypes import guess_type
|
||||
|
||||
from anthropic import AsyncAnthropic
|
||||
from anthropic.types import Message
|
||||
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot.api.provider import Provider, Personality
|
||||
from astrbot import logger
|
||||
from astrbot.core.provider.func_tool_manager import FuncCall
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
from .openai_source import ProviderOpenAIOfficial
|
||||
|
||||
|
||||
@register_provider_adapter(
|
||||
"anthropic_chat_completion", "Anthropic Claude API 提供商适配器"
|
||||
)
|
||||
class ProviderAnthropic(ProviderOpenAIOfficial):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history=True,
|
||||
default_persona: Personality = None,
|
||||
) -> None:
|
||||
# Skip OpenAI's __init__ and call Provider's __init__ directly
|
||||
Provider.__init__(
|
||||
self,
|
||||
provider_config,
|
||||
provider_settings,
|
||||
persistant_history,
|
||||
db_helper,
|
||||
default_persona,
|
||||
)
|
||||
|
||||
self.chosen_api_key = None
|
||||
self.api_keys: List = provider_config.get("key", [])
|
||||
self.chosen_api_key = self.api_keys[0] if len(self.api_keys) > 0 else None
|
||||
self.base_url = provider_config.get("api_base", "https://api.anthropic.com")
|
||||
self.timeout = provider_config.get("timeout", 120)
|
||||
if isinstance(self.timeout, str):
|
||||
self.timeout = int(self.timeout)
|
||||
|
||||
self.client = AsyncAnthropic(
|
||||
api_key=self.chosen_api_key, timeout=self.timeout, base_url=self.base_url
|
||||
)
|
||||
|
||||
self.set_model(provider_config["model_config"]["model"])
|
||||
|
||||
async def _query(self, payloads: dict, tools: FuncCall) -> LLMResponse:
|
||||
if tools:
|
||||
tool_list = tools.get_func_desc_anthropic_style()
|
||||
if tool_list:
|
||||
payloads["tools"] = tool_list
|
||||
|
||||
completion = await self.client.messages.create(**payloads, stream=False)
|
||||
|
||||
assert isinstance(completion, Message)
|
||||
logger.debug(f"completion: {completion}")
|
||||
|
||||
if len(completion.content) == 0:
|
||||
raise Exception("API 返回的 completion 为空。")
|
||||
# TODO: 如果进行函数调用,思维链被截断,用户可能需要思维链的内容
|
||||
# 选最后一条消息,如果要进行函数调用,anthropic会先返回文本消息的思维链,然后再返回函数调用请求
|
||||
content = completion.content[-1]
|
||||
|
||||
llm_response = LLMResponse("assistant")
|
||||
|
||||
if content.type == "text":
|
||||
# text completion
|
||||
completion_text = str(content.text).strip()
|
||||
llm_response.completion_text = completion_text
|
||||
|
||||
# Anthropic每次只返回一个函数调用
|
||||
if completion.stop_reason == "tool_use":
|
||||
# tools call (function calling)
|
||||
args_ls = []
|
||||
func_name_ls = []
|
||||
func_name_ls.append(content.name)
|
||||
args_ls.append(content.input)
|
||||
llm_response.role = "tool"
|
||||
llm_response.tools_call_args = args_ls
|
||||
llm_response.tools_call_name = func_name_ls
|
||||
|
||||
if not llm_response.completion_text and not llm_response.tools_call_args:
|
||||
logger.error(f"API 返回的 completion 无法解析:{completion}。")
|
||||
raise Exception(f"API 返回的 completion 无法解析:{completion}。")
|
||||
|
||||
llm_response.raw_completion = completion
|
||||
|
||||
return llm_response
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str = None,
|
||||
image_urls: List[str] = [],
|
||||
func_tool: FuncCall = None,
|
||||
contexts=[],
|
||||
system_prompt=None,
|
||||
**kwargs,
|
||||
) -> LLMResponse:
|
||||
if not prompt:
|
||||
prompt = "<image>"
|
||||
|
||||
new_record = await self.assemble_context(prompt, image_urls)
|
||||
context_query = [*contexts, new_record]
|
||||
|
||||
for part in context_query:
|
||||
if "_no_save" in part:
|
||||
del part["_no_save"]
|
||||
|
||||
model_config = self.provider_config.get("model_config", {})
|
||||
|
||||
payloads = {"messages": context_query, **model_config}
|
||||
# Anthropic has a different way of handling system prompts
|
||||
if system_prompt:
|
||||
payloads["system"] = system_prompt
|
||||
|
||||
llm_response = None
|
||||
try:
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt = 20
|
||||
while retry_cnt > 0:
|
||||
logger.warning(
|
||||
f"上下文长度超过限制。尝试弹出最早的记录然后重试。当前记录条数: {len(context_query)}"
|
||||
)
|
||||
try:
|
||||
await self.pop_record(context_query)
|
||||
response = await self.client.messages.create(
|
||||
messages=context_query, **model_config
|
||||
)
|
||||
llm_response = LLMResponse("assistant")
|
||||
llm_response.completion_text = response.content[0].text
|
||||
llm_response.raw_completion = response
|
||||
return llm_response
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt -= 1
|
||||
else:
|
||||
raise e
|
||||
return LLMResponse("err", "err: 请尝试 /reset 清除会话记录。")
|
||||
else:
|
||||
logger.error(f"发生了错误。Provider 配置如下: {model_config}")
|
||||
raise e
|
||||
|
||||
return llm_response
|
||||
|
||||
async def assemble_context(self, text: str, image_urls: List[str] = None):
|
||||
"""组装上下文,支持文本和图片"""
|
||||
if not image_urls:
|
||||
return {"role": "user", "content": text}
|
||||
|
||||
content = []
|
||||
content.append({"type": "text", "text": text})
|
||||
|
||||
for image_url in image_urls:
|
||||
if image_url.startswith("http"):
|
||||
image_path = await download_image_by_url(image_url)
|
||||
image_data = await self.encode_image_bs64(image_path)
|
||||
elif image_url.startswith("file:///"):
|
||||
image_path = image_url.replace("file:///", "")
|
||||
image_data = await self.encode_image_bs64(image_path)
|
||||
else:
|
||||
image_data = await self.encode_image_bs64(image_url)
|
||||
|
||||
if not image_data:
|
||||
logger.warning(f"图片 {image_url} 得到的结果为空,将忽略。")
|
||||
continue
|
||||
|
||||
# Get mime type for the image
|
||||
mime_type, _ = guess_type(image_url)
|
||||
if not mime_type:
|
||||
mime_type = "image/jpeg" # Default to JPEG if can't determine
|
||||
|
||||
content.append(
|
||||
{
|
||||
"type": "image",
|
||||
"source": {
|
||||
"type": "base64",
|
||||
"media_type": mime_type,
|
||||
"data": image_data.split("base64,")[1]
|
||||
if "base64," in image_data
|
||||
else image_data,
|
||||
},
|
||||
}
|
||||
)
|
||||
|
||||
return {"role": "user", "content": content}
|
||||
128
astrbot/core/provider/sources/dashscope_source.py
Normal file
128
astrbot/core/provider/sources/dashscope_source.py
Normal file
@@ -0,0 +1,128 @@
|
||||
import asyncio
|
||||
import functools
|
||||
from typing import List
|
||||
from .. import Provider, Personality
|
||||
from ..entites import LLMResponse
|
||||
from ..func_tool_manager import FuncCall
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from ..register import register_provider_adapter
|
||||
from .openai_source import ProviderOpenAIOfficial
|
||||
from astrbot.core import logger, sp
|
||||
from dashscope import Application
|
||||
|
||||
|
||||
@register_provider_adapter("dashscope", "Dashscope APP 适配器。")
|
||||
class ProviderDashscope(ProviderOpenAIOfficial):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history=False,
|
||||
default_persona: Personality = None,
|
||||
) -> None:
|
||||
Provider.__init__(
|
||||
self,
|
||||
provider_config,
|
||||
provider_settings,
|
||||
persistant_history,
|
||||
db_helper,
|
||||
default_persona,
|
||||
)
|
||||
self.api_key = provider_config.get("dashscope_api_key", "")
|
||||
if not self.api_key:
|
||||
raise Exception("阿里云百炼 API Key 不能为空。")
|
||||
self.app_id = provider_config.get("dashscope_app_id", "")
|
||||
if not self.app_id:
|
||||
raise Exception("阿里云百炼 APP ID 不能为空。")
|
||||
self.dashscope_app_type = provider_config.get("dashscope_app_type", "")
|
||||
if not self.dashscope_app_type:
|
||||
raise Exception("阿里云百炼 APP 类型不能为空。")
|
||||
self.model_name = "dashscope"
|
||||
self.variables: dict = provider_config.get("variables", {})
|
||||
|
||||
self.timeout = provider_config.get("timeout", 120)
|
||||
if isinstance(self.timeout, str):
|
||||
self.timeout = int(self.timeout)
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str = None,
|
||||
image_urls: List[str] = [],
|
||||
func_tool: FuncCall = None,
|
||||
contexts: List = None,
|
||||
system_prompt: str = None,
|
||||
**kwargs,
|
||||
) -> LLMResponse:
|
||||
# 获得会话变量
|
||||
payload_vars = self.variables.copy()
|
||||
# 动态变量
|
||||
session_vars = sp.get("session_variables", {})
|
||||
session_var = session_vars.get(session_id, {})
|
||||
payload_vars.update(session_var)
|
||||
|
||||
if self.dashscope_app_type in ["agent", "dialog-workflow"]:
|
||||
# 支持多轮对话的
|
||||
new_record = {"role": "user", "content": prompt}
|
||||
if image_urls:
|
||||
logger.warning("阿里云百炼暂不支持图片输入,将自动忽略图片内容。")
|
||||
contexts_no_img = await self._remove_image_from_context(contexts)
|
||||
context_query = [*contexts_no_img, new_record]
|
||||
if system_prompt:
|
||||
context_query.insert(0, {"role": "system", "content": system_prompt})
|
||||
for part in context_query:
|
||||
if "_no_save" in part:
|
||||
del part["_no_save"]
|
||||
# 调用阿里云百炼 API
|
||||
partial = functools.partial(
|
||||
Application.call,
|
||||
app_id=self.app_id,
|
||||
api_key=self.api_key,
|
||||
messages=context_query,
|
||||
biz_params=payload_vars or None,
|
||||
)
|
||||
response = await asyncio.get_event_loop().run_in_executor(None, partial)
|
||||
else:
|
||||
# 不支持多轮对话的
|
||||
# 调用阿里云百炼 API
|
||||
partial = functools.partial(
|
||||
Application.call,
|
||||
app_id=self.app_id,
|
||||
promtp=prompt,
|
||||
api_key=self.api_key,
|
||||
biz_params=payload_vars or None,
|
||||
)
|
||||
response = await asyncio.get_event_loop().run_in_executor(None, partial)
|
||||
|
||||
logger.debug(f"dashscope resp: {response}")
|
||||
|
||||
if response.status_code != 200:
|
||||
logger.error(
|
||||
f"阿里云百炼请求失败: request_id={response.request_id}, code={response.status_code}, message={response.message}, 请参考文档:https://help.aliyun.com/zh/model-studio/developer-reference/error-code"
|
||||
)
|
||||
return LLMResponse(
|
||||
role="err",
|
||||
completion_text=f"阿里云百炼请求失败: message={response.message} code={response.status_code}",
|
||||
)
|
||||
|
||||
output_text = response.output.get("text", "")
|
||||
return LLMResponse(role="assistant", completion_text=output_text)
|
||||
|
||||
async def forget(self, session_id):
|
||||
return True
|
||||
|
||||
async def get_current_key(self):
|
||||
return self.api_key
|
||||
|
||||
async def set_key(self, key):
|
||||
raise Exception("阿里云百炼 适配器不支持设置 API Key。")
|
||||
|
||||
async def get_models(self):
|
||||
return [self.get_model()]
|
||||
|
||||
async def get_human_readable_context(self, session_id, page, page_size):
|
||||
raise Exception("暂不支持获得 阿里云百炼 的历史消息记录。")
|
||||
|
||||
async def terminate(self):
|
||||
pass
|
||||
@@ -8,6 +8,7 @@ from astrbot.core.utils.dify_api_client import DifyAPIClient
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
from astrbot.core import logger, sp
|
||||
|
||||
|
||||
@register_provider_adapter("dify", "Dify APP 适配器。")
|
||||
class ProviderDify(Provider):
|
||||
def __init__(
|
||||
@@ -16,10 +17,14 @@ class ProviderDify(Provider):
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history=False,
|
||||
default_persona: Personality=None
|
||||
default_persona: Personality = None,
|
||||
) -> None:
|
||||
super().__init__(
|
||||
provider_config, provider_settings, persistant_history, db_helper, default_persona
|
||||
provider_config,
|
||||
provider_settings,
|
||||
persistant_history,
|
||||
db_helper,
|
||||
default_persona,
|
||||
)
|
||||
self.api_key = provider_config.get("dify_api_key", "")
|
||||
if not self.api_key:
|
||||
@@ -30,13 +35,20 @@ class ProviderDify(Provider):
|
||||
if not self.api_type:
|
||||
raise Exception("Dify API 类型不能为空。")
|
||||
self.model_name = "dify"
|
||||
self.workflow_output_key = provider_config.get("dify_workflow_output_key", "astrbot_wf_output")
|
||||
self.workflow_output_key = provider_config.get(
|
||||
"dify_workflow_output_key", "astrbot_wf_output"
|
||||
)
|
||||
self.dify_query_input_key = provider_config.get(
|
||||
"dify_query_input_key", "astrbot_text_query"
|
||||
)
|
||||
self.variables: dict = provider_config.get("variables", {})
|
||||
if not self.dify_query_input_key:
|
||||
self.dify_query_input_key = "astrbot_text_query"
|
||||
self.timeout = provider_config.get("timeout", 120)
|
||||
if isinstance(self.timeout, str):
|
||||
self.timeout = int(self.timeout)
|
||||
self.conversation_ids = {}
|
||||
'''记录当前 session id 的对话 ID'''
|
||||
|
||||
"""记录当前 session id 的对话 ID"""
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
@@ -50,78 +62,124 @@ class ProviderDify(Provider):
|
||||
) -> LLMResponse:
|
||||
result = ""
|
||||
conversation_id = self.conversation_ids.get(session_id, "")
|
||||
|
||||
|
||||
files_payload = []
|
||||
for image_url in image_urls:
|
||||
if image_url.startswith("http"):
|
||||
image_path = await download_image_by_url(image_url)
|
||||
file_response = await self.api_client.file_upload(image_path, user=session_id)
|
||||
if 'id' not in file_response:
|
||||
logger.warning(f"上传图片后得到未知的 Dify 响应:{file_response},图片将忽略。")
|
||||
file_response = await self.api_client.file_upload(
|
||||
image_path, user=session_id
|
||||
)
|
||||
if "id" not in file_response:
|
||||
logger.warning(
|
||||
f"上传图片后得到未知的 Dify 响应:{file_response},图片将忽略。"
|
||||
)
|
||||
continue
|
||||
files_payload.append({
|
||||
"type": "image",
|
||||
"transfer_method": "local_file",
|
||||
"upload_file_id": file_response['id'],
|
||||
})
|
||||
files_payload.append(
|
||||
{
|
||||
"type": "image",
|
||||
"transfer_method": "local_file",
|
||||
"upload_file_id": file_response["id"],
|
||||
}
|
||||
)
|
||||
else:
|
||||
# TODO: 处理更多情况
|
||||
logger.warning(f"未知的图片链接:{image_url},图片将忽略。")
|
||||
|
||||
|
||||
# 获得会话变量
|
||||
payload_vars = self.variables.copy()
|
||||
# 动态变量
|
||||
session_vars = sp.get("session_variables", {})
|
||||
session_var = session_vars.get(session_id, {})
|
||||
|
||||
match self.api_type:
|
||||
case "chat" | "agent":
|
||||
async for chunk in self.api_client.chat_messages(
|
||||
inputs={
|
||||
**session_var
|
||||
},
|
||||
query=prompt,
|
||||
user=session_id,
|
||||
conversation_id=conversation_id,
|
||||
files=files_payload,
|
||||
timeout=self.timeout
|
||||
):
|
||||
logger.debug(f"dify resp chunk: {chunk}")
|
||||
if chunk['event'] == "message" or \
|
||||
chunk['event'] == "agent_message":
|
||||
result += chunk['answer']
|
||||
if not conversation_id:
|
||||
self.conversation_ids[session_id] = chunk['conversation_id']
|
||||
conversation_id = chunk['conversation_id']
|
||||
|
||||
case "workflow":
|
||||
async for chunk in self.api_client.workflow_run(
|
||||
inputs={
|
||||
"astrbot_text_query": prompt,
|
||||
"astrbot_session_id": session_id,
|
||||
**session_var
|
||||
},
|
||||
user=session_id,
|
||||
files=files_payload,
|
||||
timeout=self.timeout
|
||||
):
|
||||
match chunk['event']:
|
||||
case "workflow_started":
|
||||
logger.info(f"Dify 工作流(ID: {chunk['workflow_run_id']})开始运行。")
|
||||
case "node_finished":
|
||||
logger.debug(f"Dify 工作流节点(ID: {chunk['data']['node_id']} Title: {chunk['data'].get('title', '')})运行结束。")
|
||||
case "workflow_finished":
|
||||
logger.info(f"Dify 工作流(ID: {chunk['workflow_run_id']})运行结束。")
|
||||
if chunk['data']['error']:
|
||||
logger.error(f"Dify 工作流出现错误:{chunk['data']['error']}")
|
||||
raise Exception(f"Dify 工作流出现错误:{chunk['data']['error']}")
|
||||
if self.workflow_output_key not in chunk['data']['outputs']:
|
||||
raise Exception(f"Dify 工作流的输出不包含指定的键名:{self.workflow_output_key}")
|
||||
result = chunk['data']['outputs'][self.workflow_output_key]
|
||||
case _:
|
||||
raise Exception(f"未知的 Dify API 类型:{self.api_type}")
|
||||
payload_vars.update(session_var)
|
||||
|
||||
try:
|
||||
match self.api_type:
|
||||
case "chat" | "agent":
|
||||
async for chunk in self.api_client.chat_messages(
|
||||
inputs={
|
||||
**payload_vars,
|
||||
},
|
||||
query=prompt,
|
||||
user=session_id,
|
||||
conversation_id=conversation_id,
|
||||
files=files_payload,
|
||||
timeout=self.timeout,
|
||||
):
|
||||
logger.debug(f"dify resp chunk: {chunk}")
|
||||
if (
|
||||
chunk["event"] == "message"
|
||||
or chunk["event"] == "agent_message"
|
||||
):
|
||||
result += chunk["answer"]
|
||||
if not conversation_id:
|
||||
self.conversation_ids[session_id] = chunk[
|
||||
"conversation_id"
|
||||
]
|
||||
conversation_id = chunk["conversation_id"]
|
||||
elif chunk["event"] == "message_end":
|
||||
logger.debug("Dify message end")
|
||||
break
|
||||
elif chunk["event"] == "error":
|
||||
logger.error(f"Dify 出现错误:{chunk}")
|
||||
raise Exception(
|
||||
f"Dify 出现错误 status: {chunk['status']} message: {chunk['message']}"
|
||||
)
|
||||
|
||||
case "workflow":
|
||||
async for chunk in self.api_client.workflow_run(
|
||||
inputs={
|
||||
self.dify_query_input_key: prompt,
|
||||
"astrbot_session_id": session_id,
|
||||
**payload_vars,
|
||||
},
|
||||
user=session_id,
|
||||
files=files_payload,
|
||||
timeout=self.timeout,
|
||||
):
|
||||
match chunk["event"]:
|
||||
case "workflow_started":
|
||||
logger.info(
|
||||
f"Dify 工作流(ID: {chunk['workflow_run_id']})开始运行。"
|
||||
)
|
||||
case "node_finished":
|
||||
logger.debug(
|
||||
f"Dify 工作流节点(ID: {chunk['data']['node_id']} Title: {chunk['data'].get('title', '')})运行结束。"
|
||||
)
|
||||
case "workflow_finished":
|
||||
logger.info(
|
||||
f"Dify 工作流(ID: {chunk['workflow_run_id']})运行结束。"
|
||||
)
|
||||
if chunk["data"]["error"]:
|
||||
logger.error(
|
||||
f"Dify 工作流出现错误:{chunk['data']['error']}"
|
||||
)
|
||||
raise Exception(
|
||||
f"Dify 工作流出现错误:{chunk['data']['error']}"
|
||||
)
|
||||
if (
|
||||
self.workflow_output_key
|
||||
not in chunk["data"]["outputs"]
|
||||
):
|
||||
raise Exception(
|
||||
f"Dify 工作流的输出不包含指定的键名:{self.workflow_output_key}"
|
||||
)
|
||||
result = chunk["data"]["outputs"][
|
||||
self.workflow_output_key
|
||||
]
|
||||
case _:
|
||||
raise Exception(f"未知的 Dify API 类型:{self.api_type}")
|
||||
except Exception as e:
|
||||
logger.error(f"Dify 请求失败:{str(e)}")
|
||||
return LLMResponse(role="err", completion_text=f"Dify 请求失败:{str(e)}")
|
||||
|
||||
if not result:
|
||||
logger.warning("Dify 请求结果为空,请查看 Debug 日志。")
|
||||
|
||||
return LLMResponse(role="assistant", completion_text=result)
|
||||
|
||||
async def forget(self, session_id):
|
||||
self.conversation_ids.pop(session_id, None)
|
||||
self.conversation_ids[session_id] = ""
|
||||
return True
|
||||
|
||||
async def get_current_key(self):
|
||||
@@ -137,4 +195,4 @@ class ProviderDify(Provider):
|
||||
raise Exception("暂不支持获得 Dify 的历史消息记录。")
|
||||
|
||||
async def terminate(self):
|
||||
await self.api_client.close()
|
||||
await self.api_client.close()
|
||||
|
||||
100
astrbot/core/provider/sources/edge_tts_source.py
Normal file
100
astrbot/core/provider/sources/edge_tts_source.py
Normal file
@@ -0,0 +1,100 @@
|
||||
import uuid
|
||||
import os
|
||||
import edge_tts
|
||||
import subprocess
|
||||
import asyncio
|
||||
from ..provider import TTSProvider
|
||||
from ..entites import ProviderType
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core import logger
|
||||
|
||||
"""
|
||||
edge_tts 方式,能够免费、快速生成语音,使用需要先安装edge-tts库
|
||||
```
|
||||
pip install edge_tts
|
||||
```
|
||||
Windows 如果提示找不到指定文件,以管理员身份运行命令行窗口,然后再次运行 AstrBot
|
||||
"""
|
||||
|
||||
|
||||
@register_provider_adapter(
|
||||
"edge_tts", "Microsoft Edge TTS", provider_type=ProviderType.TEXT_TO_SPEECH
|
||||
)
|
||||
class ProviderEdgeTTS(TTSProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
|
||||
# 设置默认语音,如果没有指定则使用中文小萱
|
||||
self.voice = provider_config.get("edge-tts-voice", "zh-CN-XiaoxiaoNeural")
|
||||
self.rate = provider_config.get("rate", None)
|
||||
self.volume = provider_config.get("volume", None)
|
||||
self.pitch = provider_config.get("pitch", None)
|
||||
self.timeout = provider_config.get("timeout", 30)
|
||||
|
||||
self.set_model("edge_tts")
|
||||
|
||||
async def get_audio(self, text: str) -> str:
|
||||
os.makedirs("data/temp", exist_ok=True)
|
||||
mp3_path = f"data/temp/edge_tts_temp_{uuid.uuid4()}.mp3"
|
||||
wav_path = f"data/temp/edge_tts_{uuid.uuid4()}.wav"
|
||||
|
||||
# 构建Edge TTS参数
|
||||
kwargs = {"text": text, "voice": self.voice}
|
||||
if self.rate:
|
||||
kwargs["rate"] = self.rate
|
||||
if self.volume:
|
||||
kwargs["volume"] = self.volume
|
||||
if self.pitch:
|
||||
kwargs["pitch"] = self.pitch
|
||||
|
||||
try:
|
||||
communicate = edge_tts.Communicate(**kwargs)
|
||||
await communicate.save(mp3_path)
|
||||
|
||||
# 使用ffmpeg将MP3转换为标准WAV格式
|
||||
_ = await asyncio.create_subprocess_exec(
|
||||
[
|
||||
"ffmpeg",
|
||||
"-y", # 覆盖输出文件
|
||||
"-i",
|
||||
mp3_path, # 输入文件
|
||||
"-acodec",
|
||||
"pcm_s16le", # 16位PCM编码
|
||||
"-ar",
|
||||
"24000", # 采样率24kHz (适合微信语音)
|
||||
"-ac",
|
||||
"1", # 单声道
|
||||
wav_path, # 输出文件
|
||||
],
|
||||
capture_output=True,
|
||||
check=True,
|
||||
)
|
||||
|
||||
os.remove(mp3_path)
|
||||
if os.path.exists(wav_path) and os.path.getsize(wav_path) > 0:
|
||||
return wav_path
|
||||
else:
|
||||
logger.error("生成的WAV文件不存在或为空")
|
||||
raise RuntimeError("生成的WAV文件不存在或为空")
|
||||
|
||||
except subprocess.CalledProcessError as e:
|
||||
logger.error(f"FFmpeg转换失败: {e.stderr.decode() if e.stderr else str(e)}")
|
||||
try:
|
||||
if os.path.exists(mp3_path):
|
||||
os.remove(mp3_path)
|
||||
except Exception:
|
||||
pass
|
||||
raise RuntimeError(f"FFmpeg转换失败: {str(e)}")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"音频生成失败: {str(e)}")
|
||||
try:
|
||||
if os.path.exists(mp3_path):
|
||||
os.remove(mp3_path)
|
||||
except Exception:
|
||||
pass
|
||||
raise RuntimeError(f"音频生成失败: {str(e)}")
|
||||
@@ -1,5 +1,6 @@
|
||||
import base64
|
||||
import aiohttp
|
||||
import random
|
||||
from astrbot.core.utils.io import download_image_by_url
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot.api.provider import Provider, Personality
|
||||
@@ -9,8 +10,9 @@ from typing import List
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
|
||||
class SimpleGoogleGenAIClient():
|
||||
def __init__(self, api_key: str, api_base: str, timeout: int=120) -> None:
|
||||
|
||||
class SimpleGoogleGenAIClient:
|
||||
def __init__(self, api_key: str, api_base: str, timeout: int = 120) -> None:
|
||||
self.api_key = api_key
|
||||
if api_base.endswith("/"):
|
||||
self.api_base = api_base[:-1]
|
||||
@@ -18,36 +20,38 @@ class SimpleGoogleGenAIClient():
|
||||
self.api_base = api_base
|
||||
self.client = aiohttp.ClientSession(trust_env=True)
|
||||
self.timeout = timeout
|
||||
|
||||
|
||||
async def models_list(self) -> List[str]:
|
||||
request_url = f"{self.api_base}/v1beta/models?key={self.api_key}"
|
||||
async with self.client.get(request_url, timeout=self.timeout) as resp:
|
||||
response = await resp.json()
|
||||
|
||||
|
||||
models = []
|
||||
for model in response["models"]:
|
||||
if 'generateContent' in model["supportedGenerationMethods"]:
|
||||
if "generateContent" in model["supportedGenerationMethods"]:
|
||||
models.append(model["name"].replace("models/", ""))
|
||||
return models
|
||||
|
||||
async def generate_content(
|
||||
self,
|
||||
contents: List[dict],
|
||||
model: str="gemini-1.5-flash",
|
||||
system_instruction: str="",
|
||||
tools: dict=None
|
||||
self,
|
||||
contents: List[dict],
|
||||
model: str = "gemini-1.5-flash",
|
||||
system_instruction: str = "",
|
||||
tools: dict = None,
|
||||
):
|
||||
payload = {}
|
||||
if system_instruction:
|
||||
payload["system_instruction"] = {
|
||||
"parts": {"text": system_instruction}
|
||||
}
|
||||
payload["system_instruction"] = {"parts": {"text": system_instruction}}
|
||||
if tools:
|
||||
payload["tools"] = [tools]
|
||||
payload["contents"] = contents
|
||||
logger.debug(f"payload: {payload}")
|
||||
request_url = f"{self.api_base}/v1beta/models/{model}:generateContent?key={self.api_key}"
|
||||
async with self.client.post(request_url, json=payload, timeout=self.timeout) as resp:
|
||||
request_url = (
|
||||
f"{self.api_base}/v1beta/models/{model}:generateContent?key={self.api_key}"
|
||||
)
|
||||
async with self.client.post(
|
||||
request_url, json=payload, timeout=self.timeout
|
||||
) as resp:
|
||||
if "application/json" in resp.headers.get("Content-Type"):
|
||||
try:
|
||||
response = await resp.json()
|
||||
@@ -62,17 +66,25 @@ class SimpleGoogleGenAIClient():
|
||||
raise Exception("Gemini 返回了非 json 数据: ")
|
||||
|
||||
|
||||
@register_provider_adapter("googlegenai_chat_completion", "Google Gemini Chat Completion 提供商适配器")
|
||||
@register_provider_adapter(
|
||||
"googlegenai_chat_completion", "Google Gemini Chat Completion 提供商适配器"
|
||||
)
|
||||
class ProviderGoogleGenAI(Provider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history = True,
|
||||
default_persona: Personality=None
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history=True,
|
||||
default_persona: Personality = None,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings, persistant_history, db_helper, default_persona)
|
||||
super().__init__(
|
||||
provider_config,
|
||||
provider_settings,
|
||||
persistant_history,
|
||||
db_helper,
|
||||
default_persona,
|
||||
)
|
||||
self.chosen_api_key = None
|
||||
self.api_keys: List = provider_config.get("key", [])
|
||||
self.chosen_api_key = self.api_keys[0] if len(self.api_keys) > 0 else None
|
||||
@@ -82,80 +94,87 @@ class ProviderGoogleGenAI(Provider):
|
||||
self.client = SimpleGoogleGenAIClient(
|
||||
api_key=self.chosen_api_key,
|
||||
api_base=provider_config.get("api_base", None),
|
||||
timeout=self.timeout
|
||||
timeout=self.timeout,
|
||||
)
|
||||
self.set_model(provider_config['model_config']['model'])
|
||||
self.set_model(provider_config["model_config"]["model"])
|
||||
|
||||
async def get_models(self):
|
||||
return await self.client.models_list()
|
||||
|
||||
|
||||
async def _query(self, payloads: dict, tools: FuncCall) -> LLMResponse:
|
||||
tool = None
|
||||
if tools:
|
||||
tool = tools.get_func_desc_google_genai_style()
|
||||
if not tool:
|
||||
tool = None
|
||||
|
||||
|
||||
system_instruction = ""
|
||||
for message in payloads["messages"]:
|
||||
if message["role"] == "system":
|
||||
system_instruction = message["content"]
|
||||
break
|
||||
|
||||
|
||||
google_genai_conversation = []
|
||||
for message in payloads["messages"]:
|
||||
if message["role"] == "user":
|
||||
if isinstance(message["content"], str):
|
||||
google_genai_conversation.append({
|
||||
"role": "user",
|
||||
"parts": [{"text": message["content"]}]
|
||||
})
|
||||
if not message["content"]:
|
||||
message["content"] = "<empty_content>"
|
||||
|
||||
google_genai_conversation.append(
|
||||
{"role": "user", "parts": [{"text": message["content"]}]}
|
||||
)
|
||||
elif isinstance(message["content"], list):
|
||||
# images
|
||||
parts = []
|
||||
for part in message["content"]:
|
||||
if part["type"] == "text":
|
||||
if not part["text"]:
|
||||
part["text"] = "<empty_content>"
|
||||
parts.append({"text": part["text"]})
|
||||
elif part["type"] == "image_url":
|
||||
parts.append({"inline_data": {
|
||||
"mime_type": "image/jpeg",
|
||||
"data": part["image_url"]["url"].replace("data:image/jpeg;base64,", "") # base64
|
||||
}})
|
||||
google_genai_conversation.append({
|
||||
"role": "user",
|
||||
"parts": parts
|
||||
})
|
||||
|
||||
parts.append(
|
||||
{
|
||||
"inline_data": {
|
||||
"mime_type": "image/jpeg",
|
||||
"data": part["image_url"]["url"].replace(
|
||||
"data:image/jpeg;base64,", ""
|
||||
), # base64
|
||||
}
|
||||
}
|
||||
)
|
||||
google_genai_conversation.append({"role": "user", "parts": parts})
|
||||
|
||||
elif message["role"] == "assistant":
|
||||
google_genai_conversation.append({
|
||||
"role": "model",
|
||||
"parts": [{"text": message["content"]}]
|
||||
})
|
||||
|
||||
|
||||
if not message["content"]:
|
||||
message["content"] = "<empty_content>"
|
||||
google_genai_conversation.append(
|
||||
{"role": "model", "parts": [{"text": message["content"]}]}
|
||||
)
|
||||
|
||||
logger.debug(f"google_genai_conversation: {google_genai_conversation}")
|
||||
|
||||
|
||||
result = await self.client.generate_content(
|
||||
contents=google_genai_conversation,
|
||||
model=self.get_model(),
|
||||
system_instruction=system_instruction,
|
||||
tools=tool
|
||||
tools=tool,
|
||||
)
|
||||
logger.debug(f"result: {result}")
|
||||
|
||||
|
||||
if "candidates" not in result:
|
||||
raise Exception("Gemini 返回异常结果: " + str(result))
|
||||
|
||||
candidates = result["candidates"][0]['content']['parts']
|
||||
|
||||
candidates = result["candidates"][0]["content"]["parts"]
|
||||
llm_response = LLMResponse("assistant")
|
||||
for candidate in candidates:
|
||||
if 'text' in candidate:
|
||||
llm_response.completion_text += candidate['text']
|
||||
elif 'functionCall' in candidate:
|
||||
if "text" in candidate:
|
||||
llm_response.completion_text += candidate["text"]
|
||||
elif "functionCall" in candidate:
|
||||
llm_response.role = "tool"
|
||||
llm_response.tools_call_args.append(candidate['functionCall']['args'])
|
||||
llm_response.tools_call_name.append(candidate['functionCall']['name'])
|
||||
|
||||
llm_response.tools_call_args.append(candidate["functionCall"]["args"])
|
||||
llm_response.tools_call_name.append(candidate["functionCall"]["name"])
|
||||
|
||||
llm_response.completion_text = llm_response.completion_text.strip()
|
||||
return llm_response
|
||||
|
||||
@@ -163,57 +182,83 @@ class ProviderGoogleGenAI(Provider):
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str = None,
|
||||
image_urls: List[str]=None,
|
||||
func_tool: FuncCall=None,
|
||||
image_urls: List[str] = None,
|
||||
func_tool: FuncCall = None,
|
||||
contexts=[],
|
||||
system_prompt=None,
|
||||
**kwargs
|
||||
) -> LLMResponse:
|
||||
**kwargs,
|
||||
) -> LLMResponse:
|
||||
new_record = await self.assemble_context(prompt, image_urls)
|
||||
context_query = []
|
||||
context_query = [*contexts, new_record]
|
||||
if system_prompt:
|
||||
context_query.insert(0, {"role": "system", "content": system_prompt})
|
||||
|
||||
for part in context_query:
|
||||
if '_no_save' in part:
|
||||
del part['_no_save']
|
||||
|
||||
model_config = self.provider_config.get("model_config", {})
|
||||
model_config['model'] = self.get_model()
|
||||
|
||||
payloads = {
|
||||
"messages": context_query,
|
||||
**model_config
|
||||
}
|
||||
for part in context_query:
|
||||
if "_no_save" in part:
|
||||
del part["_no_save"]
|
||||
|
||||
model_config = self.provider_config.get("model_config", {})
|
||||
model_config["model"] = self.get_model()
|
||||
|
||||
payloads = {"messages": context_query, **model_config}
|
||||
llm_response = None
|
||||
try:
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt = 20
|
||||
while retry_cnt > 0:
|
||||
logger.warning(f"请求失败:{e}。上下文长度超过限制。尝试弹出最早的记录然后重试。当前记录条数: {len(context_query)}")
|
||||
try:
|
||||
await self.pop_record(context_query)
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
break
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt -= 1
|
||||
else:
|
||||
raise e
|
||||
if retry_cnt == 0:
|
||||
llm_response = LLMResponse("err", "err: 请尝试 /reset 重置会话")
|
||||
elif "Function calling is not enabled" in str(e):
|
||||
logger.info(f"{self.get_model()} 不支持函数工具调用,已自动去除,不影响使用。")
|
||||
if 'tools' in payloads:
|
||||
del payloads['tools']
|
||||
llm_response = await self._query(payloads, None)
|
||||
else:
|
||||
logger.error(f"发生了错误(gemini_source)。Provider 配置如下: {self.provider_config}")
|
||||
|
||||
raise e
|
||||
|
||||
retry = 10
|
||||
keys = self.api_keys.copy()
|
||||
chosen_key = random.choice(keys)
|
||||
|
||||
for i in range(retry):
|
||||
try:
|
||||
self.client.api_key = chosen_key
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
break
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt = 20
|
||||
while retry_cnt > 0:
|
||||
logger.warning(
|
||||
f"请求失败:{e}。上下文长度超过限制。尝试弹出最早的记录然后重试。当前记录条数: {len(context_query)}"
|
||||
)
|
||||
try:
|
||||
await self.pop_record(context_query)
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
break
|
||||
except Exception as e:
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt -= 1
|
||||
else:
|
||||
raise e
|
||||
if retry_cnt == 0:
|
||||
llm_response = LLMResponse(
|
||||
"err", "err: 请尝试 /reset 重置会话"
|
||||
)
|
||||
elif "Function calling is not enabled" in str(e):
|
||||
logger.info(
|
||||
f"{self.get_model()} 不支持函数工具调用,已自动去除,不影响使用。"
|
||||
)
|
||||
if "tools" in payloads:
|
||||
del payloads["tools"]
|
||||
llm_response = await self._query(payloads, None)
|
||||
break
|
||||
elif "429" in str(e) or "API key not valid" in str(e):
|
||||
keys.remove(chosen_key)
|
||||
if len(keys) > 0:
|
||||
chosen_key = random.choice(keys)
|
||||
logger.info(
|
||||
f"检测到 Key 异常({str(e)}),正在尝试更换 API Key 重试... 当前 Key: {chosen_key[:12]}..."
|
||||
)
|
||||
continue
|
||||
else:
|
||||
logger.error(
|
||||
f"检测到 Key 异常({str(e)}),且已没有可用的 Key。 当前 Key: {chosen_key[:12]}..."
|
||||
)
|
||||
raise Exception("API 资源已耗尽,且没有可用的 Key 重试...")
|
||||
else:
|
||||
logger.error(
|
||||
f"发生了错误(gemini_source)。Provider 配置如下: {self.provider_config}"
|
||||
)
|
||||
raise e
|
||||
|
||||
return llm_response
|
||||
|
||||
@@ -222,16 +267,16 @@ class ProviderGoogleGenAI(Provider):
|
||||
|
||||
def get_keys(self) -> List[str]:
|
||||
return self.api_keys
|
||||
|
||||
|
||||
def set_key(self, key):
|
||||
self.client.api_key = key
|
||||
|
||||
|
||||
async def assemble_context(self, text: str, image_urls: List[str] = None):
|
||||
'''
|
||||
"""
|
||||
组装上下文。
|
||||
'''
|
||||
"""
|
||||
if image_urls:
|
||||
user_content = {"role": "user","content": [{"type": "text", "text": text}]}
|
||||
user_content = {"role": "user", "content": [{"type": "text", "text": text}]}
|
||||
for image_url in image_urls:
|
||||
if image_url.startswith("http"):
|
||||
image_path = await download_image_by_url(image_url)
|
||||
@@ -244,18 +289,24 @@ class ProviderGoogleGenAI(Provider):
|
||||
if not image_data:
|
||||
logger.warning(f"图片 {image_url} 得到的结果为空,将忽略。")
|
||||
continue
|
||||
user_content["content"].append({"type": "image_url", "image_url": {"url": image_data}})
|
||||
user_content["content"].append(
|
||||
{"type": "image_url", "image_url": {"url": image_data}}
|
||||
)
|
||||
return user_content
|
||||
else:
|
||||
return {"role": "user","content": text}
|
||||
return {"role": "user", "content": text}
|
||||
|
||||
async def encode_image_bs64(self, image_url: str) -> str:
|
||||
'''
|
||||
"""
|
||||
将图片转换为 base64
|
||||
'''
|
||||
"""
|
||||
if image_url.startswith("base64://"):
|
||||
return image_url.replace("base64://", "data:image/jpeg;base64,")
|
||||
with open(image_url, "rb") as f:
|
||||
image_bs64 = base64.b64encode(f.read()).decode('utf-8')
|
||||
image_bs64 = base64.b64encode(f.read()).decode("utf-8")
|
||||
return "data:image/jpeg;base64," + image_bs64
|
||||
return ''
|
||||
return ""
|
||||
|
||||
async def terminate(self):
|
||||
await self.client.client.close()
|
||||
logger.info("Google GenAI 适配器已终止。")
|
||||
|
||||
52
astrbot/core/provider/sources/gsvi_tts_source.py
Normal file
52
astrbot/core/provider/sources/gsvi_tts_source.py
Normal file
@@ -0,0 +1,52 @@
|
||||
import uuid
|
||||
import aiohttp
|
||||
import urllib.parse
|
||||
from ..provider import TTSProvider
|
||||
from ..entites import ProviderType
|
||||
from ..register import register_provider_adapter
|
||||
|
||||
|
||||
@register_provider_adapter(
|
||||
"gsvi_tts_api", "GSVI TTS API", provider_type=ProviderType.TEXT_TO_SPEECH
|
||||
)
|
||||
class ProviderGSVITTS(TTSProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
self.api_base = provider_config.get("api_base", "http://127.0.0.1:5000")
|
||||
if self.api_base.endswith("/"):
|
||||
self.api_base = self.api_base[:-1]
|
||||
self.character = provider_config.get("character")
|
||||
self.emotion = provider_config.get("emotion")
|
||||
|
||||
async def get_audio(self, text: str) -> str:
|
||||
path = f"data/temp/gsvi_tts_{uuid.uuid4()}.wav"
|
||||
params = {"text": text}
|
||||
|
||||
if self.character:
|
||||
params["character"] = self.character
|
||||
if self.emotion:
|
||||
params["emotion"] = self.emotion
|
||||
|
||||
query_parts = []
|
||||
for key, value in params.items():
|
||||
encoded_value = urllib.parse.quote(str(value))
|
||||
query_parts.append(f"{key}={encoded_value}")
|
||||
|
||||
url = f"{self.api_base}/tts?{'&'.join(query_parts)}"
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(url) as response:
|
||||
if response.status == 200:
|
||||
with open(path, "wb") as f:
|
||||
f.write(await response.read())
|
||||
else:
|
||||
error_text = await response.text()
|
||||
raise Exception(
|
||||
f"GSVI TTS API 请求失败,状态码: {response.status},错误: {error_text}"
|
||||
)
|
||||
|
||||
return path
|
||||
@@ -1,8 +1,7 @@
|
||||
import json
|
||||
import os
|
||||
from llmtuner.chat import ChatModel
|
||||
from typing import List
|
||||
from .. import Provider, Personality
|
||||
from .. import Provider
|
||||
from ..entites import LLMResponse
|
||||
from ..func_tool_manager import FuncCall
|
||||
from astrbot.core.db import BaseDatabase
|
||||
@@ -22,7 +21,11 @@ class LLMTunerModelLoader(Provider):
|
||||
default_persona=None,
|
||||
) -> None:
|
||||
super().__init__(
|
||||
provider_config, provider_settings, persistant_history, db_helper, default_persona
|
||||
provider_config,
|
||||
provider_settings,
|
||||
persistant_history,
|
||||
db_helper,
|
||||
default_persona,
|
||||
)
|
||||
if not os.path.exists(provider_config["base_model_path"]) or not os.path.exists(
|
||||
provider_config["adapter_model_path"]
|
||||
@@ -70,10 +73,10 @@ class LLMTunerModelLoader(Provider):
|
||||
for idx, context in enumerate(query_context):
|
||||
if context["role"] == "system":
|
||||
system_idxs.append(idx)
|
||||
|
||||
if '_no_save' in context:
|
||||
del context['_no_save']
|
||||
|
||||
|
||||
if "_no_save" in context:
|
||||
del context["_no_save"]
|
||||
|
||||
for idx in reversed(system_idxs):
|
||||
system_prompt += " " + query_context.pop(idx)["content"]
|
||||
|
||||
@@ -84,12 +87,12 @@ class LLMTunerModelLoader(Provider):
|
||||
if func_tool:
|
||||
tool_list = func_tool.get_func_desc_openai_style()
|
||||
if tool_list:
|
||||
conf['tools'] = tool_list
|
||||
conf["tools"] = tool_list
|
||||
|
||||
responses = await self.model.achat(**conf)
|
||||
|
||||
llm_response = LLMResponse("assistant", responses[-1].response_text)
|
||||
|
||||
|
||||
return llm_response
|
||||
|
||||
async def get_current_key(self):
|
||||
@@ -99,4 +102,4 @@ class LLMTunerModelLoader(Provider):
|
||||
pass
|
||||
|
||||
async def get_models(self):
|
||||
return [self.get_model()]
|
||||
return [self.get_model()]
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
import base64
|
||||
import json
|
||||
import os
|
||||
import inspect
|
||||
|
||||
from openai import AsyncOpenAI, AsyncAzureOpenAI
|
||||
from openai.types.chat.chat_completion import ChatCompletion
|
||||
@@ -15,17 +16,26 @@ from typing import List
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
|
||||
@register_provider_adapter("openai_chat_completion", "OpenAI API Chat Completion 提供商适配器")
|
||||
|
||||
@register_provider_adapter(
|
||||
"openai_chat_completion", "OpenAI API Chat Completion 提供商适配器"
|
||||
)
|
||||
class ProviderOpenAIOfficial(Provider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history = True,
|
||||
default_persona: Personality = None
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history=True,
|
||||
default_persona: Personality = None,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings, persistant_history, db_helper, default_persona)
|
||||
super().__init__(
|
||||
provider_config,
|
||||
provider_settings,
|
||||
persistant_history,
|
||||
db_helper,
|
||||
default_persona,
|
||||
)
|
||||
self.chosen_api_key = None
|
||||
self.api_keys: List = provider_config.get("key", [])
|
||||
self.chosen_api_key = self.api_keys[0] if len(self.api_keys) > 0 else None
|
||||
@@ -39,54 +49,73 @@ class ProviderOpenAIOfficial(Provider):
|
||||
api_key=self.chosen_api_key,
|
||||
api_version=provider_config.get("api_version", None),
|
||||
base_url=provider_config.get("api_base", None),
|
||||
timeout=self.timeout
|
||||
timeout=self.timeout,
|
||||
)
|
||||
else:
|
||||
# 使用 openai api
|
||||
self.client = AsyncOpenAI(
|
||||
api_key=self.chosen_api_key,
|
||||
base_url=provider_config.get("api_base", None),
|
||||
timeout=self.timeout
|
||||
timeout=self.timeout,
|
||||
)
|
||||
|
||||
self.set_model(provider_config['model_config']['model'])
|
||||
|
||||
self.default_params = inspect.signature(
|
||||
self.client.chat.completions.create
|
||||
).parameters.keys()
|
||||
|
||||
model_config = provider_config.get("model_config", {})
|
||||
model = model_config.get("model", "unknown")
|
||||
self.set_model(model)
|
||||
|
||||
async def get_models(self):
|
||||
try:
|
||||
models_str = []
|
||||
models = await self.client.models.list()
|
||||
models = models.data
|
||||
models = sorted(models.data, key=lambda x: x.id)
|
||||
for model in models:
|
||||
models_str.append(model.id)
|
||||
return models_str
|
||||
except NotFoundError as e:
|
||||
raise Exception(f"获取模型列表失败:{e}")
|
||||
|
||||
|
||||
async def _query(self, payloads: dict, tools: FuncCall) -> LLMResponse:
|
||||
if tools:
|
||||
tool_list = tools.get_func_desc_openai_style()
|
||||
if tool_list:
|
||||
payloads['tools'] = tool_list
|
||||
|
||||
payloads["tools"] = tool_list
|
||||
|
||||
# 不在默认参数中的参数放在 extra_body 中
|
||||
extra_body = {}
|
||||
to_del = []
|
||||
for key in payloads.keys():
|
||||
if key not in self.default_params:
|
||||
extra_body[key] = payloads[key]
|
||||
to_del.append(key)
|
||||
for key in to_del:
|
||||
del payloads[key]
|
||||
|
||||
completion = await self.client.chat.completions.create(
|
||||
**payloads,
|
||||
stream=False
|
||||
**payloads, stream=False, extra_body=extra_body
|
||||
)
|
||||
|
||||
assert isinstance(completion, ChatCompletion)
|
||||
if not isinstance(completion, ChatCompletion):
|
||||
raise Exception(
|
||||
f"API 返回的 completion 类型错误:{type(completion)}: {completion}。"
|
||||
)
|
||||
|
||||
logger.debug(f"completion: {completion}")
|
||||
|
||||
if len(completion.choices) == 0:
|
||||
raise Exception("API 返回的 completion 为空。")
|
||||
choice = completion.choices[0]
|
||||
|
||||
|
||||
llm_response = LLMResponse("assistant")
|
||||
|
||||
|
||||
if choice.message.content:
|
||||
# text completion
|
||||
completion_text = str(choice.message.content).strip()
|
||||
llm_response.completion_text = completion_text
|
||||
|
||||
|
||||
if choice.message.tool_calls:
|
||||
# tools call (function calling)
|
||||
args_ls = []
|
||||
@@ -100,45 +129,43 @@ class ProviderOpenAIOfficial(Provider):
|
||||
llm_response.role = "tool"
|
||||
llm_response.tools_call_args = args_ls
|
||||
llm_response.tools_call_name = func_name_ls
|
||||
|
||||
if choice.finish_reason == 'content_filter':
|
||||
raise Exception("API 返回的 completion 由于内容安全过滤被拒绝(非 AstrBot)。")
|
||||
|
||||
if choice.finish_reason == "content_filter":
|
||||
raise Exception(
|
||||
"API 返回的 completion 由于内容安全过滤被拒绝(非 AstrBot)。"
|
||||
)
|
||||
|
||||
if not llm_response.completion_text and not llm_response.tools_call_args:
|
||||
logger.error(f"API 返回的 completion 无法解析:{completion}。")
|
||||
raise Exception(f"API 返回的 completion 无法解析:{completion}。")
|
||||
|
||||
|
||||
llm_response.raw_completion = completion
|
||||
|
||||
|
||||
return llm_response
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str=None,
|
||||
image_urls: List[str]=[],
|
||||
func_tool: FuncCall=None,
|
||||
session_id: str = None,
|
||||
image_urls: List[str] = [],
|
||||
func_tool: FuncCall = None,
|
||||
contexts=[],
|
||||
system_prompt=None,
|
||||
**kwargs
|
||||
) -> LLMResponse:
|
||||
**kwargs,
|
||||
) -> LLMResponse:
|
||||
new_record = await self.assemble_context(prompt, image_urls)
|
||||
context_query = [*contexts, new_record]
|
||||
if system_prompt:
|
||||
context_query.insert(0, {"role": "system", "content": system_prompt})
|
||||
|
||||
for part in context_query:
|
||||
if '_no_save' in part:
|
||||
del part['_no_save']
|
||||
|
||||
|
||||
model_config = self.provider_config.get("model_config", {})
|
||||
model_config['model'] = self.get_model()
|
||||
if "_no_save" in part:
|
||||
del part["_no_save"]
|
||||
|
||||
payloads = {
|
||||
"messages": context_query,
|
||||
**model_config
|
||||
}
|
||||
model_config = self.provider_config.get("model_config", {})
|
||||
model_config["model"] = self.get_model()
|
||||
|
||||
payloads = {"messages": context_query, **model_config}
|
||||
llm_response = None
|
||||
try:
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
@@ -146,7 +173,7 @@ class ProviderOpenAIOfficial(Provider):
|
||||
logger.warning(f"不可处理的实体错误:{e},尝试删除图片。")
|
||||
# 尝试删除所有 image
|
||||
new_contexts = await self._remove_image_from_context(context_query)
|
||||
payloads['messages'] = new_contexts
|
||||
payloads["messages"] = new_contexts
|
||||
context_query = new_contexts
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
except Exception as e:
|
||||
@@ -154,7 +181,9 @@ class ProviderOpenAIOfficial(Provider):
|
||||
# 重试 10 次
|
||||
retry_cnt = 20
|
||||
while retry_cnt > 0:
|
||||
logger.warning(f"上下文长度超过限制。尝试弹出最早的记录然后重试。当前记录条数: {len(context_query)}")
|
||||
logger.warning(
|
||||
f"上下文长度超过限制。尝试弹出最早的记录然后重试。当前记录条数: {len(context_query)}"
|
||||
)
|
||||
try:
|
||||
await self.pop_record(context_query)
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
@@ -165,83 +194,93 @@ class ProviderOpenAIOfficial(Provider):
|
||||
else:
|
||||
raise e
|
||||
if retry_cnt == 0:
|
||||
llm_response = LLMResponse("err", "err: 请尝试 /reset 清除会话记录。")
|
||||
elif "The model is not a VLM" in str(e): # siliconcloud
|
||||
llm_response = LLMResponse(
|
||||
"err", "err: 请尝试 /reset 清除会话记录。"
|
||||
)
|
||||
elif "The model is not a VLM" in str(e): # siliconcloud
|
||||
# 尝试删除所有 image
|
||||
new_contexts = await self._remove_image_from_context(context_query)
|
||||
payloads['messages'] = new_contexts
|
||||
payloads["messages"] = new_contexts
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
|
||||
# openai, ollama, gemini openai, siliconcloud 的错误提示与 code 不统一,只能通过字符串匹配
|
||||
elif 'does not support Function Calling' in str(e) \
|
||||
or 'does not support tools' in str(e) \
|
||||
or 'Function call is not supported' in str(e) \
|
||||
or 'Function calling is not enabled' in str(e) \
|
||||
or 'Tool calling is not supported' in str(e) \
|
||||
or 'No endpoints found that support tool use' in str(e) \
|
||||
or 'model does not support function calling' in str(e) \
|
||||
or ('tool' in str(e) and 'support' in str(e).lower()) \
|
||||
or ('function' in str(e) and 'support' in str(e).lower()):
|
||||
logger.info(f"{self.get_model()} 不支持函数工具调用,已自动去除,不影响使用。")
|
||||
if 'tools' in payloads:
|
||||
del payloads['tools']
|
||||
llm_response = await self._query(payloads, None)
|
||||
elif (
|
||||
"does not support Function Calling" in str(e)
|
||||
or "does not support tools" in str(e)
|
||||
or "Function call is not supported" in str(e)
|
||||
or "Function calling is not enabled" in str(e)
|
||||
or "Tool calling is not supported" in str(e)
|
||||
or "No endpoints found that support tool use" in str(e)
|
||||
or "model does not support function calling" in str(e)
|
||||
or ("tool" in str(e) and "support" in str(e).lower())
|
||||
or ("function" in str(e) and "support" in str(e).lower())
|
||||
):
|
||||
logger.info(
|
||||
f"{self.get_model()} 不支持函数工具调用,已自动去除,不影响使用。"
|
||||
)
|
||||
if "tools" in payloads:
|
||||
del payloads["tools"]
|
||||
llm_response = await self._query(payloads, None)
|
||||
else:
|
||||
logger.error(f"发生了错误。Provider 配置如下: {self.provider_config}")
|
||||
|
||||
if 'tool' in str(e).lower() and 'support' in str(e).lower():
|
||||
logger.error("疑似该模型不支持函数调用工具调用。请输入 /tool off_all")
|
||||
|
||||
if 'Connection error.' in str(e):
|
||||
|
||||
if "tool" in str(e).lower() and "support" in str(e).lower():
|
||||
logger.error(
|
||||
"疑似该模型不支持函数调用工具调用。请输入 /tool off_all"
|
||||
)
|
||||
|
||||
if "Connection error." in str(e):
|
||||
proxy = os.environ.get("http_proxy", None)
|
||||
if proxy:
|
||||
logger.error(f"可能为代理原因,请检查代理是否正常。当前代理: {proxy}")
|
||||
|
||||
logger.error(
|
||||
f"可能为代理原因,请检查代理是否正常。当前代理: {proxy}"
|
||||
)
|
||||
|
||||
raise e
|
||||
|
||||
|
||||
return llm_response
|
||||
|
||||
|
||||
async def _remove_image_from_context(self, contexts: List):
|
||||
'''
|
||||
"""
|
||||
从上下文中删除所有带有 image 的记录
|
||||
'''
|
||||
"""
|
||||
new_contexts = []
|
||||
|
||||
|
||||
flag = False
|
||||
for context in contexts:
|
||||
if flag:
|
||||
flag = False # 删除 image 后,下一条(LLM 响应)也要删除
|
||||
flag = False # 删除 image 后,下一条(LLM 响应)也要删除
|
||||
continue
|
||||
if isinstance(context['content'], list):
|
||||
if isinstance(context["content"], list):
|
||||
flag = True
|
||||
# continue
|
||||
new_content = []
|
||||
for item in context['content']:
|
||||
if isinstance(item, dict) and 'image_url' in item:
|
||||
for item in context["content"]:
|
||||
if isinstance(item, dict) and "image_url" in item:
|
||||
continue
|
||||
new_content.append(item)
|
||||
if not new_content:
|
||||
# 用户只发了图片
|
||||
new_content = [{"type": "text", "text": "[图片]"}]
|
||||
context['content'] = new_content
|
||||
context["content"] = new_content
|
||||
new_contexts.append(context)
|
||||
return new_contexts
|
||||
|
||||
|
||||
def get_current_key(self) -> str:
|
||||
return self.client.api_key
|
||||
|
||||
def get_keys(self) -> List[str]:
|
||||
return self.api_keys
|
||||
|
||||
|
||||
def set_key(self, key):
|
||||
self.client.api_key = key
|
||||
|
||||
|
||||
async def assemble_context(self, text: str, image_urls: List[str] = None):
|
||||
'''
|
||||
"""
|
||||
组装上下文。
|
||||
'''
|
||||
"""
|
||||
if image_urls:
|
||||
user_content = {"role": "user","content": [{"type": "text", "text": text}]}
|
||||
user_content = {"role": "user", "content": [{"type": "text", "text": text}]}
|
||||
for image_url in image_urls:
|
||||
if image_url.startswith("http"):
|
||||
image_path = await download_image_by_url(image_url)
|
||||
@@ -254,18 +293,20 @@ class ProviderOpenAIOfficial(Provider):
|
||||
if not image_data:
|
||||
logger.warning(f"图片 {image_url} 得到的结果为空,将忽略。")
|
||||
continue
|
||||
user_content["content"].append({"type": "image_url", "image_url": {"url": image_data}})
|
||||
user_content["content"].append(
|
||||
{"type": "image_url", "image_url": {"url": image_data}}
|
||||
)
|
||||
return user_content
|
||||
else:
|
||||
return {"role": "user","content": text}
|
||||
return {"role": "user", "content": text}
|
||||
|
||||
async def encode_image_bs64(self, image_url: str) -> str:
|
||||
'''
|
||||
"""
|
||||
将图片转换为 base64
|
||||
'''
|
||||
"""
|
||||
if image_url.startswith("base64://"):
|
||||
return image_url.replace("base64://", "data:image/jpeg;base64,")
|
||||
with open(image_url, "rb") as f:
|
||||
image_bs64 = base64.b64encode(f.read()).decode('utf-8')
|
||||
image_bs64 = base64.b64encode(f.read()).decode("utf-8")
|
||||
return "data:image/jpeg;base64," + image_bs64
|
||||
return ''
|
||||
return ""
|
||||
|
||||
@@ -1,16 +1,17 @@
|
||||
import uuid
|
||||
import os
|
||||
from openai import AsyncOpenAI, NOT_GIVEN
|
||||
from ..provider import TTSProvider
|
||||
from ..entites import ProviderType
|
||||
from ..register import register_provider_adapter
|
||||
|
||||
|
||||
@register_provider_adapter("openai_tts_api", "OpenAI TTS API", provider_type=ProviderType.TEXT_TO_SPEECH)
|
||||
@register_provider_adapter(
|
||||
"openai_tts_api", "OpenAI TTS API", provider_type=ProviderType.TEXT_TO_SPEECH
|
||||
)
|
||||
class ProviderOpenAITTSAPI(TTSProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
@@ -22,19 +23,15 @@ class ProviderOpenAITTSAPI(TTSProvider):
|
||||
base_url=provider_config.get("api_base", None),
|
||||
timeout=provider_config.get("timeout", NOT_GIVEN),
|
||||
)
|
||||
|
||||
|
||||
self.set_model(provider_config.get("model", None))
|
||||
|
||||
|
||||
async def get_audio(self, text: str) -> str:
|
||||
path = f'data/temp/openai_tts_api_{uuid.uuid4()}.wav'
|
||||
path = f"data/temp/openai_tts_api_{uuid.uuid4()}.wav"
|
||||
async with self.client.audio.speech.with_streaming_response.create(
|
||||
model=self.model_name,
|
||||
voice=self.voice,
|
||||
response_format='wav',
|
||||
input=text
|
||||
model=self.model_name, voice=self.voice, response_format="wav", input=text
|
||||
) as response:
|
||||
with open(path, 'wb') as f:
|
||||
with open(path, "wb") as f:
|
||||
async for chunk in response.iter_bytes(chunk_size=1024):
|
||||
f.write(chunk)
|
||||
return path
|
||||
return path
|
||||
|
||||
112
astrbot/core/provider/sources/sensevoice_selfhosted_source.py
Normal file
112
astrbot/core/provider/sources/sensevoice_selfhosted_source.py
Normal file
@@ -0,0 +1,112 @@
|
||||
"""
|
||||
Author: diudiu62
|
||||
Date: 2025-02-24 18:04:18
|
||||
LastEditTime: 2025-02-25 14:06:30
|
||||
"""
|
||||
|
||||
import asyncio
|
||||
from datetime import datetime
|
||||
import os
|
||||
import re
|
||||
from funasr_onnx import SenseVoiceSmall
|
||||
from funasr_onnx.utils.postprocess_utils import rich_transcription_postprocess
|
||||
from ..provider import STTProvider
|
||||
from ..entites import ProviderType
|
||||
from astrbot.core.utils.io import download_file
|
||||
from ..register import register_provider_adapter
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.tencent_record_helper import tencent_silk_to_wav
|
||||
|
||||
|
||||
@register_provider_adapter(
|
||||
"sensevoice_stt_selfhost",
|
||||
"SenseVoice 自托管语音识别 模型部署",
|
||||
provider_type=ProviderType.SPEECH_TO_TEXT,
|
||||
)
|
||||
class ProviderSenseVoiceSTTSelfHost(STTProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
self.set_model(provider_config.get("stt_model", None))
|
||||
self.model = None
|
||||
self.is_emotion = provider_config.get("is_emotion", False)
|
||||
|
||||
async def initialize(self):
|
||||
logger.info("下载或者加载 SenseVoice 模型中,这可能需要一些时间 ...")
|
||||
|
||||
# 将模型加载放到线程池中执行
|
||||
self.model = await asyncio.get_event_loop().run_in_executor(
|
||||
None, lambda: SenseVoiceSmall(self.model_name, quantize=True, batch_size=16)
|
||||
)
|
||||
|
||||
logger.info("SenseVoice 模型加载完成。")
|
||||
|
||||
async def get_timestamped_path(self) -> str:
|
||||
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
return os.path.join("data", "temp", f"{timestamp}")
|
||||
|
||||
async def _convert_audio(self, path: str) -> str:
|
||||
from pyffmpeg import FFmpeg
|
||||
|
||||
filename = await self.get_timestamped_path() + ".mp3"
|
||||
ff = FFmpeg()
|
||||
output_path = ff.convert(path, os.path.join('data","temp', filename))
|
||||
return output_path
|
||||
|
||||
async def _is_silk_file(self, file_path):
|
||||
silk_header = b"SILK"
|
||||
with open(file_path, "rb") as f:
|
||||
file_header = f.read(8)
|
||||
|
||||
if silk_header in file_header:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
async def get_text(self, audio_url: str) -> str:
|
||||
try:
|
||||
is_tencent = (
|
||||
audio_url.startswith("http") and "multimedia.nt.qq.com.cn" in audio_url
|
||||
)
|
||||
|
||||
if is_tencent:
|
||||
path = await self.get_timestamped_path()
|
||||
await download_file(audio_url, path)
|
||||
audio_url = path
|
||||
|
||||
if not os.path.isfile(audio_url):
|
||||
raise FileNotFoundError(f"文件不存在: {audio_url}")
|
||||
|
||||
if audio_url.endswith((".amr", ".silk")) or is_tencent:
|
||||
is_silk = await self._is_silk_file(audio_url)
|
||||
if is_silk:
|
||||
logger.info("Converting silk file to wav ...")
|
||||
output_path = await self.get_timestamped_path() + ".wav"
|
||||
await tencent_silk_to_wav(audio_url, output_path)
|
||||
audio_url = output_path
|
||||
|
||||
# 使用 run_in_executor 来调用模型进行识别
|
||||
loop = asyncio.get_event_loop()
|
||||
res = await loop.run_in_executor(
|
||||
None, # 使用默认的线程池
|
||||
lambda: self.model(audio_url, language="auto", use_itn=True),
|
||||
)
|
||||
|
||||
# res = self.model(audio_url, language="auto", use_itn=True)
|
||||
logger.debug(f"SenseVoice识别到的文案:{res}")
|
||||
text = rich_transcription_postprocess(res[0])
|
||||
if self.is_emotion:
|
||||
# 提取第二个匹配的值
|
||||
matches = re.findall(r"<\|([^|]+)\|>", res[0])
|
||||
if len(matches) >= 2:
|
||||
emotion = matches[1]
|
||||
text = f"(当前的情绪:{emotion}) {text}"
|
||||
else:
|
||||
logger.warning("未能提取到情绪信息")
|
||||
return text
|
||||
except Exception as e:
|
||||
logger.error(f"处理音频文件时出错: {e}")
|
||||
raise
|
||||
@@ -8,11 +8,16 @@ from ..register import register_provider_adapter
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.tencent_record_helper import tencent_silk_to_wav
|
||||
|
||||
@register_provider_adapter("openai_whisper_api", "OpenAI Whisper API", provider_type=ProviderType.SPEECH_TO_TEXT)
|
||||
|
||||
@register_provider_adapter(
|
||||
"openai_whisper_api",
|
||||
"OpenAI Whisper API",
|
||||
provider_type=ProviderType.SPEECH_TO_TEXT,
|
||||
)
|
||||
class ProviderOpenAIWhisperAPI(STTProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
@@ -23,16 +28,17 @@ class ProviderOpenAIWhisperAPI(STTProvider):
|
||||
base_url=provider_config.get("api_base", None),
|
||||
timeout=provider_config.get("timeout", NOT_GIVEN),
|
||||
)
|
||||
|
||||
|
||||
self.set_model(provider_config.get("model", None))
|
||||
|
||||
|
||||
async def _convert_audio(self, path: str) -> str:
|
||||
from pyffmpeg import FFmpeg
|
||||
filename = str(uuid.uuid4()) + '.mp3'
|
||||
|
||||
filename = str(uuid.uuid4()) + ".mp3"
|
||||
ff = FFmpeg()
|
||||
output_path = ff.convert(path, os.path.join('data/temp', filename))
|
||||
output_path = ff.convert(path, os.path.join("data/temp", filename))
|
||||
return output_path
|
||||
|
||||
|
||||
async def _is_silk_file(self, file_path):
|
||||
silk_header = b"SILK"
|
||||
with open(file_path, "rb") as f:
|
||||
@@ -44,31 +50,31 @@ class ProviderOpenAIWhisperAPI(STTProvider):
|
||||
return False
|
||||
|
||||
async def get_text(self, audio_url: str) -> str:
|
||||
'''only supports mp3, mp4, mpeg, m4a, wav, webm'''
|
||||
"""only supports mp3, mp4, mpeg, m4a, wav, webm"""
|
||||
is_tencent = False
|
||||
|
||||
|
||||
if audio_url.startswith("http"):
|
||||
if "multimedia.nt.qq.com.cn" in audio_url:
|
||||
is_tencent = True
|
||||
|
||||
|
||||
name = str(uuid.uuid4())
|
||||
path = os.path.join("data/temp", name)
|
||||
await download_file(audio_url, path)
|
||||
audio_url = path
|
||||
|
||||
|
||||
if not os.path.exists(audio_url):
|
||||
raise FileNotFoundError(f"文件不存在: {audio_url}")
|
||||
|
||||
|
||||
if audio_url.endswith(".amr") or audio_url.endswith(".silk") or is_tencent:
|
||||
is_silk = await self._is_silk_file(audio_url)
|
||||
if is_silk:
|
||||
logger.info("Converting silk file to wav ...")
|
||||
output_path = os.path.join('data/temp', str(uuid.uuid4()) + '.wav')
|
||||
output_path = os.path.join("data/temp", str(uuid.uuid4()) + ".wav")
|
||||
await tencent_silk_to_wav(audio_url, output_path)
|
||||
audio_url = output_path
|
||||
|
||||
|
||||
result = await self.client.audio.transcriptions.create(
|
||||
model=self.model_name,
|
||||
file=open(audio_url, "rb"),
|
||||
)
|
||||
return result.text
|
||||
return result.text
|
||||
|
||||
@@ -9,30 +9,38 @@ from ..register import register_provider_adapter
|
||||
from astrbot.core import logger
|
||||
from astrbot.core.utils.tencent_record_helper import tencent_silk_to_wav
|
||||
|
||||
@register_provider_adapter("openai_whisper_selfhost", "OpenAI Whisper 模型部署", provider_type=ProviderType.SPEECH_TO_TEXT)
|
||||
|
||||
@register_provider_adapter(
|
||||
"openai_whisper_selfhost",
|
||||
"OpenAI Whisper 模型部署",
|
||||
provider_type=ProviderType.SPEECH_TO_TEXT,
|
||||
)
|
||||
class ProviderOpenAIWhisperSelfHost(STTProvider):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
self.set_model(provider_config.get("model", None))
|
||||
self.model = None
|
||||
|
||||
|
||||
async def initialize(self):
|
||||
loop = asyncio.get_event_loop()
|
||||
logger.info("下载或者加载 Whisper 模型中,这可能需要一些时间 ...")
|
||||
self.model = await loop.run_in_executor(None, whisper.load_model, self.model_name)
|
||||
self.model = await loop.run_in_executor(
|
||||
None, whisper.load_model, self.model_name
|
||||
)
|
||||
logger.info("Whisper 模型加载完成。")
|
||||
|
||||
|
||||
async def _convert_audio(self, path: str) -> str:
|
||||
from pyffmpeg import FFmpeg
|
||||
filename = str(uuid.uuid4()) + '.mp3'
|
||||
|
||||
filename = str(uuid.uuid4()) + ".mp3"
|
||||
ff = FFmpeg()
|
||||
output_path = ff.convert(path, os.path.join('data/temp', filename))
|
||||
output_path = ff.convert(path, os.path.join("data/temp", filename))
|
||||
return output_path
|
||||
|
||||
|
||||
async def _is_silk_file(self, file_path):
|
||||
silk_header = b"SILK"
|
||||
with open(file_path, "rb") as f:
|
||||
@@ -45,28 +53,28 @@ class ProviderOpenAIWhisperSelfHost(STTProvider):
|
||||
|
||||
async def get_text(self, audio_url: str) -> str:
|
||||
loop = asyncio.get_event_loop()
|
||||
|
||||
|
||||
is_tencent = False
|
||||
|
||||
|
||||
if audio_url.startswith("http"):
|
||||
if "multimedia.nt.qq.com.cn" in audio_url:
|
||||
is_tencent = True
|
||||
|
||||
|
||||
name = str(uuid.uuid4())
|
||||
path = os.path.join("data/temp", name)
|
||||
await download_file(audio_url, path)
|
||||
audio_url = path
|
||||
|
||||
|
||||
if not os.path.exists(audio_url):
|
||||
raise FileNotFoundError(f"文件不存在: {audio_url}")
|
||||
|
||||
|
||||
if audio_url.endswith(".amr") or audio_url.endswith(".silk") or is_tencent:
|
||||
is_silk = await self._is_silk_file(audio_url)
|
||||
if is_silk:
|
||||
logger.info("Converting silk file to wav ...")
|
||||
output_path = os.path.join('data/temp', str(uuid.uuid4()) + '.wav')
|
||||
output_path = os.path.join("data/temp", str(uuid.uuid4()) + ".wav")
|
||||
await tencent_silk_to_wav(audio_url, output_path)
|
||||
audio_url = output_path
|
||||
|
||||
|
||||
result = await loop.run_in_executor(None, self.model.transcribe, audio_url)
|
||||
return result['text']
|
||||
return result["text"]
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
import traceback
|
||||
from astrbot.core.db import BaseDatabase
|
||||
from astrbot import logger
|
||||
from astrbot.core.provider.func_tool_manager import FuncCall
|
||||
@@ -7,37 +6,44 @@ from ..register import register_provider_adapter
|
||||
from astrbot.core.provider.entites import LLMResponse
|
||||
from .openai_source import ProviderOpenAIOfficial
|
||||
|
||||
|
||||
@register_provider_adapter("zhipu_chat_completion", "智浦 Chat Completion 提供商适配器")
|
||||
class ProviderZhipu(ProviderOpenAIOfficial):
|
||||
def __init__(
|
||||
self,
|
||||
provider_config: dict,
|
||||
self,
|
||||
provider_config: dict,
|
||||
provider_settings: dict,
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history = True,
|
||||
default_persona = None
|
||||
db_helper: BaseDatabase,
|
||||
persistant_history=True,
|
||||
default_persona=None,
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings, db_helper, persistant_history, default_persona)
|
||||
|
||||
super().__init__(
|
||||
provider_config,
|
||||
provider_settings,
|
||||
db_helper,
|
||||
persistant_history,
|
||||
default_persona,
|
||||
)
|
||||
|
||||
async def text_chat(
|
||||
self,
|
||||
prompt: str,
|
||||
session_id: str = None,
|
||||
image_urls: List[str]=None,
|
||||
func_tool: FuncCall=None,
|
||||
image_urls: List[str] = None,
|
||||
func_tool: FuncCall = None,
|
||||
contexts=[],
|
||||
system_prompt=None,
|
||||
**kwargs
|
||||
) -> LLMResponse:
|
||||
**kwargs,
|
||||
) -> LLMResponse:
|
||||
new_record = await self.assemble_context(prompt, image_urls)
|
||||
context_query = []
|
||||
|
||||
|
||||
context_query = [*contexts, new_record]
|
||||
|
||||
|
||||
model_cfgs: dict = self.provider_config.get("model_config", {})
|
||||
model = self.get_model()
|
||||
# glm-4v-flash 只支持一张图片
|
||||
if model.lower() == 'glm-4v-flash' and image_urls and len(context_query) > 1:
|
||||
if model.lower() == "glm-4v-flash" and image_urls and len(context_query) > 1:
|
||||
logger.debug("glm-4v-flash 只支持一张图片,将只保留最后一张图片")
|
||||
logger.debug(context_query)
|
||||
new_context_query_ = []
|
||||
@@ -45,18 +51,15 @@ class ProviderZhipu(ProviderOpenAIOfficial):
|
||||
if isinstance(context_query[i].get("content", ""), list):
|
||||
continue
|
||||
new_context_query_.append(context_query[i])
|
||||
new_context_query_.append(context_query[i+1])
|
||||
new_context_query_.append(context_query[-1]) # 保留最后一条记录
|
||||
new_context_query_.append(context_query[i + 1])
|
||||
new_context_query_.append(context_query[-1]) # 保留最后一条记录
|
||||
context_query = new_context_query_
|
||||
logger.debug(context_query)
|
||||
|
||||
|
||||
if system_prompt:
|
||||
context_query.insert(0, {"role": "system", "content": system_prompt})
|
||||
|
||||
payloads = {
|
||||
"messages": context_query,
|
||||
**model_cfgs
|
||||
}
|
||||
|
||||
payloads = {"messages": context_query, **model_cfgs}
|
||||
try:
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
return llm_response
|
||||
@@ -64,7 +67,9 @@ class ProviderZhipu(ProviderOpenAIOfficial):
|
||||
if "maximum context length" in str(e):
|
||||
retry_cnt = 10
|
||||
while retry_cnt > 0:
|
||||
logger.warning(f"请求失败:{e}。上下文长度超过限制。尝试弹出最早的记录然后重试。")
|
||||
logger.warning(
|
||||
f"请求失败:{e}。上下文长度超过限制。尝试弹出最早的记录然后重试。"
|
||||
)
|
||||
try:
|
||||
self.pop_record(session_id)
|
||||
llm_response = await self._query(payloads, func_tool)
|
||||
@@ -75,4 +80,4 @@ class ProviderZhipu(ProviderOpenAIOfficial):
|
||||
else:
|
||||
raise e
|
||||
else:
|
||||
raise e
|
||||
raise e
|
||||
|
||||
@@ -1,25 +1,20 @@
|
||||
from typing import List
|
||||
from openai import AsyncOpenAI
|
||||
|
||||
class SimpleOpenAIEmbedding():
|
||||
|
||||
class SimpleOpenAIEmbedding:
|
||||
def __init__(
|
||||
self,
|
||||
self,
|
||||
model,
|
||||
api_key,
|
||||
api_base=None,
|
||||
) -> None:
|
||||
self.client = AsyncOpenAI(
|
||||
api_key=api_key,
|
||||
base_url=api_base
|
||||
)
|
||||
self.client = AsyncOpenAI(api_key=api_key, base_url=api_base)
|
||||
self.model = model
|
||||
|
||||
|
||||
async def get_embedding(self, text) -> List[float]:
|
||||
'''
|
||||
"""
|
||||
获取文本的嵌入
|
||||
'''
|
||||
embedding = await self.client.embeddings.create(
|
||||
input=text,
|
||||
model=self.model
|
||||
)
|
||||
"""
|
||||
embedding = await self.client.embeddings.create(input=text, model=self.model)
|
||||
return embedding.data[0].embedding
|
||||
|
||||
@@ -4,7 +4,8 @@ from astrbot.core import logger
|
||||
from .store import Store
|
||||
from astrbot.core.config import AstrBotConfig
|
||||
|
||||
class KnowledgeDBManager():
|
||||
|
||||
class KnowledgeDBManager:
|
||||
def __init__(self, astrbot_config: AstrBotConfig) -> None:
|
||||
self.db_path = "data/knowledge_db/"
|
||||
self.config = astrbot_config.get("knowledge_db", {})
|
||||
@@ -20,23 +21,27 @@ class KnowledgeDBManager():
|
||||
except ImportError as ie:
|
||||
logger.error(f"{ie} 可能未安装 chromadb 库。")
|
||||
continue
|
||||
self.store_insts[name] = ChromaVectorStore(name, cfg["embedding_config"])
|
||||
self.store_insts[name] = ChromaVectorStore(
|
||||
name, cfg["embedding_config"]
|
||||
)
|
||||
else:
|
||||
logger.error(f"不支持的策略:{cfg['strategy']}")
|
||||
|
||||
|
||||
async def list_knowledge_db(self) -> List[str]:
|
||||
return [f for f in os.listdir(self.db_path) if os.path.isfile(os.path.join(self.db_path, f))]
|
||||
|
||||
|
||||
return [
|
||||
f
|
||||
for f in os.listdir(self.db_path)
|
||||
if os.path.isfile(os.path.join(self.db_path, f))
|
||||
]
|
||||
|
||||
async def create_knowledge_db(self, name: str, config: Dict):
|
||||
'''
|
||||
"""
|
||||
config 格式:
|
||||
```
|
||||
{
|
||||
"strategy": "embedding", # 目前只支持 embedding
|
||||
"chunk_method": {
|
||||
"strategy": "fixed",
|
||||
"strategy": "fixed",
|
||||
"chunk_size": 100,
|
||||
"overlap_size": 10
|
||||
},
|
||||
@@ -48,40 +53,37 @@ class KnowledgeDBManager():
|
||||
}
|
||||
}
|
||||
```
|
||||
'''
|
||||
"""
|
||||
if name in self.config:
|
||||
raise ValueError(f"知识库已存在:{name}")
|
||||
|
||||
|
||||
self.config[name] = config
|
||||
self.astrbot_config["knowledge_db"] = self.config
|
||||
self.astrbot_config.save_config()
|
||||
|
||||
|
||||
|
||||
async def insert_record(self, name: str, text: str):
|
||||
if name not in self.store_insts:
|
||||
raise ValueError(f"未找到知识库:{name}")
|
||||
|
||||
|
||||
ret = []
|
||||
match self.config[name]["chunk_method"]['strategy']:
|
||||
match self.config[name]["chunk_method"]["strategy"]:
|
||||
case "fixed":
|
||||
chunk_size = self.config[name]["chunk_method"]["chunk_size"]
|
||||
chunk_overlap = self.config[name]["chunk_method"]["overlap_size"]
|
||||
ret = self._fixed_chunk(text, chunk_size, chunk_overlap)
|
||||
case _:
|
||||
pass
|
||||
|
||||
|
||||
for chunk in ret:
|
||||
await self.store_insts[name].save(chunk)
|
||||
|
||||
|
||||
async def retrive_records(self, name: str, query: str, top_n: int = 3) -> List[str]:
|
||||
if name not in self.store_insts:
|
||||
raise ValueError(f"未找到知识库:{name}")
|
||||
|
||||
|
||||
inst = self.store_insts[name]
|
||||
return await inst.query(query, top_n)
|
||||
|
||||
|
||||
|
||||
def _fixed_chunk(self, text: str, chunk_size: int, chunk_overlap: int) -> List[str]:
|
||||
chunks = []
|
||||
start = 0
|
||||
@@ -89,4 +91,4 @@ class KnowledgeDBManager():
|
||||
end = start + chunk_size
|
||||
chunks.append(text[start:end])
|
||||
start += chunk_size - chunk_overlap
|
||||
return chunks
|
||||
return chunks
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
from typing import List
|
||||
|
||||
class Store():
|
||||
|
||||
class Store:
|
||||
async def save(self, text: str):
|
||||
pass
|
||||
|
||||
|
||||
async def query(self, query: str, top_n: int = 3) -> List[str]:
|
||||
pass
|
||||
|
||||
@@ -5,35 +5,38 @@ from astrbot.api import logger
|
||||
from ..embedding.openai_source import SimpleOpenAIEmbedding
|
||||
from . import Store
|
||||
|
||||
|
||||
class ChromaVectorStore(Store):
|
||||
def __init__(self, name: str, embedding_cfg: Dict) -> None:
|
||||
self.chroma_client = chromadb.PersistentClient(path='data/long_term_memory_chroma.db')
|
||||
self.chroma_client = chromadb.PersistentClient(
|
||||
path="data/long_term_memory_chroma.db"
|
||||
)
|
||||
self.collection = self.chroma_client.get_or_create_collection(name=name)
|
||||
self.embedding = None
|
||||
if embedding_cfg["strategy"] == "openai":
|
||||
self.embedding = SimpleOpenAIEmbedding(
|
||||
model=embedding_cfg["model"],
|
||||
api_key=embedding_cfg["api_key"],
|
||||
api_base=embedding_cfg.get("base_url", None)
|
||||
api_base=embedding_cfg.get("base_url", None),
|
||||
)
|
||||
|
||||
|
||||
async def save(self, text: str, metadata: Dict = None):
|
||||
logger.debug(f"Saving text: {text}")
|
||||
embedding = await self.embedding.get_embedding(text)
|
||||
|
||||
|
||||
self.collection.upsert(
|
||||
documents=text,
|
||||
documents=text,
|
||||
metadatas=metadata,
|
||||
ids=str(uuid.uuid4()),
|
||||
embeddings=embedding
|
||||
embeddings=embedding,
|
||||
)
|
||||
|
||||
async def query(self, query: str, top_n=3, metadata_filter: Dict = None) -> List[str]:
|
||||
|
||||
async def query(
|
||||
self, query: str, top_n=3, metadata_filter: Dict = None
|
||||
) -> List[str]:
|
||||
embedding = await self.embedding.get_embedding(query)
|
||||
|
||||
|
||||
results = self.collection.query(
|
||||
query_embeddings=embedding,
|
||||
n_results=top_n,
|
||||
where=metadata_filter
|
||||
query_embeddings=embedding, n_results=top_n, where=metadata_filter
|
||||
)
|
||||
return results['documents'][0]
|
||||
return results["documents"][0]
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user